前言
本篇和大家一起深入
MySQL
的字符集与对照规则,剖析下我们存储在
MySQL
中的字段是如何进行存储和校验比对的。
-
先看问题
:
unique key
为什么失效了? -
拉齐共识
:回顾下字符编码的基础知识,回炉下
ASCII
和
Unicode
。 -
深入了解
:通过
MySQL
官网中对字符编码的支持和规则进行学习分析 -
汇总结论
:根据掌握的规则来总结下项目实践中的注意事项
先看问题:unique key为什么失效了?
最近做迁移数据的工作,把A库数据迁移到B库,中间没有任何处理逻辑,是纯复制工作。但是,在迁移过程中发现大部分表都可以正常完成迁移且源表和目标表数量能够保持一致,只有两张表数据总是会少插入数据,于是我开始按照以下思路排查:
-
第一步
,这两张有问题的表最大不同点是,都有
unique key
,其他的表没有,猜测可能和此有关; -
第二步
,发现两张表结构定义部分字段的
字符集(CHARACTER SET)
、
排序规则(COLLATE)
不一致; -
第三步
,带着上面两个差异点,对比源表、目标表定位插入失败的数据,缩小问题范围。
基于上述思路,使用测试数据来阐述
出现问题的表结构定义如下:
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(32) NOT NULL COMMENT '姓名',
`age` int(11) NOT NULL COMMENT '年龄',
PRIMARY KEY (`id`), -- 主键
UNIQUE KEY `name` (`name`,`age`) -- 联合唯一索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 -- 表字符集
插入一条数据,如下:
mysql> insert into user (name, age) value ('ZHANGSAN',1);
Query OK, 1 row affected (0.01 sec)
随后,再插入一条数据,如下:
mysql> insert into user (name, age) value ('zhangsan',1);
ERROR 1062 (23000): Duplicate entry 'zhangsan-1' for key 'name'
