目录
前言
实际业务场景中,数据分析师经常会被要求作出数据预估,已满足各式各样的需求,根据我的实际经验,本文结合案例介绍三种常用方法。
一、
DAU预估 with
Python
1、数据准备
创建底层表,表计算逻辑:由UU全量表计算起量至最新一天每天新增用户在最新一天的留存率。
2、DAU预估模型
预估逻辑说明

如Fig 1,其中R_0代表0天前留存率,N_0代表0天前新增,当天所有的留存和新增相乘加和便为DAU
目前的DAU预估模型根据现有留存预估偏移进行预估,该预估方式预估k天后的DAU主要需要实现几个逻辑:
-
如Fig2 在留存率序列队尾增加k个预估的用户的长期留存R_f,目前模型中以队尾30天的平均留存计算
-
如Fig2 在新增序列对首添加预估的新增N_f,模型中对应用户填写输入的新增
-
将增加了预估留存率和预估新增的新留存率序列和新增序列相乘加和
通过上述逻辑,循环预估1天后~k天后的DAU
3、预估算法
记:
-n天新增用户数为$$n_{n}$$
-n天新增用户且当前活跃数为$$r_{n}$$
k 天后达成DAU为$$r$$
所需新增用户数$$n_f$$
则:
用户n天的留存率 $$p_n=\frac{r_n}{n_n} $$
新增用户k天后留存 $$r_n=\sum\limits_{i=1}^{k}{n_f*p_k}=n_f\sum\limits_{i=1}^{k}{p_k}$$
存量用户k天后留存 $$r_s=\sum\limits_{j=1}^{\infty}{n_j*p_{j+k}}$$
由上两式可推出:
$$n_f=\frac{r-\sum\limits_{j=1}^{\infty}{n_j*p_{j+k}}}{\sum\limits_{i=1}^{k}{p_k}}$$
脚本代码
import pandas as pd
import datetime
from scipy import log
from scipy.optimize import curve_fit
func = {
'logarithmic':lambda x, a, b : a * log(x) + b,
'exponential':lambda x, a, b : x**a + b,
}
popt, pcov = curve_fit(func['logarithmic'], df['留存率'].index[1:],df['留存率'][1:])
target_dau = 31000000
future_days = (datetime.date(2020,3,31) - datetime.date(2020,3,12)).days
file_name = 'Downloads/DAU-新增日期结构_列表_20200312-20200312.csv'
def parse_csv(file_name):
