大数据
相关技术
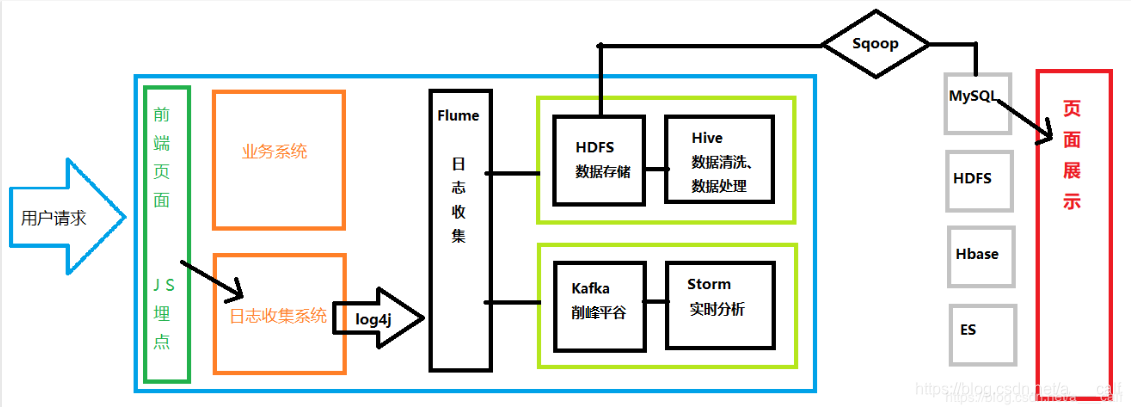
Flume:数据的收集聚集加载
Hadoop.HDFS:海量数据的存储
MapReduce、Hive、SparkSql:数据的离线处理
Kafka、flink、SparkStreaming:数据的实时处理
Hbase:数据库
Sqoop:HDFS和关系型数据库桥梁
Hadoop基础
Hadoop:分布式海量离线数据存储处理平台
重要组成部分:
HDFS:海量数据的存储(起源于Google论文《Google File System》)
MapReduce:海量离线数据的处理(起源于Google论文《MapReduce》)
Yarn:集群资源协调管理(使Hadoop.HDFS可以对接更多的应用(如Hbase、Spark等))
日志的捕获
JS埋点:将参数系数组织起来发送到日志收集系统。(传统后台埋点,影响后台维护和运行;script标签内发送影响前端逻辑,最后选择以img标签实现埋点信息的发送)
Log4j:收集日志,在打印同时,输出到flume中。
Flume:数据的收集聚集加载
离线分析
HDFS(Hadoop的一部分):海量数据的存储
Hive(底层基于Hadoop):海量离线数据的处理
实时分析
Storm:流式数据处理(速度最快)
Kafka:消息队列,削峰平谷
HDFS详解

