近期因进行项目全链路压测,需要对服务部分接口进行业务日志提取,用来做参数化测试数据。据了解,服务日志存储于elk日志平台中。于是为了避免每次手工提取费时费事,且每次不能批量提取大量日志,决定使用脚本实现自动提取,并保存至特定目录文件中。
前提:
- elk日志平台地址
- 查询索引名
- 查询条件
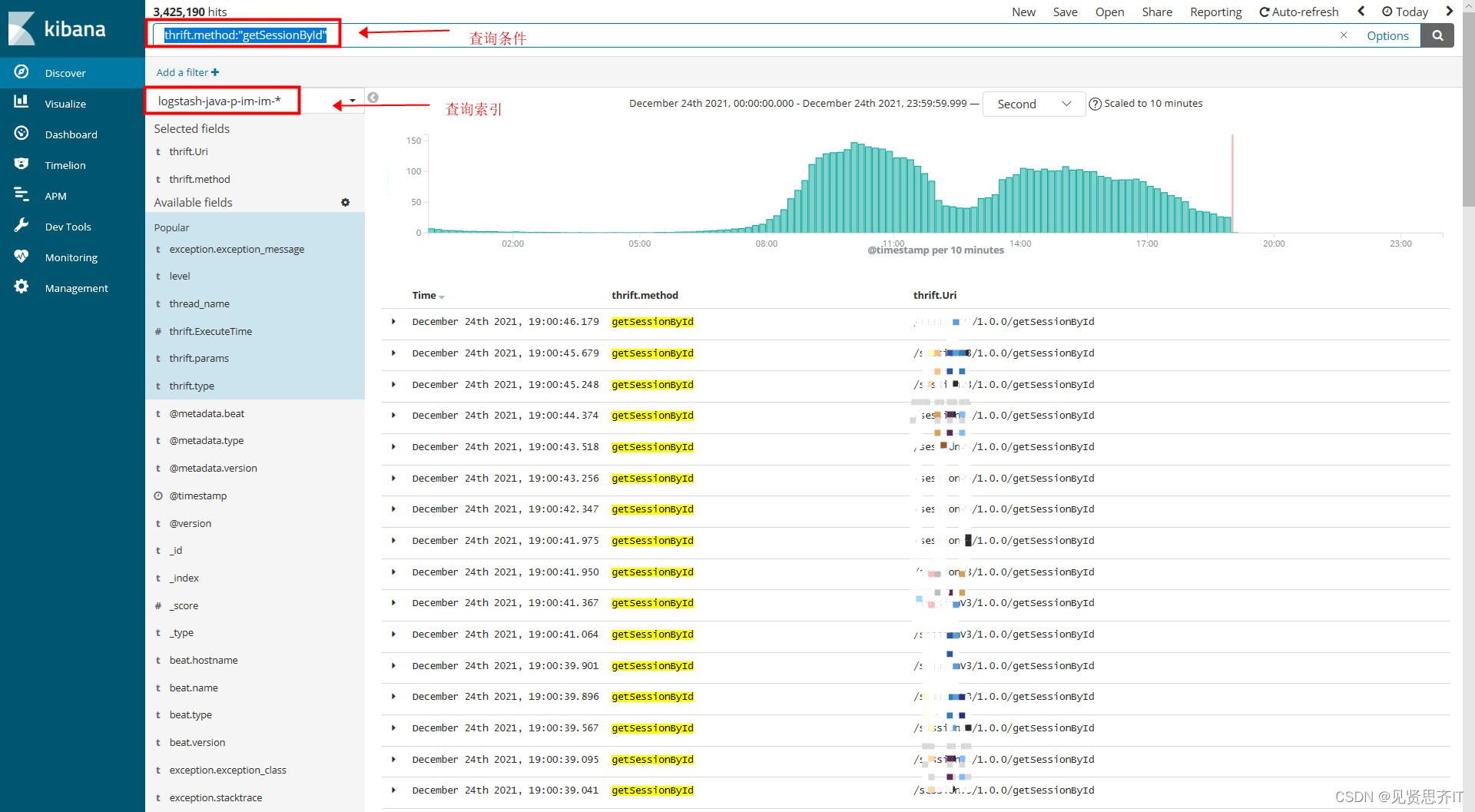
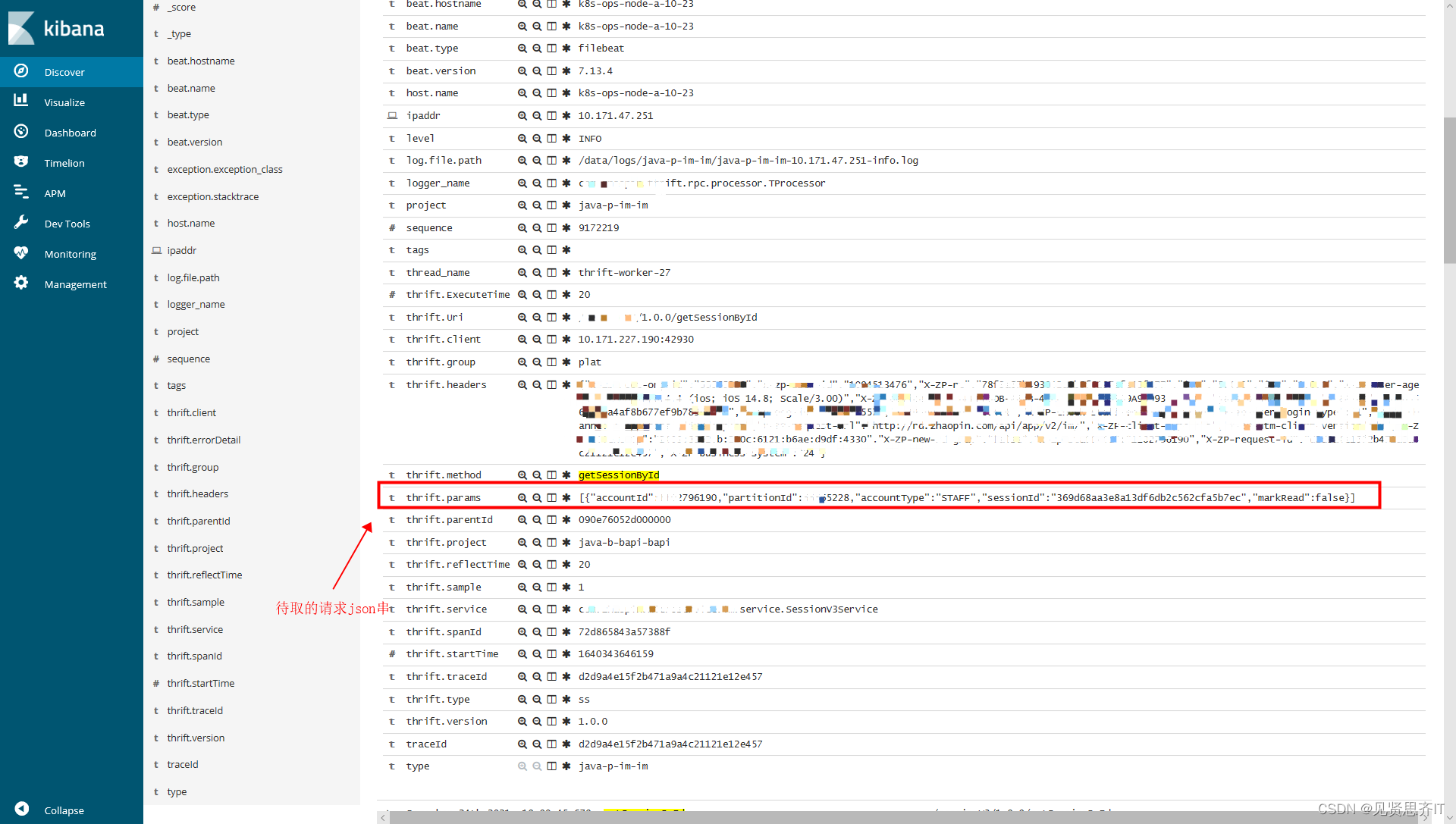
以下为具体java代码,供参考:
ImSearchExtractData类
package com.Fulllink.imsearch;
import com.Fulllink.utils.HttpGetTest;
import com.Fulllink.utils.IsOverdueByAt;
import com.Fulllink.utils.WriteFile;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.UnsupportedEncodingException;
/**
*
* 接口:获取 im数据
* 从ELK平台中根据索引及查询条件提取日志信息
* @Author: jiajun.du
* @Date: 2021/11/6 10:37
*/
public class ImSearchExtractData {
Logger logger = LoggerFactory.getLogger(ImSearchExtractData.class);
HttpGetTest httpGetTest = new HttpGetTest();
IsOverdueByAt isOverdueByAt = new IsOverdueByAt();
WriteFile writeFile = new WriteFile();
/**
* metaDataSource 提取日志数据
* @param queryCondition 查询过滤条件
* @param expctLogNum 提取日志数量
* @param index 查询索引
* @return
*/
public Boolean metaDataSource(String filePath,String index,String queryCondition,int expctLogNum,String methodName){
//int actualLogNum = 0; //实际的提取的条数
final int indexStart = 1; //起始查询的索引(常量)
final int size = 100; //每次请求接口查询100条数据(常量)
int fetchCount = expctLogNum/size;//访问ELK接口次数,用于计算实际查询的条数
File fileName = new File(filePath);
String indexStr = index.trim();
int nums = 0;
String queryConditionStr = queryCondition;
String thrift_params = null;
String thrift_at = null;
Long atTime = null;
String accessTokenEndTime = null;
JSONObject jsonObjectAt = null;
if(indexStr!=null && indexStr!="" && queryConditionStr !=null && queryConditionStr!="" && expctLogNum >0 ){
for(int m = 0; m < fetchCount; m++){
//组装URL请求串
String url = "http://xx-xx-elk.zpidc.com/" + index;
String passportUrl ="http://p-xx-xx.zpidc.com/xx-service/xx/getUserTokenByAt?at=";
String param = queryConditionStr + "&from=" + indexStart*m*size + "&size=" + size + "&sort=@timestamp:desc";