df = pd.read_csv(file_name)
df['新增天数']=(pd.to_datetime(df['日期'],format='%Y-%m-%d')-pd.to_datetime(df['新增日期'],format='%Y%m%d')).map(lambda x: x.days)
df = df.loc[df['新增日期'] > 20180809].sort_values(by='新增日期',ascending=False).reset_index()
return df
def forecast_newuu_logarithmic_fitting(df, days, target_dau, asymptotic_retention_rate):
ret_list = list(df['留存率'])+[func['logarithmic'](x ,popt[0] ,popt[1]) for x in range(len(df),len(df)+days)]
dau_ret = sum([df['新增当日开机uu'][i]*ret_list[i+days] for i in range(min(len(ret_list)-days,len(df)))])
dau_ret_rate = sum(ret_list[:days])
new_uu_daily = (target_dau-dau_ret)/dau_ret_rate
new_ret = dau_ret_rate * (target_dau-dau_ret)/dau_ret_rate
return {
'预期newuu': int(new_uu_daily),
'存量用户留存': int(dau_ret),
'新增用户留存': int(new_ret)
}
def forecast_newuu_max_two_year(df, days, target_dau, asymptotic_retention_rate):
ret_list = list(df['留存率'])+[asymptotic_retention_rate]*(730-len(df))
dau_ret = sum([df['新增当日开机uu'][i]*ret_list[i+days] for i in range(min(len(ret_list)-days,len(df)))])
dau_ret_rate = sum(ret_list[:days])
new_uu_daily = (target_dau-dau_ret)/dau_ret_rate
new_ret = dau_ret_rate * (target_dau-dau_ret)/dau_ret_rate
return {
'预期newuu': int(new_uu_daily),
'存量用户留存': int(dau_ret),
