线程案例
JavaEE & 线程案例 & 单例模式 and 阻塞队列
- 单例模式是一种很经典的设计模式~
1. 设计模式
-
下棋有棋谱
-
弹奏有乐谱
-
而计算机设计模式,是前人总结下来的一些代码编写套路
- 按照这些模式,你代码写得也不会太差~
- 兜底~
-
主要是因为大佬的代码和其他人的代码能力差距实在是大
- 大佬们总结了这些模式帮助我们写好代码~
设计模式有很多种(不是23种~)
-
之前有个大佬写了本书,讨论了23种设计模式
- 而这23 种,只是那位大佬精心选了这23种~
-
(1条消息) 设计模式23模式介绍_哪 吒的博客-CSDN博客
- 有一些博主有对其进行讨论研究~
-
在现阶段,主要要掌握的有两种:
-
单例模式
- 本章重点
-
工厂模式
- 下一章讲~
-
2. 单例模式
2.1 单例的含义
-
单例
==> single instance ==> 单个实例对象- 也就是说,单例模式通过一些Java语法,保证某个类,只能有一个实例,即只能new一个对象~
-
就有一些场合,限制一个类只能有一个对象,而不是多个对象去分担资源。
-
这些限制是符合“初心写代码”,“针对性写代码”的~
-
而单例模式有多种写法:
-
饿汉模式(急迫)
-
懒汉模式(从容)
- 在计算机,懒是个褒义词
- 因为可以节省开销
- …
-
-
就比如说,你打开一个1000页的pdf
-
计算机是直接加载1000页
- 你也没法1000页一起看,也不一定要看1000页
- 加载1000页需要大量时间和空间
-
还是每次只加载你看到的1-2页呢~
- 看似只加载1-2页,你要去看其他页的时候,再给你加载~
- 读的次数多,但是开销少~
-
计算机是直接加载1000页
-
没错
-
前者就是饿汉模式
,很着急的将所有东西加载 -
后者就是懒汉模式
,非必要不加载,你给什么任务我就只做什么任务~- 绝对不多干一点活,非必要不做~
-
2.2 初步代码设计
2.2.1 饿汉模式
class Singleton {
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
private Singleton() {
}
}
public class Test {
public static void main(String[] args) {
Singleton s1 = Singleton.getInstance();
//Singleton s2 = new Singleton();报错~
}
}
-
在类加载的时候就急切地实例一个对象了
-
这个很特殊,相当于静态代码块执行实例操作
-
这个构造方法加载好,是可以在静态代码块内执行的~
-
而这个单例的建立,必然是线程启动前,所以有绝对的线程安全~
-
-
特殊的语法场景,该属性是类的属性(类对象上),jvm中,类对象只有一份~
-
那么instance就仅此一份了~
-
一方面保证单例的特性—-“初心” + “针对性”
-
用Java语法去禁止外部实例
-
这个直接编译都通不过
-
这要比抛异常方便且有效,因为抛异常在这里就有点闷声禁止
-
-
要打破单例,就必须通过“反射”
-
反射特别不常规!是为了特定的特殊场景,【破例】去访问private
*
比如说,玩我的世界的时候,常常有玩家说“这是我最后一次开创造”
-
可以利用枚举类型,枚举的private属性,反射是访问不到的
-
完美的单例
-
-
-
通过类名点的方式,访问这个单例
-
get方法~
2.2.2 懒汉模式
class SingletonLazy {
private static SingletonLazy singletonLazy = null;
public static SingletonLazy getSingletonLazy() {
if(singletonLazy == null) {
