携程,一家中国领先的在线票务服务公司,从 1999 年创立至今,数据库系统历经三次替换。在移动互联网时代,面对云计算卷积而来的海量数据,携程通过新的数据库方案实现存储成本降低 85% 左右,性能提升数倍。本文讲述携程在历史库场景下,如何解决水平扩容、存储成本、导入性能等痛点,以及对于解决方案的制定和思考过程。
自创立之初,携程前期业务以使用 SQL Server 数据库为主。在 MySQL 传入国内并大行其道时,携程也在 2016-2018 年将数据库逐步从 SQL Server 转到 MySQL 数据库。但是,随着技术多元化及业务的不断发展,MySQL 逐渐显露瓶颈,如扩容工艺复杂、数据存储成本高、表相关维护操作耗时等,如今已无法满足携程需求。
因此,携程在生产环境数据量过大时,尝试将生产环境中业务访问极少的冷数据归档到历史库,以减少生产环境中的数据量,降低生产环境中的查询时延、表结构变更时延等关键性能指标。
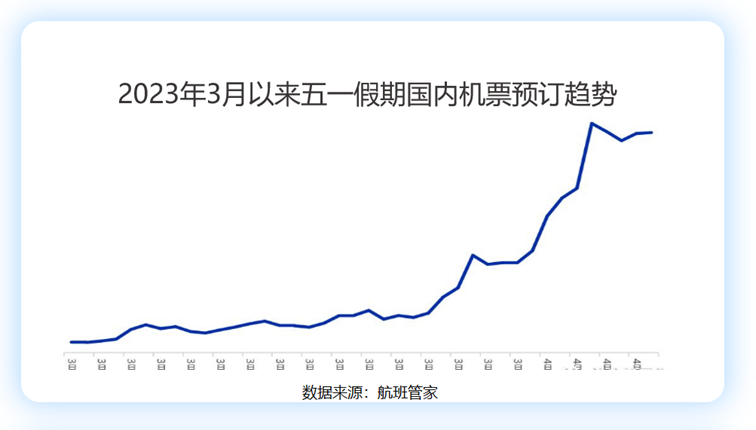
最初,携程使用 MyRocks( RocksDB for MySQL )作为历史库,只因其兼容 MySQL 主从架构,且自带压缩,对成本节约友好。如下图所示,今年上半年国内、国外机票预定量倍增,订单量相应增加,但随着业务数据量的激增, MyRocks 扩容难的问题暴露了出来。由于 MyRocks 无法适应如此快速的数据增长,携程需要再次考虑历史库选型,引入新的架构进行优化。

在历史库选型过程中,携程重点关注以下四个方面:
-
水平扩缩容。所选数据库是否能够水平扩缩容、扩缩容后是否方便进行负载均衡;
-
迁移便捷度。是否方便数据迁移;
-
降本。是否有足够低的存储成本;
-
增效。数据写入历史库的性能是否能达到要求。
基于上一次的历史库选型经验和产品调研,此次携程决定对完全自研且开源的分布式数据库 OceanBase 进行初步考察。除了高度兼容 MySQL 外,OceanBase 还具备透明水平扩展、高可靠、数据压缩能力强等特点。于是,携程根据业务场景对 OceanBase 数据库做了进一步的调研和测试。
如下图所示,携程对 MySQL 业务迁移至 OceanBase 的容量进行了测试对比,依据压缩算法的原理,表对比压缩率与数据类型、重复度等密切相关,所以携程采用了整库迁移对比,希望更接近实际场景。结果显示,MySQL 容量 2.1TB,迁移到 OceanBase 后为 264GB,数据压缩比 8:1。
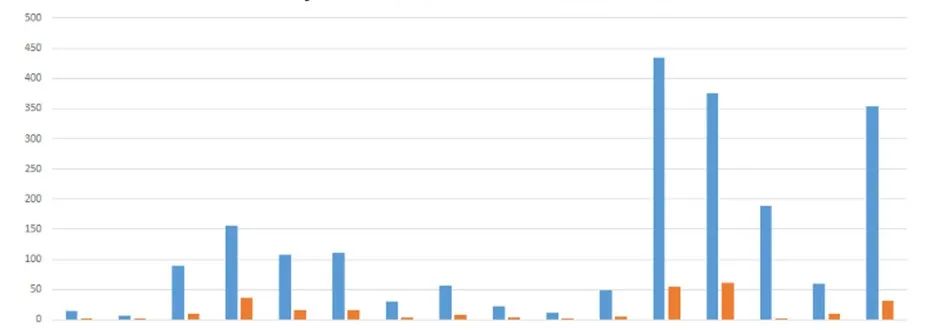
空间对比:MySQL(蓝) vs OceanBase(橙)
此外,在测试过程中,携程也考察了 OceanBase 在水平扩缩容、迁移便捷度,以及性能方面的表现,最终决定应用 OceanBase,上线后,效果符合预期。

一、水平扩缩容