'新增用户留存': int(new_ret)
}
def forecast_newuu(df, days, target_dau, asymptotic_retention_rate):
dau_ret = sum([df['新增当日开机uu'][i]*df['留存率'][i+days] for i in range(len(df)-days)]) + sum(df['新增当日开机uu'][-days:])*asymptotic_retention_rate
dau_ret_rate = sum(df['留存率'][:days])
new_uu_daily = (target_dau-dau_ret)/dau_ret_rate
new_ret = dau_ret_rate * (target_dau-dau_ret)/dau_ret_rate
return {
'预期newuu': int(new_uu_daily),
'存量用户留存': int(dau_ret),
'新增用户留存': int(new_ret)
}
if __name__ == '__main__':
print(forecast_newuu(df, 19, 31000000, 0.4))
print(forecast_newuu(df, 110, 36000000, 0.4))
print(forecast_newuu(df, 202, 41000000, 0.4))
print(forecast_newuu(df, 294, 51000000, 0.4))
print(forecast_newuu_max_two_year(df, 19, 31000000, 0.4))
print(forecast_newuu_max_two_year(df, 110, 36000000, 0.4))
print(forecast_newuu_max_two_year(df, 202, 41000000, 0.4))
print(forecast_newuu_max_two_year(df, 294, 51000000, 0.4))
print(forecast_newuu_logarithmic_fitting(df, 19, 31000000, 0.4))
print(forecast_newuu_logarithmic_fitting(df, 110, 36000000, 0.4))
print(forecast_newuu_logarithmic_fitting(df, 202, 41000000, 0.4))
print(forecast_newuu_logarithmic_fitting(df, 294, 51000000, 0.4))3.1、环境说明
脚本运行环境为 python3,需要 安装pandas 包
3.2
