在lifelong比赛上下载了图片数据集,目标是将不同光照下不同视角物体的分类,每张图片只含有一种类别,一共有51个类别(有刀、订书机、杯子、勺子等),所以想到了用ResNet50做图片分类,顺便学习ResNet的背后原理。
论文阅读:Residual learning

在ResNet之前
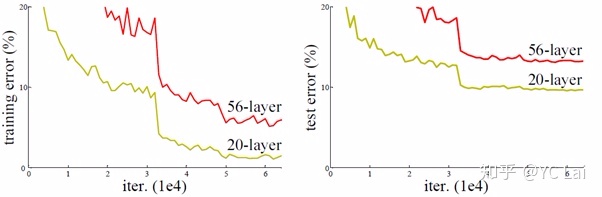
理论上,加深神经网络层数之后,网络应该可以对更为复杂的特征进行提取,但是实验的结果是发现网络会出现
退化问题(degradation problem)
:网络深度增加时,网络的训练问题反而上升了。
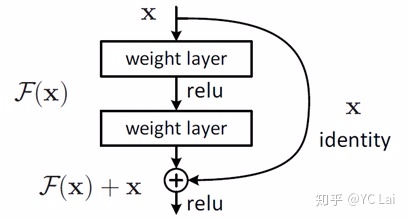
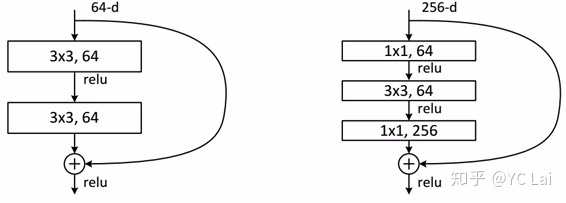
残差学习
如果想继续堆积新层来建立深层网络,一个极端的情况就是增加的层什么也不学习,做一个
恒等映射(identity mapping)
。残差学习提出了一个结构,相比之前的结构引入了一个
短路连接(shortcut connection)
,只学习残差项,因为残差学习比较原始特征学习更为容易,如果学习到的残差值为0,就相当于做了一个恒等映射,至少网络的性能不会下降。
残差学习到的内容比较少,学习难度小,从数学角度分析:
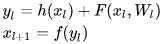
其中
和
分别表示的是第
个残差单元的输入和输出,注意每个残差单元一般包含多层结构。
是残差函数,表示学习到的残差,而
表示恒等映射
,
是ReLU激活函数。基于上式,我们求得从浅层
到深层
的学习特征为:
利用链式规则,可以求得反向过程的梯度:
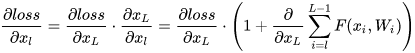
式子的第一个因子
表示的损失函数到达
的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意
上面的推导并不是严格的证明
。
以上的内容摘自(有略)
:
你必须要知道CNN模型:ResNet – 小小将的文章 – 知乎
(有空再补全一下ResNet背后的数学推导)
也可以参考一下大神对ResNet的另一种角度的解读:
对ResNet本质的一些思考 – 黄二二的文章 – 知乎
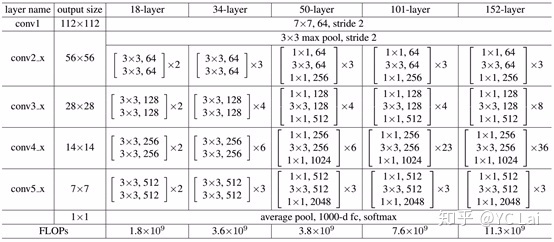
网络框架
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在
ResNet直接使用stride=2的卷积做下采样
,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:
当feature map大小降低一半时,feature map的数量增加一倍
,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1×1,3×3和1×1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
代码块:
1 卷积块
def conv_op(x, name, n_out, training, useBN, kh=3, kw=3, dh=1, dw=1, padding="SAME",
activation=tf.nn.relu):
'''
x: 输入
kh,kw: 卷集核的大小
n_out:输出的通道数
dh,dw: strides大小
name: op的名字
'''
n_in = x.get_shape()[-1].value
with tf.name_scope(name) as scope:
w = tf.get_variable(scope + "w", shape=[kh, kw, n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
b = tf.get_variable(scope + "b", shape=[n_out], dtype=tf.float32,
initializer=tf.constant_initializer(0.01))
conv = tf.nn.conv2d(x, w, [1, dh, dw, 1], padding=padding)
z = tf.nn.bias_add(conv, b)
if useBN:
z = tf.layers.batch_normalization(z, trainable=training)
if activation:
z = activation(z)
return z2 最大池化层以及平均池化层
def max_pool_op(x, name, kh=2, kw=2, dh=2, dw=2, padding="SAME"):
return tf.nn.max_pool(x,
ksize=[1, kh, kw, 1],
strides=[1, dh, dw, 1],
padding=padding,
name=name)
def avg_pool_op(x, name, kh=2, kw=2, dh=2, dw=2, padding="SAME"):
return tf.nn.avg_pool(x,
ksize=[1, kh, kw, 1],
strides=[1, dh, dw, 1],
padding=padding,
name=name)3 全连接层
def fc_op(x, name, n_out, activation=tf.nn.relu):
n_in = x.get_shape()[-1].value
with tf.name_scope(name) as scope:
w = tf.get_variable(scope + "w", shape=[n_in, n_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable(scope + "b", shape=[n_out], dtype=tf.float32,
initializer=tf.constant_initializer(0.01))
fc = tf.matmul(x, w) + b
out = activation(fc)
return fc, out
做分类的时候,最后接的是一个全连接层,然后得到的是 [batch
size, class_number
] 的概率矩阵,这个结果是需要跟ground truth进行比较得到最终的loss的,但这里不需要用到out这个结果,
用到的是fc这个结果
(用out矩阵去与ground truth比较反而训练的误差降不下去)
4 res block
把上面的各个子块写好,就组建res 子块(就上面图的残差单元)
def res_block_layers(x, name, n_out_list, change_dimension=False, block_stride=1):
if change_dimension:
short_cut_conv = conv_op(x, name + "_ShortcutConv", n_out_list[1], training=True, useBN=True, kh=1, kw=1,