singletonLazy = new SingletonLazy();
}
return singletonLazy;
}
private SingletonLazy() {
}
}
public class Test {
public static void main(String[] args) {
SingletonLazy s1 = SingletonLazy.getSingletonLazy();
SingletonLazy s2 = SingletonLazy.getSingletonLazy();
System.out.println(s1 == s2);
}
}
-
与饿汉不同的是
-
类加载的时候,并没有实例单例出来,置为初始值null
-
在【需要的时候】,即get方法被调用的时候
-
判断单例是否被实例(是否为null)
-
未被实例则立马就实例一个
-
-
2.3 线程安全角度分析
2.3.1 对于饿汉模式
-
饿汉模式的单例,绝对是在线程启动之前,所以这一修改操作,不存在线程安全问题
-
读操作,本身就没有线程安全问题
-
所以目前我们认为线程是安全的
-
自己写的时候线程不安全还是会不安全
-
2.3.2 对于懒汉模式
-
对于懒汉模式而言,单例第一次实例是在第一次get的时候
-
这个时候多条线程可能已经启动了
-
对于单例未被实例的情况下(为null)
-
就会进行第一次实例~
-
-
而这里就会出现一个很重要的问题!
-
回忆一波,这个场景很熟悉~
-
指令重排序
在这里插入图片描述
-
指令重排序是一方面原因,可能导致,一些线程get到的单例对象,是没有执行构造方法的【毛坯房】
-
是因为第3执行后,别的线程判定是否有单例的时候,判定为已有,直接return了~
-
-
原子性不受保证~

-
如图,这个操作可以分为这两步~
-
那就有以下这种极端情况~

- 只要该线程过了“if语句这一关”,那么就会导致,多new一个对象
-
总结,这两种本质上,就是这一段代码是不保证“原子性”的,所以,我只需要加锁,就可以解决两个问题~
首先,先提一下单例模式的重要性
-
在一个大工程中,一个核心的类,一个对象包含的内存数据可能是巨大的,比如100G以上~
-
这个类只需要一个单例就行了~
-
假设这个单例管理整个项目的加载的所有内存数据
-
那确实一个就够了
-
-
但是,由于线程不安全,即使是低概率事件而引发多new一次(100G -> 200G)
-
那就是个大事故了~
-
并且可能再极端一点,new了3个4个的…
-
2.4 处理懒汉模式线程不安全问题
-
法1:
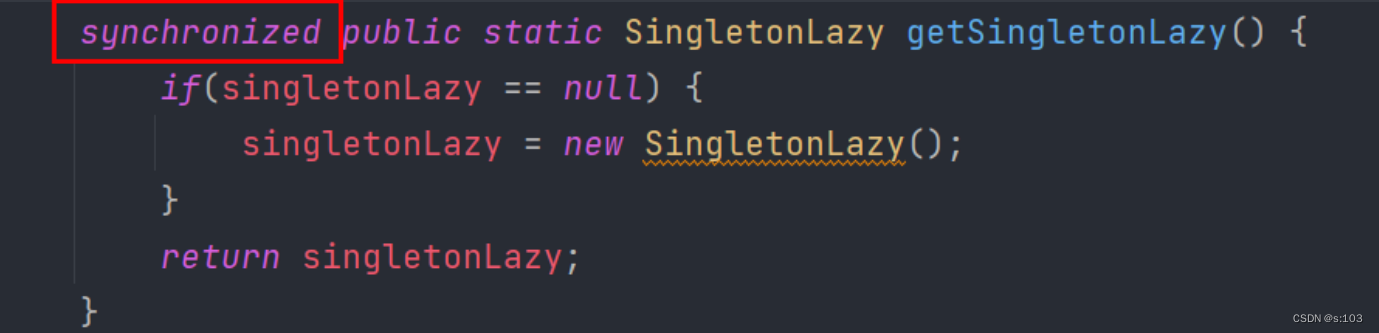
-
法2:
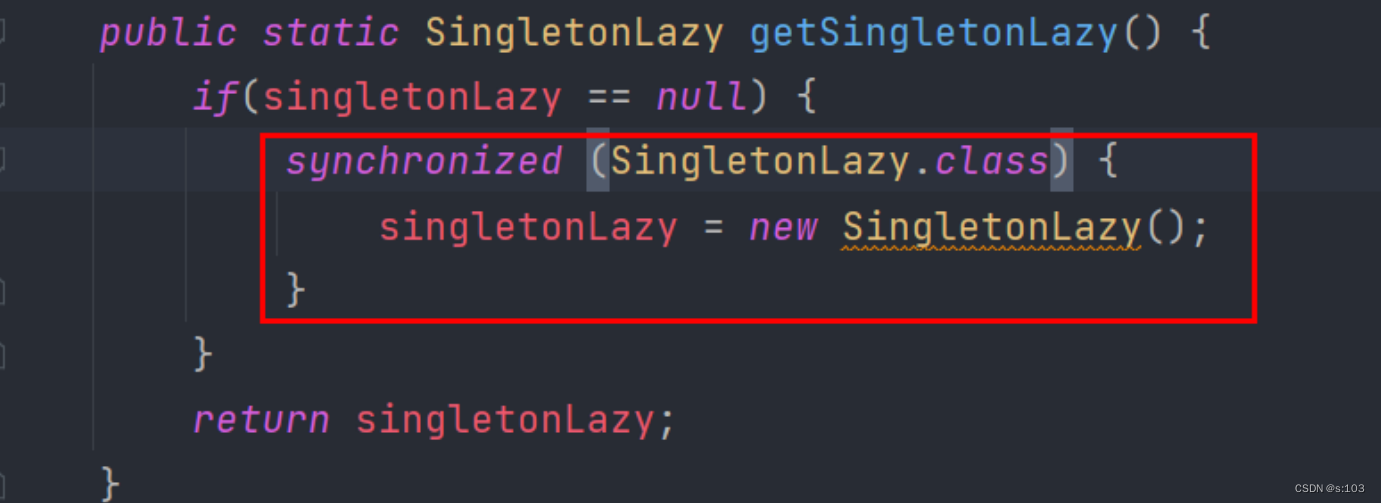
- 这个是错误的!
-
这只是解决指令重排序,但是并没有完全解决问题~
- 仍然有可能会出现两个线程同时过了“if大关”~
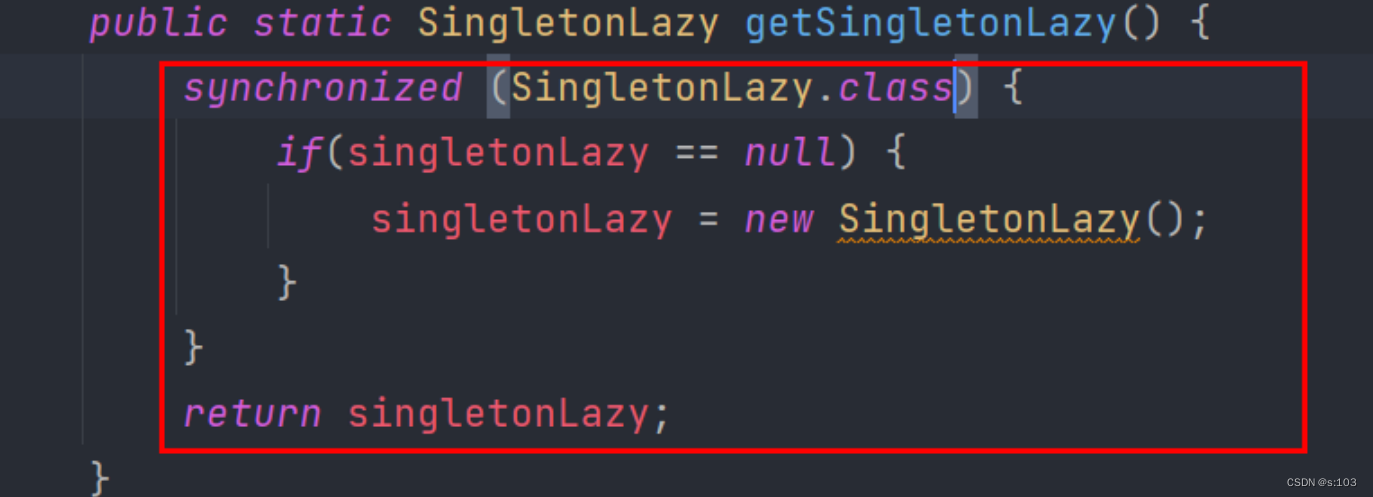
- 这个才是正确的~
-
法3:
-
法1法2都有个弊端
-
就是加锁太频繁了
-
加锁这个操作本身就开销大,因为其他线程就得阻塞
-
而实际情况是,没必要多次锁,只需要锁第一次,以后就不会有事~
-
-
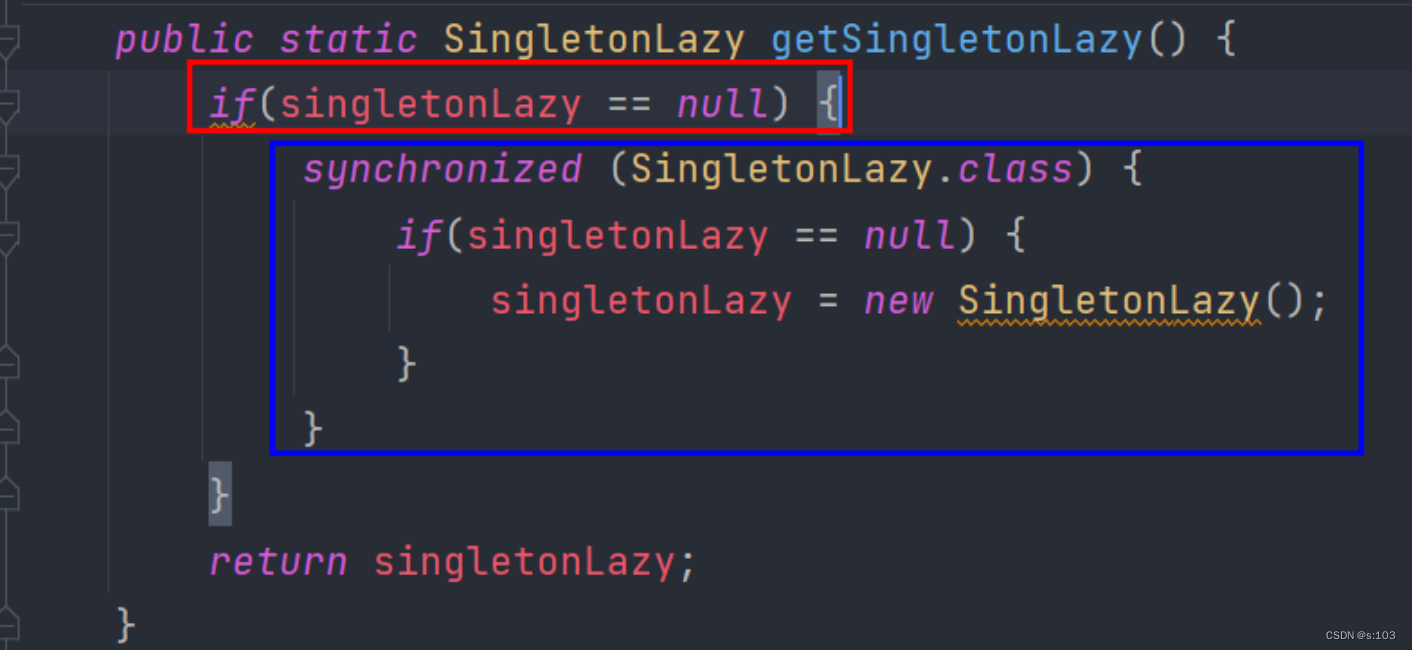
所以可以这么搞:
-
两个if是形式一样的,但是目的是不一样的~
-
内层if是为了防止多次new
-
外层if是为了
尽量减少加锁的次数
-
当然,可能有极端情况,锁了两次三次的,但是无伤大雅
-
因为外层if,依旧不保证原子性~
-
-
-
这样设计,在锁过一次之后,基本情况上,就不会再锁了~
-
但是这种写法,却又有一个缺陷
-
就是指令重排序的坑,有被挖出来了
-
法1法2保证了完全的原子性
-