try {
JSONObject jsonObject = httpGetTest.doGet(url,param);//调用提取数据url-每次取100条
if(jsonObject.getJSONObject("hits")!=null && jsonObject.getJSONObject("hits").getJSONArray("hits")!=null) {
JSONArray jsonArray = jsonObject.getJSONObject("hits").getJSONArray("hits");
StringBuffer sb = new StringBuffer();
for (int i = 0; i < jsonArray.size(); i++) {
if (jsonArray.getJSONObject(i).getJSONObject("_source").size() >= 1) {
if(methodName.equals("getTags")){
thrift_params = jsonArray.getJSONObject(i).getJSONObject("_source").getString("thrift.Params");
sb.append("\"" + thrift_params + "\""+ "\r\n");//post请求 换行
nums++;
}else {
thrift_at = jsonArray.getJSONObject(i).getJSONObject("_source").getString("thrift.Headers_.x-zp-at");
thrift_params = jsonArray.getJSONObject(i).getJSONObject("_source").getString("thrift.Body");
jsonObjectAt = httpGetTest.doGet(passportUrl, thrift_at);
if (jsonObjectAt.getJSONObject("data") != null) {
try {
accessTokenEndTime = jsonObjectAt.getJSONObject("data").getString("accessTokenEndTime");
if (accessTokenEndTime != null) {
atTime = Long.parseLong(accessTokenEndTime);
if (atTime != null && isOverdueByAt.validateByAt(atTime)) {//token失效日期大于2天
thrift_params = StringUtils.replace(thrift_params, "\"", "\"\"");
sb.append("\"" + thrift_params + "\"" + "," + thrift_at + "\r\n");//post请求 换行
nums++;
}
}
} catch (NumberFormatException e) {
e.printStackTrace();
}
}
}
}
}
writeFile.writeFile(sb.toString(),fileName);//每100条写入一次文件
sb.delete(0,sb.length());
System.out.println(methodName+"接口写入记录:"+ nums+"条!");
}
//logger.info("*******************写入记录{%d}条!",fetchCount * size);
} catch (Exception e) {
logger.error("写入文件异常!");
e.printStackTrace();
return false;
}
}
}
return true;
}
public static void main(String [] args){
ImSearchExtractData extractData = new ImSearchExtractData();
//查询条件-接口名称
