Spring循环依赖和三级缓存详解
Spring在启动过程中,使用到了
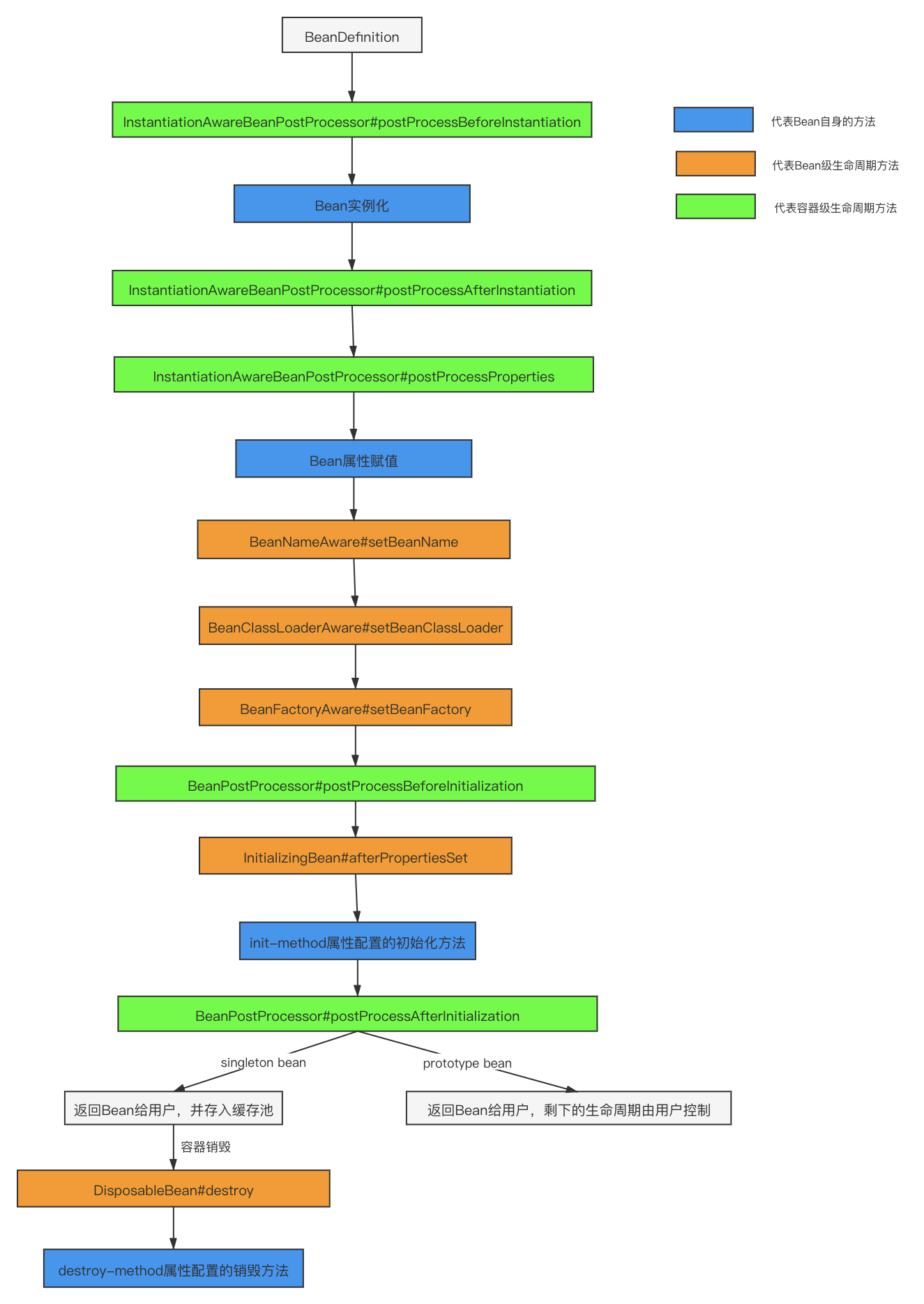
三个map,称为三级缓存

我们可以这样理解,假设,我们只有一个缓存容器,并且缓存是直接开放给用户可以调用的,如果将未完成赋值的Bean和已完成赋值的Bean全部放到同一个容器,那这个时候,调用者就有可能拿到未赋值的Bean,这样的Bean对于用户来说是不可用的,可能会导致空指针异常。
所以,Spring设计者,才有了这样一个设计,将能够直接提供给用户使用的Bean放到
一级缓存中,这样Bean称之为终态Bean,或者叫成熟Bean
。
将已经完成初始化,但还不能提供给用户使用的Bean单独放到一个缓存容器中,就是
二级缓存,这样的Bean称之为临时Bean,或者叫早期Bean
。
依照以上的分析,理论上二级缓存就能解决循环依赖问题,那为什么Spring还要设计一个三级缓存呢?