但是法3没有,因为外层if的存在,是不原子的~
-
那就会有以下情况:
-
因为该情况下,进入if语句是不需要争夺锁的~
-
所以锁在这里并没有解决指令重排序的后果
-
-

-
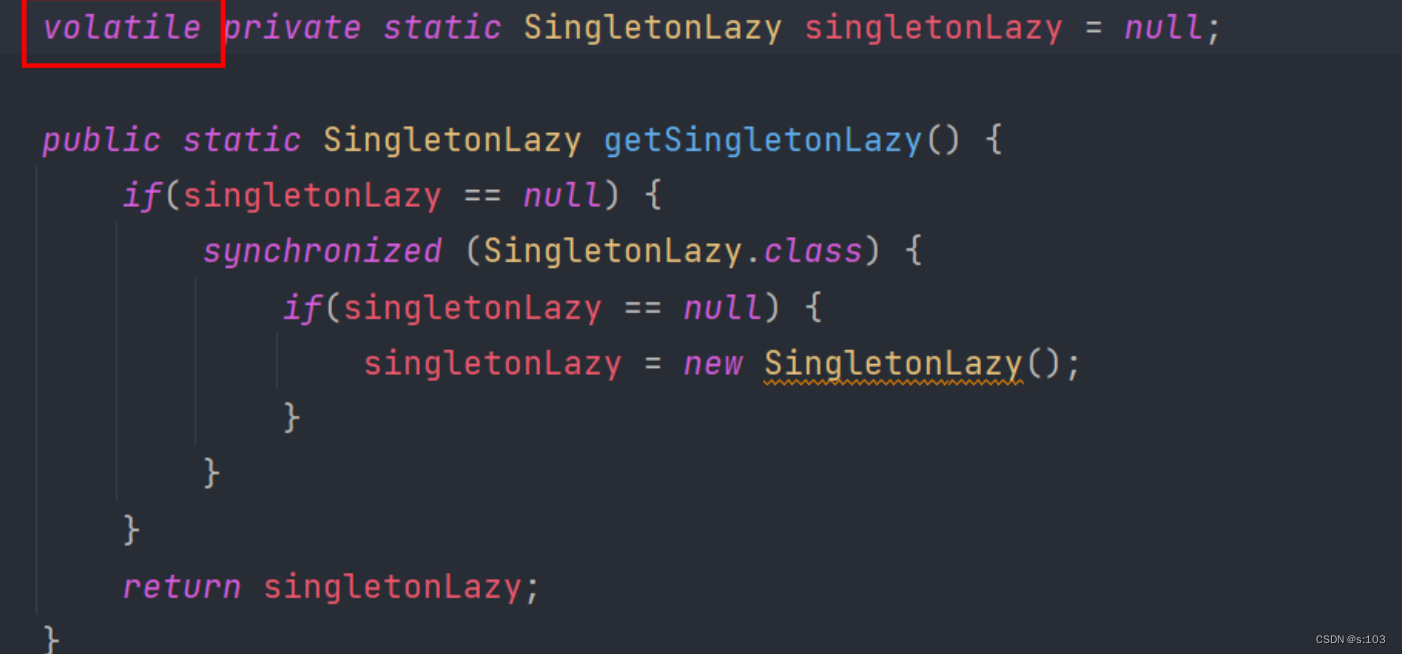
所以在这里还要对
singletonLazy
进行禁止指令重排序操作 -
即使用
volatile
~
-
这样,
法3
就是较优且解决线程安全问题的方式了~
3. 阻塞队列
-
队列—>先进先出,排好队~
-
优先级队列—> PriorityQueue —> 堆
-
阻塞队列—> 带有阻塞特性
3.1 阻塞特性
-
如果队列为空
- 尝试出队列,就要阻塞等待,直到队列不为空
-
如果队列为满
- 尝试入队列,就要阻塞等待,直到队列不为满
-
是线程安全的
3.2 Java标准库内自带的阻塞队列BlockingQueue接口
-
BlockingDeque代表的是双端的队列
- 对应的就是LinkedBlockingDeque和ArrayBlockingDeque
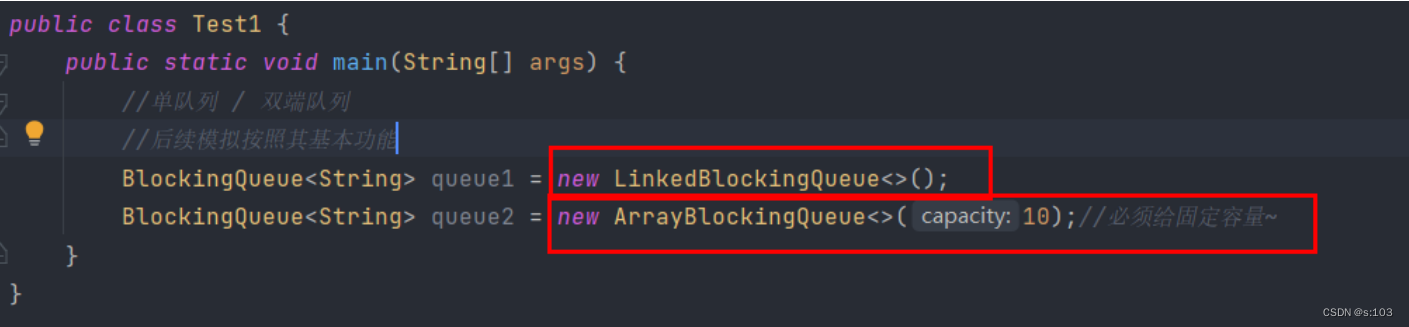
- 链表实现,默认最大容量是int的极限最大值
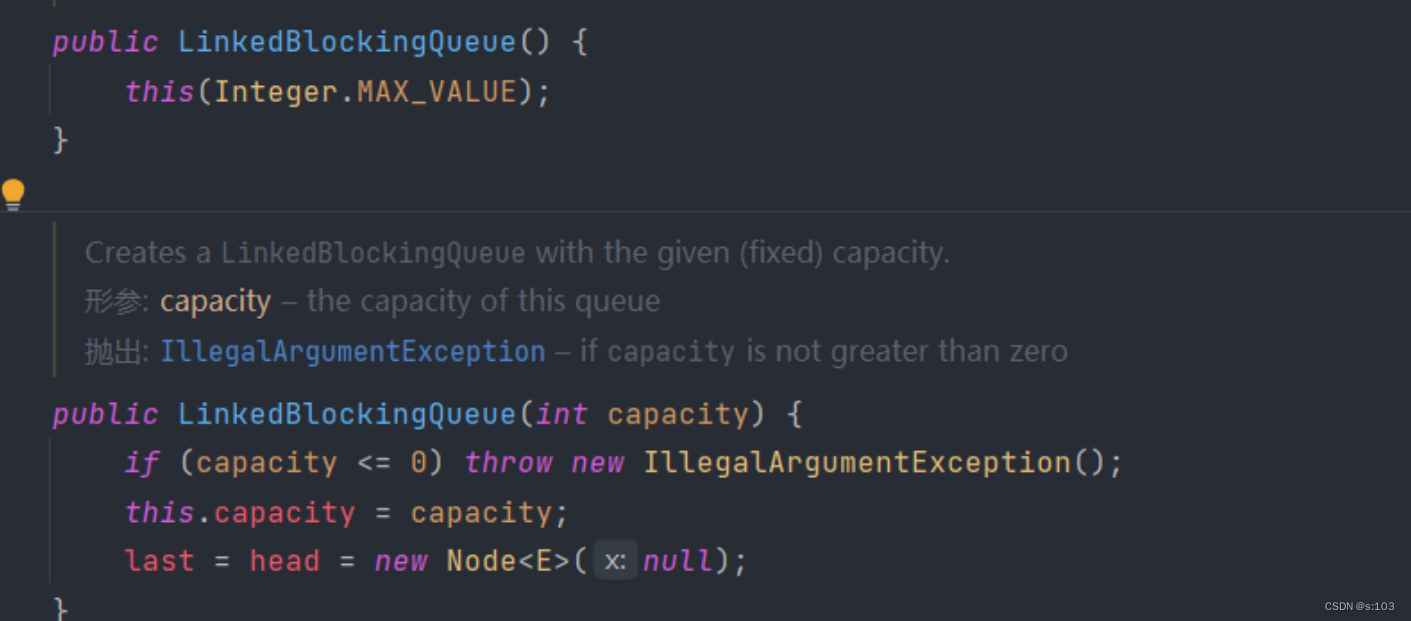
-
顺序表实现,没有给默认容量,必须自己定~
- 这很合理,因为如果默认为int极限最大值
- 一下子创建那么大容量的数组,显然是不合理的

3.2.1 方法1 put入队列
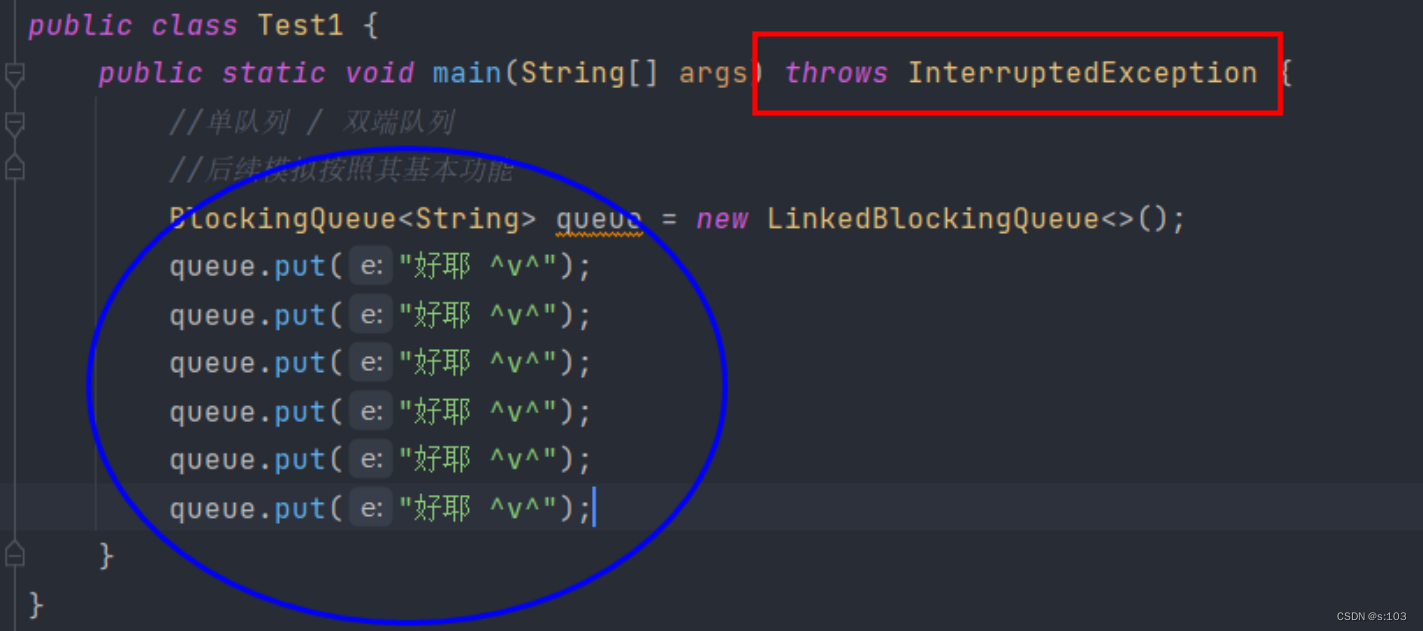
- 多线程编程特别常见且常有的异常
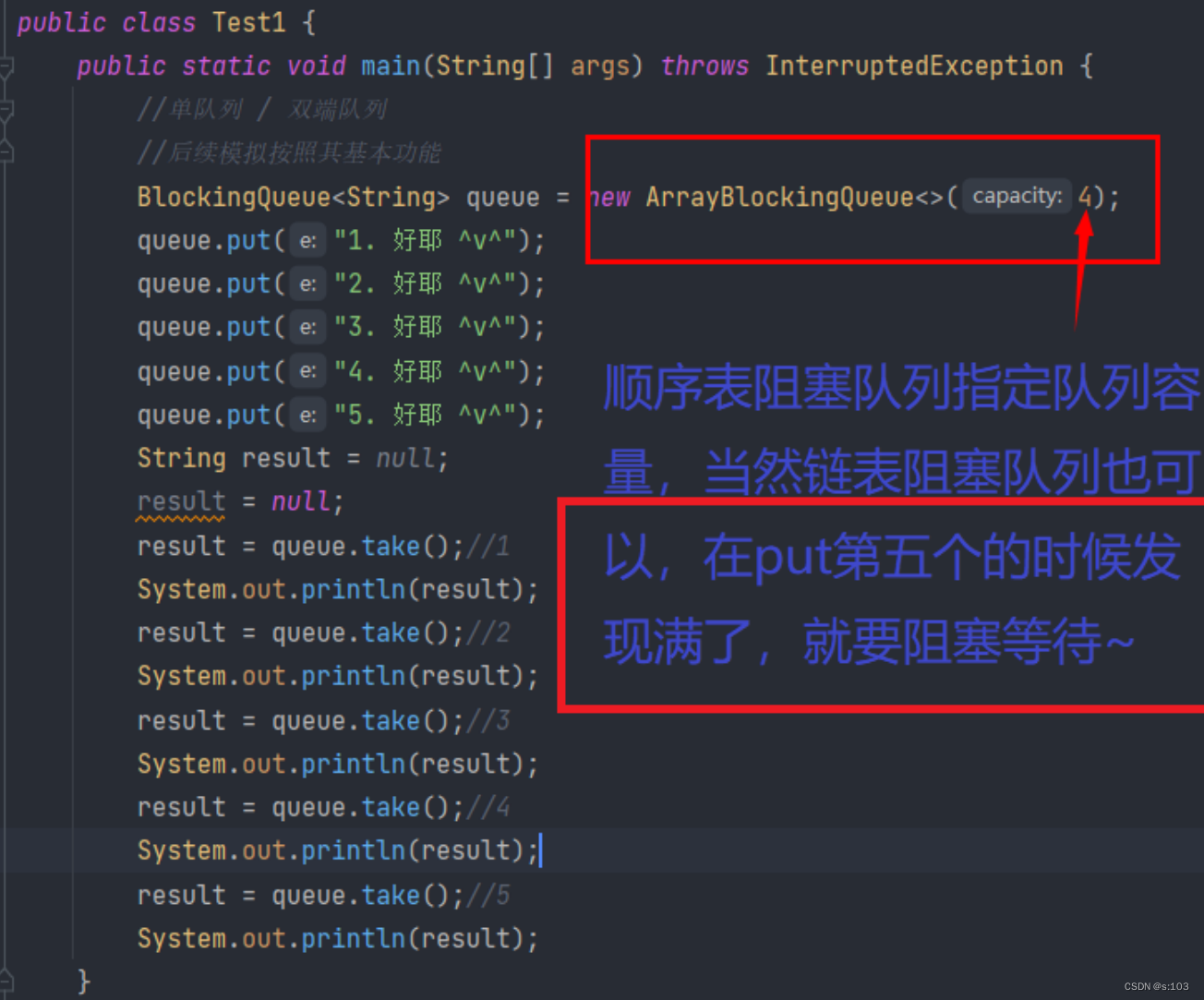
- 运行结果是这样的:(ctrl + f2终止程序)

3.2.2 方法2 take出队列
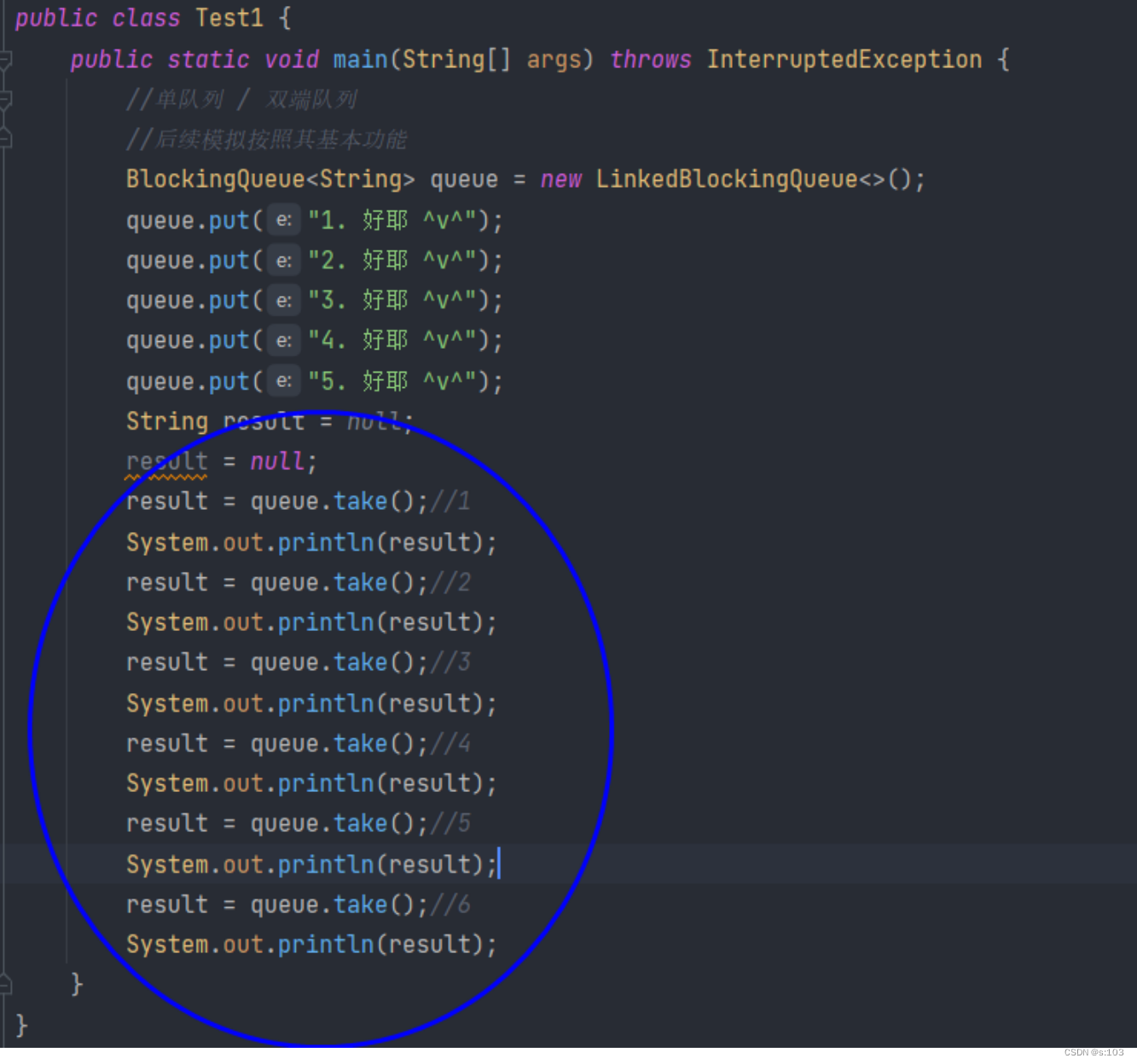
- 现在队列里有五个元素,我take六次
- 执行结果是这样的:
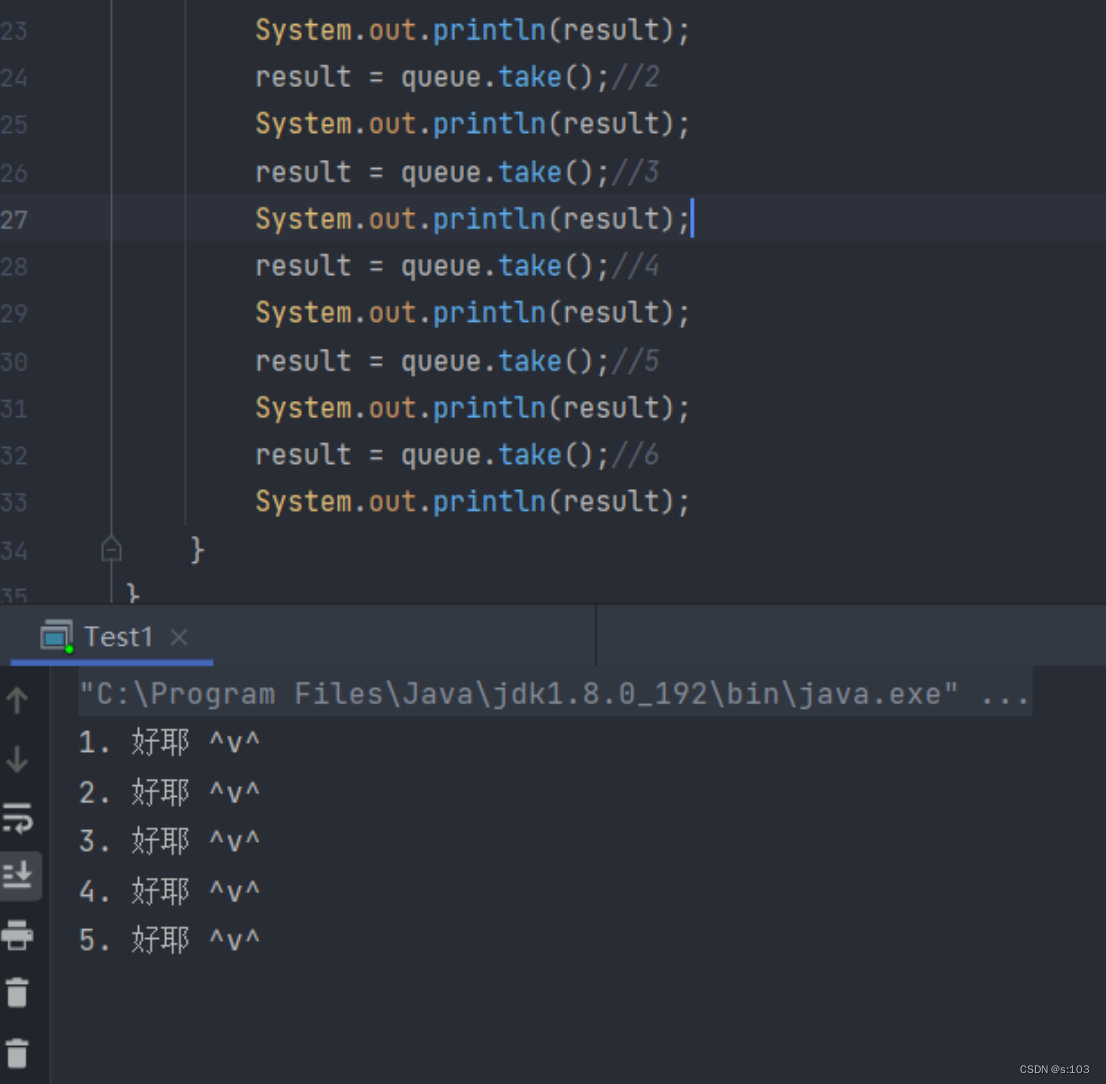
-
确实按照先入先出,但是程序好像并没有结束,这是因为第六次take的时候,发现是空队列,阻塞等待了~
-
五次则刚好可以结束~
-
可按ctrl + f2结束程序~
-
这两个方法是阻塞队列的核心方法,其他方法跟普通队列别无二致~
peek的时候队列空,阻塞等待,但是几乎不用这个方法和其他方法~
3.3 阻塞队列的好处
-
写多线程代码时,多线程之间若进行数据交互,可以用阻塞队列简化代码编写~
-
在go语言中,支持多并发编程,并且引入了一个“轻量级线程”的“协程”,协程与协程之间进行交互数据的时候,
会通过一个阻塞队列:channel
3.3.1 生产者消费者模型
- 这是很关键的,服务器开发中一种很常见的代码写法~
- 我们更希望代码执行起来更像“流水线”一样
举个栗子:
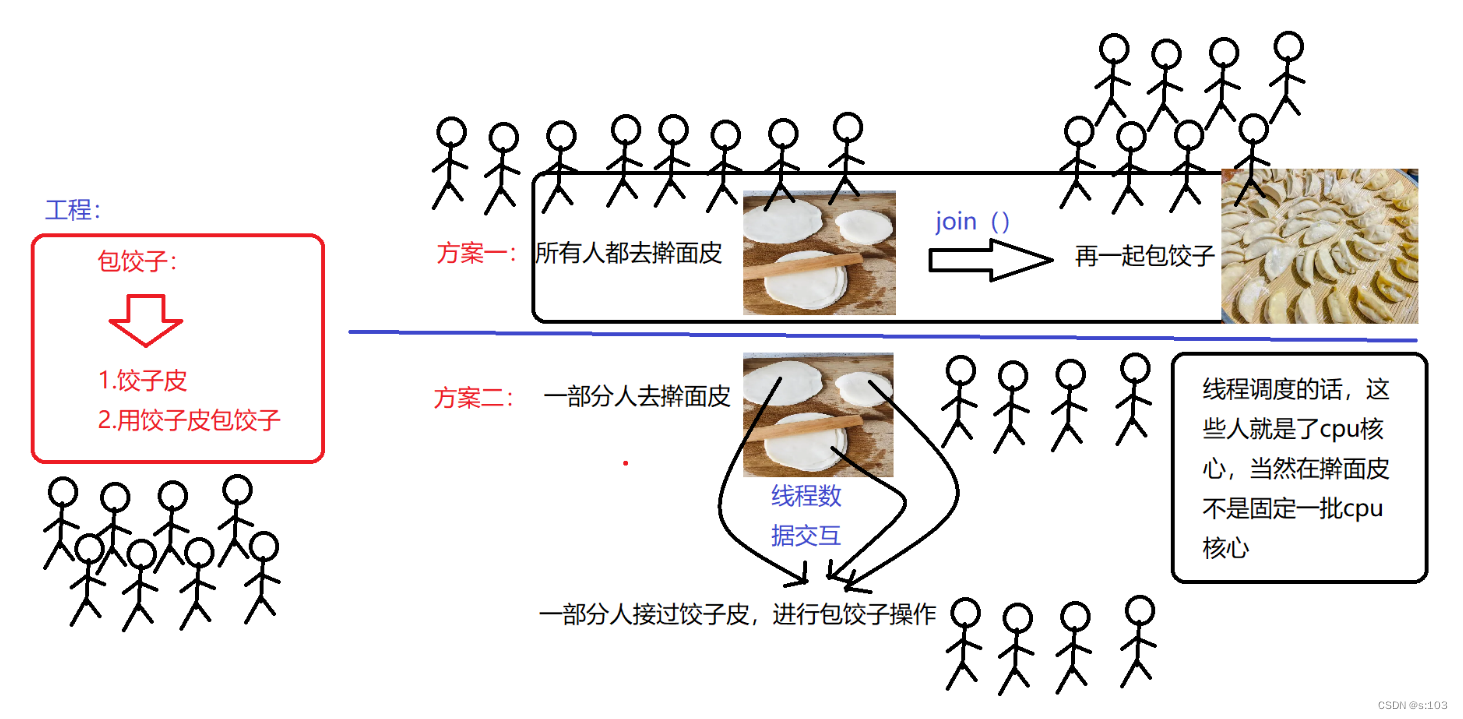
-
这个包饺子工程,显然方案二的效率会更高
- 两个线程同时进行,进行数据交互
- 这个模型就是“生产者消费者模型”
3.3.2 生产者消费者模型的优点
-
解耦合
-
我们常听到一个词语“高内聚低耦合”
- 这是代码风格的良好习惯~
-
耦合代表,
两个模块关联度越高,耦合性越高,关联度越低,耦合性越低
-
内聚代表,关联度高的模块应该聚集在一起,则为高内聚,
反之,低内聚
~
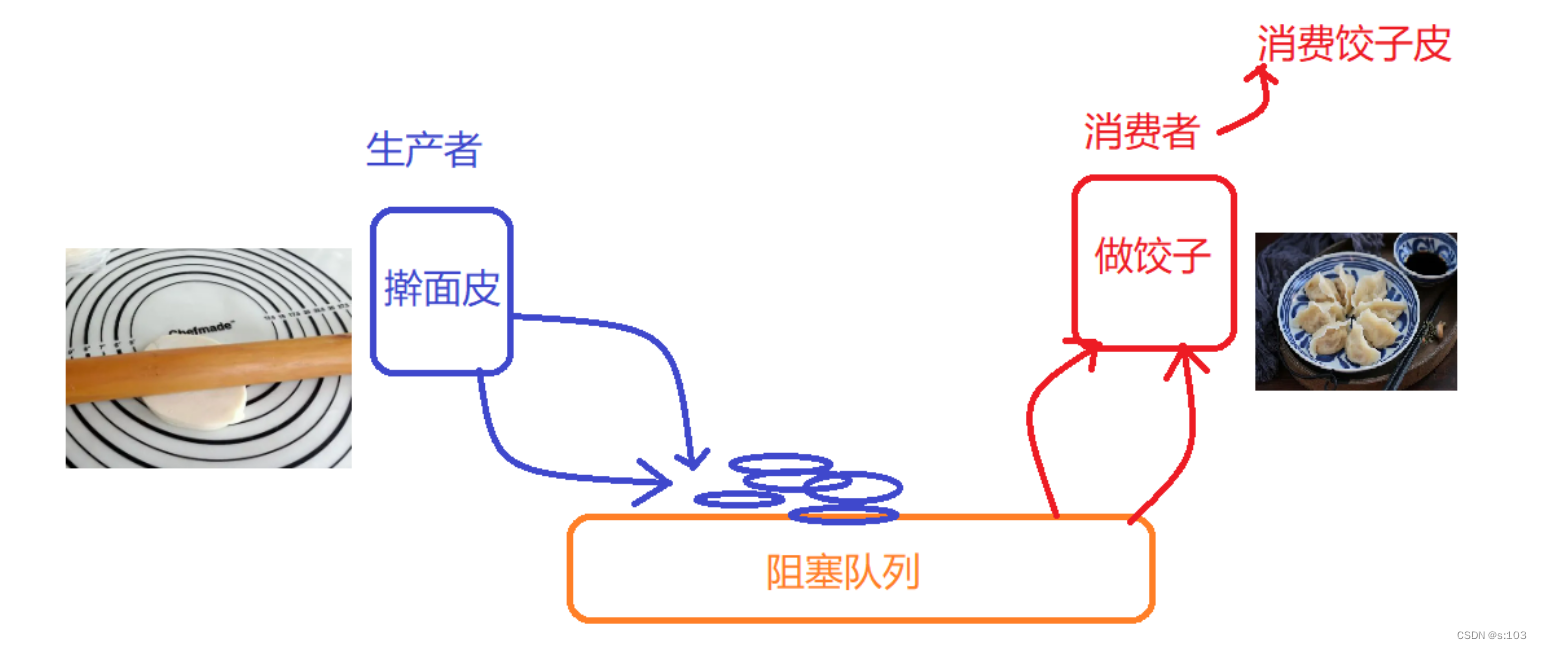
- 在这里,以阻塞队列为中介,即作为两个线程进行数据交互的桥梁
-
这样就可以减少生产者与消费者之间的关联度,即解耦合
- 这样子做有利于防止一个线程bug严重影响另一个线程
-
生产者只认识队列不知道消费者存在
-
消费者只认识队列不知道生产者存在
-