String [] methodNames ={"method1","method2","method3"};
String index = null;
String queryConditionHead = null;
String query = null;
for (int t = 0; t<methodNames.length; t++){
String filePath = "D:\\FullLinkData\\imsearch\\"+methodNames[t]+".csv";//生成文件
if(methodNames[t].equals("getTags")){
index = "logstash-java-p-xx-xx-*";//查询索引
queryConditionHead = "/_search?_source=thrift.Params&q=thrift.Uri:";//查询条件部分
try {
query = queryConditionHead+java.net.URLEncoder.encode("\"/resumetag/tagService/"+methodNames[t]+"\"", "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}else {
index = "logstash-java-b-xx-xx-*";//查询索引
queryConditionHead = "/_search?_source=thrift.Headers_.x-zp-at,thrift.Body&q=thrift.method:";//查询条件部分
try {
query = queryConditionHead+java.net.URLEncoder.encode(methodNames[t], "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
int expctLogNum = 500;//提取条数,elk当前限制单次最多取10000条记录
for(int k = 0; k < 1 ; k++){
extractData.metaDataSource(filePath,index,query,expctLogNum,methodNames[t]);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}HttpGetTest类
package com.Fulllink.utils;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* @Author: jiajun.du
* @Date: 2021/11/23 15:53
*/
public class HttpGetTest {
Logger logger = LoggerFactory.getLogger(HttpGetTest.class);
/**
* get请求
* @param url
* @return
* @throws Exception
*/
public JSONObject doGet(String url, String param) throws Exception{
CloseableHttpClient httpClient = null;
CloseableHttpResponse httpResponse =null;
String strResult = "";
try {
httpClient = HttpClients.createDefault();//创建一个httpClient实例
org.apache.http.client.methods.HttpGet httpGet =new org.apache.http.client.methods.HttpGet(url+param);//创建httpGet远程连接实例
// 设置请求头信息
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(60000).//连接主机服务器时间
setConnectionRequestTimeout(60000).//请求超时时间
setSocketTimeout(60000).//数据读取超时时间
build();