携程最初使用 MySQL 作为归档历史库,当集群空间也达到上限时,采用了分库分表的解决方案。分库分表的方案在一定程度上带来了水平扩展的能力,降低了业务的系统性风险。
与此同时,分库分表方案使携程历史库面临诸多问题。
-
问题 1:在通过增加节点进行水平扩容时,需要 DBA 介入数据的迁移过程,利用人工完成数据的 rebalance。
-
问题 2 :额外的数据管理负担和数据运算压力,在某些场景下,需要遍历每个 ShardDB,并执行相同语句获取结果。此时请求量会翻倍,一旦出现慢 SQL,容易导致进程堆积。
-
问题 3:分库分表方案多种多样,如果开发人员设计不合理或使用不当,会出现数据分布不均的问题。
综合以上问题,我们在对历史库进行选型时,希望能够找到一款可以同时支持对业务无感的在线扩缩容、自动负载均衡及分布式事务的原生分布式数据库。
OceanBase 是原生分布式数据库,基于 Multi-Paxos 实现了分布式一致性协议,支持分布式事务;同时支持透明水平扩展,满足业务快速扩容缩容的需求,扩容后分区表的数据会自动均衡到新节点上,对上层业务透明,节省迁移成本。
在携程业务高速发展时,历史库的扩容操作对业务透明,这些特性完美地解决了携程历史库业务场景在最初使用分库分表策略时的各种痛点。
携程历史库在使用 MySQL 分库分表方案时,将数据按照月、日进行分表,需要开发人员在发布系统上主动配置,应用代码需要进行改造。一旦容量告警,需要 DBA 人工介入,进行数据拆分。而在 OceanBase 中只需要创建以时间作为分区键的 range 分区表,OceanBase 会自动将分区表的多个分区均匀地分散在每个 Zone 的各台节点上。每台节点均可以独立执行 SQL,如果应用需要访问的数据在不同机器上,节点自动将请求路由至数据所在的机器,对业务完全透明。
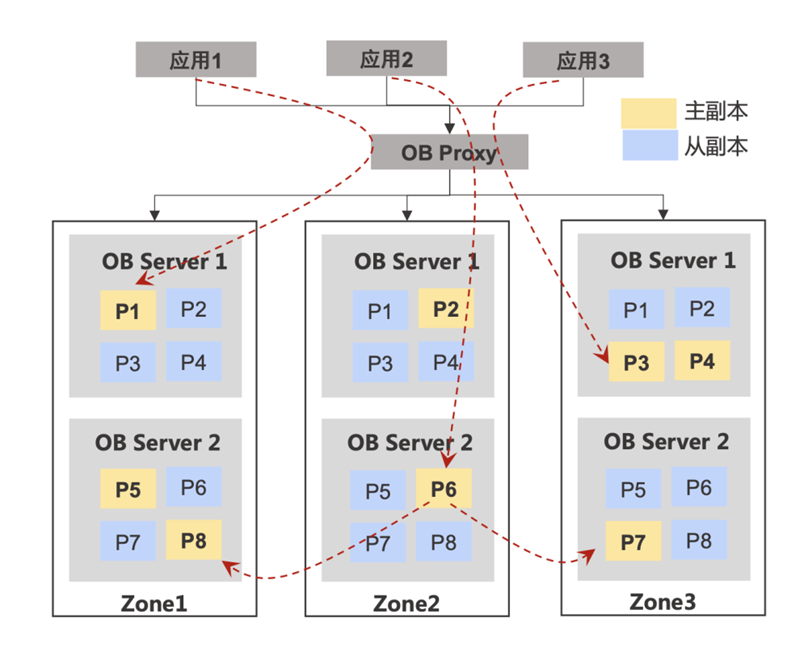
扩容时只需要在集群维度为其增加资源节点,通过修改租户资源规格的方式,可以将资源分配给指定租户,然后集群的 RootService 会调度分区副本在各 Zone 内部进行迁移,直到各节点的负载差值小于用户配置的阈值。各个分区主副本也会在每个节点上进行自动均衡,避免主副本的分配倾斜导致部分节点的请求负载过大。
二、数据迁移
在传统异构数据迁移方案中,通常有两种方式:一种是静态数据迁移,确保数据静态后,使用导出工具的方式进行迁移;另一种是需要开发人员在业务代码中进行双写。针对 MySQL 历史库的迁移,携程最终选择 OMS,进行数据迁移。
OMS(OceanBase Migration Service ,OceanBase 迁移服务)是一种支持同构或异构数据源与 OceanBase 之间进行数据交互的服务,具备在线迁移存量数据和实时同步增量数据的能力。OMS 支持了携程历史库的在线不停服迁移,整个迁移过程中,业务应用无感知。