一方挂了对另一方影响较小
-
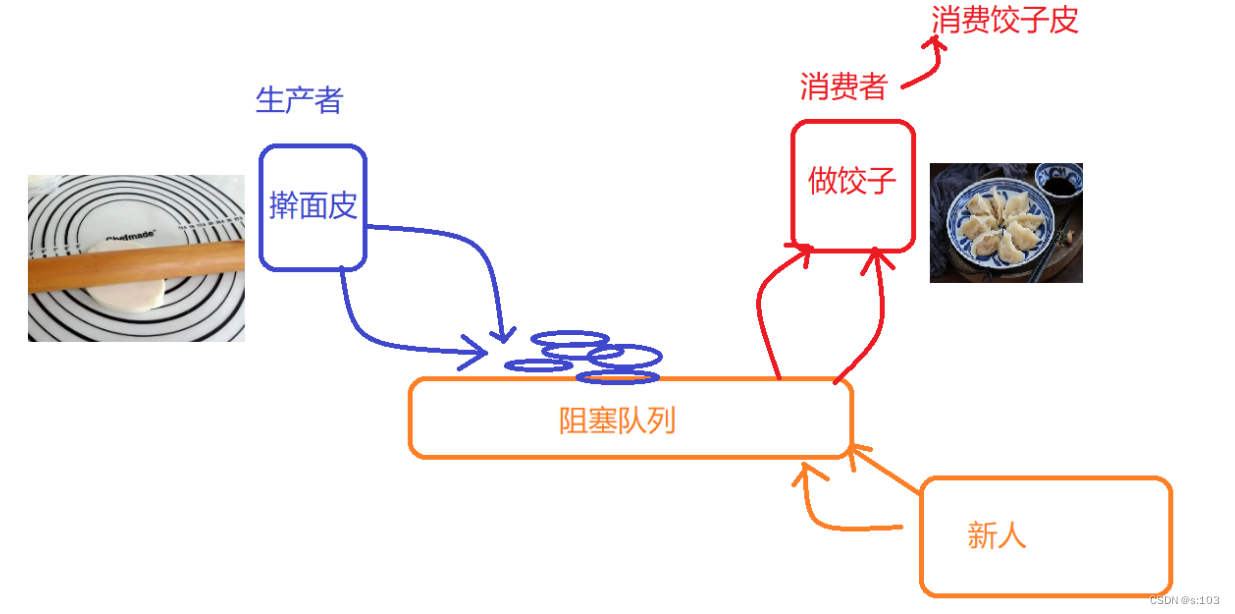
并且,引入一个新生产者,和新消费者,都很好办
-
只需要新人与阻塞队列联系就好了
-
新人的到来也对其他人影响最小化了
-
-
-
由于阻塞队列非常好使,大佬们将阻塞队列功能单独拎出来做成一个单独的服务器~
-
消息队列服务器~
- 这个服务器我们以后可能会用到,核心数据结构就是阻塞队列~
-
这个服务器会挂吗
- 会,但是其概率比你写的代码挂的概率低得低得低~
- 人家可是固定下来的,大佬写的~
-
削峰填谷
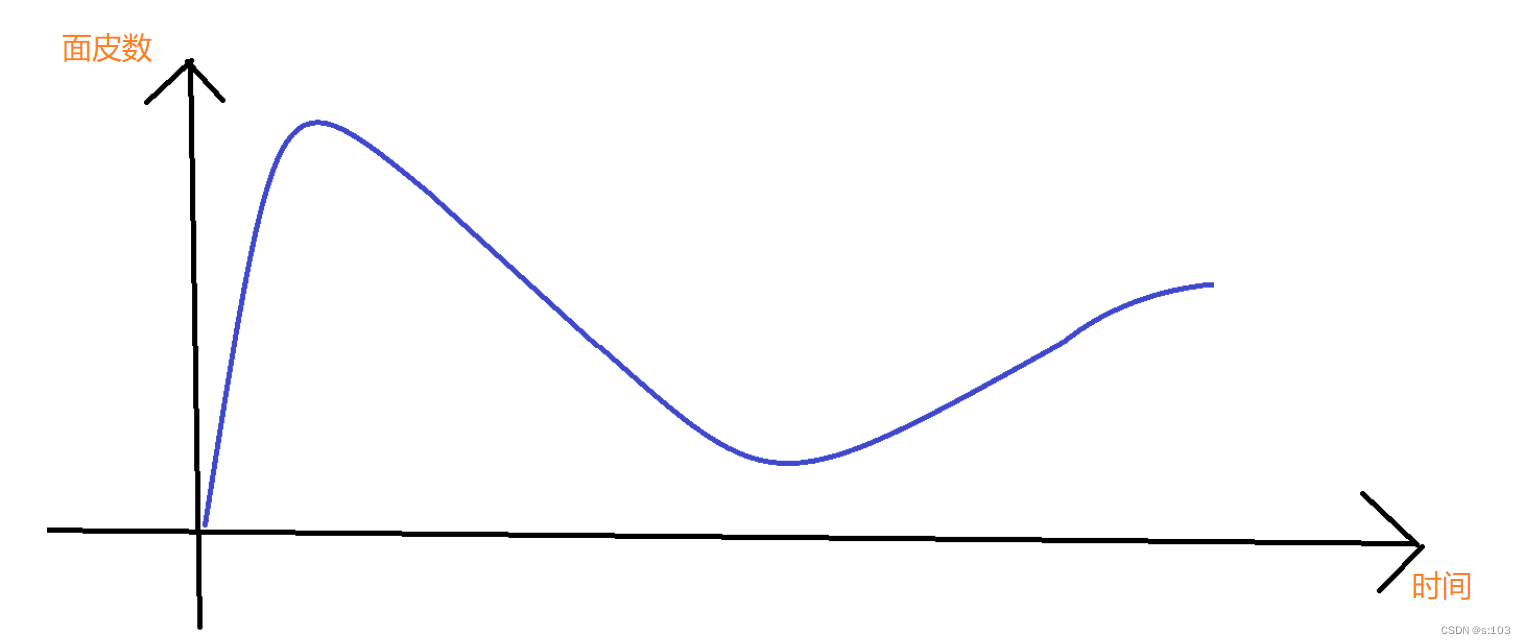
-
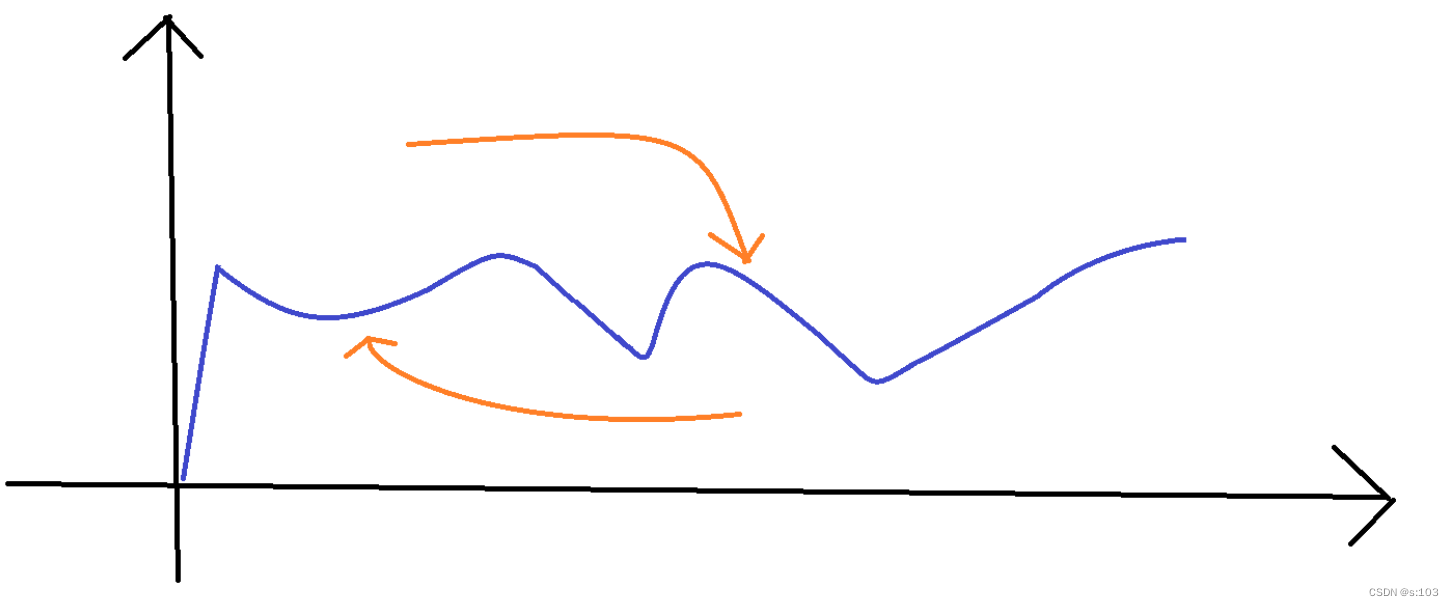
如图,
该曲线可以代表,擀面皮产生的面皮量与时间的关系
-
而图中出现的波峰与波谷就会产生一些问题
-
如果没有阻塞队列
- 波峰的产生会导致消费者一下子接受大量的数据,而常常消费者的“条件”是低于生产者的,所以消费者很可能会遇到麻烦~
- 波谷的产生会导致消费者很快的消耗完饺子皮,那么就会处于无饺子皮的情景~
-
而削峰填谷的含义就是
“中和”
,让线程之间的交互更加稳定
-
-
生产者生产太多,导致队列满了,则进入阻塞,直到队列不满
-
消费者消耗太多,导致队列空了,则进入阻塞,直到队列不空
-
有点像三峡大坝,上流水太多关闸门防洪,下流水太少开闸门防旱

3.4 代码实现生产者消费者模型

-
下面将介绍一些情景~
-
大部分是线程不安全的~
-
当这只是打印顺序问题~
-
但是阻塞队列绝对是安全的
-
还有“死锁”情况
-
3.4.1 生产者 < 消费者
public class Test1 {
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>(5);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(100);
blockingQueue.put(1);
System.out.println("生产1个");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(10);
blockingQueue.take();
System.out.println("消耗1个");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
}

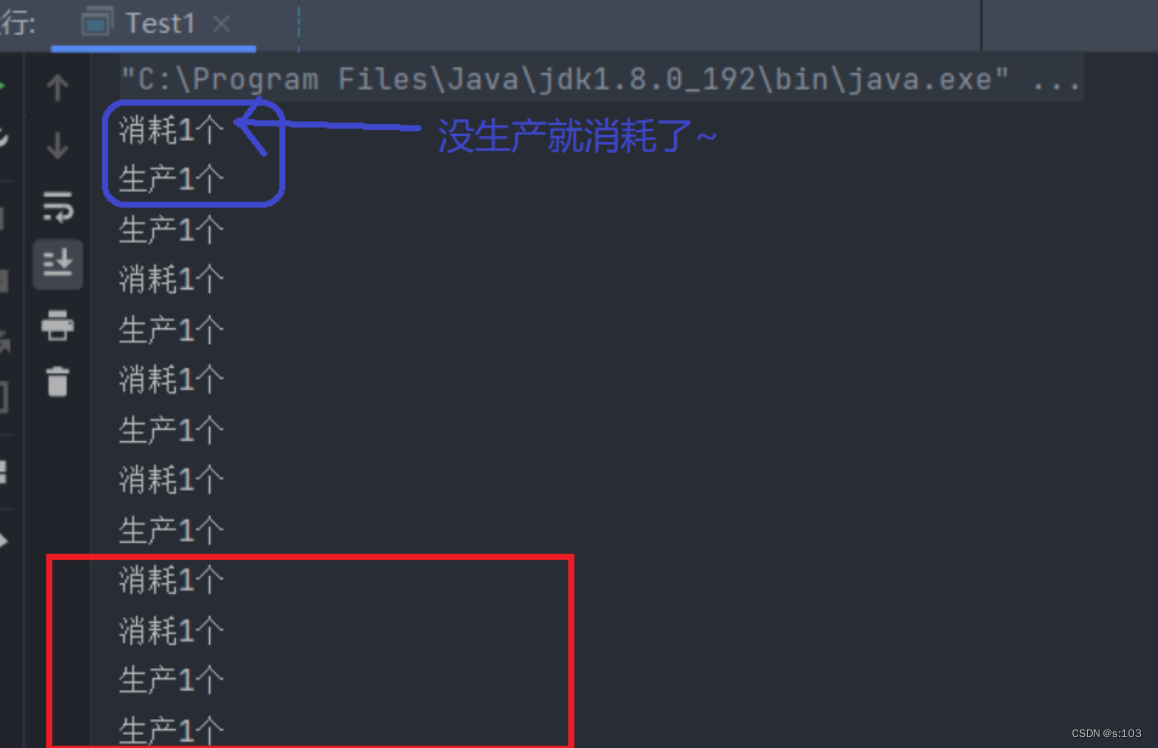
- 我们理论上想要的结果是,生产一个消费一个,因为是消费者在阻塞(速度快)
-
而结果是:
-
-
这里是因为,消费者阻塞被唤醒时,生产者线程还来不及打印那句话~
-
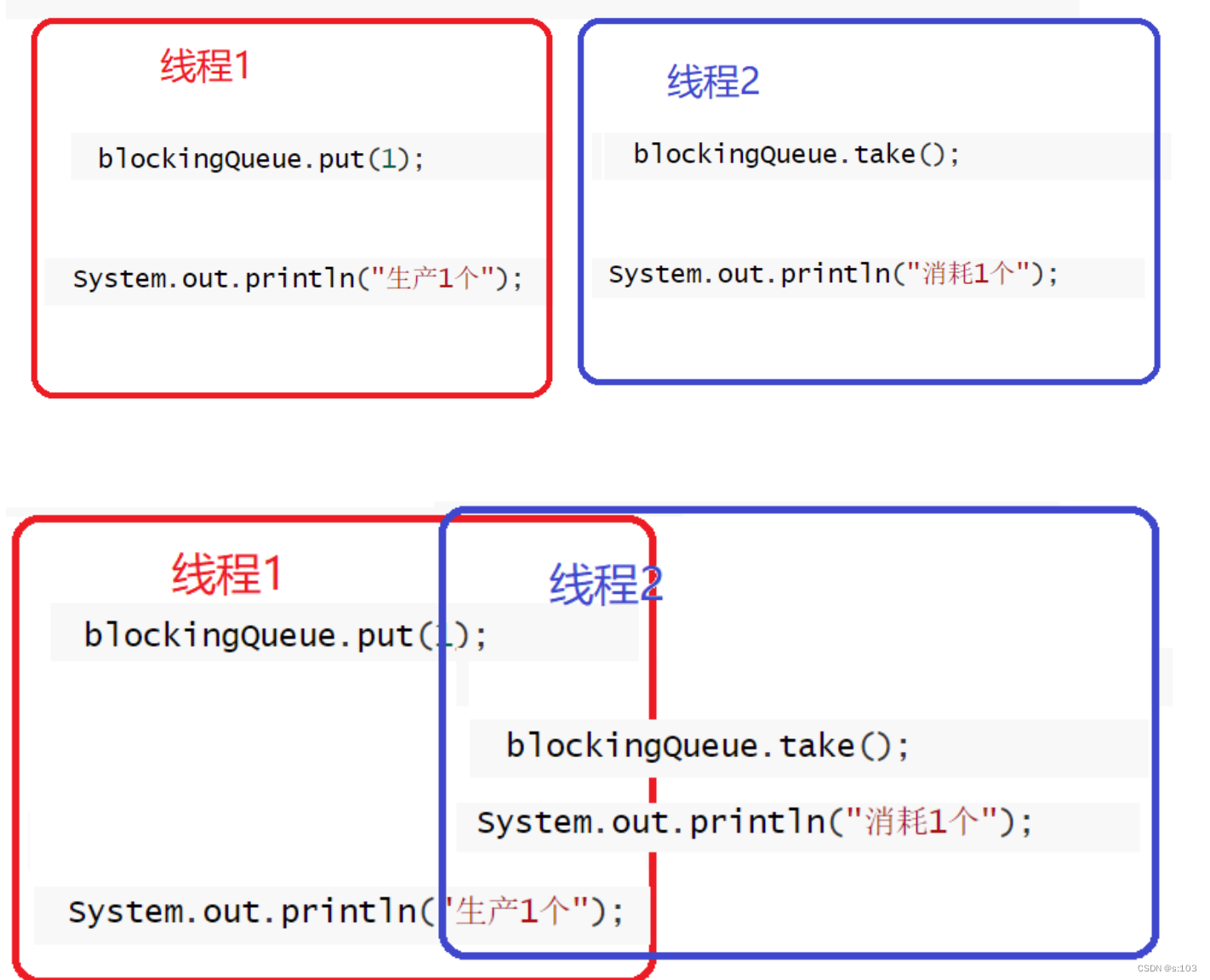
只需要加一把锁就行了~
- 至于锁在哪个线程加,无所谓~
-
-
由于线程2比较快,所以它的take基本上是在等put的
- 由于take和println非原子,所以有以上这种情况
-
即使线程2,但是还是有可能put被调度在take前
- 只是缺少了个线程阻塞的过程罢了,本质上就是线程有元素了,不需要阻塞
- 皆大欢喜~
- 但是也因为非原子性,会有以上这种情况~
-
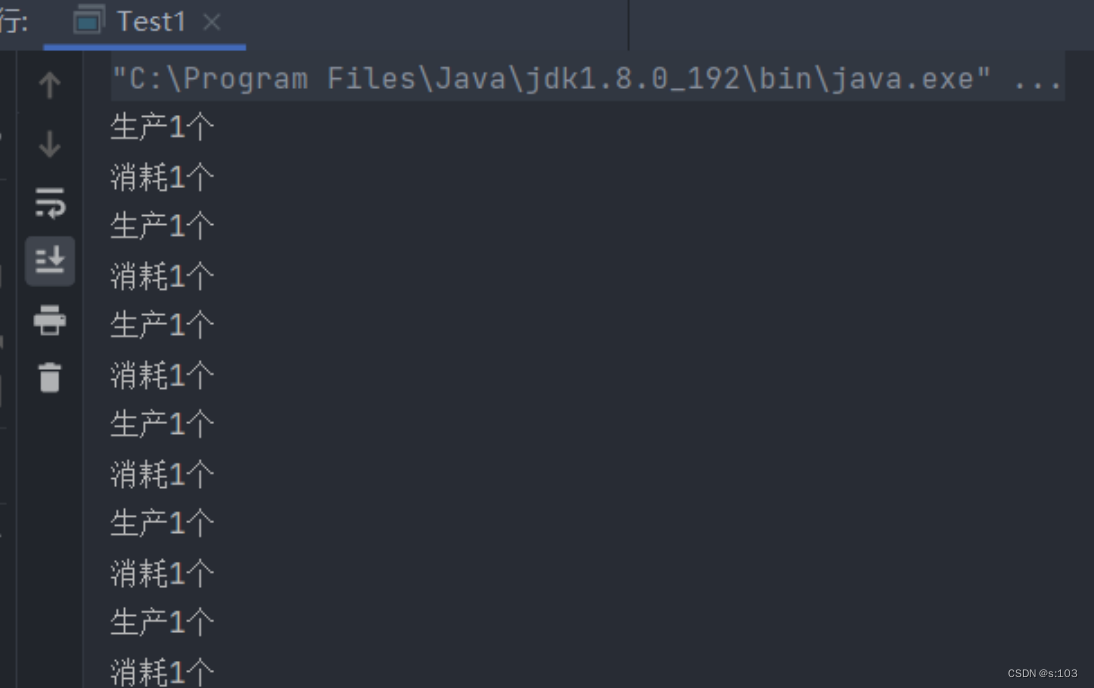
修改线程2:(快捷键,鼠标选中需包围的语句 + ctrl + alt + t + synchronized)
Thread t2 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(10);
synchronized (blockingQueue) {
blockingQueue.take();
