原创不易,本文禁止抄袭、转载,多年爬虫实战开发经验总结,侵权必究!
一、爬虫任务
任务背景
:爬取实习僧网站Python实习数据
任务目标
:利用解析库Beautiful Soup解析网页并获得所需数据
二、解析
首先进入实习僧官网主页:
https://www.shixiseng.com
爬取一下实习僧IT互联网的Python实习信息,如下图:
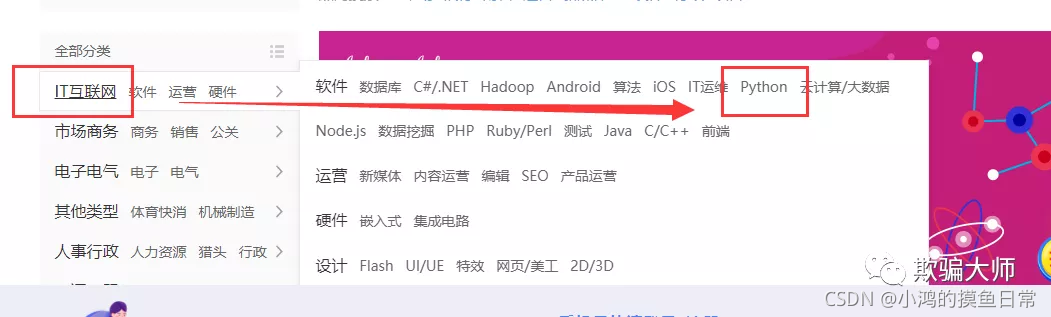

滑到页面最底部,点击下一页,观察URL的规律,如下图:

从上面的网址可以看出,只有page=?这里变化了
接着再点进去,查看相应的详细数据:
https://www.shixiseng.com/intern/inn_1k3vhcwwguaf?pcm=pc_SearchList
然后再查看相应源代码的属性,如下图:
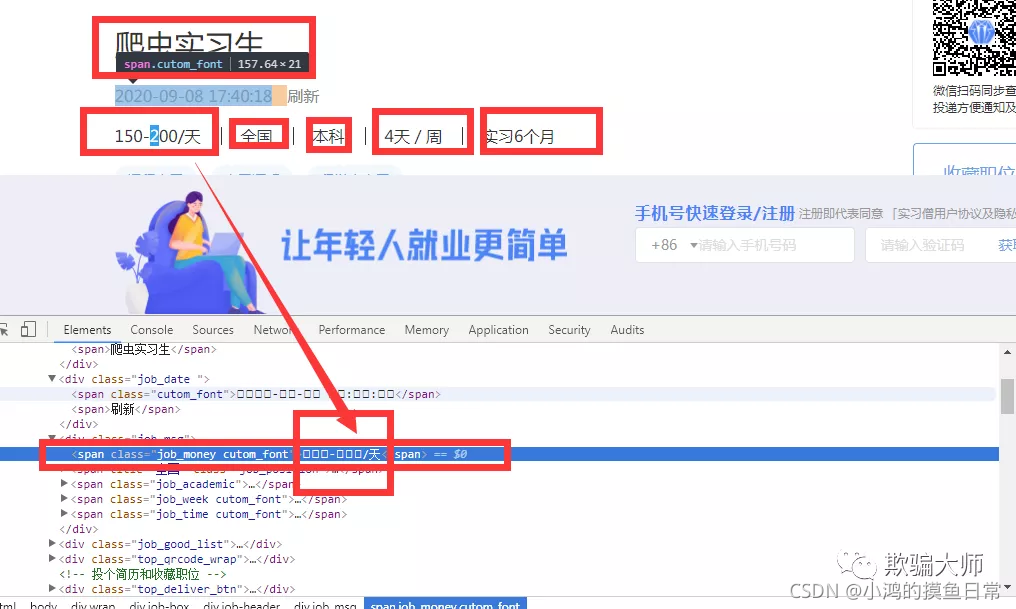
如上图所示,该字段的数据看不见,可能它不希望你很简单的就获得它网站的这些数据,这些数据对他来说比较重要,不想让我们轻易获得,所以启用了
反爬
如果直接运行,这些数据是爬取不下来的,如下图:
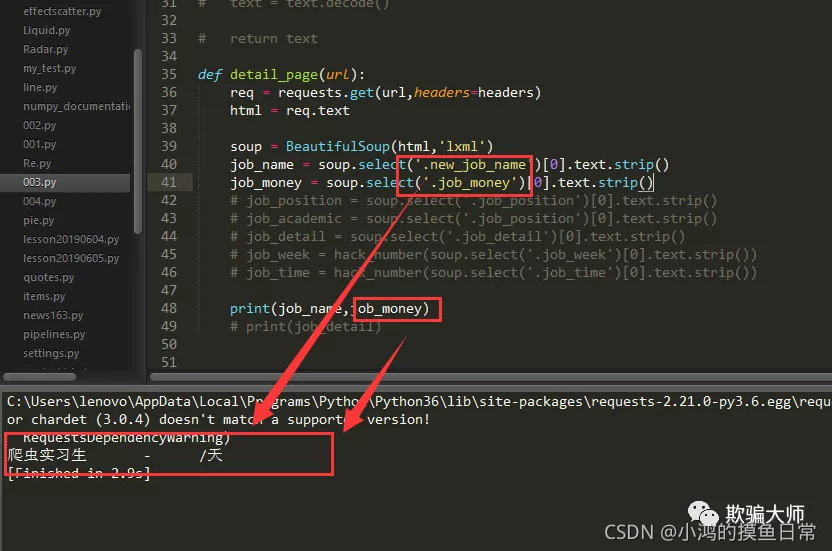
反反爬技巧
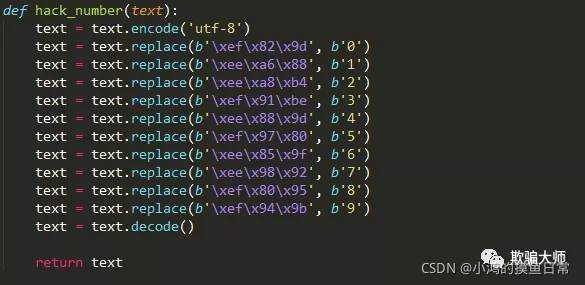
:实际上这是编码问题,我们只要用一种编码方式,比如“utf-8”编码来表示这些数据,然后再用你选的编码方式来替换相应的数据部分,如下图:
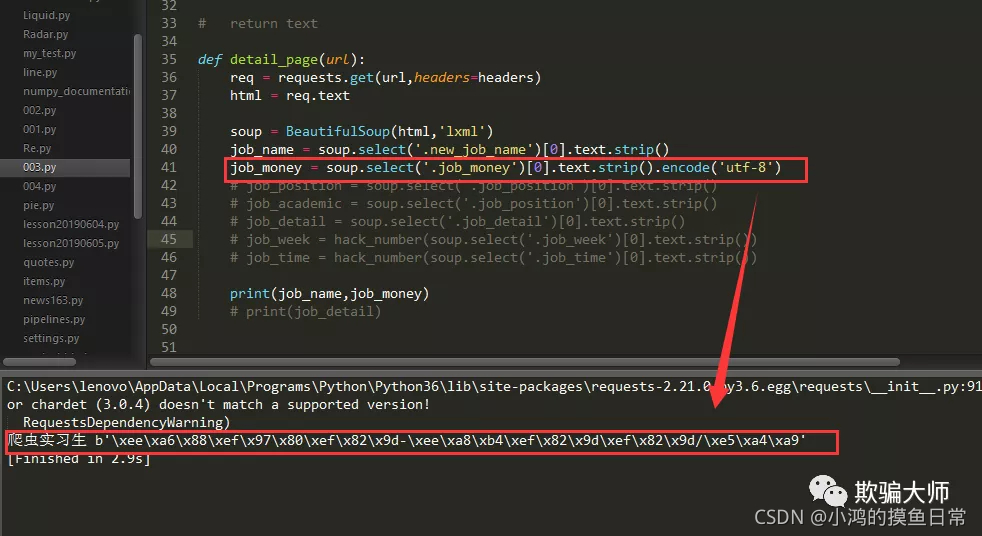
如上图,相关数据已经以“utf-8”编码的方式呈现出来
创建函数hack_number(),用于解码数字:
然后再观察一下点进去的网址:

我们这里是
先广度再深度
进行爬取数据
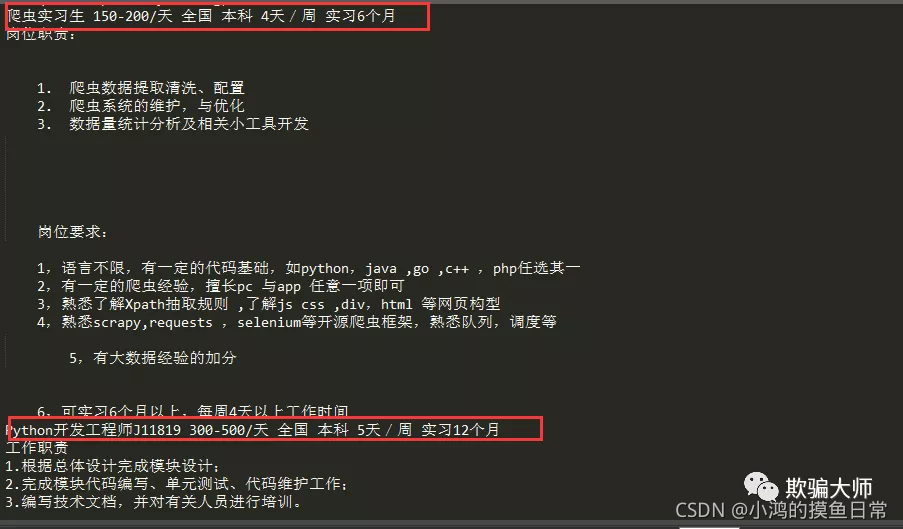
编写好相关代码之后,查看运行结果:
三、源码下载
CSDN源码下载链接:
下载源码
原创不易,如果觉得有点用,希望可以随手点个赞,拜谢各位老铁!
四、作者Info
作者:小鸿的摸鱼日常,Goal:让编程更有趣!
专注于算法、爬虫,网站,游戏开发,数据分析、自然语言处理,AI等,期待你的关注,让我们一起成长、一起Coding!
转载说明:本文禁止抄袭、转载 ,侵权必究!