、渐进留存率asymptotic_retention_rate
预估的一个留存率,指超过一定天数后,留存率基本稳定为一个值
二、续费系数计算 with Excel
1、概念及公式
-
续费系数: 用户续费期望
-
预估续费系数: 以当前续费系数预估出用户未来某周(现在是计算18周)的续费系数
-
ROI(实时) = ((1*破冰价格+续费系数*续费价格) * 收益系数)/CPA
注:目前收益系数为0.7,表示苹果商店折扣 -
ROI(预估) = ((1*破冰价格+预估续费系数*续费价格) * 收益系数)/CPA
2、续费系数计算
(1)计算公式
记第 i 次付费期望为Ei
记订阅满 i 周用户为Ai
记订阅满 i 周用户且在续费人数为Bi
总续费期望:

(2)计算说明
按week_count、purchase_uu、renewal_uu对数据表进行透视
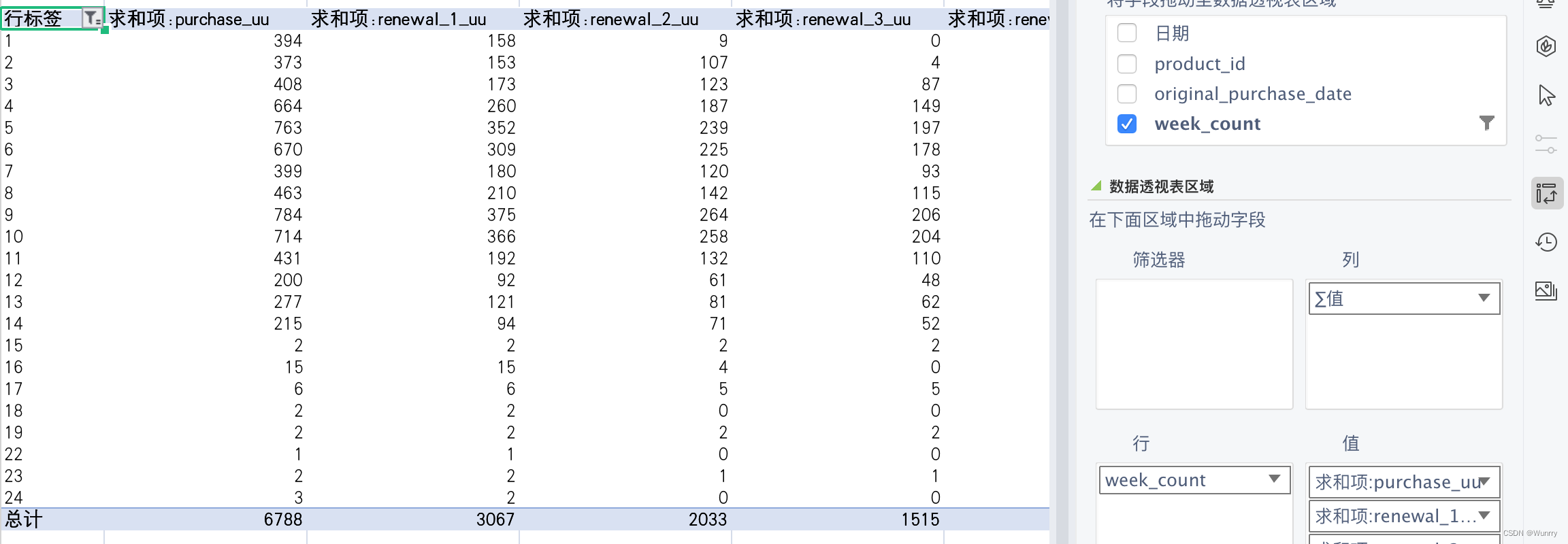
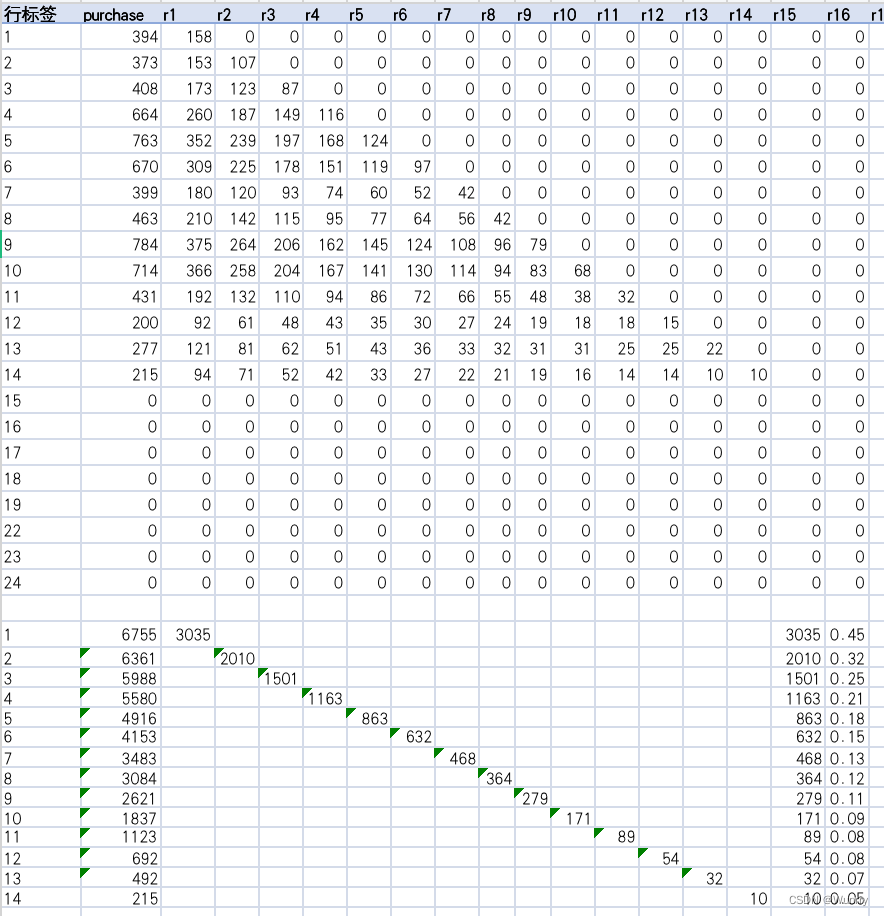
记订阅满 i 周用户为Ai,记订阅满 i 周用户且在续费人数为Bi,计算总付费期望
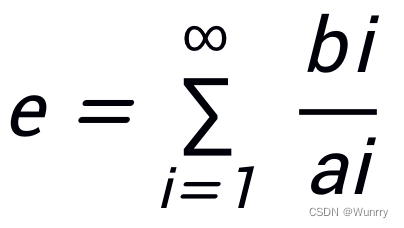
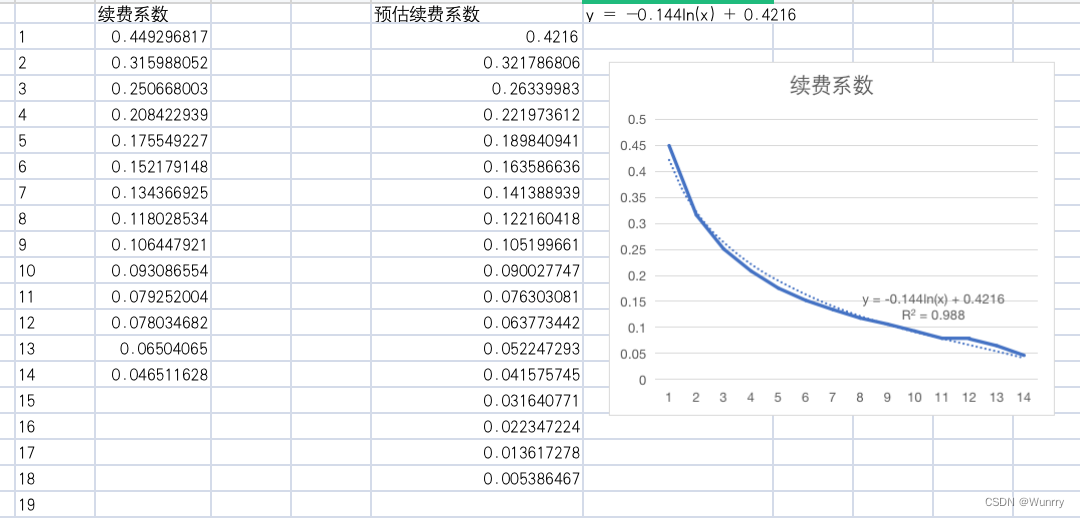
将续费系数做成折线图并添加拟合曲线,预估未来周的续费系数
三、LT720的算法 with SQL
理论:
1、对于满2年的渠道
n年LT = n年 内每天新增到昨天的留存率之和
2、对于满1.5年 但是不满2年的渠道
1)1年 / 1.5年 LT = 1年 / 1.5年 内每天新增到昨天的留存率之和
2)计算2年 LT 需要对不满2年的部分进行预估,预估方案:采用该渠道最前面30天的平均留存 * 0.7,作为不满两年 LT的预估值,那么最后的2年LT = 真实值 + 预估值
3、对于满1年 但是不满1.5年的渠道
1)1年 LT = 1年 内每天新增到昨天的留存率之和
2)计算1.5年 和 2年 LT时,需要进行预估,预估方案同上
4、对于满3月 但是 不满1年的渠道
1)1年 / 1.5年 / 2年 LT = 真实值 + 预估值
5、对于不满3月的渠道,不予考虑
不进行自动计算,请业务同学根据渠道的留存 对比和此渠道类似的其他渠道,比如当前渠道A留存不满3个月,渠道A留存和渠道B留存差不多,那么渠道A的LT 参考渠道B的LT。在平台上展示-
6、对于新渠道
对于新开渠道来说,前期数据量级小,数据波动大,可信度不高,对于新渠道数据,会剔除掉新增 uu < 100的数据
代码
暂不公开,聪明的你肯定一听就会,若是笨蛋请收买作者。
总结
以上就是今天要讲的内容,本文简单介绍了三种数据预估的方法,除此之外,还有很多能使我们快速便捷预估数据的函数和方法。