System.out.println("消耗1个");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
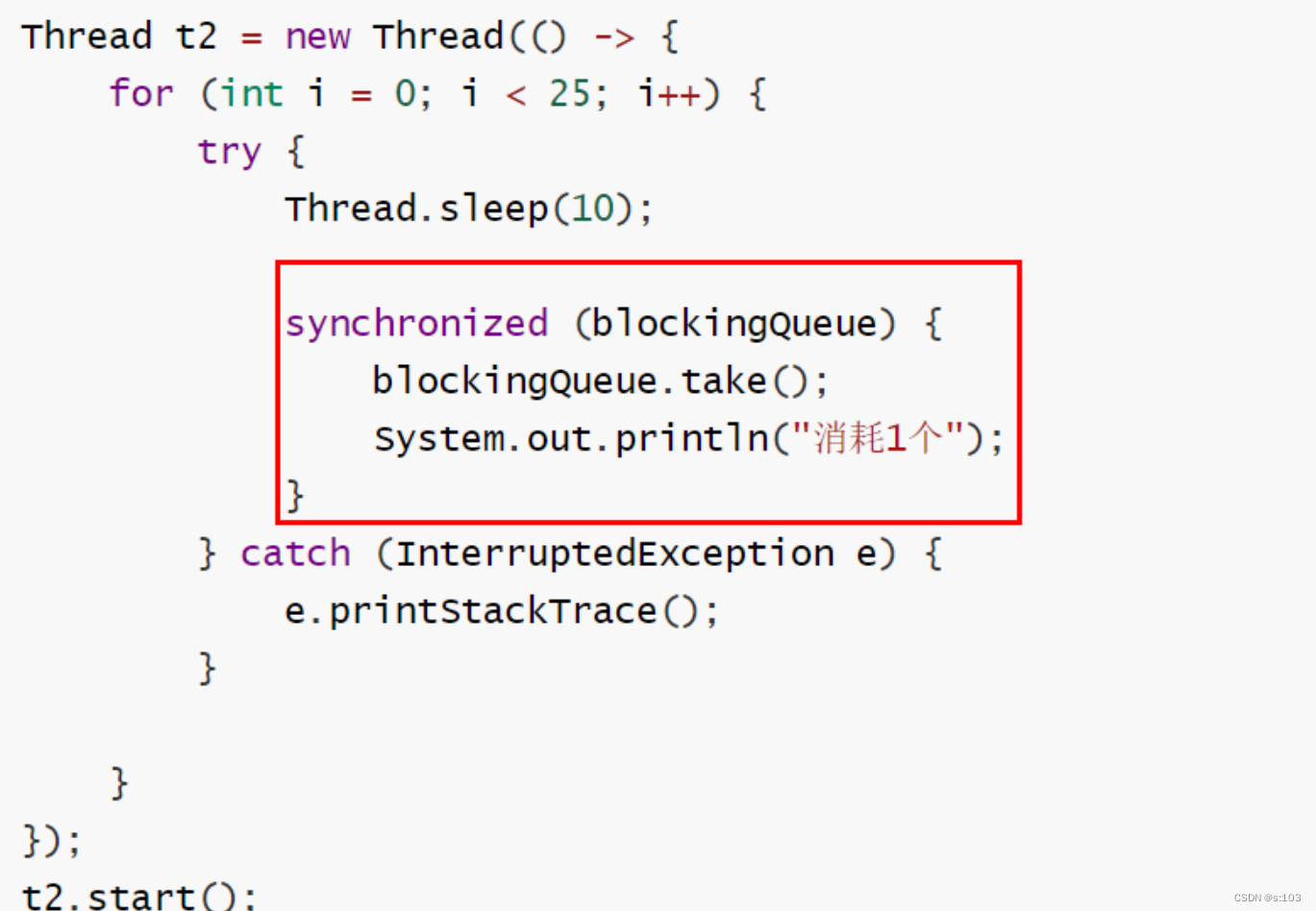
- 结果:
-
不要加两把,会死锁!
- 因为加两把
- 生产者要填入元素,也要进行阻塞等待(等待锁)
- 那么就无法唤醒消费者,导致两人都进入阻塞态~
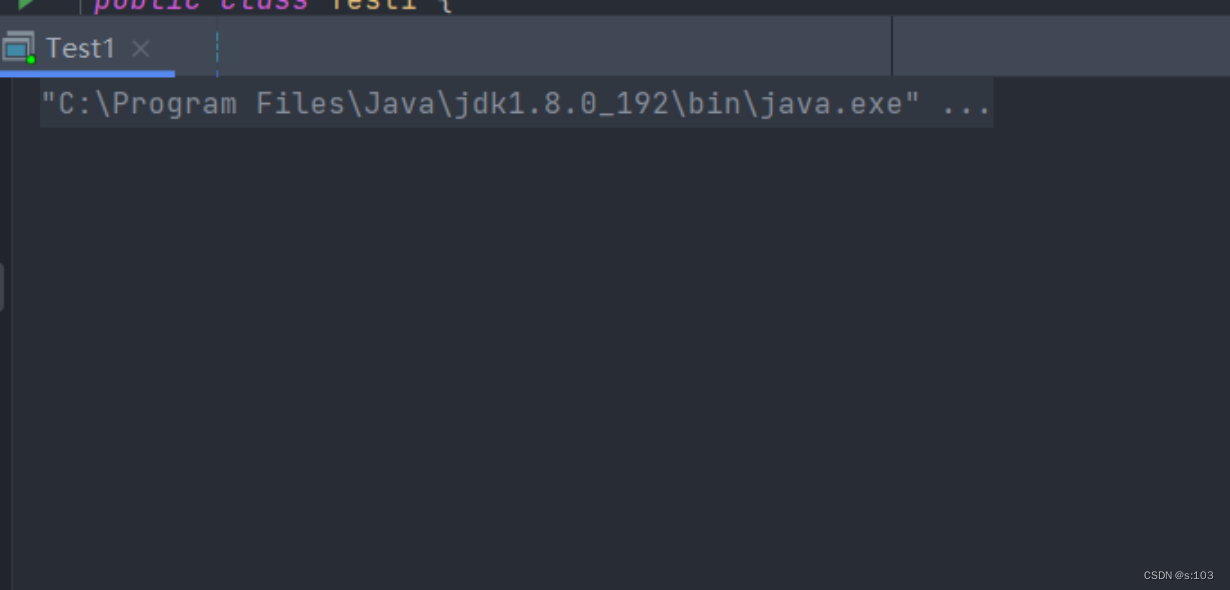
改动两个线程:
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>(5);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(100);
synchronized (blockingQueue) {
blockingQueue.put(1);
System.out.println("生产1个");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(10);
synchronized (blockingQueue) {
blockingQueue.take();
System.out.println("消耗1个");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
- 死锁了:
3.4.2 生产者 > 消费者
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>(5);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(10);
blockingQueue.put(1);
System.out.println("生产1个");}
catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(100);
blockingQueue.take();
System.out.println("消耗1个");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
- 同样的,一个锁都不加的情况下,也会出现一些差错~
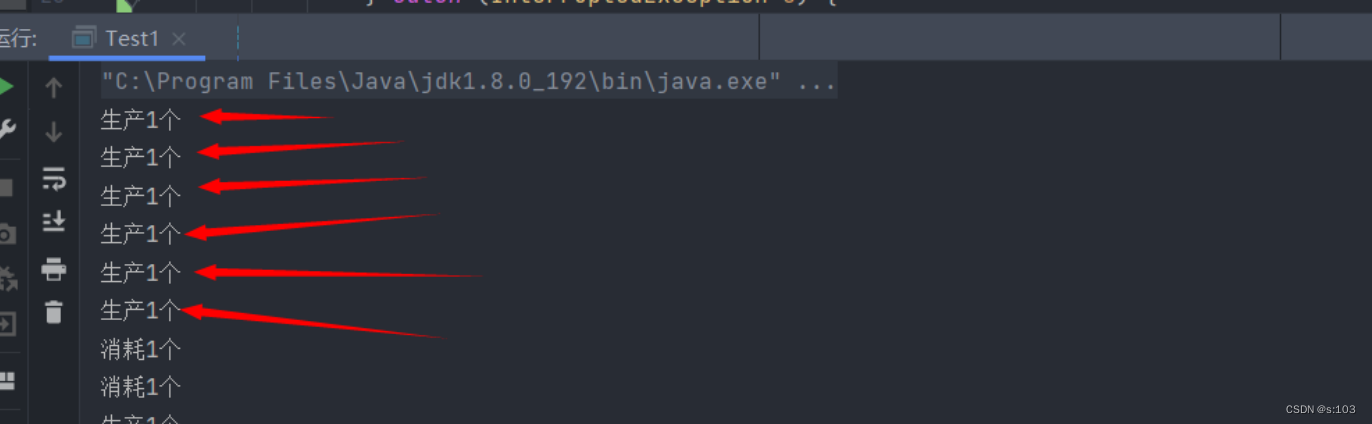
-
加一把锁后,结果正常~
- 双锁会死锁~
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>(5);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(10);
blockingQueue.put(1);
System.out.println("生产1个");}
catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
Thread.sleep(100);
synchronized (blockingQueue) {
blockingQueue.take();
System.out.println("消耗1个");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}

3.4.3 正常写法
-
一般不会让两个线程都不sleep
- 这样,“打印”这个操作就很大概率会结果出错
-
让一方留足够的时间等对方~
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>(5);
Object o = new Object();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