这里两次插入
name
字段的值是大小写有区分的,按照一般理解,即使是相同字符但不同大小写的字符是不同的,应该支持插入,这里居然提示重复了,命中了
unique key
的拦截规则限制。
拉齐共识:回顾字符编码
推荐一个很不错的科普视频
《快速搞懂?Unicode,ASCII,UTF-8,代码点,编码…》
ASCII
ASCII
(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,它是现今最通用的单字节编码系统。
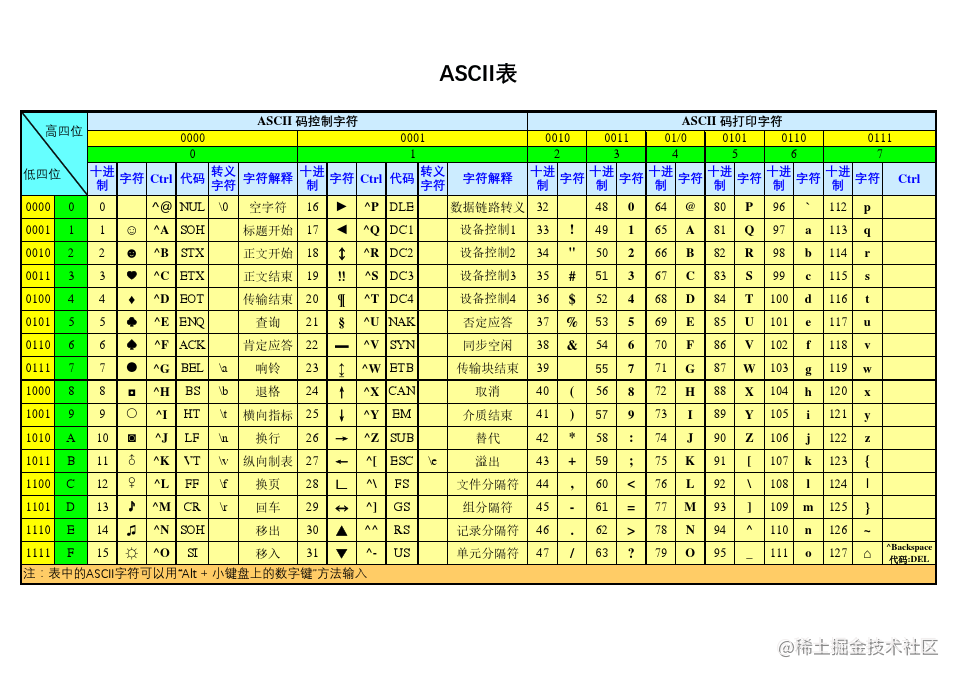
如上,是一张
ASCII
码映射表,它将西文字符映射到
[0,127]
之间的数字上,即能够支持128个字符的表示。如果想要表示字符串
Hello
,就会得到如下
ASCII
码映射:
| 字符串 | 十进制 | 二进制 |
|---|---|---|
| H | 72 | 0100 1000 |
| e | 101 | 0110 0101 |
| l | 108 | 0110 1100 |
| l | 108 | 0110 1100 |
| o | 111 | 0110 1111 |
计算机存储是按照
字节(Byte)
来计算,这里最大十进制数字是
127
,它的二进制最多使用
8位(Bit)
表示,因此最多
ASCII
编码消耗
1个字节
存储空间。
ASCII
编码在英文世界如鱼得水,一切都井然有序,但是世界语言还有很多,中文、梵文、阿拉伯文等等,
ASCII
编码对英文外的语言无法支持。
Unicode
这里有一个比较扣字眼的地方?♂️,
Unicode
一般认为是字符集,而具体的
UTF8
、
UTF16
等认为是字符编码。
Unicode
就是字典映射表码值,管它叫字符集(Character Set)
UTF8
就是转换二进制存储的方式,管它叫编码(Encoding)可以结合下文的编码规则差异品一品,理解意思就好,没必要背八股。
基于上述,我们需要更为通用、能够支持全世界多语种字符的编码来作为“
通用语言
”,于是
Unicode
应运而生,它能够囊括一百多种语言的十几万量级的字符,其中包含重音符、表情符号和各种各样奇怪的特殊字符。
关于Unicode的字符编码有以下特点:
-
「代码点映射」