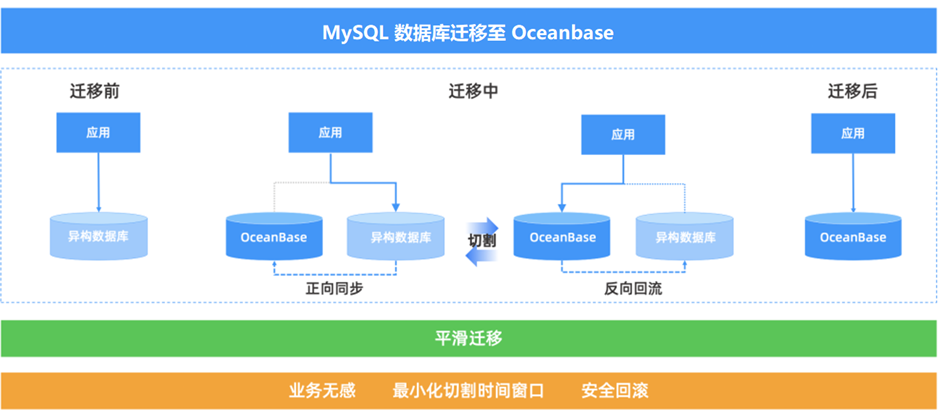
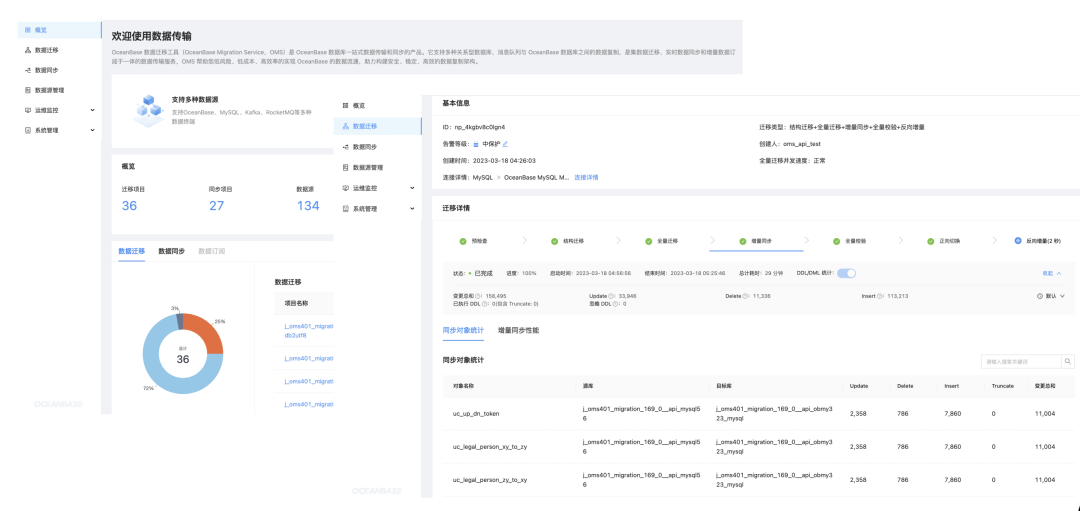
OMS 提供了可视化的集中管控平台,支持为数据迁移过程进行全生命周期的管理服务,在管控界面上即可完成对数据迁移和数据同步任务的创建、配置、监控和管理,交互简单方便。同时还提供了多种数据一致性校验方式,更加全面、省时、高效地保证数据质量。
携程通过 OMS(OceanBase Migration Service)提供的不停服数据迁移功能,将现有的 MySQL 历史库通过 OMS 平滑迁移至 OceanBase,在迁移过程中没有进行业务上的改造。迁移过程中原 MySQL 历史库持续对外提供服务,将数据迁移对业务的影响最小化。
三、存储成本
数据压缩是降低海量数据存储空间占用的关键手段。OceanBase 高压缩比的分布式存储引擎, 摒弃了传统数据库的定长数据块存储, 采用基于 LSM-Tree 的存储架构和自适应压缩技术,创造性地解决了传统数据库无法平衡“性能”和“压缩比”的难题。
OceanBase 支持 zlib、snappy、lz4 和 zstd 四种压缩算法。在通用压缩的基础上,OceanBase 自研了一套对数据库进行行列混存编码的压缩方法(encoding),使用行列的字典、差值、前缀等编码算法,在通用压缩算法之前对数据做了编码压缩,带来更大的压缩率,进一步降低存储成本。

存储层会根据数据特征自适应地选择最优的编码规则,合并时会计算数据的压缩比,如果发现压缩比不高,会尽快回退,选择其他的编码方式,从而确保数据编码的过程不会影响正常的数据写入性能。
OceanBase 在数据压缩方面的表现十分优秀,携程 MySQL 历史库中大小为 475G 的表,迁移到 OceanBase 后仅占 55G,平均存储资源仅为原来的 1/8,存储成本降低 85% 左右。
四、导入性能
携程历史库除了看重水平扩展性、存储成本等因素外,还对历史库的大量归档数据导入性能提出了较高要求。OceanBase 的并行执行框架能够将 DML 语句通过并发的方式进行执行( Parallel DML ),对于多节点的数据库,实现了多机并发写入,并且保证大事务的一致性。结合异步转储机制,还能在很大程度上优化 LSM-Tree 存储引擎在内存紧张的情况下对大事务的支持。
我们可以通过这样一个例子来体验 PDML:以 TPC-H 的 lineitem 表为基础,创建一张相同表结构的空表 lineitem2。然后以 INSERT INTO…SELECT 的方式,将 lineitem 的全部 600 万行数据插入新表 lineitem2 中。然后我们分别用关闭和开启 PDML 的方式执行,观察其效果和区别。
首先,复制 lineitem 的表结构,创建 lineitem2。