System.out.println("生产1个");
blockingQueue.put(1);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread t2 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
try {
blockingQueue.take();
System.out.println("消耗1个");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
-
这样,线程1只要put1个,线程2就会立马take掉~
-
线程1则不可能会满
-
这是通过sleep解决了一定的线程安全问题~
-
因为调度无需,“现象”可能不合意
-
但是阻塞队列数据交互绝对是线程安全的
-
-
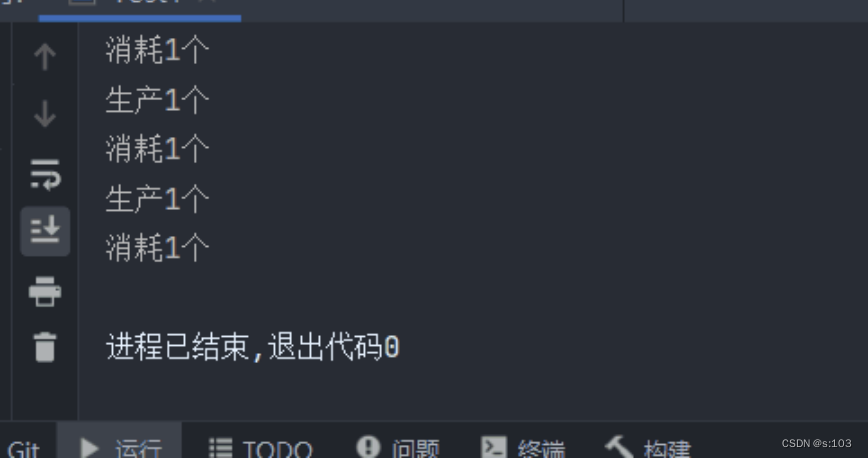
测试:
- 严格生产一个消耗一个~
-
顺便一提:

-
出了点小错:
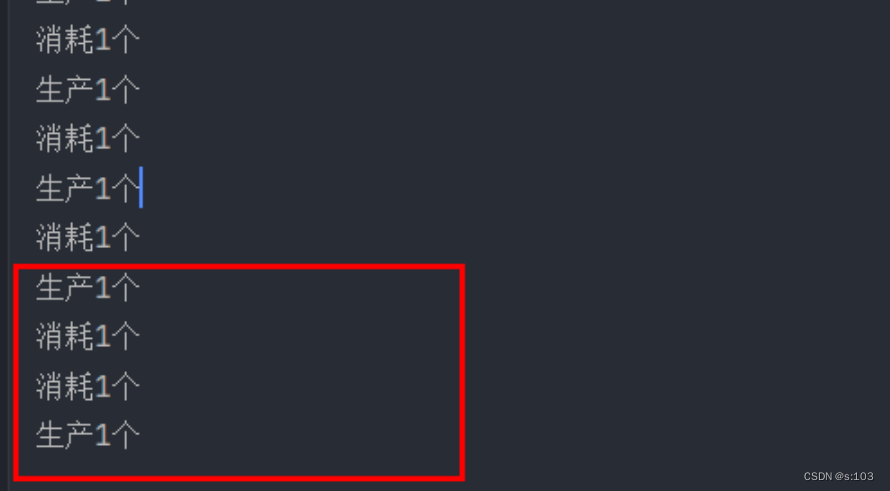
-
当然,打印顺序不合我们的意没关系,因为我们用到阻塞队列,主要是为了数据交互,而数据交互,必然是线程安全的~
3.5 模拟实现阻塞队列
-
这里的队列是个循环队列
- 单队列
-
线程安全
-
队列满,插入元素时必须阻塞
===
wait
-
队列不满,唤醒阻塞 ===
notify
-
队列不满,唤醒阻塞 ===
-
队列空,取出元素时必须阻塞
===
wait
-
队列不空,唤醒阻塞 ===
notify
-
队列不空,唤醒阻塞 ===
-
这里的循环队列跟之前数据结构讲的循环队列,整体结构是一样的
- 只需要进行也些修改
-
两种方式确定队列是满是空:
- size表示队列元素个数【本次讲解方式】
- 牺牲一个下标,区分满空
-
用什么底层数据结构
- 链表
-
顺序表【本次讲解方式】
- 取模法
-
在适当的时机,设计wait和notify的对应代码
-
总体代码在此,讲解才后:
public class MyBlockingQueue {
volatile private int[] items;
volatile private int front;
volatile private int rear;
private final static int INIT = 10;
private int size;
public MyBlockingQueue(int capacity) {
this.items = new int[capacity];
}
synchronized public void put(int value) throws InterruptedException {
if(size == items.length) {
this.wait();
}
items[rear] = value;
rear = (rear + 1) % items.length;
size++;
this.notify();
}
synchronized public int take() throws InterruptedException {
if(size == 0) {
this.wait();
}
int ret = items[front];
front = (front + 1) % items.length;
size--;
this.notify();
return ret;//ret刚刚跳出队列的元素~
}
public MyBlockingQueue() {
this.items = new int[INIT];
}
}
3.5.1 属性
volatile private int[] items;
volatile private int front;