在Unicode中,字符需要首先映射到
代码点(Code Points)
上,有的字符不止由一个代码点映射,可以通过组合多个代码点组合来表示一个字符含义,然后再通过得到的代码点转换成二进制来存储;-
Unicode
支持的字符编码更丰富,可包含数量大,也能通过组合
代码点
来编码表示复杂符号
(dén、hören)
或表情
(??)
等 -
ASCII
被包含于
Unicode
中,英文字母在
Unicode
中的代码点与
ASCII
中的映射值是一样的,如
unicode('H')
的代码点、
ascii('H')
的映射值都是
72
。
-
-
「语言的存储差异」
在
Unicode
中,代码点很多,由于代码点排列分布的问题,英文字符先入为主比较靠前是低位代码点,因此转换成二进制的时候占用空间小,而其他复杂语言的代码点“入场”较晚被安排在高位,转换成二进制的时候空间占用就会大一些,因此存储上其他语言相比英文字符来说会占用更多空间。
小结
编码规则差异
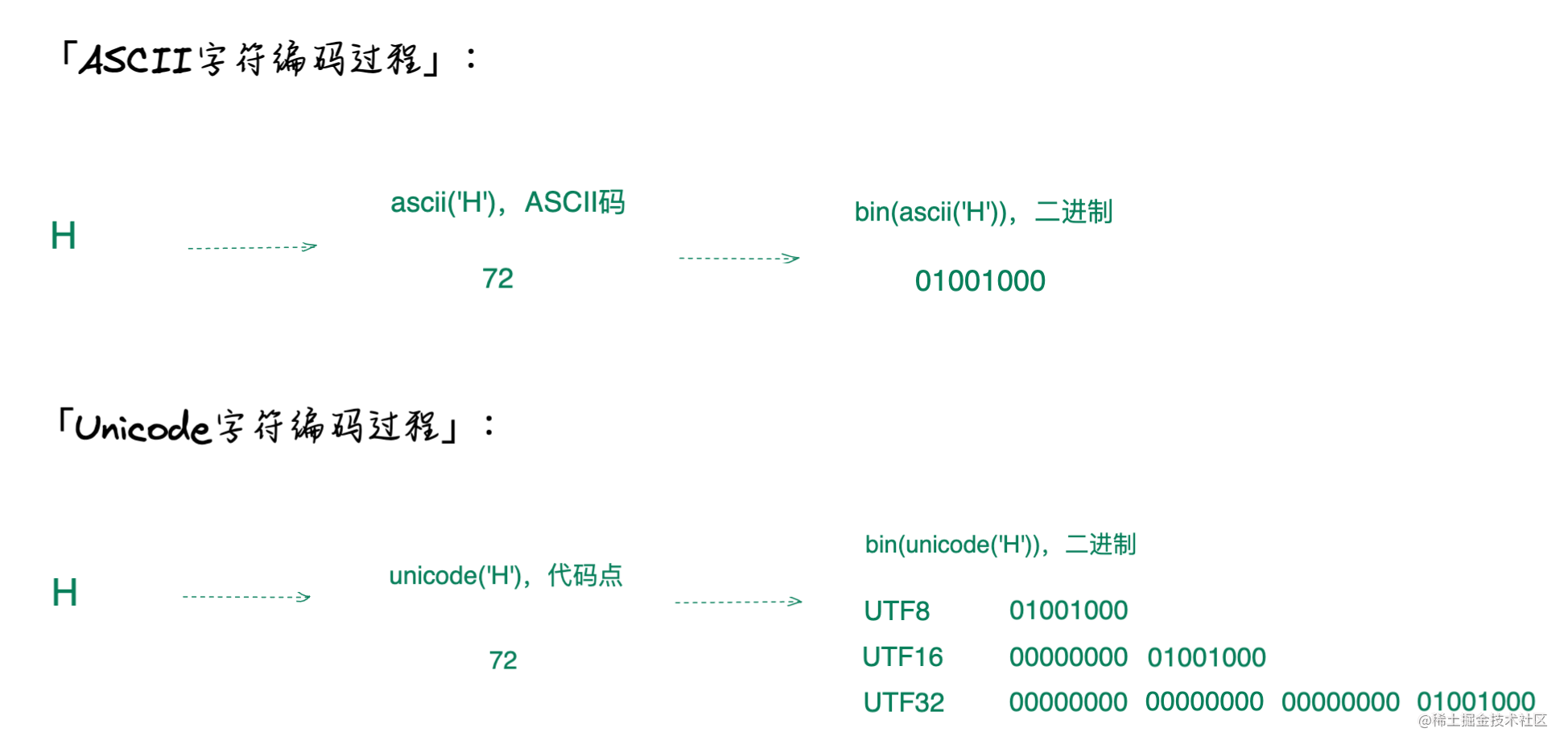
-
ASCII
字符编码过程:-
[1]
根据
字符
找到唯一映射的
ASCII码
,如
ascii('H') -> 72
-
[2]
根据
ASCII码
转换二进制进行存储,如
bin(ascii('H')) -> 0100 1000
-
-
Unicode
字符编码过程:-
[1]
根据
字符
找到唯一映射的
代码点(Code Point)
,如
unicode('H') -> 72
-
[2]
根据
代码点(Code Point)
转换二进制进行存储,如
bin(unicode('H')) -> 0100
,这里代码点的概念可以等同于ASCII的码值,
ASCII
是一次映射得到值,
Unicode
在此基础上还可以做组合之后映射。
-
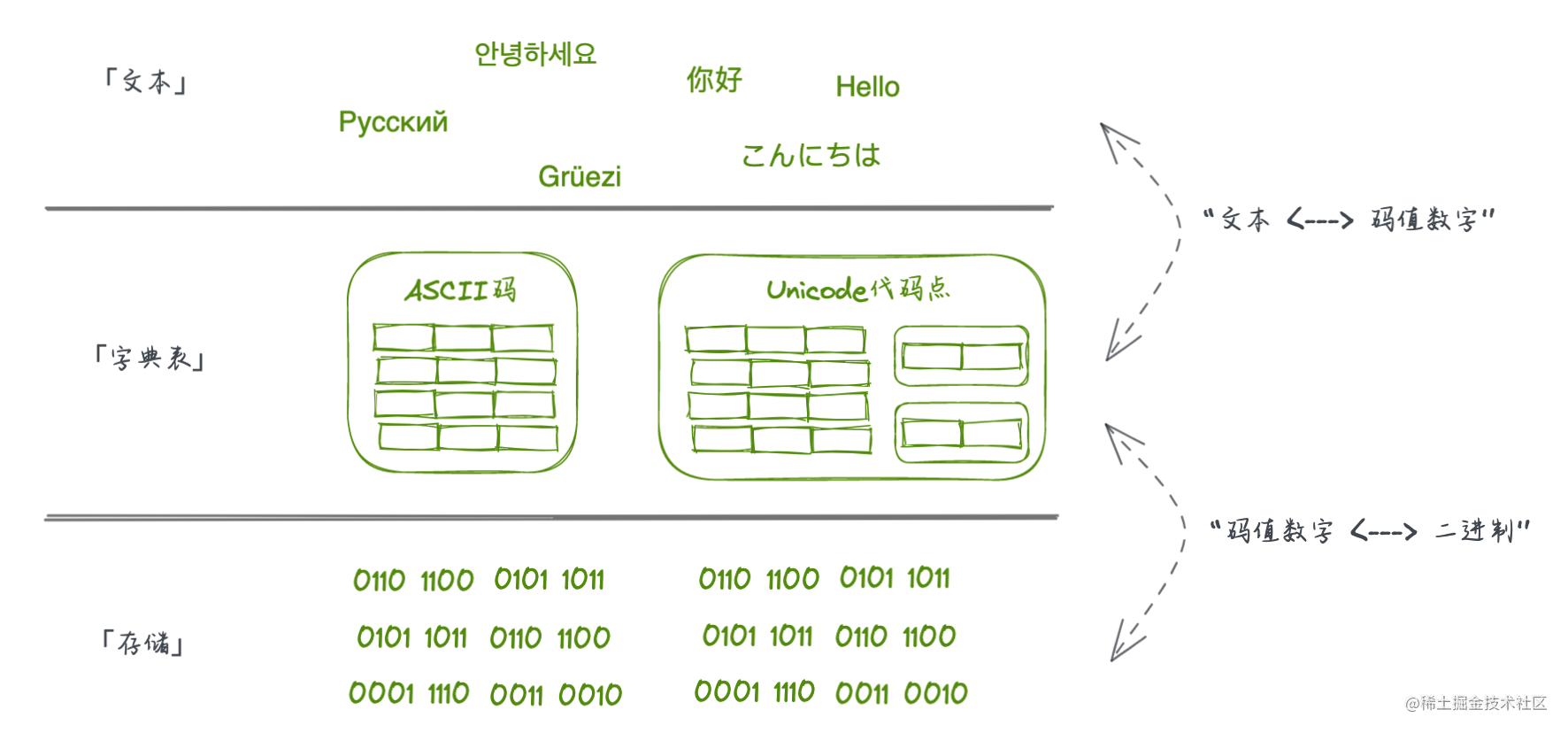
其实,原理是类似的,都需要预先做好一张
字典表
做映射,实际存储的时候存的是字典映射表中的数字的
二进制形式
而已。
Unicode
更胜一筹的地方在于扩展了字典表规模容纳了更多的字符表达差异进来,而且兼容了
ASCII码
已经定义的字典表直接进行了吸纳。
| 文本表达 | unicode编码表示 |
|---|---|
| ? |
|
| ? |
