《Speech and Language Processing》读书笔记——语法规则及其解析
1.摘要
本章主要介绍了:
- PCFG(概率上下文无关语法)
- probabilistic CKY(基于概率上下文无关语法的CKY算法)
- PCFG存在的问题
- PCFG的改进
- Probabilistic lexicalized CFGs(词汇化上下文无关语法)
- 语法剖析树的评价标准
2.PCFG
其基本原理就是,结合上下文无关文法(CFG)中最左派生规则(left-most derivations)和不同的Rules概率,计算所有可能的树结构的概率,取最大值对应的树作为该句子的句法分析结果。
对于 PCFG 中的 CFG 部分, 一般是由领域相关的专家给出的, 例如英语专家规定英语的 CFG. 而PCFG 中的 p 是从语料中统计而来. 运用最大似然估计, 可以有:
P
(
X
−
>
Y
)
=
c
o
u
n
t
(
X
−
>
Y
)
/
c
o
u
n
t
(
X
)
P(X -> Y) = count(X->Y)/count(X)
P
(
X
−
>
Y
)
=
c
o
u
n
t
(
X
−
>
Y
)
/
c
o
u
n
t
(
X
)
注意到, 规则中包括终端词与非终端词两种元素. 在一个适当规模的语料中, 我们可以认为所有的非终端词都会出现, 但是认为所有的终端词都会出现却是不现实的(想一下我们常听到的那个美国农民日常使用的英语单词只有数千个, 而所有的英语单词却有数万个的情况). 当语料中没有出现, 而在我们的测试样本中却出现了少见的单词时, PCFG 会对所有的语法树都给出概率为0的估计, 这对 PCFG 的模型是一个致命的问题。
通常的补救措施是, 对语料中所有单词出现次数进行统计, 然后将出现频率少于 t 的所有单词都换成同一个 symbol. 在进行测试时, 先查找测试句子中的所有单词是否在句子中出现, 若没有出现, 则使用 symbol 代替. 通过这种方法, 可以避免 PCFG 模型给出概率为0 的估计, 同时也不会损失太多的信息。
3.probabilistic CKY
CKY 是一种 DP 算法, 其要求PCFG 中的R 必须符合 Chromsky Normal Form, 即:
{
X
→
Y
1
Y
2
}
o
r
{
X
→
N
}
\{X\to Y_1 Y_2\} or\{ X\to N\}
{
X
→
Y
1
Y
2
}
o
r
{
X
→
N
}
,其中Y属于非终结符,N属于非终结符。
满足了这种形式后, 可以定义CKY的最优子结构为 π(i, j, X), 其表示以 X 为根部非终端词, 涵盖句子中第 i 个到第 j 个位置之间词串的语法树的概率. 如下所示
在这样的定义下, 我们的目标就是寻找到一棵语法树 t,使得 π(0, n, S)最大。
DP 算法的一个特点是问题的解是贪婪的, 一个较大问题的解必然依赖于一个较小问题的解, DP 算法按照 bottom-up 的方式, 从解决较小规模的问题开始, 逐渐构建对于目标问题的解.Probabilistic CKY 所定义的递推式算法如下:

其具体形式如下线图表格所示,先计算对角线的所有概率,再依次从左至右,从下往上计算计算,直到计算出右上角的π(0, 5, S),即可构成一个线图表,据此便可建立一个对应句子的语法剖析树。

4.PCFG存在的问题
PCFG主要存在如下两方面的问题:
-
不良的独立性假设:CFG规则对概率施加了独立性假设,导致对整个解析树的结构依赖关系建模不佳。
举个栗子:
在PCFG中计算概率时,只看某个词序列的词性(N…)或者短语形式(NP…),无法从整个句子的主语、宾语上来进行区分,所以其无法模拟结构依赖性。
然而在结构方面不同的结构上该词汇出现的概率是不同的,例如主体位置的NP往往是代词,而对象位置的NP往往具有完整的词汇(非句子)形式。
因此NP展开为代词和展开为实词性名词或名词短语的概率是由其所处的结构位置(主语、宾语)决定的,但是前面的PCFG是无法表达这种结构依赖性概率。
- 缺乏词汇条件作用:CFG规则不模拟关于特定单词的句法事实,导致子分类歧义、介词附加和协调结构歧义问题。
5.PCFG的改进
对于问题1我们可以采取将终结符分割成多种形式,对于问题2我们可以采取Probabilistic lexicalized CFGs,即概率词汇化CFG。
-
分割非终结符:
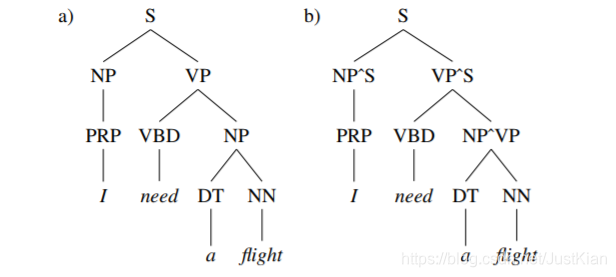
例如,我们可以将NP分成两种形式:①主语上的NP ②宾语上的NP
要如何实现这种结构形式呢,我们可以采取
父节点标注
。具体形式如下图所示:(图a为传统PCFG、图b为父节点标注PCFG)
-
Probabilistic lexicalized CFGs
其结构如下图所示:

其实际上就是将每个句法同一个词汇中心(lexical head)关联起来,每个非终结符号都要标上一个单词作为它的词汇中心。
6.语法剖析树的评价标准
给定测试集标准解析,如果与在标准解析Cr中存在具有相同起点,终点和非终结符号的成分,则假设解析中的给定成分s被标记为“正确”。

除了recall和precession ,我们也可以用f-measure来表示:
f
1
=
2
⋅
P
⋅
R
P
+
R
f_1=\frac{2\cdot P\cdot R}{P+R}
f
1
=
P
+
R
2
⋅
P
⋅
R
另外,还可通过交叉括号的数量来判断好坏。交叉括号:例如树库中某一句法括号表示为((A B) C),但在候选剖析中却表示为(A (B C)),这便算一个括号交叉。