volatile private int rear;
private final static int INIT = 10;
private int size;
-
items ==> 底层顺序表
-
front 队头
-
rear 队尾
-
INIT默认容量
-
常量不能被volatile修饰,因为常量不需要~
-
常量压根没有被优化
-
-
volatile是为了保证内存可见性和禁止指令重排序~
-
size为队里元素个数~
3.5.2 构造方法
public MyBlockingQueue(int capacity) {
if(capacity <= 0) {
//没有容量为0或者小于0的队列~
this.items = new int[INIT];
}
this.items = new int[capacity];
}
public MyBlockingQueue() {
this.items = new int[INIT];
}
- 没啥好说的,队列数据结构应该很熟了吧[斜眼笑]
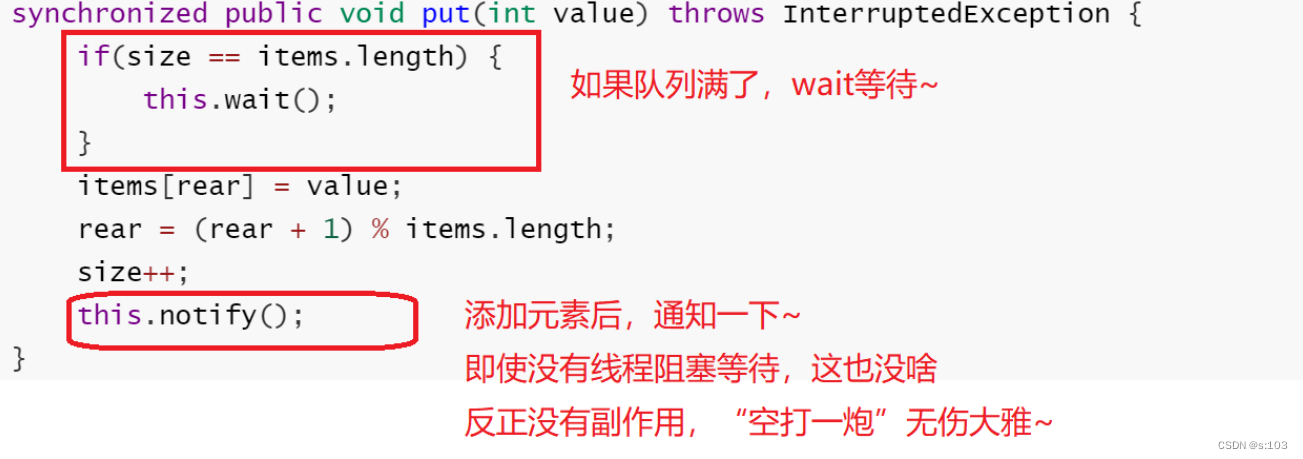
3.5.3 put方法
synchronized public void put(int value) throws InterruptedException {
if(size == items.length) {
this.wait();
}
items[rear] = value;
rear = (rear + 1) % items.length;
size++;
this.notify();
}
3.5.4 take方法
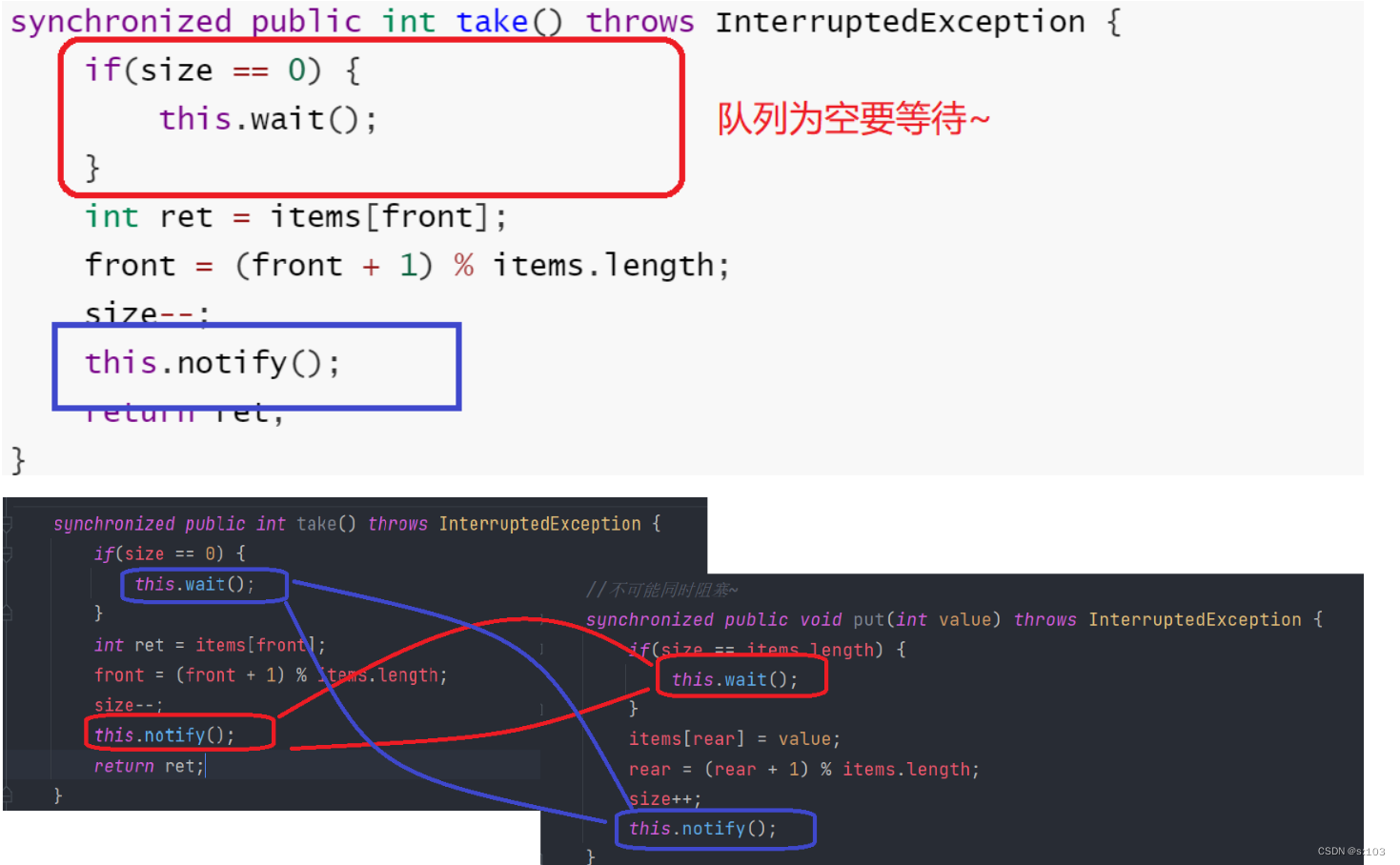
synchronized public int take() throws InterruptedException {
if(size == 0) {
this.wait();
}
int ret = items[front];
front = (front + 1) % items.length;
size--;
this.notify();
return ret;
}
-
显然一个队列是不会即满又空的
- 容量不为0~
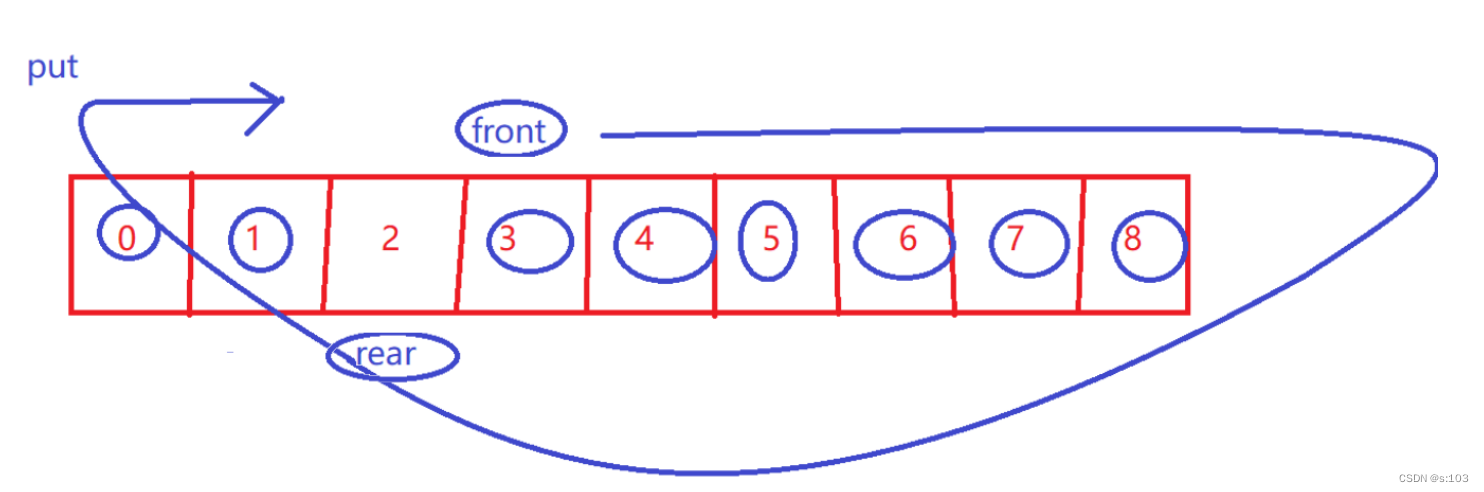
3.5.5 循环队列原理小小复习
-
简单的通过size就可以判断空或者满了~
-
size与 0/数组长度 比较
- 而不是只判断front与rear相遇
- 因为相遇可能是空或者满
-
- “浪费一个数组空间”的方式,这里不讲,但是确实可以不需要size~
-
简单put
-
size++
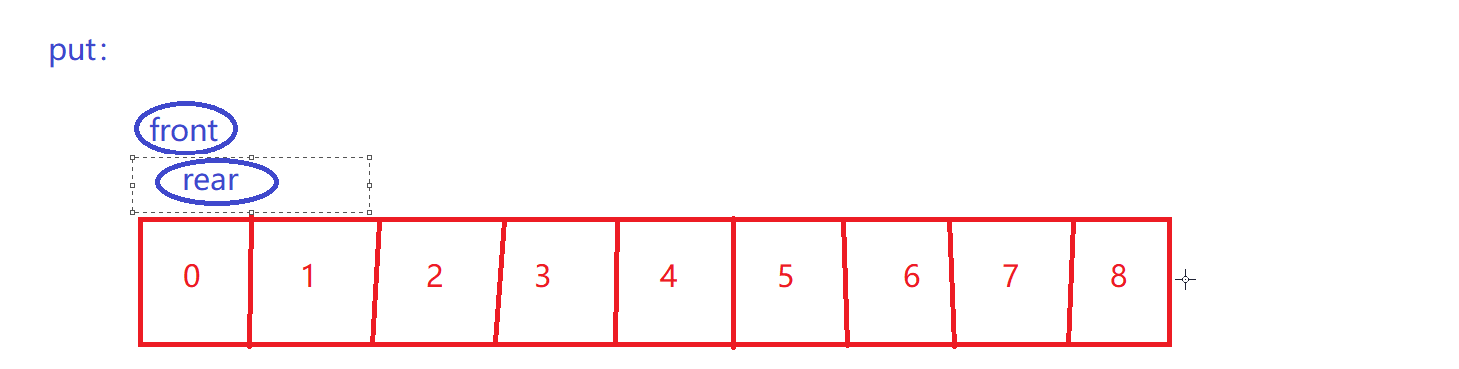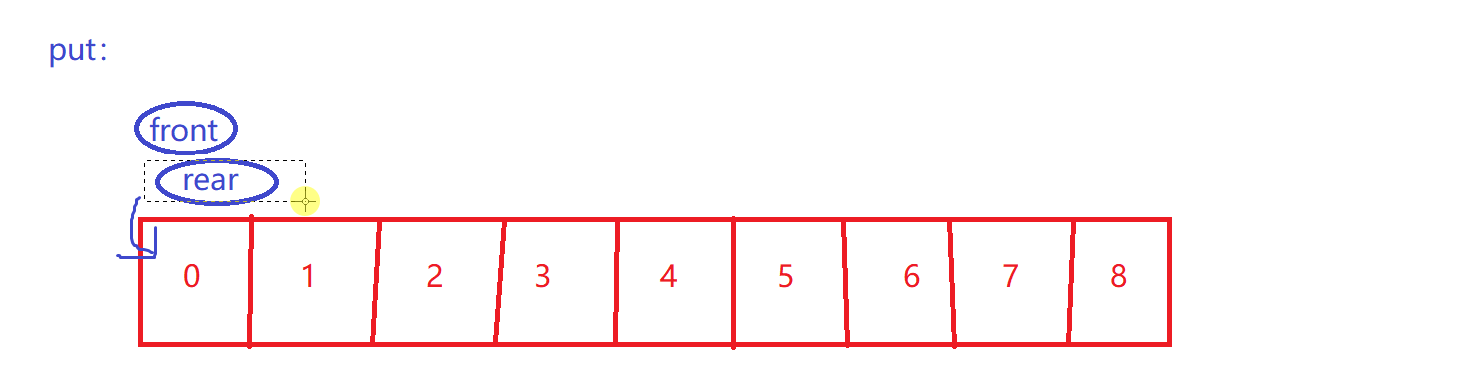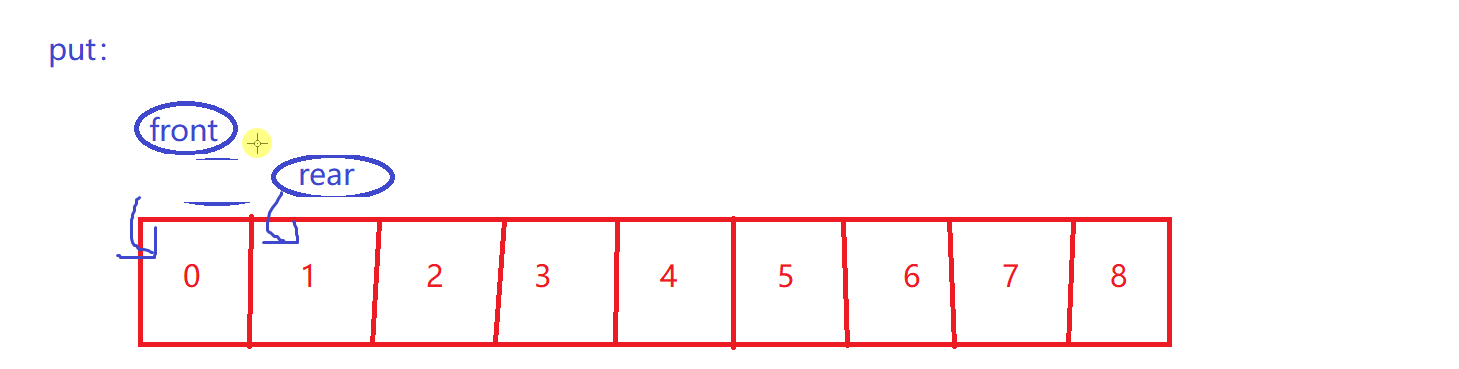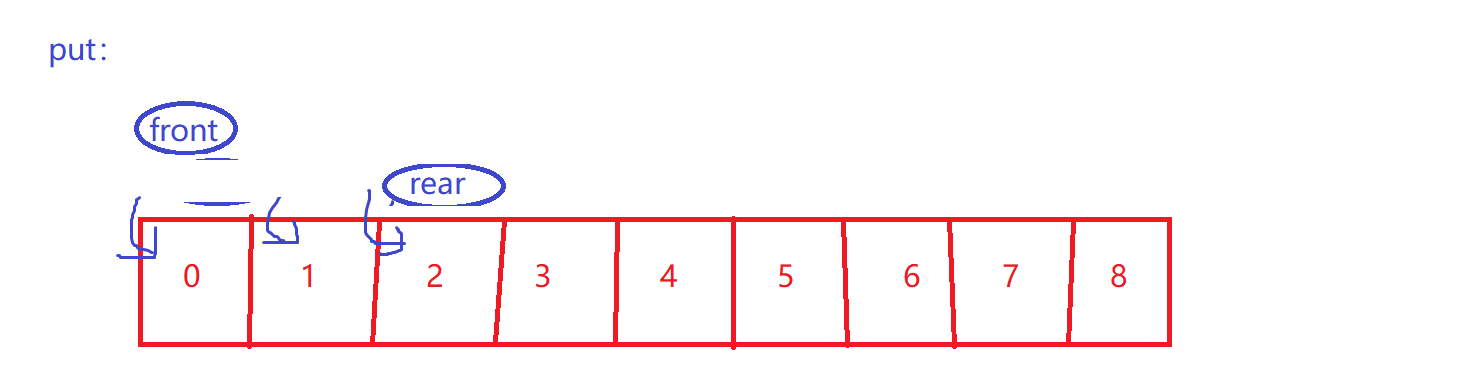
-
size++
-
简单take
-
size–
-
front到rear之间才是有效数据
-
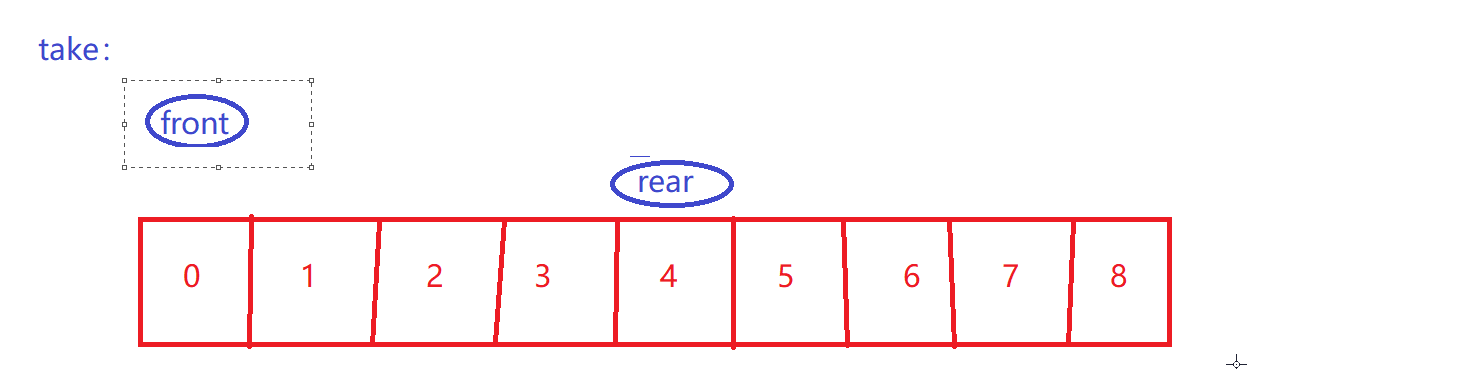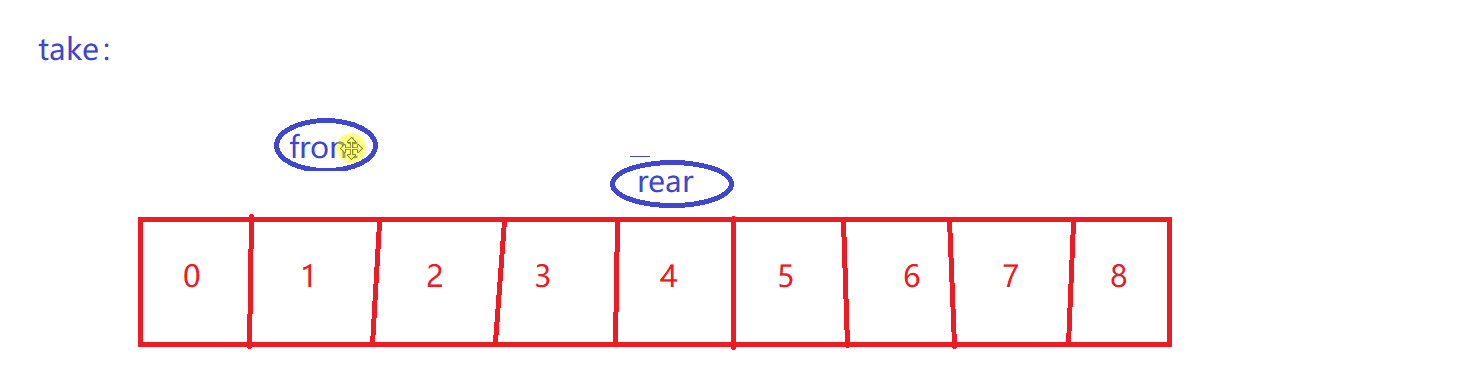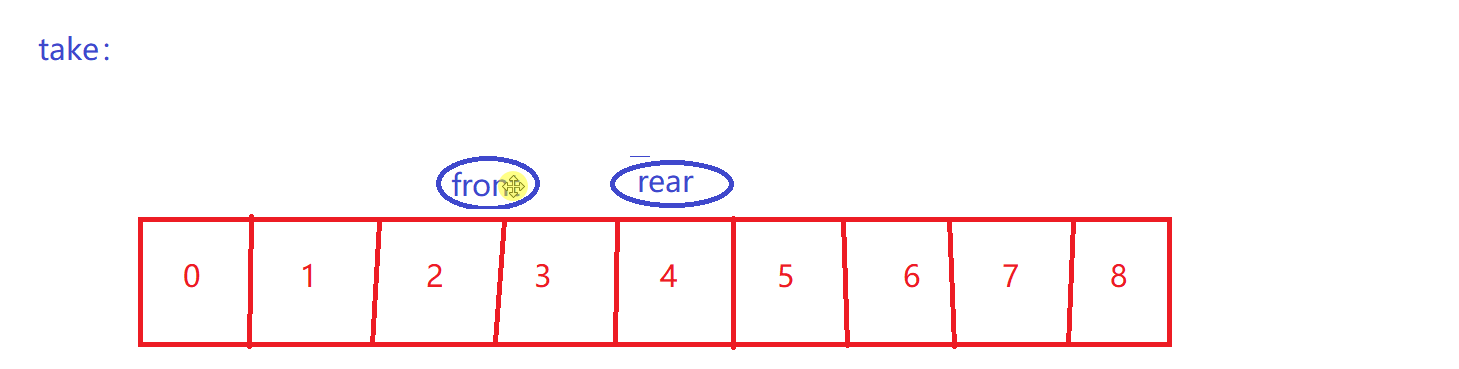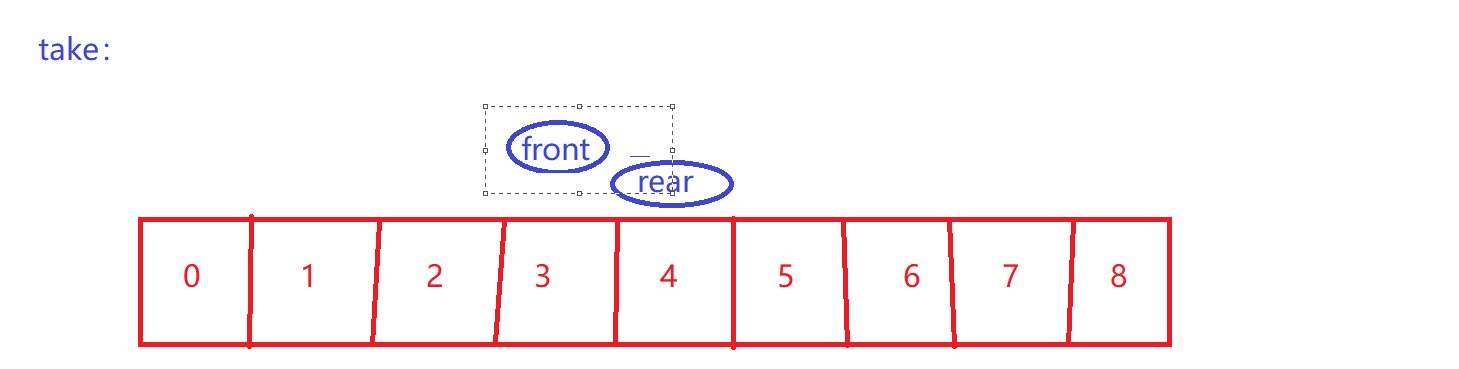
-
put【循环性质】
-
size++

-
size++
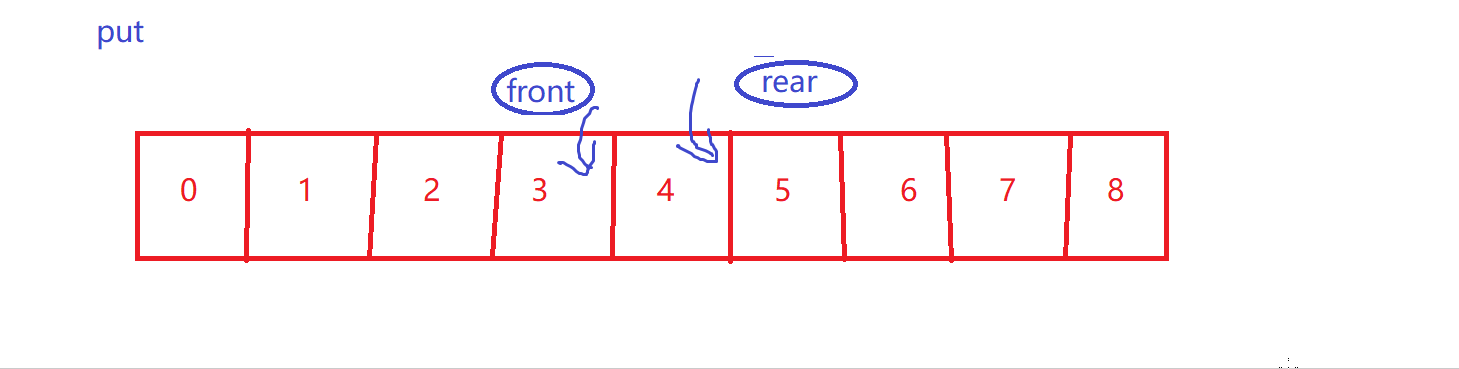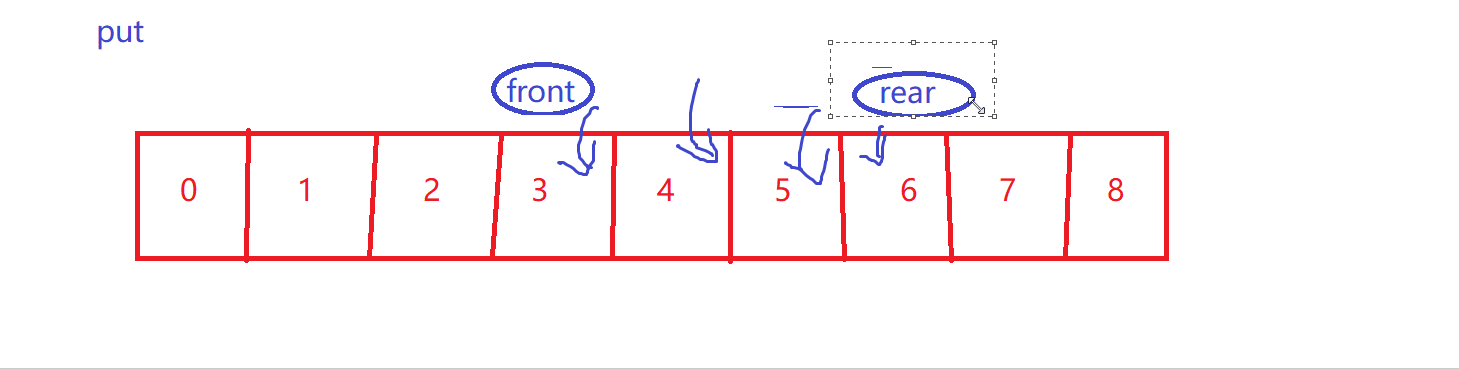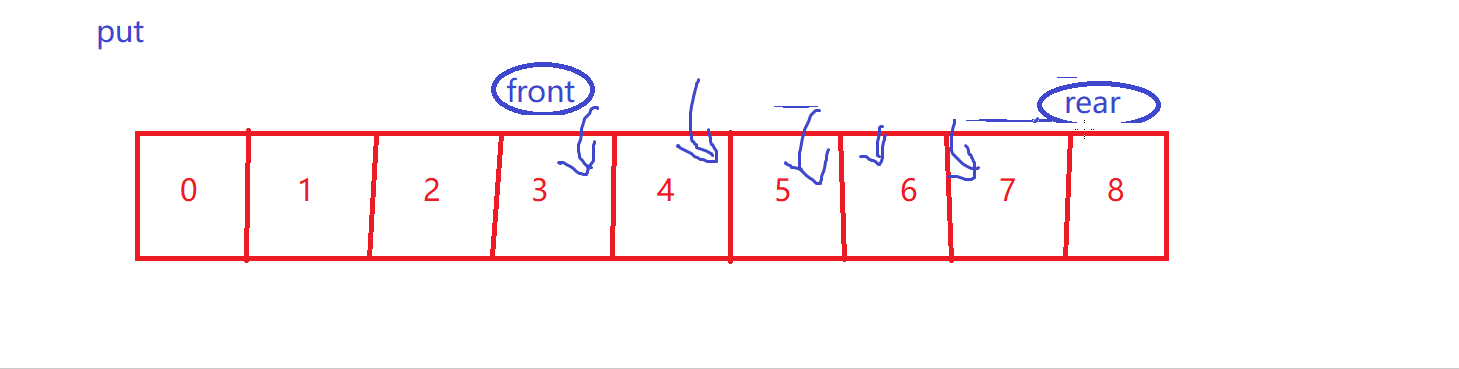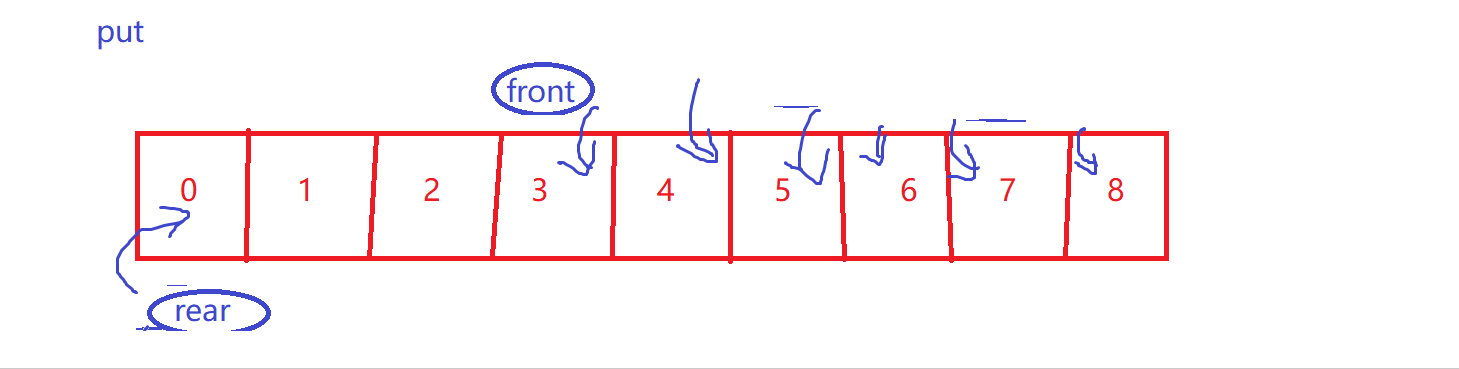
