直接干货
MySQL从5.7版本开始,引入了JSON类型字段,这使我们可以在MySQL数据库中存储JSON格式的数据,并保留其对象格式,再也不用转成字符串类型保存了,减少了许多字符串类型和对象类型之间的转换步骤。而同时也会衍生出,查询时如何筛选出与JSON字段内容相匹配的数据问题,那么接下来,我们就看看面对不同格式的JSON数据,都有哪些查询匹配方式。
数据准备
数据库结构
– 创建表
CREATE TABLE `t_json_demo` (
`f_id` INT NOT NULL AUTO_INCREMENT,
`f_arrays` JSON NULL,
`f_object` JSON NULL,
PRIMARY KEY (`f_id`))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4;
-- 插入模拟数据
insert into t_json_demo (f_arrays, f_object) values
(JSON_ARRAY("1", "2", "3", "4"), JSON_OBJECT("name", "Anna", "age", 16)),
(JSON_ARRAY("2", "4", "5", "6"), JSON_OBJECT("name", "Bob", "age", 17)),
(JSON_ARRAY("9", "6"), JSON_OBJECT("name", "Candy", "age", 18)),
(JSON_ARRAY("11", "22", "33", 'Elden "Lord"'), JSON_OBJECT("name", "Davied", "age", 20)),
(JSON_ARRAY("99"), JSON_OBJECT("name", "Eric", "age", 19));
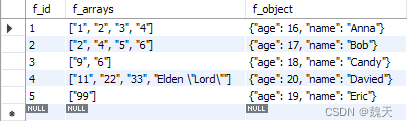
数据库表和数据都已经准备好了,分别是数组类型的JSON和对象类型的JSON
下面就针对这两种数据类型,做查询筛选操作
1. JSON_EXTRACT(column, path)
左侧参数column是列名,右侧参数path是 JSON 路径(字符串文字)
数组类型JSON查询:
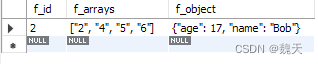
select * from t_json_demo where JSON_EXTRACT(f_arrays, '$[0]') = '1';
查询结果为:
2. column->path 和 column->>path
这是一种写法增强,用法与JSON_EXTRACT(column, path)一致 column->path 相当于
JSON_EXTRACT(column, path),其查询结果存在引号和转义 column->>path 则相当于
JSON_UNQUOTE(JSON_EXTRACT(column, path)),也相当于
JSON_UNQUOTE(column->path),查询结果中去除了引号和其转义
数组类型JSON查询:
select * from t_json_demo where f_arrays -> '$[1]' = '22';
查询结果为:

对象类型JSON查询:
select * from t_json_demo where f_object -> '$.age' > 18;
查询结果为:

上面我们说到column->path查询结果会存在转义的情况,那么是不是column->>path这种方式就不会转义了呢?
下面执行两条查询语句对比一下
select f_arrays -> '$[3]' from t_json_demo;

select f_arrays ->> '$[3]' from t_json_demo;

由此可见两种查询的区别,如果是需要将查询出结果导出到Excel文件的需求场景,那么肯定不希望查询的结果中存在转义字符,则可以使用第二种写法。
好的,JSON字段的匹配查询就先说到这。。。
当然,除了我说的这几种方式之外,还有许多其他的函数匹配,像JSON_CONTAINS(),还有JSON_SEARCH(),以及在MySQL 8.0.21中引入的JSON_VALUE()等,这些就不一一详述了,如果有疑问或者是更好的建议,欢迎评论留言。
如果觉得不错,不妨点赞支持一下!!
示例:

mybatis-plus
List<User> list = userMapper.selectList(new QueryWrapper<User>()
.eq("name->'$.en-US'", userName)
);
如果是xml文件
name -> "$.\"#{param.lang}\"" LIKE concat("%",#{param.name},"%")