Spring三级缓存是为了解决对象间的循环依赖问题
。
单纯解决循环依赖可以只用二级缓存,但是如果涉及到代理对象的循环依赖,就需要用到三级缓存。其实一、二、三级缓存是根据获取对象的顺序来命名的,我们完全可以这样理解,
一级缓存就是终态缓存,二级缓存是临时缓存、三级缓存是代理工厂的缓存
。
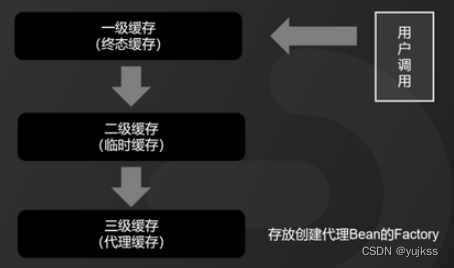
Spring中有很多注入的Bean是需要创建代理Bean的,但是,不是所有的Bean都需要再实例化之后立马就会创建代理Bean。是要等到Bean初始化全部完成之后才创建代理Bean。因此,循环依赖的出现,Spring又不得不去提前创建代理Bean。如果不创建代理Bean,注入原始Bean就会产生错误。因 此,Spring设计三级缓存,专门用来存放代理Bean。但是,创建代理Bean的又不同的规则,因此,
Spring三级缓存中,并不是直接保存代理Bean的引用,而是保存创建代理Bean的Factory
。
A依赖B,B依赖A,这就是一个简单的
循环依赖
。
循环依赖就是指循环引用,是两个或多个Bean相互之间的持有对方的引用。
循环依赖有三种形态
:
(1)相互依赖,也就是A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。 (2)三者间依赖,也就是A 依赖 B,B 依赖 C,C 又依赖
A,形成了循环依赖。
(3)自我依赖,也是A依赖A形成了循环依赖自己依赖自己。
我们来先看看三级缓存的源码。
(1)查看“获取Bean”的源码,注意getSingleton()方法。