dh=block_stride, dw=block_stride,
padding="SAME", activation=None)
else:
short_cut_conv = x
block_conv_1 = conv_op(x, name + "_lovalConv1", n_out_list[0], training=True, useBN=True, kh=1, kw=1,
dh=block_stride, dw=block_stride,
padding="SAME", activation=tf.nn.relu)
block_conv_2 = conv_op(block_conv_1, name + "_lovalConv2", n_out_list[0], training=True, useBN=True, kh=3, kw=3,
dh=1, dw=1,
padding="SAME", activation=tf.nn.relu)
block_conv_3 = conv_op(block_conv_2, name + "_lovalConv3", n_out_list[1], training=True, useBN=True, kh=1, kw=1,
dh=1, dw=1,
padding="SAME", activation=None)
block_res = tf.add(short_cut_conv, block_conv_3)
res = tf.nn.relu(block_res)
return res5 ResNet搭建
def bulid_resNet(x, num_class, training=True, usBN=True):
conv1 = conv_op(x, "conv1", 64, training, usBN, 3, 3, 1, 1)
pool1 = max_pool_op(conv1, "pool1", kh=3, kw=3)
block1_1 = res_block_layers(pool1, "block1_1", [64, 256], True, 1)
block1_2 = res_block_layers(block1_1, "block1_2", [64, 256], False, 1)
block1_3 = res_block_layers(block1_2, "block1_3", [64, 256], False, 1)
block2_1 = res_block_layers(block1_3, "block2_1", [128, 512], True, 2)
block2_2 = res_block_layers(block2_1, "block2_2", [128, 512], False, 1)
block2_3 = res_block_layers(block2_2, "block2_3", [128, 512], False, 1)
block2_4 = res_block_layers(block2_3, "block2_4", [128, 512], False, 1)
block3_1 = res_block_layers(block2_4, "block3_1", [256, 1024], True, 2)
block3_2 = res_block_layers(block3_1, "block3_2", [256, 1024], False, 1)
block3_3 = res_block_layers(block3_2, "block3_3", [256, 1024], False, 1)
block3_4 = res_block_layers(block3_3, "block3_4", [256, 1024], False, 1)
block3_5 = res_block_layers(block3_4, "block3_5", [256, 1024], False, 1)
block3_6 = res_block_layers(block3_5, "block3_6", [256, 1024], False, 1)
block4_1 = res_block_layers(block3_6, "block4_1", [512, 2048], True, 2)
block4_2 = res_block_layers(block4_1, "block4_2", [512, 2048], False, 1)
block4_3 = res_block_layers(block4_2, "block4_3", [512, 2048], False, 1)
pool2 = avg_pool_op(block4_3, "pool2", kh=7, kw=7, dh=1, dw=1, padding="SAME")
shape = pool2.get_shape()
fc_in = tf.reshape(pool2, [-1, shape[1].value * shape[2].value * shape[3].value])
logits, prob = fc_op(fc_in, "fc1", num_class, activation=tf.nn.softmax)
# 需要进入损失函数的是没有经过激活函数的logits
return logits, prob6 训练过程的搭建
def training_pro():
train_data_path, train_label = loadCSVfile(train_path) # 加载图片的路径 和 图片的label
batch_index = []
# 将 训练数据 分batch
for i in range(train_data_path.shape[0]):
if i % batch_size == 0:
batch_index.append(i)
if batch_index[-1] is not train_data_path.shape[0]:
batch_index.append(train_data_path.shape[0])
input = tf.placeholder(dtype=tf.float32, shape=[None, img_size, img_size, channel], name="input")
# output = tf.placeholder(dtype=tf.float32, shape=[None, num_classes], name="output")
output = tf.placeholder(dtype=tf.int64, shape=[None], name="output")
# 将label值进行onehot编码
one_hot_labels = tf.one_hot(indices=tf.cast(output, tf.int32), depth=51)
# 需要传入到softmax_cross_entropy_with_logits的是没有经过激活函数的y_pred
y_pred, _ = bulid_resNet(input, num_classes)