需要注意的是,在 OceanBase 数据库中我们使用分区表进行数据扩展,此处的例子中我们使用 16 个分区,那么对应的 lineitem2 也应完全相同:
obclient [test]> SHOW CREATE TABLE lineitem;CREATE TABLE `lineitem` (`l_orderkey` bigint(20) NOT NULL,`l_partkey` bigint(20) NOT NULL,`l_suppkey` bigint(20) NOT NULL,`l_linenumber` bigint(20) NOT NULL,`l_quantity` bigint(20) NOT NULL,`l_extendedprice` bigint(20) NOT NULL,`l_discount` bigint(20) NOT NULL,`l_tax` bigint(20) NOT NULL,`l_returnflag` char(1) DEFAULT NULL,`l_linestatus` char(1) DEFAULT NULL,`l_shipdate` date NOT NULL,`l_commitdate` date DEFAULT NULL,`l_receiptdate` date DEFAULT NULL,`l_shipinstruct` char(25) DEFAULT NULL,`l_shipmode` char(10) DEFAULT NULL,`l_comment` varchar(44) DEFAULT NULL,PRIMARY KEY (`l_orderkey`, `l_linenumber`),KEY `I_L_ORDERKEY` (`l_orderkey`) BLOCK_SIZE 16384 LOCAL,KEY `I_L_SHIPDATE` (`l_shipdate`) BLOCK_SIZE 16384 LOCAL) partition by key(l_orderkey)(partition p0,partition p1,partition p2,partition p3,partition p4,partition p5,partition p6,partition p7,partition p8,partition p9,partition p10,partition p11,partition p12,partition p13,partition p14,partition p15);
在不开启 PDML 的情况下,创建好 lineitem2 后,我们先以默认配置不开启并行的方式插入, 因为这是一个 600 万行的大事务,我们需要将 OceanBase 数据库默认的事务超时时间调整到更大的值(单位为 μs):