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
//第1级缓存 用于存放 已经属性赋值、完成初始化的 单列BEAN
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
//第2级缓存 用于存在已经实例化,还未做代理属性赋值操作的 单例BEAN
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
//第3级缓存 存储创建单例BEAN的工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
//已经注册的单例池里的beanName
private final Set<String> registeredSingletons = new LinkedHashSet<>(256);
//正在创建中的beanName集合
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));
//缓存查找bean 如果第1级缓存没有,那么从第2级缓存获取。如果第2级缓存也没有,那么从第3级缓存创建,并放入第2级缓存。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); //第1级
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName); //第2级
if (singletonObject == null && allowEarlyReference) {
//第3级缓存 在doCreateBean中创建了bean的实例后,封装ObjectFactory放入缓存的bean实例
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//创建未赋值的bean
singletonObject = singletonFactory.getObject();
//放入到第2级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从第3级缓存删除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
}
1.不支持循环依赖情况下,只有一级缓存生效,二三级缓存用不到
2.二三级缓存就是为了解决循环依赖,且之所以是二三级缓存而不是二级缓存,主要是可以解决循环依赖对象需要提前被aop代理,以及如果没有循环依赖,早期的bean也不会真正暴露,不用提前执行代理过程,也不用重复执行代理过程。
https://fangshixiang.blog.csdn.net/article/details/92801300
https://blog.csdn.net/u012098021/article/details/107352463
https://blog.csdn.net/chinawangfei/article/details/122963121