y_pred = tf.reshape(y_pred, shape=[-1, num_classes])
tf.add_to_collection('output_layer', y_pred)
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_pred, labels=output))
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y_pred, labels=one_hot_labels))
# 该api,做了三件事儿 1. y_ -> softmax 2. y -> one_hot 3. loss = ylogy
tf.summary.scalar('loss', loss)
# 这一段是为了得到accuracy,首先是得到数值最大的索引
# 准确度
a = tf.argmax(y_pred, 1)
b = tf.argmax(one_hot_labels, 1)
correct_pred = tf.equal(a, b)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 将上句的布尔类型 转化为 浮点类型,然后进行求平均值,实际上就是求出了准确率
# 标记一下:这里可以尝试一下GD方法,体验一下学习率调参,然后加个momentum功能试一下
train_op = tf.train.AdamOptimizer(lr).minimize(loss)
saver = tf.train.Saver(max_to_keep=10)
total_loss = 0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
merged = tf.summary.merge_all()
train_writer_train = tf.summary.FileWriter("logs_res/train", sess.graph)
train_writer_val = tf.summary.FileWriter("logs_res/val")
i = 0
while True:
for step in range(len(batch_index) - 1):
i += 1
x_train, _ = load_train(train_data_path[batch_index[step]:batch_index[step + 1]],
train_label[batch_index[step]:batch_index[step + 1]], img_size, num_classes)
y_train = np.array(list(train_label[batch_index[step]:batch_index[step + 1]]))
_a, _, loss_, y_t, y_p, a_, b_ = sess.run(
[merged, train_op, loss, one_hot_labels, y_pred, a, b],
feed_dict={input: x_train, output: y_train})
print('step: {}, train_loss: {}'.format(i, loss_))
if i % 20 == 0:
_loss, acc_train = sess.run([loss, accuracy], feed_dict={input: x_train, output: y_train})
print('--------------------------------------------------------')
print('step: {} train_acc: {} loss: {}'.format(i, acc_train, _loss))
print('--------------------------------------------------------')
if i % 10000 == 0:
saver.save(sess, 'model_1202/resnet50.model', global_step=i)7 图片加载到tensor之前的操作 (上面程序的 load_train)
就是做了一个图片的resize,以及用了keras库的针对resnet50的图片处理(from keras.applications.resnet50 import preprocess_input)
def load_train(train_path, train_label, img_size, classes):
"""
因为系统内存无法存储那么大的图像矩阵,只能一个batch地去读取图片
:param train_path: 经过batch_index 规定好范围的图片路径
:param train_label: 图片label
:param img_size: 默认224
:param classes: 有多少个类
:return: [batch, img_size, img_size, channel]的图像, [batch, num_classes]的label(经过one_hot)
"""
images = []
labels = []
for i in range(len(train_path)):
image = cv2.imread(train_path[i])
image = cv2.resize(image, (img_size, img_size), 0.0, interpolation=cv2.INTER_CUBIC)
image = image.astype(np.float32)
image = preprocess_input(image)
images.append(image)
label = np.zeros(classes)
label[train_label[i]] = 1.0
labels.append(label)
images = np.array(images)
labels = np.array(labels)
return images, labels
全部代码上传到 github 上:
github地址
8 试错
(1)这个程序最终在Geforce GTX TitanX(显存12G)跑的,之前试过在Geforce 1050(显存2G)跑,那么batch
size就得调得比较小,因为batch_size调大,
tensor需要暂时存储的空间变大。
(2)上面所说的 out 和 fc 的问题
(3)用于分类的loss函数有:tf.nn.sigmoid_cross_entropy_with_logits、tf.nn.softmax_cross_entropy_with_logits,因为现在是多分类的问题,本来看了很多资料应该是softmax会比较得好一些(每一张图片只有一种类别),但是在这里使用sigmoid函数表现得更好,可能因为类别中杯子1和杯子2或者不同的光照条件下会比较相似?总之
还是需要多多尝试不同的误差函数。
这几个分类的误差函数可以看看这个:如何选择不同的交叉熵?
9 结果
最终在验证集的识别正确率能达到98%。