NameNode
HDFS集群中的老大,负责元数据信息(文件分为几块,备份几份,每一份都存在哪里的描述信息)的存储和整个集群工作的调度。
DataNode
集群中干活的小弟,存放文件块,记录自己存放文件的基本信息。
Block
文件块,Hadoop1.0时,每块64M。Hadoop2.0时,每块128M。默认备份三份。
SecondaryNameNode
NameNode的小秘,帮助NameNode干一些其他的事情(对fsimage和edits进行合并)。分担NameNode的压力。
HDFS优点
可以存储超大文件(无限拓展)
高容错,支持数据丢失自动恢复
可以构建在廉价机上
HDFS缺点
做不到低延迟访问
不支持超强的事务
不适合存大量小文件(如果有大量小文件存储在DataNode中,会使得DataNode的存储空间浪费,NameNode也会存储大量元数据信息,导致检索的速度变慢,而且使得NameNode的压力增大。)
不支持行级别的增删改(因为每一块Block的文件大小是固定的,如果在中间增数据,会使得文件块大小发生改变,使得后边的文件快也会随之改变,而且备份文件也会随之而发生生变化,NameNode肯定会重新生成存储文件的元数据信息,效率很慢,NameNode的工作量也会大大增加。后面版本支持在最后一个文件快中追加数据,但是官方表示不建议使用。)
HDFS细节图解
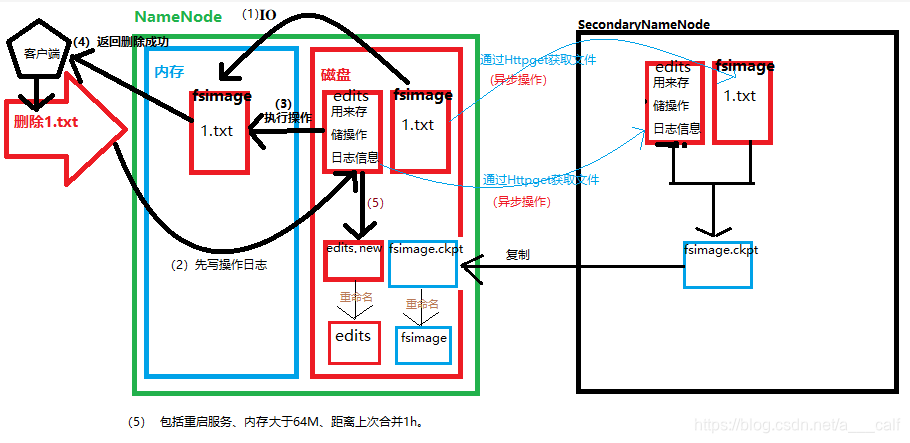
(注:上图中两条蓝色的线的过程错误,原图删除不方便修改,正确的是复制过程;(5)中的第二个是达到了64M)
Block备份如何放置?
第一份:如果该文件本身从Hadoop集群中的某个节点上传,那么第一份存放在上传节点中,如果从Hadoop集群之外上传,那么存放在相对不太忙,负载较小的节点上。
第二份:放在与第一份所放置的节点相邻机架上的某个节点上。
第三份:放在与第二份所在节点的机架上的另外一台机器上。
三份以上,放置在负载相对较小的节点上。
Yarn
Hadoop中的大管家,负责整个集群的资源管理调度。主要用于管理MapReduce相关资源。
原来HDFS中的数据只能被MapReduce直接处理,引入Yarn之后可以支持多种数据处理工具的接入,包括Spark等(相当于插排)。
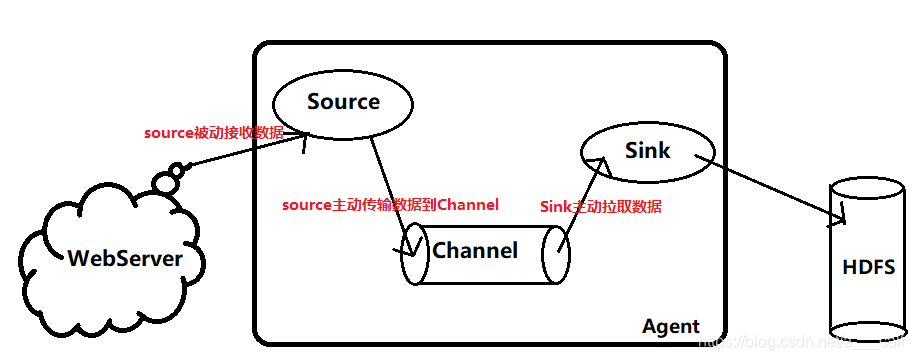
Flume
分布式日志收集系统,支持接收多种数据来源,可以对日志信息进行简单处理,然后写出到数据存储系统中。
重要概念
Event:事件,数据载体,flume将一批日志数据包装成为一个event进行传输处理,其结构非常简单,就是json串。Eg:{“headers”:info,”body”:info}其中header中的数据是我们自定义的一些内容,或者默认的内容。Body中的数据就是日志本身。
Agent:代理,就是flume包装、承载、传输event到目的地的过程。这个过程中包含三部分(source、channel、sink)。
Source:数据源,接收日志信息并将其包装为一个一个的event,传到channel中。
Channel:通道,被动接收source传来的数据,并将其暂时存储,等待sink的消费。
Sink:水槽,指定该agent数据传输的目的地,消费channel中的数据加载到目的地。
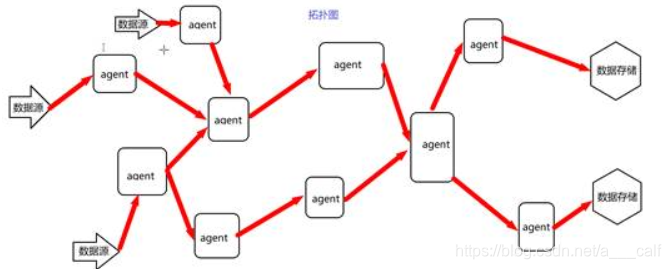
Flume多级流动