https://blog.csdn.net/qq_36381855/article/details/79752689
https://zhuanlan.zhihu.com/p/496273636
https://blog.csdn.net/Trouvailless/article/details/124675721
https://blog.csdn.net/riemann_/article/details/118500805
https://blog.csdn.net/qq_35634181/article/details/104473308
springBean的生命周期
弄懂循环依赖必须清楚
springBean的生命周期
否则就是空谈
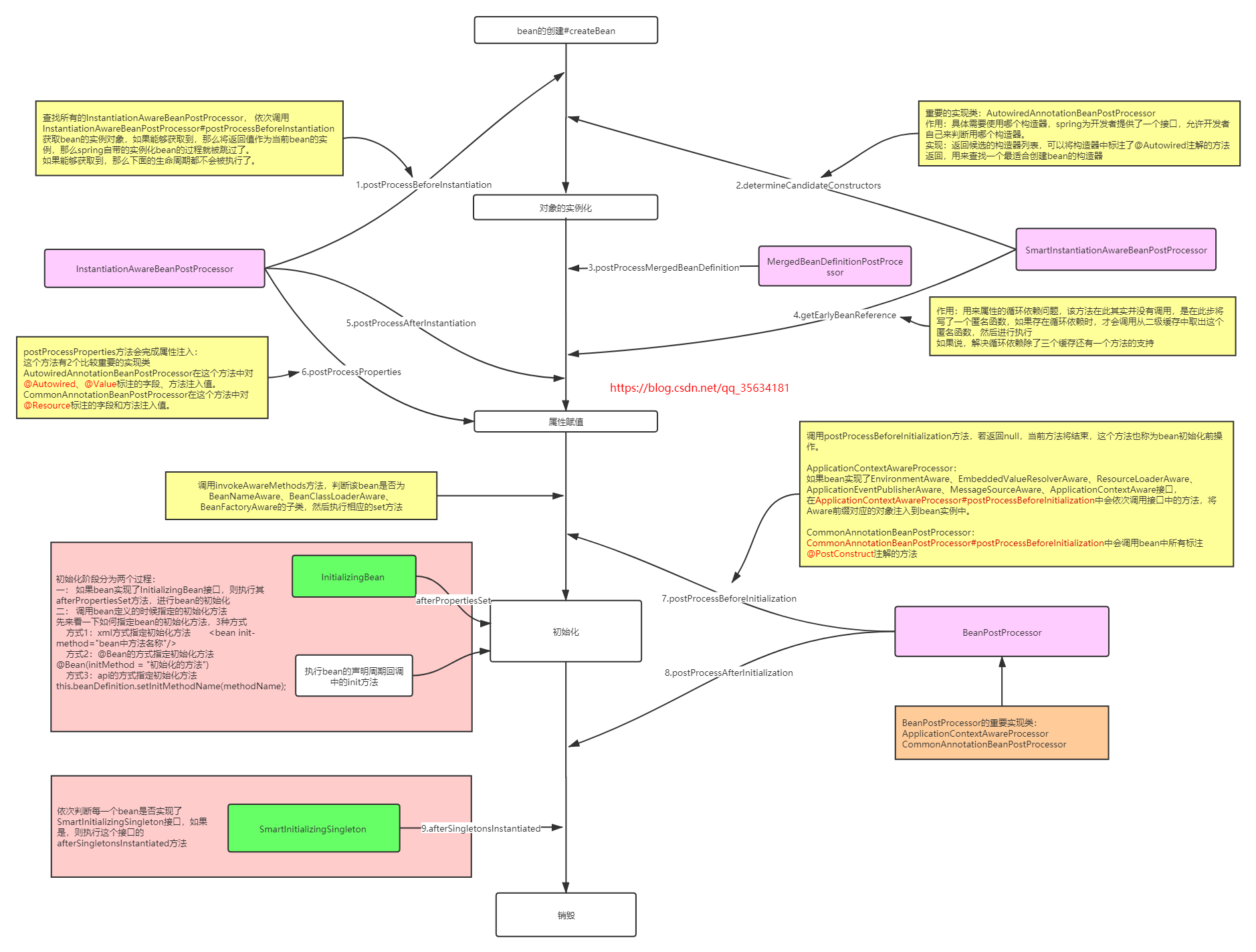
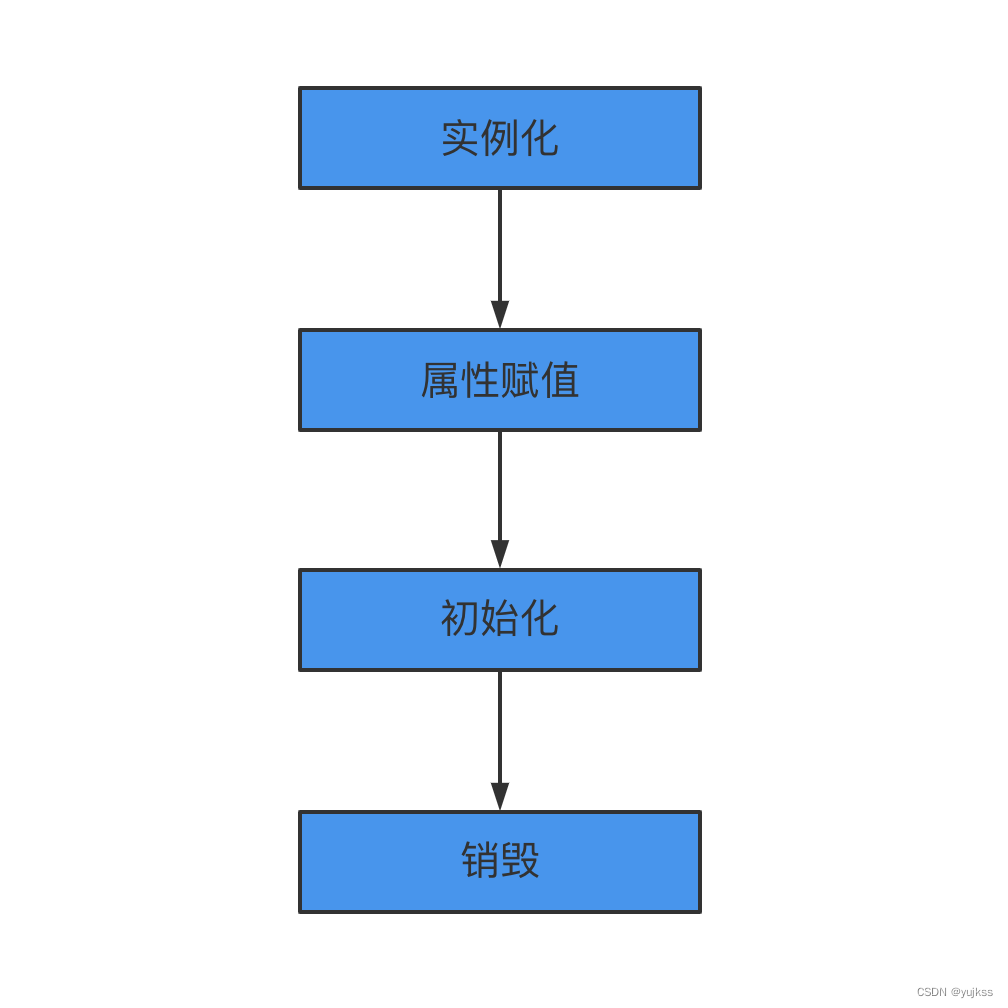
构造函数、getter/setter 以及 init-method 和 destory-method 所指定的方法等,也就对应着上文说
的实例化 -> 属性赋值 -> 初始化 -> 销毁
四个阶段。
主要是后处理器方法,比如下图的 InstantiationAwareBeanPostProcessor、BeanPostProcessor 接口方法。这些接口的实现类是独立于 Bean 的,并且会注册到 Spring 容器中。在 Spring 容器创建任何 Bean 的时候,这些后处理器都会发生作用。
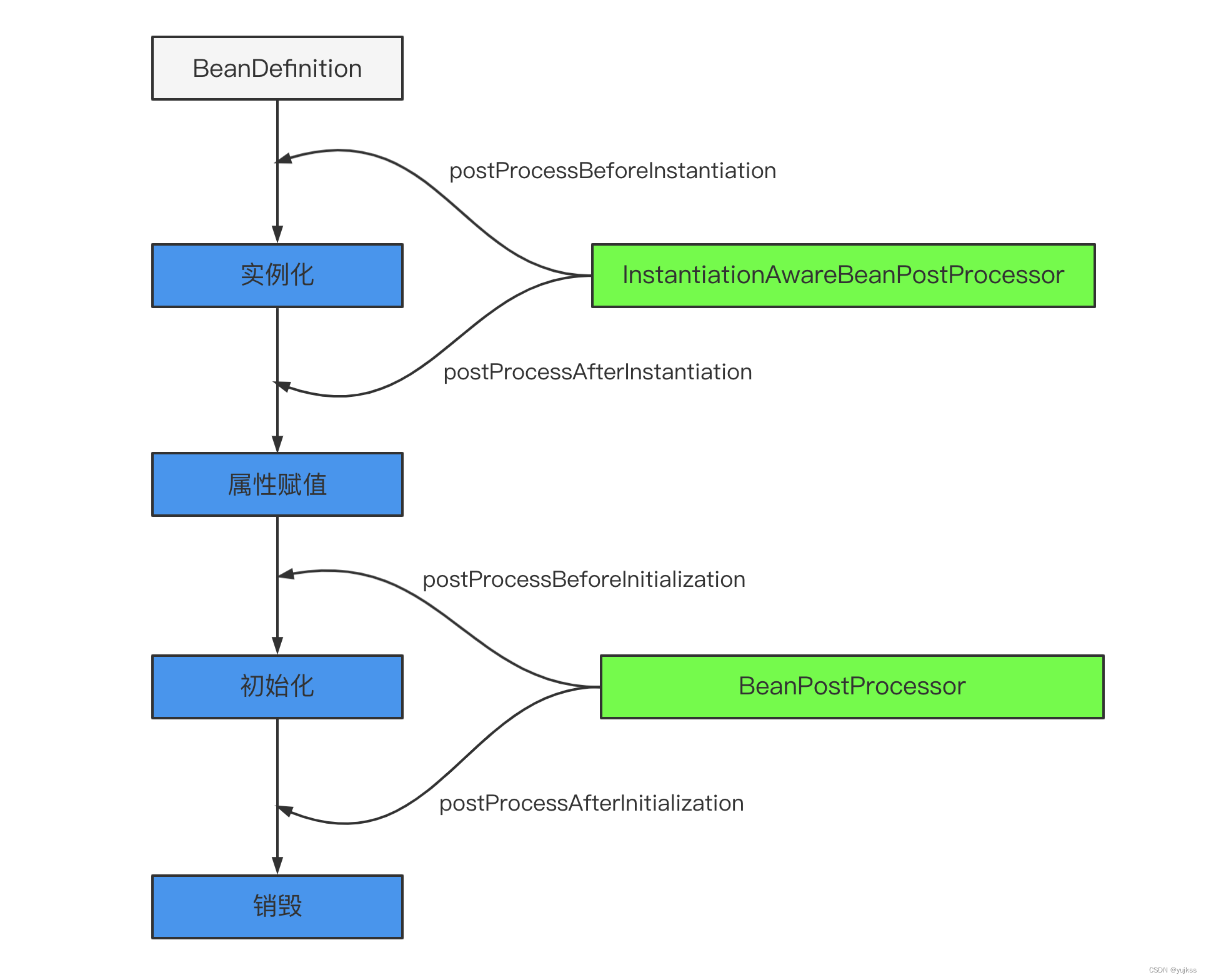
Spring Bean 生命周期流程图