|
而且
Unicode
打破了之前
ASCII
编码“一对一”映射的编码逻辑,而是采用
代码点
的概念来做中间层转换,将
字典表映射
和
编码规则
进一步解耦,支持组合多个代码点成为新的字符表示。然而,这一切并不是没有代价的,表示容量越大就意味着需要更多的数字,而数字越大转换二进制的成本就越高,下面展开讲。
空间占用对比
| 编码 | 大小 | 支持语言 |
|---|---|---|
| ASCII | 1字节 | 英文 |
| Unicode | 2字节 | 所有语言 |
Unicode
相比
ASCII码
会占用更多空间。
-
ASCII码
的字典表词量有限,支持需要支持英文主流语言和符号等,最多只用一字节即可包括全部字符编码需求,且具备一个特点,就是字符数量等于字节数量,即每个字符都只占一字节,因此也就具备字符空间占用等长的特点。 -
Unicode
代码点映射数字远远大于ASCII码的127这个数字,2个字节空间可以支持16位的二进制存储,映射到代码点的十进制数字能够容纳65535个,这已经能够容纳非常庞大体量的文本映射表达能力了,因此
Unicode
一般使用2字节即可,生僻字或符号最多也不会超过4字节即可满足,而且基于很多代码点还可以通过组合形成更大的字符表达。代码点和ASCII码值本质上都是一个十进制的数字,因此范围越大,且还要组合更大范围,必然也需要更大的空间存储。
深入了解:MySQL的字符编码
我们基于
MySQL5.7
来深入了解
下MySQL
中字符集相关内容的约定、规则和支持,官方文档关于这部分内容的介绍,
Character Sets, Collations, Unicode
,
中文对照
字符集、对照规则
基础概念
先来认识下
MySQL
中我们创建库、表常用到的两个关键词,
character set
、
collate
:
| 关键词 | 含义 | 作用 | 支持配置级别 |
|---|---|---|---|
|
character set |
字符集 | 文本编码方式 |
服务器 数据库 表 列 |
|
collate |
校验、对照规则 |
文本对照的规则,用于对比一致性、差异性等,在 条件查询匹配 、 数据库防重幂校验 等都会用到 |
服务器 数据库 表 列 |
下面是一些
character set
、
collate
的特点:
-
「支持级别」
在
MySQL
中,字符集和对照规则有四个级别的默认设置:
服务器(Server)
,
数据库(database
),
表(table)
,
列(column)
;此外,也支持
SQL
级别的
字面量(literals)
编码、对照能力。 -
「规则关系」
不同层级之间采用“
最近原则
”进行覆盖,举例:若字段级别配置声明了编码和对照规则,则字段使用该规则,否则会使用就近的表一级配置,以此类推到数据库、服务器级别。
参数配置
下面来看下字符编码、对照规则的各级别配置的方式和参数配置:
| 级别 | 编码参数 | 对照参数 |
|---|---|---|
| 服务器(server) |
|
|
| 数据库(database) |
|
|
| 表(table) |
建表语句 Table… |
建表语句 Table… |
| 字段(column) |
建表语句 Column… |
建表语句 Column… |
| SQL字面量(literals) |
SQL中使用,如; |
同左 |
除此之外,还支持一些其他方式的编码干预影响策略,可以通过
show variables like '%character_set_%'
命令来查看和扩展,如存储编码可以和最终展示的编码方式可以进行转换或兼容,此处不做展开,感兴趣可以根据上方官网链接进行扩展尝试。
字符集库
字符集的支持
MySQL字符集库支持非常广泛,总的来说一般常用的字符集都是
Unicode
的子集,只有个别领域、足够小众的字符集才需要考虑兼容等棘手却又不太可能发生的场景问题,因此对于使用MySQL的用户来说,不太会存在这种“海纳百川,唯漏一斗”的尴尬。
字符集的选择
通过综上对字符编码的回顾和论述,我们能够明白一件事:选择什么样的字符集就意味着使用什么样的字符支持能力以及编码规则,所以我们在选择字符集的时候需要考虑的主要有:
-
[1]
Q:字符集是否能够支持业务存储的大部分文本?
一般来说国内大部分业务除了
汉字、英文、数字、符号
基本没有其他特别需要考虑的场景,因此只要支持以上文本编码即可。 -
[2]
Q:存储空间的消耗如何?
只有全高位的字符映射理论上会相对占用很多存储空间,否则不需要过分关心,按照字符编码必不可少的“沉默成本”来对待即可。
-
[3]
Q:性能如何?
可能你会疑惑了,为什么还有性能问题呢?