- 再次强调,front到rear才是有效数据~
-
take【循环性质】
-
size–
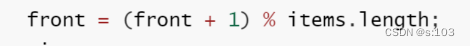
-
size–
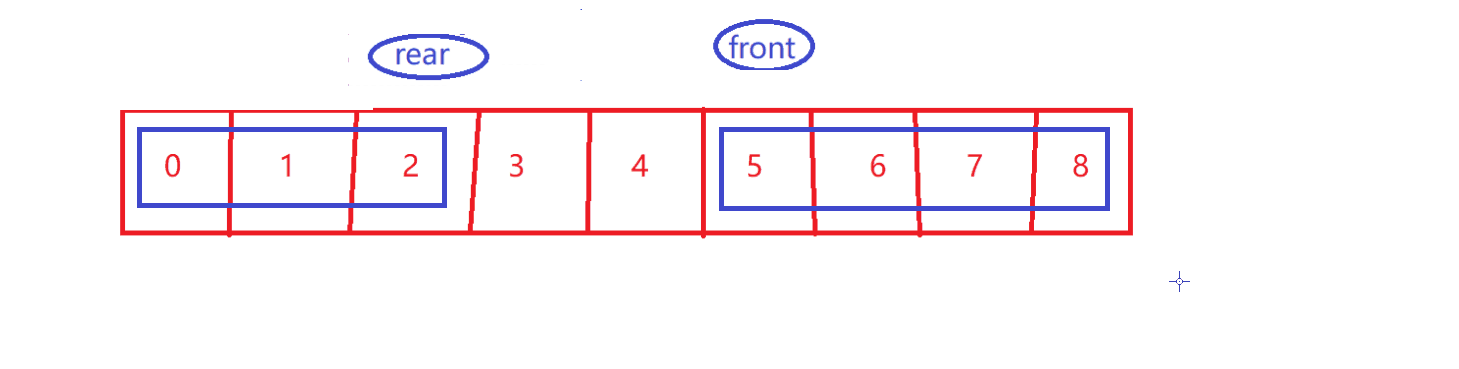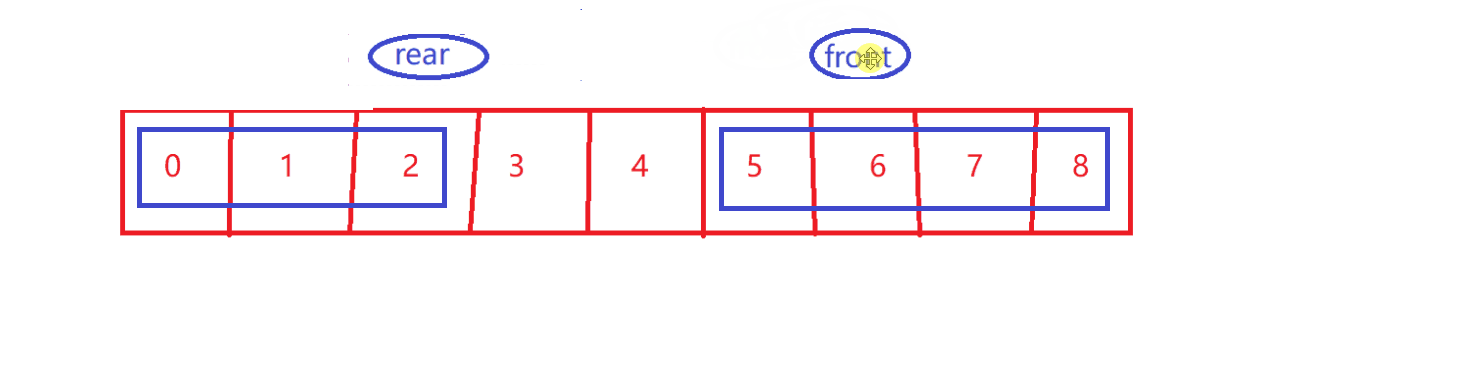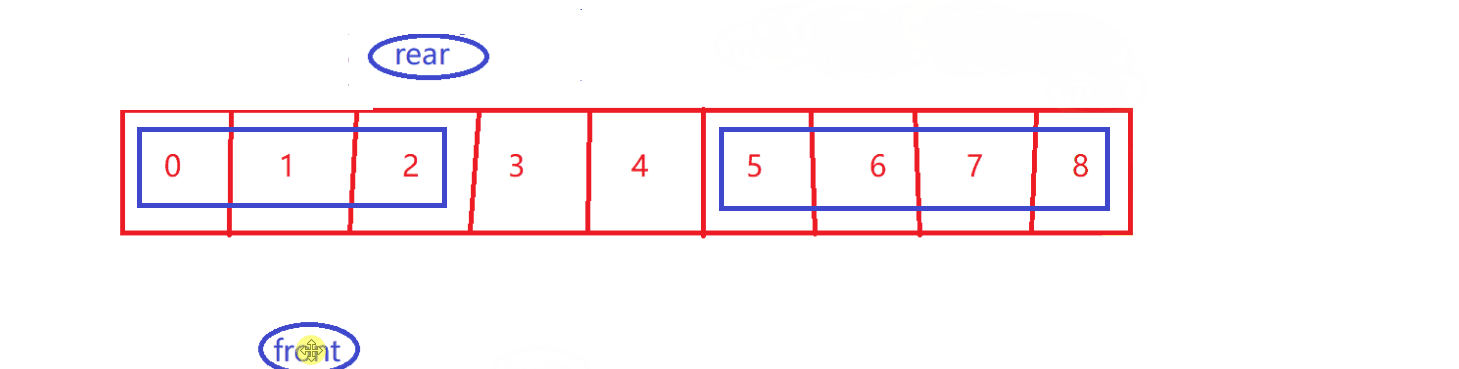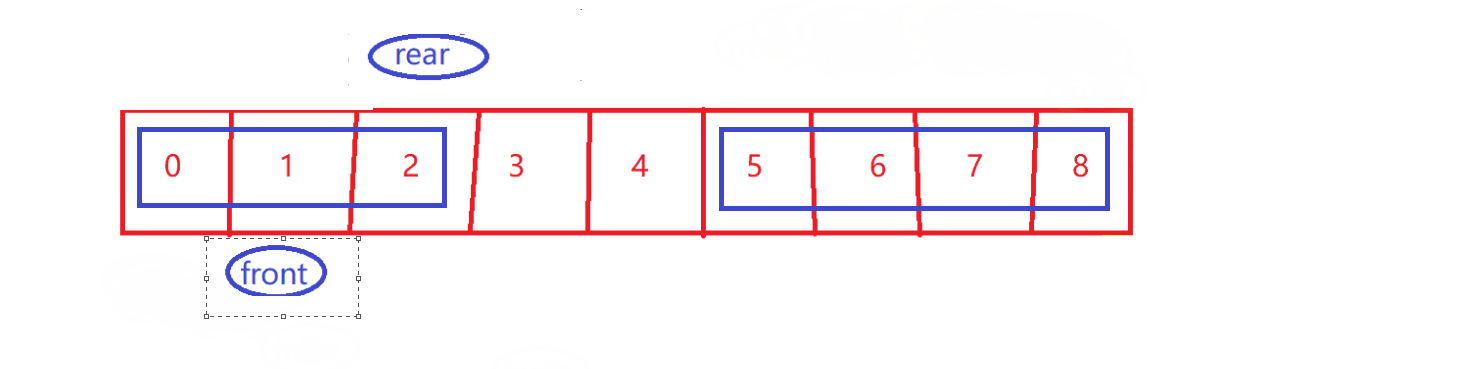
-
剩余的有效数据~
- front 到 rear
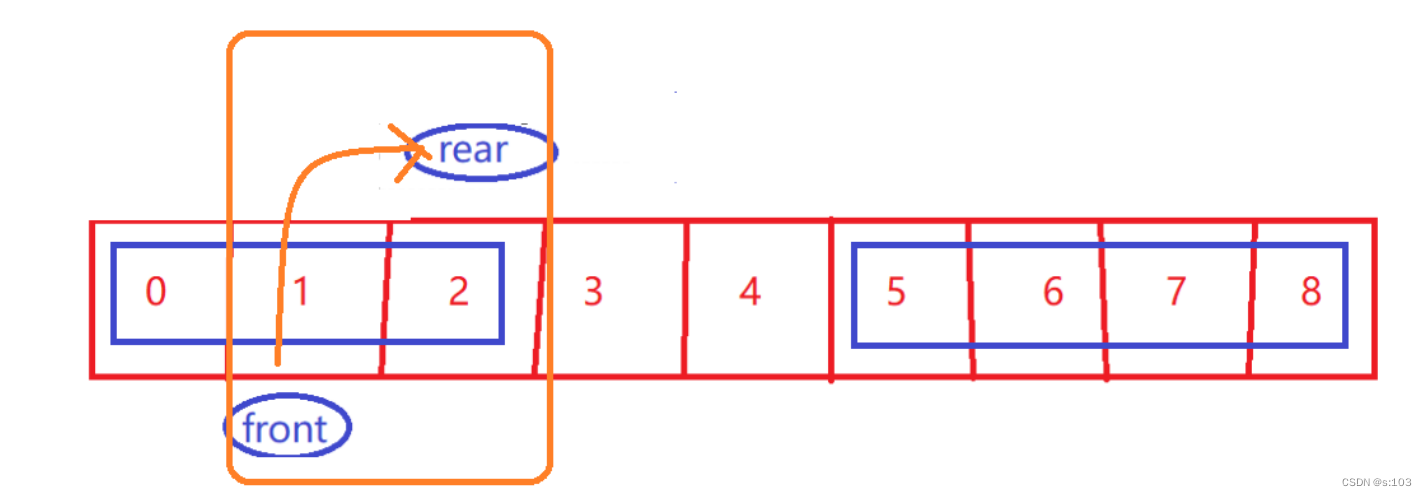
-
判断空
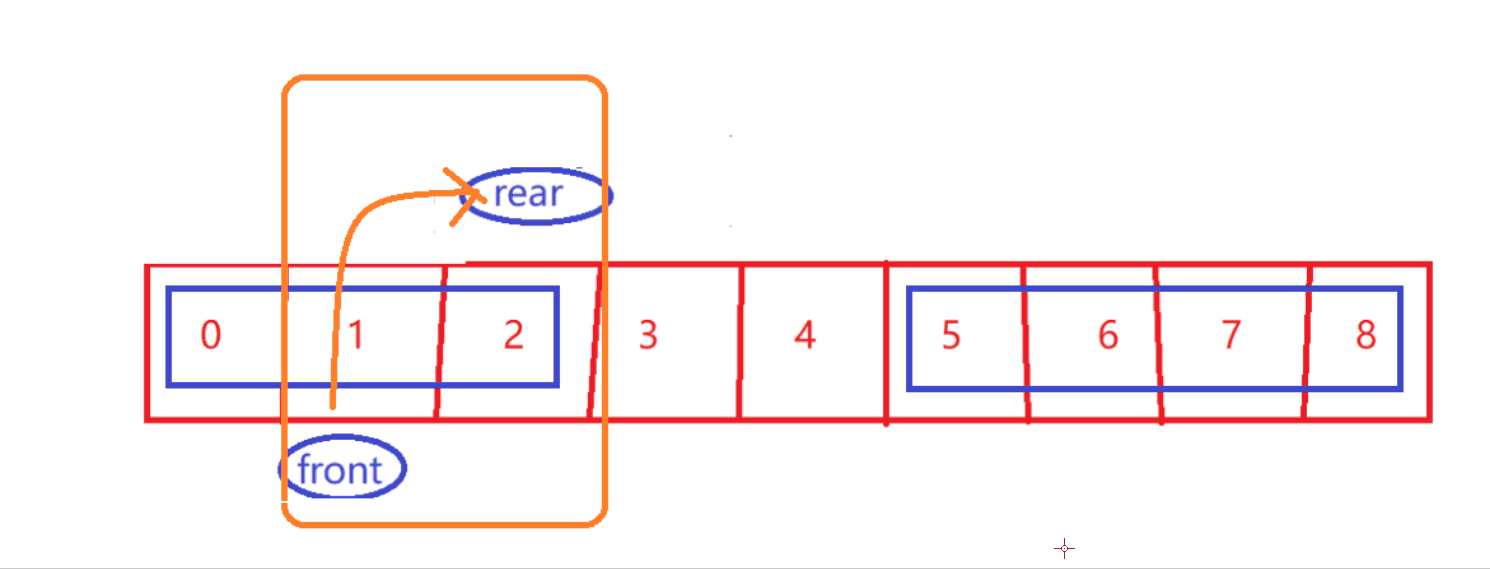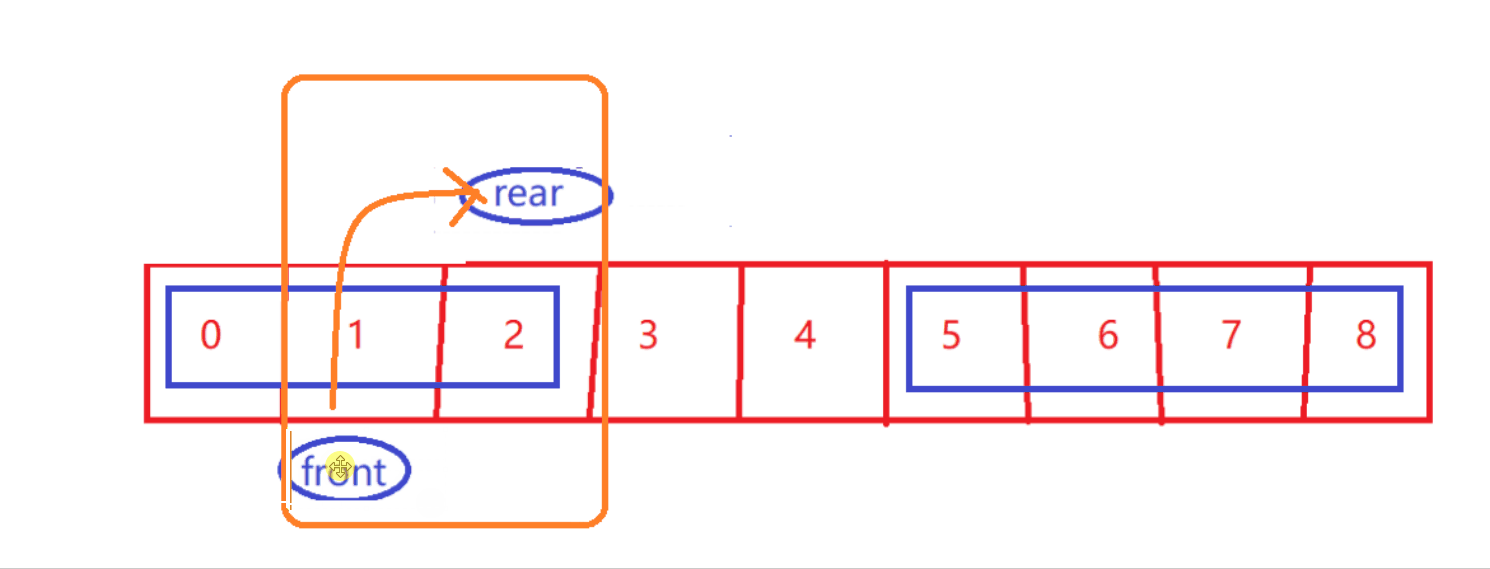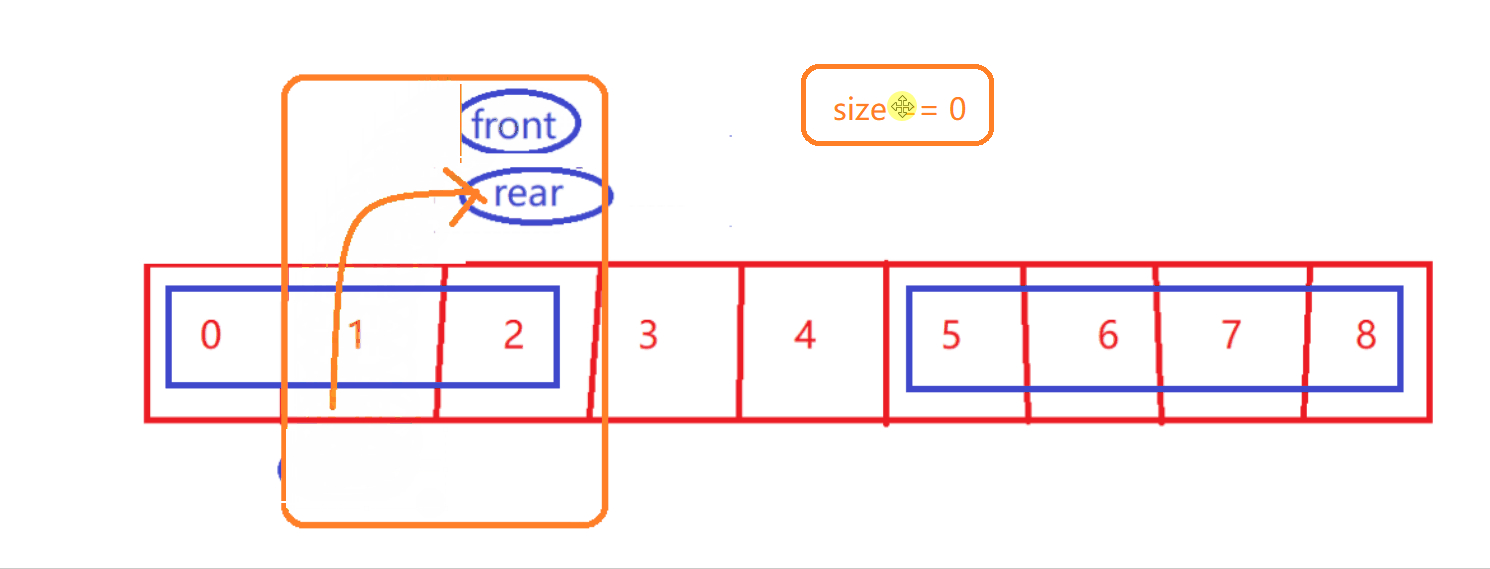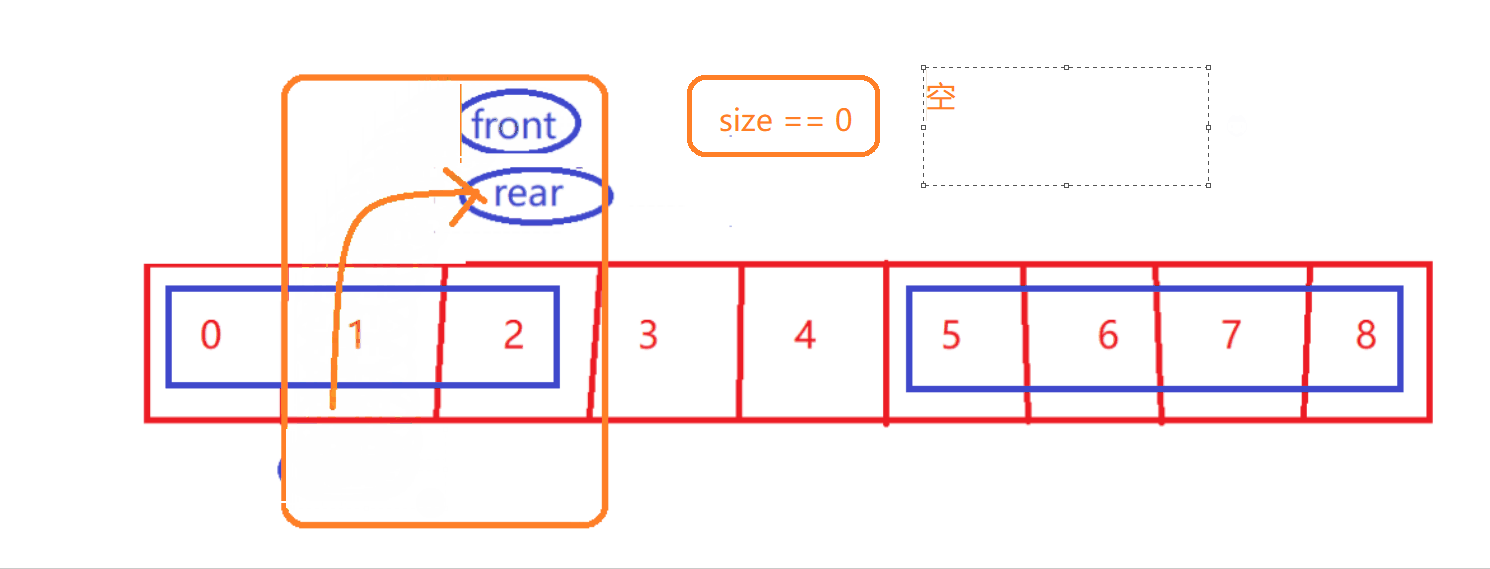
- size == 0
-
判断满
-
size == items.length
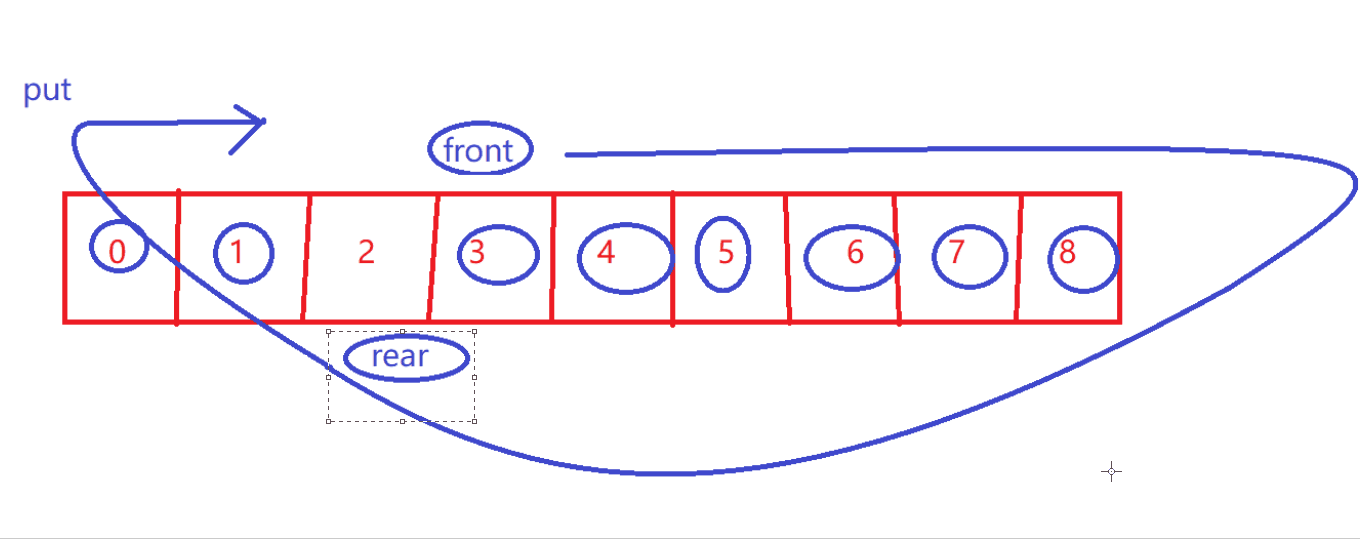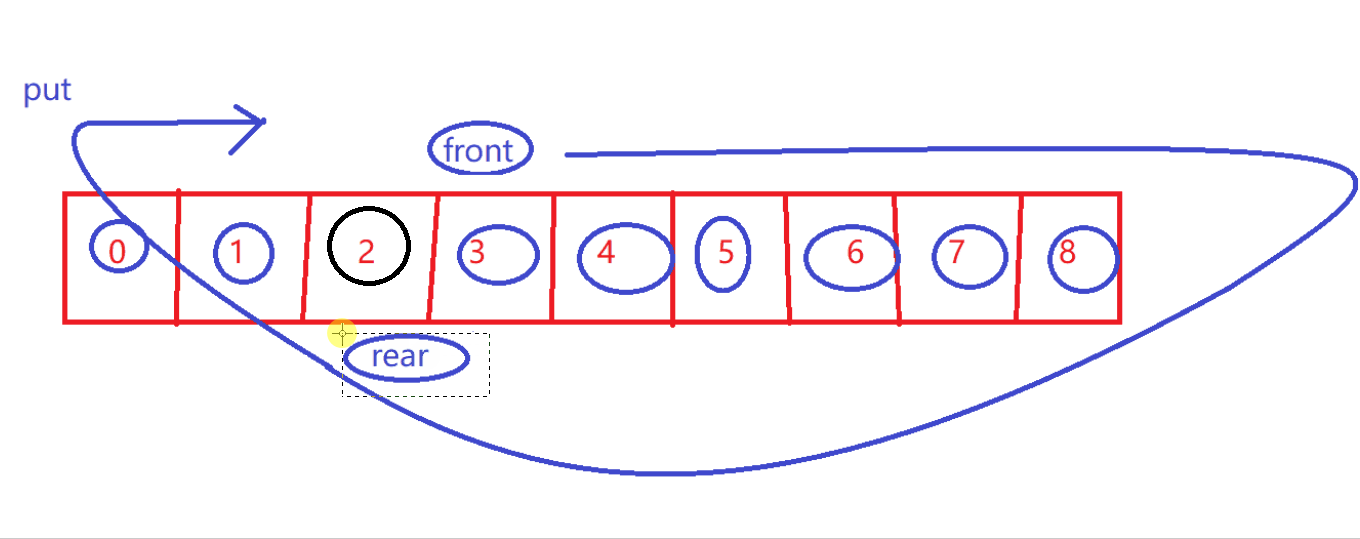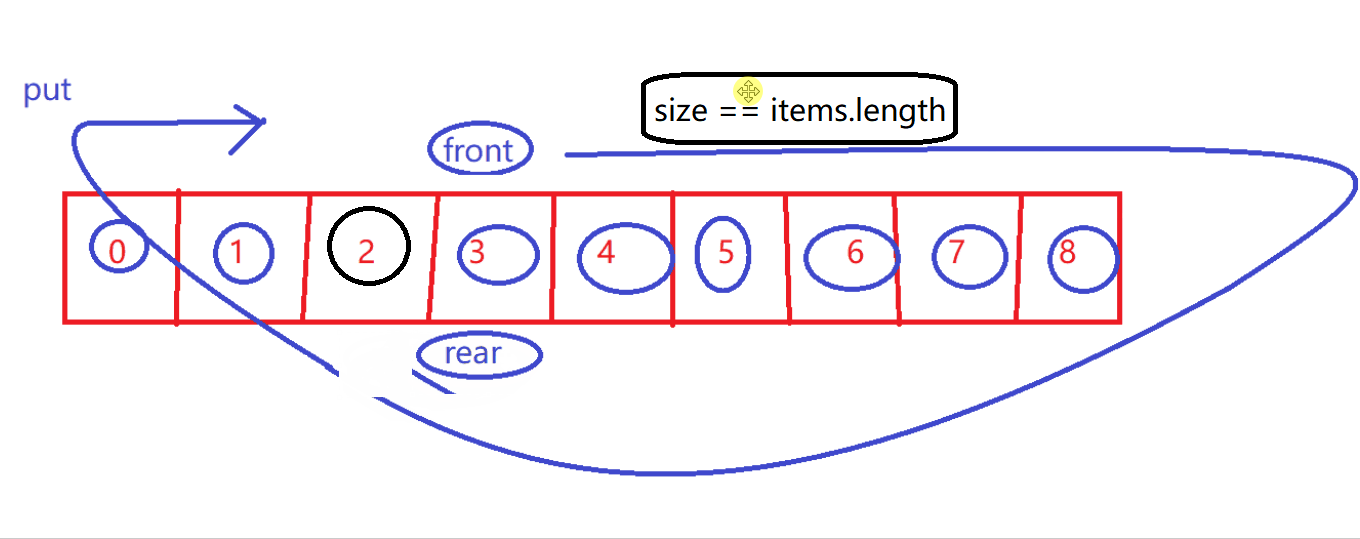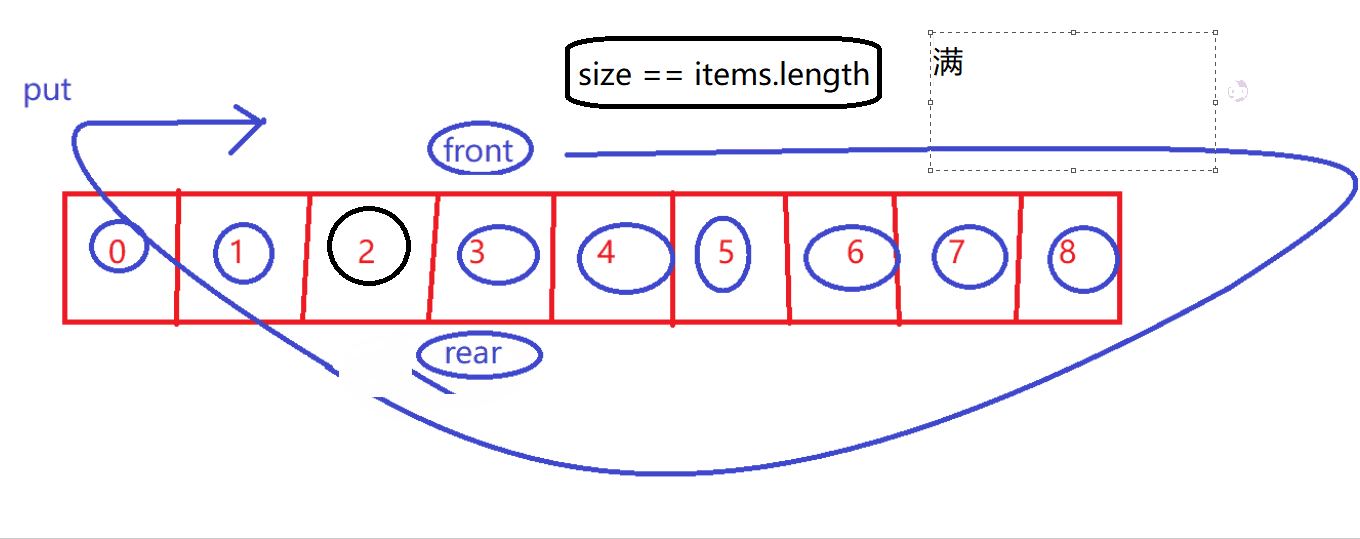
-
size == items.length
3.5.6 修复小瑕疵
- 概率特别特别小,但是一旦bug,会导致巨大亏损

-
interrupt
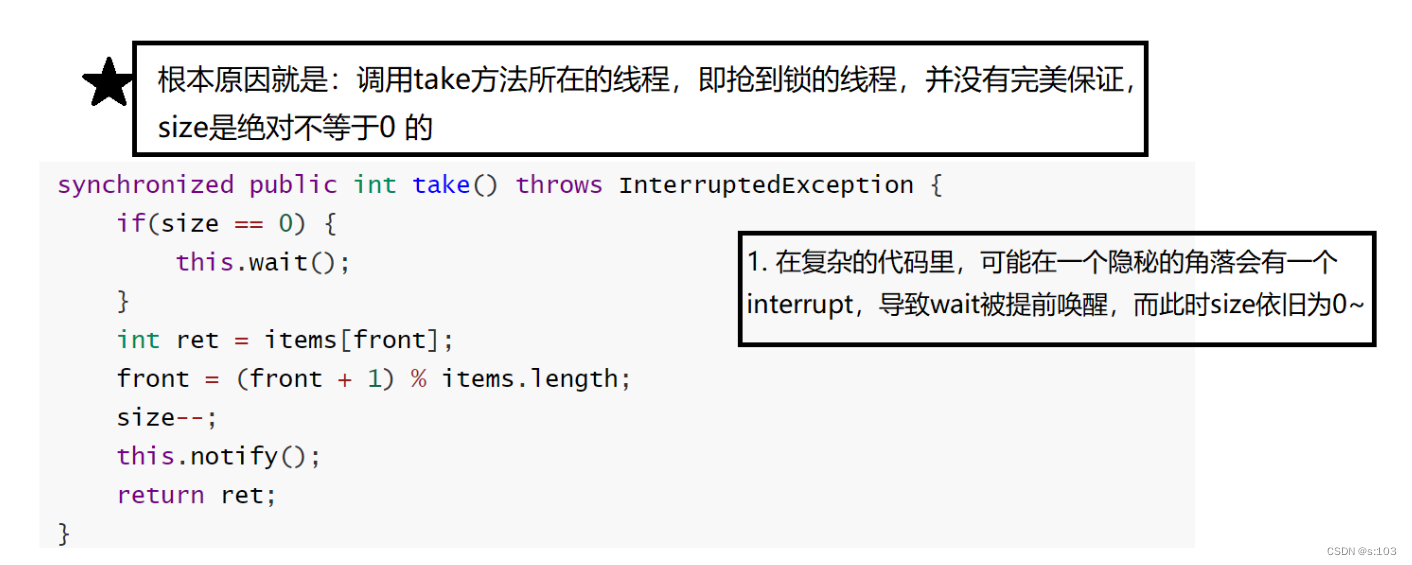
- 被抢锁

-
图示:
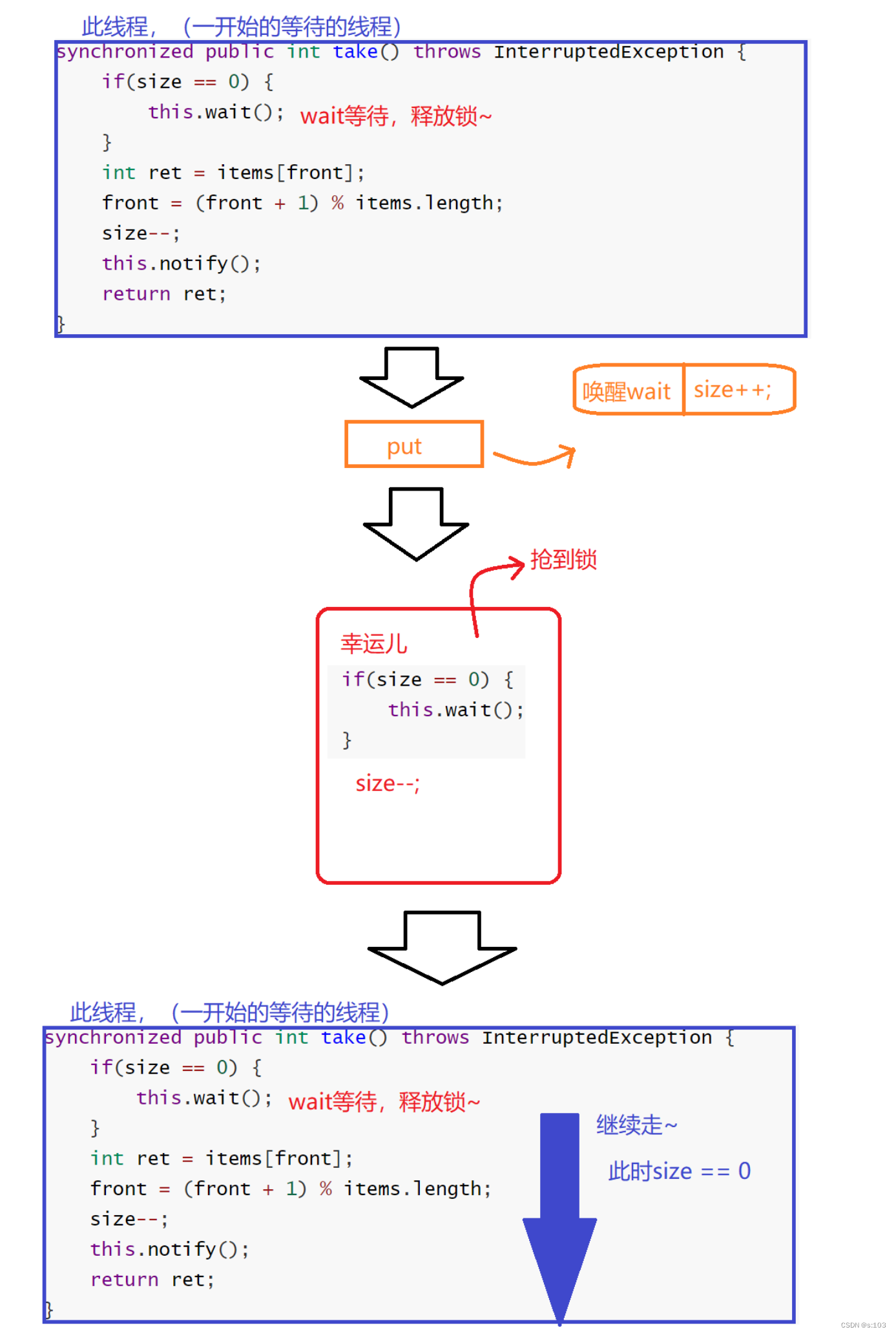
-
解决方案:
-
使用while循环,保证抢到锁的时候,size为0才能
继续走
~ - 一旦发现size依旧为0,继续等待~
- size为0无法再减减,所以一定不存在size小于0的情况~
-
使用while循环,保证抢到锁的时候,size为0才能
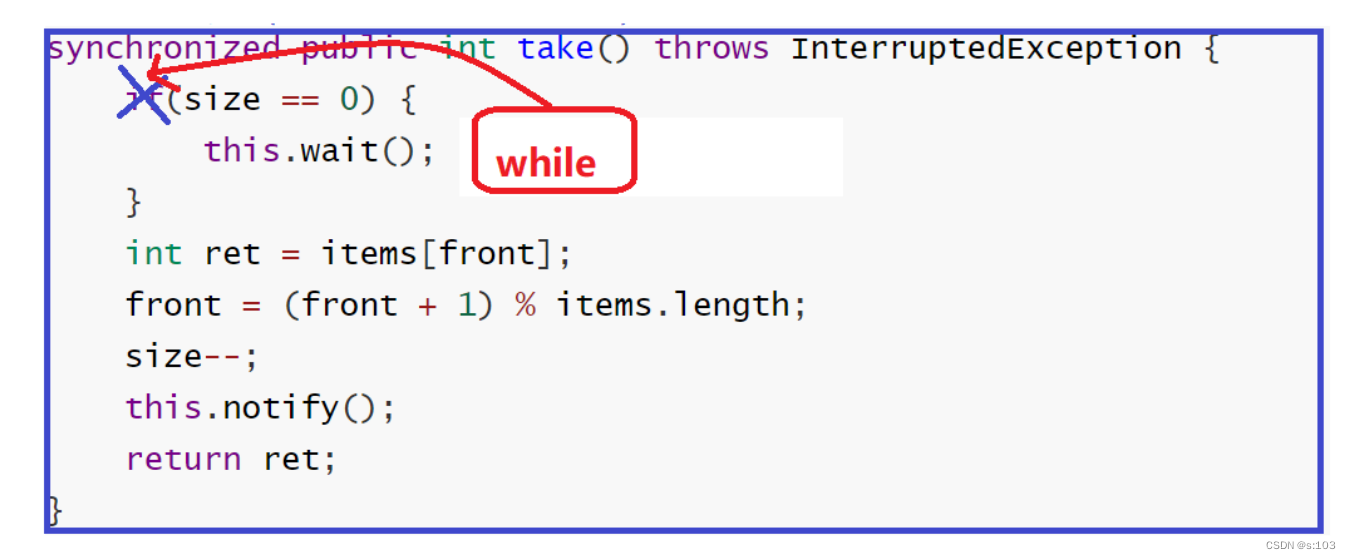
-
take最终版:
synchronized public int take() throws InterruptedException {
while(size == 0) {
this.wait();
}
int ret = items[front];
front = (front + 1) % items.length;
size--;
this.notify();
return ret;
}
-
put最终版:
-
同样的put也有相同的问题~
synchronized public void put(int value) throws InterruptedException {
while(size == items.length) {
this.wait();
}
items[rear] = value;
rear = (rear + 1) % items.length;
size++;
this.notify();
}
3.5.7 测试
-
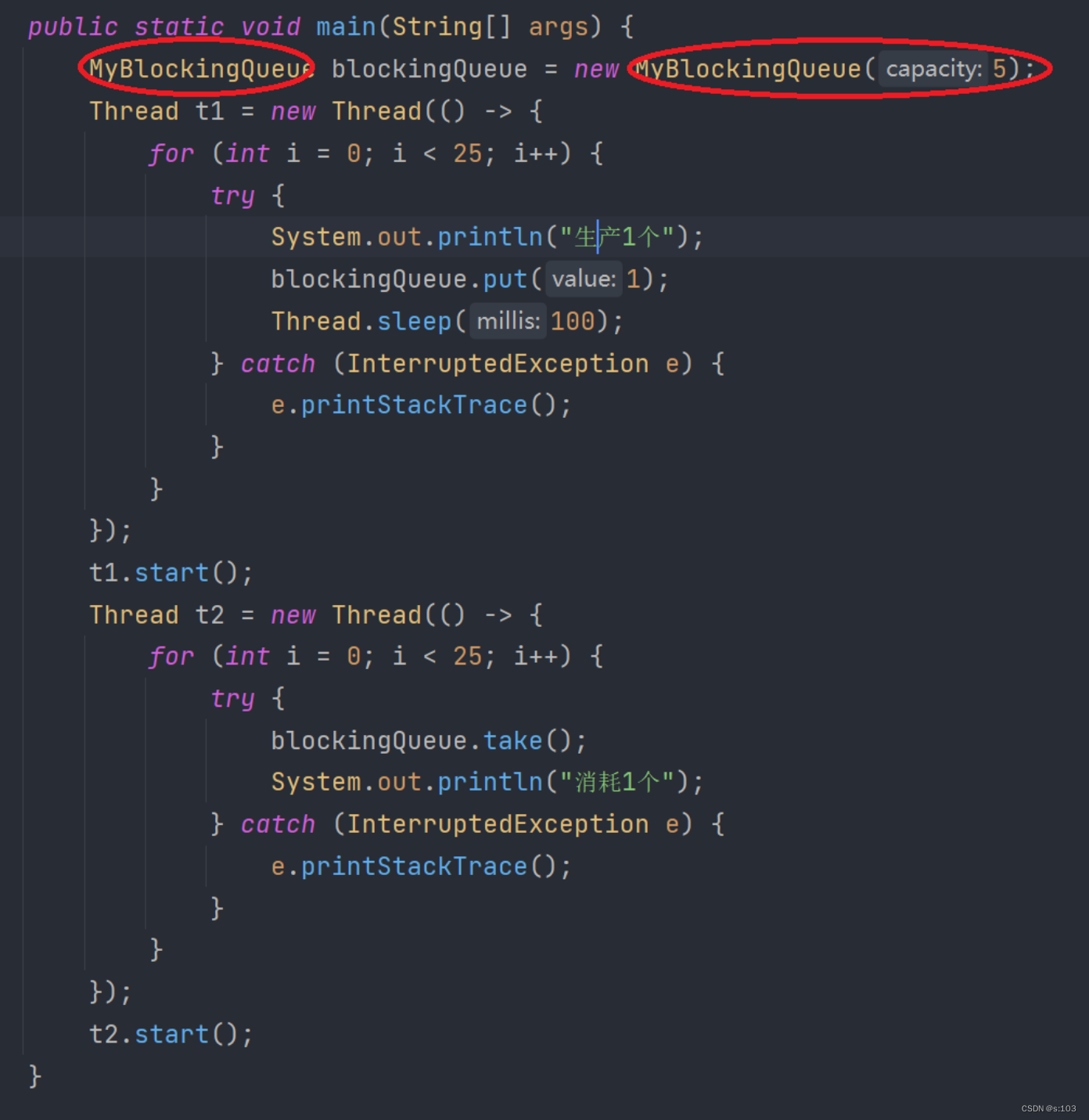
用3.4.3那个例子中,
BlockingQueue换成我们的阻塞队列MyBlockingQueue
~
- 结果正常~
文章到此结束!谢谢观看
可以叫我
小马
,我可能写的不好或者有错误,但是一起加油鸭
?
!