obclient [test]> INSERT INTO lineitem2 SELECT * FROM lineitem;Query OK, 6001215 rows affected (1 min 47.312 sec)Records: 6001215 Duplicates: 0 Warnings: 0
可以看到,不开启并行的情况下,单个事务插入 600 万行数据,OceanBase 的耗时为 107 秒。
下面我们通过添加一个 Hint,开启 PDML 的执行选项。
再次插入前,我们先将上次插入的数据清空。来看这次的执行耗时:
obclient [test]> TRUNCATE TABLE lineitem2;Query OK, 0 rows affected (0.108 sec)obclient [test]> INSERT /*+ parallel(16) enable_parallel_dml */ INTO lineitem2 SELECT * FROM lineitem;Query OK, 6001215 rows affected (22.117 sec)Records: 6001215 Duplicates: 0 Warnings: 0
可以看到开启 PDML 后,相同的表插入 600 万行数据,OceanBase 数据库的耗时缩短为 22 秒左右。PDML 特性带来的性能提升大约为 5 倍,数据写入性能远超 MySQL,并发 DML 这一特性支撑了携程批量归档数据快速导入历史库的需求。

总的来说,到目前为止,携程已经把众多核心业务迁移到 OceanBase 数据库。携程历史库场景经过 OceanBase 替换 MySQL 的实践后,取得了以下四点主要收益。
第一,无缝 scale-in or out:使用普通的 PC 服务器即可构建超高吞吐的 OceanBase 集群,无需分库分表,快速按需扩展,并为携程历史库在水平扩展过程中提供了平滑的成本增长曲线。
第二,数据迁移对业务透明:OMS 支持全量数据迁移、增量数据同步,支持主流数据库的一站式数据迁移,高效地完成了携程历史库数据到 OceanBase 的迁移。
第三,降低存储成本 85% 左右:基于 OceanBase 的高级压缩技术,在保证性能的同时,数据存储空间节约近 85%。同等硬件投入的前提下,OceanBase 支持携程历史库存储更多数据。
第四,数据写入性能优秀:OceanBase 的无共享架构、分区级主副本打散,以及并行执行框架提供的 Parallel DML 能力,真正实现了高效的多节点写入。利用该特性,数据写入性能提升了数倍,能够从容应对携程历史库的超高并发数据写入需求。
目前,携程使用的是 OceanBase 3.x 版本,未来将逐步升级至 4.x 版本,以获得更好的性能和写入效率。此外,OceanBase 4.x 高度兼容 MySQL 8.0,并支持租户级别的物理备份,这将有利于携程做数据的离线备份,以及能够更快地恢复备份。