匹配查询、内容对比
是一个高频场景功能,它受到内容存储形态的影响,尤其是面对大数据体量的样本匹配、对比会有很大影响,这个后面我们会展开讲到。
一般来说,
utf8及其扩展字符集
是最常用的,常见的家族表列举如下:
| 字符集 | 描述 | 每个字符占用空间 | 基本多语言平面(BMP)字符、补充字符的支持 |
|---|---|---|---|
| utf8 |
Unicode字符集的UTF-8编码,别名 |
1~3字节 | 仅支持 BMP 字符 |
| utf8mb4 | Unicode字符集的UTF-8编码 | 1~4字节 | 支持 |
| utf16 | Unicode字符集的UTF-16编码 | 2~4字节 | 支持 |
| utf32 | Unicode字符集的UTF-32编码 | 4字节 | 支持 |
如果你疑惑什么是
BMP
?可以参考
BMP(基本多语音平面)
的概念。
下面通过一个例子验证下,首先创建一张表,分别配置字段的字符编码
col_1
为
utf8mb4
、
col_2
为
utf8
,如下:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`col_1` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL,
`col_2` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
然后分别给两个字段插入“?”这个表情来看看:
小提示:
如果使用命令行交互,可以先执行如下命令保持连接会话使用
utf8mb4
编码进行数据传输避免不兼容,一般MySQL图形工具都默认支持。mysql> SET NAMES utf8mb4;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test (col_1) value ('?');
Query OK, 1 row affected (0.03 sec)
mysql> insert into test (col_2) value ("?");
ERROR 1366 (HY000): Incorrect string value: '\xF0\x9F\x98\x84' for column 'col_2' at row 1
显然
utf8
(即
utf8mb3
)对类似字符是不支持的,无法完成这种符号的编码存储和插入;而
utf8mb4
支持,虽然
utf16
、
utf32
也支持但是能看到它们的编码空间上存在一些“浪费”,所以在一般系统设计中对字符串字段存储选择
utf8mb4
是比较通用和推荐的。
元数据使用UTF-8字符集
MySQL
中的自身元数据选择使用
UTF-8
字符集来提供交互,这点不言而喻了,它能提供标准字符集范围,可以兼容所有子集,而且一般都是英文,绝对可以满足所有场景,没有后顾之优。
字符集的命名规则
参考
MySQL字符集命名规则
命名规则是按照”
encoding_feature_collate
“的结构来定位和区分的。
-
encoding
,即字符编码集,如
utf8
-
feature
,即字符特征,如
general
是通用的,
turkish
是面向土耳其语的 -
collate
,即对比校验规则,如是否区分大小写、重音符号是否敏感
| 命名后缀 | 含义 | 举例 |
|---|---|---|
|
Accent-insensitive |
变音不敏感,、 认为是相同字符 |
|
Accent-sensitive |
变音敏感,、 认为是不同字符 |
|
Case-insensitive |
大小写不敏感,、 认为是相同字符 |
|
Case-sensitive |
大小写敏感,、 认为是不同字符 |
|
Binary | 基于二进制判断 |
下面是一些命名后缀的特点:
-
「规则关系」
如果没有声明重音规则后缀,则按照大小写规则后缀进行统一,
_ai
对齐
ci
,
_as
对齐
cs
,即
ci
即不区分大小写,并且忽略变音,
cs
则即区分大小写,也区分变音。 -
「二进制对照」
bin
区别于以上,是独立的一种对照规则。
| 分类 | 字段类型 | 对比规则 |
|---|---|---|
| 二进制字符串 | binary、varbinary、blob | 基于数字字节值进行排序、对比 |
| 非二进制字符串 | char、varchar、text、longtext |
基于数字字节值进行排序、对比; 基于字符序列、多序列进行排序、对比 |
字符集的对照规则
下面用例子验证下不同对照规则。首先创建一张表,让字段编码类型和校验格式分别能够支持
*_ci
,
*_cs
,
*_bin
,如下:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`col_1` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin,
`col_2` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci,
`col_3` varchar(50) CHARACTER SET latin7 COLLATE latin7_general_cs,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1
插入两条大小写数据,方便验证。
mysql> insert into test (col_1,col_2,col_3) value ('A','A','A');
Query OK, 1 row affected (0.03 sec)
mysql> insert into test (col_1,col_2,col_3) value ('a','a','a');
Query OK, 1 row affected (0.03 sec)
mysql> select * from test;
+----+-------+-------+-------+
| id | col_1 | col_2 | col_3 |
+----+-------+-------+-------+
| 1 | A | A | A |
| 2 | a | a | a |
+----+-------+-------+-------+
2 rows in set (0.00 sec)
分别对三个不同字符编码的字段用同一个条件进行查询,验证如下:
-- utf8mb4_bin
mysql> SELECT * from test where col_1= 'A';
+----+-------+-------+-------+
| id | col_1 | col_2 | col_3 |
+----+-------+-------+-------+
| 1 | A | A | A |
+----+-------+-------+-------+
1 row in set (0.00 sec)
-- utf8mb4_general_ci
mysql> SELECT * from test where col_2= 'A';
+----+-------+-------+-------+
| id | col_1 | col_2 | col_3 |
+----+-------+-------+-------+
| 1 | A | A | A |
| 2 | a | a | a |