httpGet.setConfig(requestConfig);//为httpGet实例设置配置信息
httpResponse = httpClient.execute(httpGet);//通过get请求得到返回对象
//发送请求成功并得到响应
if(httpResponse.getStatusLine().getStatusCode()==200){
strResult = EntityUtils.toString(httpResponse.getEntity());
JSONObject resultJsonObject = JSONObject.parseObject(strResult);//获取请求返回结果
return resultJsonObject;
}else{
logger.error("请求{%s}失败,状态码为{%d}",url,httpResponse.getStatusLine().getStatusCode());
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException i){
i.printStackTrace();
logger.error("IOException异常:{%s}",i.getMessage());
} finally {
if(httpResponse!=null){
try {
httpResponse.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(httpClient!=null){
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
}
WriteFile 类
package com.Fulllink.utils;
import java.io.*;
/**
* @Author: jiajun.du
* @Date: 2021/11/30 14:50
*/
public class WriteFile {
/**
* 读取数据写入指定文件
* @param str
* @param fileName
*/
public void writeFile(String str, File fileName){
if((str!=null || !str.trim().equals("")) && fileName!=null ) {
try {
FileOutputStream fos = new FileOutputStream(fileName,true);
Writer w = new OutputStreamWriter(fos,"UTF-8");
try {
str = str.replaceAll("%(?![0-9a-fA-F]{2})", "%25");
str = str.replaceAll("\\+", "%2B");
w.write(java.net.URLDecoder.decode(str, "UTF-8"));
w.flush();
w.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
}
IsOverdueByAt 类
package com.Fulllink.utils;
/**
* 判断时间戳是否过期(at)
* @Author: jiajun.du
* @Date: 2021/11/23 11:14
*/
public class IsOverdueByAt {
public Boolean validateByAt(Long at){
if(at!=null){
long days = 0;
Long todayTs = System.currentTimeMillis(); // 当前时间戳
days = (at-todayTs)/(24*60*60*1000);
if(days>=2){
return true;
}else return false;
}
return null;
}
}最后生成参数化文件
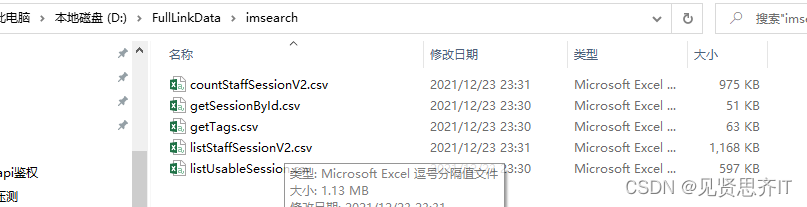

版权声明:本文为junior77原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。