Flume的扇入扇出
扇入:多个数据来源一起流进同一个agent中。

扇出:一个agent中的数据流向多个数据出处。
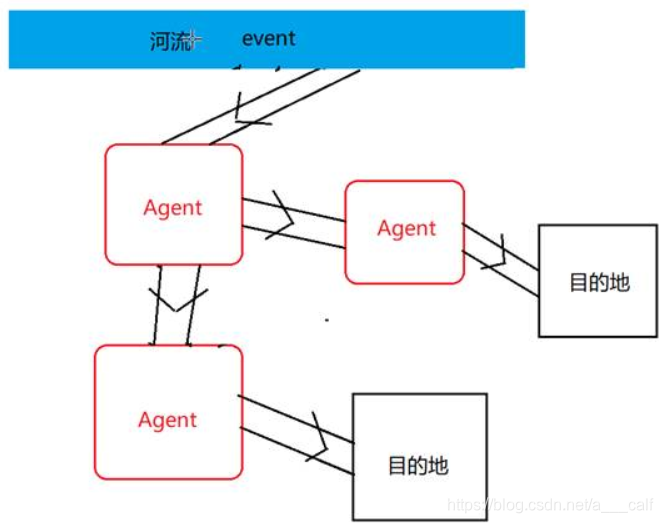
Flume的优势
基于flume的多级流动,扇入扇出,可以实现非常复杂的拓扑结构,适应处理几乎任何场景的数据。
Hive
Hadoop在分布式数据处理中遇到的问题
1)MR开发调试复杂,不适合要求快速得出结果的场景。
2)Hadoop由Java开发,对JAVA支持最好,对其他语言的使用者不够友好。
3)需要对Hadoop底层具有一定的了解,并且熟悉API才能开发出优秀的MR程序。
概述
Hive是一个建立在Hadoop基础之上的数据仓库工具,以HiveQL(类SQL)的操作方式让我们能够轻松的实现分布式的海量离线数据处理。而不必去编写调试繁琐的MR程序。

优点:
1)避免了MR繁琐的开发调试过程,Hive自动将我们输入的HQL编译为MR运行
2)HQL这种类SQL语言对于任何开发语言的程序员来说都比较友好。
3)我们不需要对Hadoop底层有太多的理解,也不用记忆大量的API就能实现分布式数据的处理
4)Hive也提供了自定义函数的方式来补充自身函数库可能存在的不足。即编写JAVA代码来实现复杂的逻辑并封装为UDF(自定义函数)来供我们重复使用。
数据仓库
数据仓库是一个面向主题的,稳定的,反应历史数据的数据存储工具,他主要支持管理者的决策分析。

本节总结:
Hive其实就是在Hadoop外边套了一层壳,底层其实就是Hadoop,数据存储用HDFS,数据处理用MR,不同的是我们在数据处理中不需要再去编写复杂的MR而是用简单的类SQL(HiveQL)就能实现海量离线数据的分析。
Hive的设计其实非常简单,其中数据库和表都是HDFS中的文件夹,而数据则是文件夹中的文件。Hive只是来维护这些文件夹和文件的关系。
Hive原生的使用Derby(内嵌式关系型数据库)作为元数据库,但是Derby具有天生的缺点,不能用作生产环境(derby默认在启动目录下创建一个metastore_db的文件夹来保存元数据,这样不安全。并且derby这样的内置数据库,性能稍差。实际生产中,会将derby替换,官方提供了建议方案,mysql oracle一般使用mysql替换derby作为hive的元数据库),所以我们需要将它替换成mysql来作为我们的元数据库。注意!!!元数据库中hive表的字符集必须是latin1!!!否则在执行Hql过程中会报错!
Hive为什么要用传统关系型数据库来作为他的元数据库而不用HDFS来存储元数据?关系型数据库支持实时的增删改查!