+----+-------+-------+-------+
2 rows in set (0.01 sec)
-- latin7_general_cs
mysql> SELECT * from test where col_3= 'A';
+----+-------+-------+-------+
| id | col_1 | col_2 | col_3 |
+----+-------+-------+-------+
| 1 | A | A | A |
+----+-------+-------+-------+
1 row in set (0.00 sec)
将结果汇总如下:
-
*_ci
是大小写不敏感的,无论输入
a
还是
A
,都会把
a
、
A
数据查询出来 -
*_cs
是大小写敏感的,输入
a
就匹配
a
,输入
A
就匹配
A
-
*_bin
是大小写敏感的,输入
a
就匹配
a
,输入
A
就匹配
A
二进制与字符串的对照差异
最后再来对比下
二进制存储
和
字符串存储
的区别,再来创建一张表,分别将字段设置为
二进制
、
字符串
格式:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`col_1` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin,
`col_2` blob COLLATE `binary`,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1
插入数据:
mysql> insert into test (col_1,col_2) value ('A','A');
Query OK, 1 row affected (0.02 sec)
mysql> insert into test (col_1,col_2) value ('a','a');
Query OK, 1 row affected (0.02 sec)
mysql> select * from test;
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | A | A |
| 2 | a | a |
+----+-------+-------+
2 rows in set (0.00 sec)
保持同一个条件完成查询:
-- varchar collate utf8mb4_bin
mysql> select * from test where col_1='A';
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | A | A |
+----+-------+-------+
1 row in set (0.00 sec)
-- blob collate binary
mysql> select * from test where col_2='A';
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | A | A |
+----+-------+-------+
1 row in set (0.00 sec)
得到结论是二者都是基于二进制做对照,是大小写敏感的,等同于
*_cs
后缀对照规则。下面我们通过SQL的字面量来强制改变下字符对照规则来看看:
-- varchar collate utf8mb4_general_ci 使用大小写不敏感来查询
mysql> select * from test where col_1='A' collate utf8mb4_general_ci;
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | A | A |
| 2 | a | a |
+----+-------+-------+
2 rows in set (0.00 sec)
-- blob collate utf8mb4_general_ci 使用大小写不敏感来查询
mysql> select * from test where col_2='A' collate utf8mb4_general_ci;
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | A | A |
| 2 | a | a |
+----+-------+-------+
2 rows in set (0.00 sec)
可以看到传入
*_ci
后缀对照规则后,大小写不敏感了,可全部查询出来。
二进制存储
、
字符串存储
都支持对照规则的“
就近传入
”来影响最终查询的数据输出。
尾随空间处理“陷阱”
需要特别注意。对于非二进制的字符串编码,会默认存储所有的空格空间,但是在匹配对照时会剔除尾随空格。
先来插入测试数据,如下:
mysql> insert into test (col_1) value ('a');
Query OK, 1 row affected (0.02 sec)
mysql> insert into test (col_1) value ('a ');
Query OK, 1 row affected (0.04 sec)
mysql> insert into test (col_1) value (' a ');
Query OK, 1 row affected (0.02 sec)
mysql> select *,length(col_1) from test;
+----+-------+---------------+
| id | col_1 | length(col_1) |
+----+-------+---------------+
| 4 | a | 1 |
| 5 | a | 2 |
| 6 | a | 3 |
+----+-------+---------------+
3 rows in set (0.00 sec)
接着进行查询,仔细观察检索条件和匹配结果,如下:
mysql> select * from test where col_1='a';
+----+-------+
| id | col_1 |
+----+-------+
| 4 | a |
| 5 | a |
+----+-------+
2 rows in set (0.00 sec)
mysql> select * from test where col_1='a ';
+----+-------+
| id | col_1 |
+----+-------+
| 4 | a |
| 5 | a |
+----+-------+
2 rows in set (0.00 sec)
mysql> select * from test where col_1=' a';
+----+-------+
| id | col_1 |
+----+-------+
| 6 | a |
+----+-------+
1 row in set (0.00 sec)
mysql> select * from test where col_1=' a ';
+----+-------+
| id | col_1 |
+----+-------+
| 6 | a |
+----+-------+
1 row in set (0.00 sec)
不难发现,匹配默认剔除了尾随空格;再来看看二进制存储的情况,先插入表数据:
mysql> insert into test(col_2) value('a');
Query OK, 1 row affected (0.03 sec)
mysql> insert into test(col_2) value('a ');
Query OK, 1 row affected (0.02 sec)
mysql> insert into test(col_2) value(' a ');
Query OK, 1 row affected (0.03 sec)
mysql> select *,length(col_2) from test;
+----+-------+-------+---------------+
| id | col_1 | col_2 | length(col_2) |
+----+-------+-------+---------------+
| 1 | NULL | a | 1 |
| 2 | NULL | a | 2 |
| 3 | NULL | a | 3 |
+----+-------+-------+---------------+
3 rows in set (0.00 sec)
再来查询下看看匹配结果:
mysql> select * from test where col_2 ='a';
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | NULL | a |
+----+-------+-------+
1 row in set (0.00 sec)
mysql> select * from test where col_2 ='a ';
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 2 | NULL | a |
+----+-------+-------+
1 row in set (0.00 sec)
mysql> select * from test where col_2 =' a ';
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 3 | NULL | a |
+----+-------+-------+
1 row in set (0.00 sec)
mysql> select * from test where col_2 =' a';
Empty set (0.00 sec)
二进制存储的字段才是真正“秉持Geek精神”的,存储什么就匹配什么,没有丝毫的默认夹带处理。
基于上述,要区分二者的区别,根据需要进行适配设计。
汇总结论:掌握规则,避免踩坑
综上,我们已经较为细致地回顾了
ASCII
、
Unicode
两种字符编码以及
MySQL
中对字符集、字符编码、对照规则的定义、分类、使用等,下面做个整体总结。
对存储的影响
直接用
SQL
来查看即可,
_utf8mb4
是相对来说空间性价比最高,覆盖字符表达映射最强的。
mysql> select length(_utf8mb3'H'),length(_utf8mb4'H'),length(_utf16'H'),length(_utf32'H');
+---------------------+---------------------+-------------------+-------------------+
| length(_utf8mb3'H') | length(_utf8mb4'H') | length(_utf16'H') | length(_utf32'H') |
+---------------------+---------------------+-------------------+-------------------+
| 1 | 1 | 2 | 4 |
+---------------------+---------------------+-------------------+-------------------+
1 row in set (0.00 sec)
对Unique Key的影响
创建一张表,配置两个字段分别为
*_ci
、
*_bin
并设置字段为唯一索引进行防重设计,如下:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`col_1` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin,
`col_2` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci,
PRIMARY KEY (`id`),
unique key (`col_1`),
unique key (`col_2`)
) ENGINE=InnoDB AUTO_INCREMENT=1
先插入底表数据,如下:
mysql> insert into test (col_1,col_2) value ('a','a');
Query OK, 1 row affected (0.02 sec)
mysql> select * from test;
+----+-------+-------+
| id | col_1 | col_2 |
+----+-------+-------+
| 1 | a | a |
+----+-------+-------+
1 row in set (0.00 sec)
下面进行大小写做撞库测试:
-- 先对大小写敏感的唯一索引进行插入测试,只要字符相同大小写不同就可以插入
mysql> insert into test (col_1) value ('a');
ERROR 1062 (23000): Duplicate entry 'a' for key 'col_1'
mysql> insert into test (col_1) value ('A');
Query OK, 1 row affected (0.02 sec)
-- 再对大小写不敏感的唯一索引进行插入测试,只要字符相同就不可以插入
mysql> insert into test (col_2) value ('a');
ERROR 1062 (23000): Duplicate entry 'a' for key 'col_2'
mysql> insert into test (col_2) value ('A');
ERROR 1062 (23000): Duplicate entry 'A' for key 'col_2'
结果一目了然,整理如下:
| 分类 | 防重效果 | 业务场景 |
|---|---|---|
| 区分大小写 | 只要字符相同大小写不同就可以插入 | 适合字符维度+大小写维度的联合防重,不会误杀,能多支持一些信息填入 |
| 不区分大小写 | 只要字符相同就不可以插入 | 适合字符维度不区分大小写的防重,严格准入 |
最后建议大家,使用数据库的
unique key
一定推荐使用纯数字来进行,比如你的订单号、业务流水号等等,减少因为字符多样性带来的解释成本,不给差异留口子和存在空间,如果非要在使用字符串类型尽量保持统一大小写,不要再让重音(四种声调,甚至更多)、大小写(两种维度)等混淆数据,给系统带来不稳定的“坏味道”设计。
亲爱的朋友,感谢你读到最后,希望本文对你有帮助~?
欢迎
点赞、收藏、关注
一键三连支持~❤️我会继续坚持输出高质量文章分享~?