一、索引类型
1.1、主键索引
InnoDB存储引擎使用B+树建立索引,主键索引的非叶子结点存放主键字段的值,通过主键中的字段构建B+树,叶子结点存放对应主键的整一条记录的信息(
因此主键索引也称为聚集索引
),
每张表只能建立一个主键索引(聚集索引)(可以是联合索引)
。
1.2、辅助索引
辅助索引(Secondary Index),也叫做二级索引,也是通过B+树建立,
与主键索引的唯一不同之处在于,叶子结点存放的是对应行的主键值
,而不是行数据
(因此也叫做非聚集索引,获取主键值之后,需要再次去主键索引表中查询该主键对应的记录,获取其叶子结点存储的记录内容,相当于要搜索两张索引表)
1.2.1、举个例子
这里给出一张表,id字段为主键索引,age字段为普通索引,然后插入一些数据,然后给出InnoDB为其维护的两个
逻辑上的
索引文件结构。
create table T(
`id` int primary key,
`name` varchar(11) not null,
`age` int not null,
index(age)
) # 5.5以后默认是InnoDB存储引擎
# 插入了四条数据:(1, 小明, 15)、(2, 小红, 20)、(3, 小兰, 16)、(4, 小金, 18)
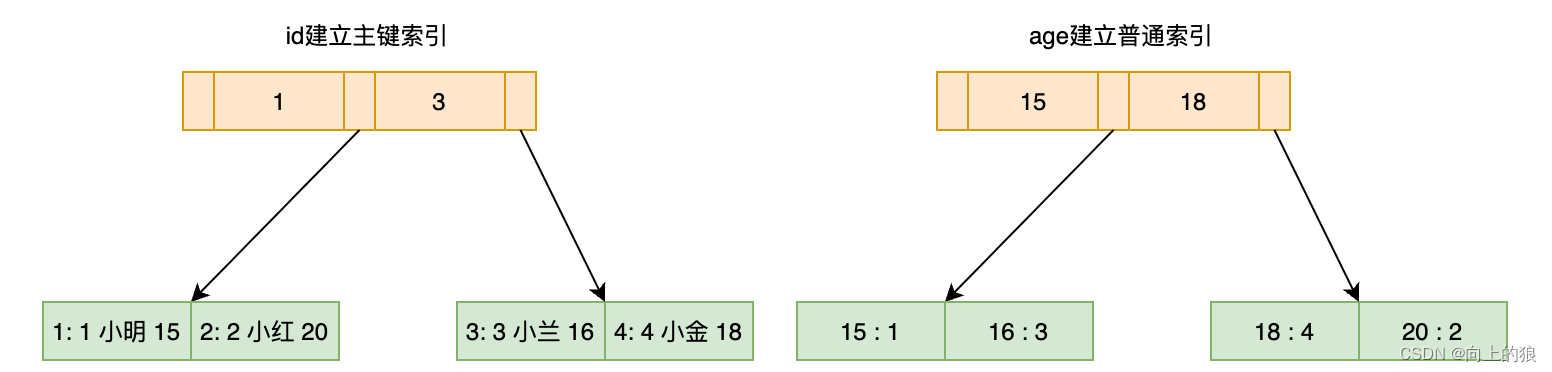
下面给出两个查询语句并分析索引执行情况
select * from T where id = 1 # 按照左侧主键索引搜索树,搜索到id为1的叶子结点,获取其中的记录数据
select * from T where age = 15 # 先按照右侧age建立的辅助索引树找到age=15对应记录主键id值等于1,然后再去左侧主键索引搜索树搜索id=1的这条记录
通过分析第二条SQL,我们得出结论,
对于走辅助索引的查询,必然会二次查询主键索引树(当然有特殊情况,下面讲)
,一张表只有一个主键索引,但是可以建立很多的辅助索引,且辅助索引的叶子结点里存放着主键值,
那么如果主键是字符串类型或者长度很长,那么必然会导致辅助索引占用的空间增加,所以自增主键往往是一个常用的选择。
1.3、覆盖索引
那么所有使用辅助索引的SQL查询语句都必须两次回表吗?当然有特殊情况,如果辅助索引树的叶子结点中的字段,
已经覆盖了需要查询的所有字段
,则不需要回表(回表的目的是获取辅助索引树中没有的字段数据),
覆盖索引我更愿意称之为索引覆盖,它还是归属于辅助索引。
select id from T where age = 15 # 对于这个查询,将查询的字段只要求id,则在搜索完右侧age的辅助索引树之后,即可获得到id=1,无需回表
1.4、联合索引
联合索引依旧是辅助索引的一种情况
(不是主键索引就都归属于辅助索引)
,
辅助索引可以在多个字段之间建立,如果第一个字段相同则比较第二个字段,依次类推建立索引搜索树结点之间的先后关系,也就是说索引项按照索引定义的字段顺序排序
(后面要讲到的最左前缀原则就是在此基础上来分析的)
,下面举个例子,还是借助上面这张表,但是辅助索引不是单单age字段建立,而是name和age共同建立。
create table T(
`id` int primary key,
`name` varchar(11) not null,
`age` int not null,
key `name_age` (`name`, `age`)
) # 5.5以后默认是InnoDB存储引擎
# 插入了四条数据:(1, 小红, 16)、(2, 小红, 15)、(3, 小兰, 16)、(4, 小金, 16)
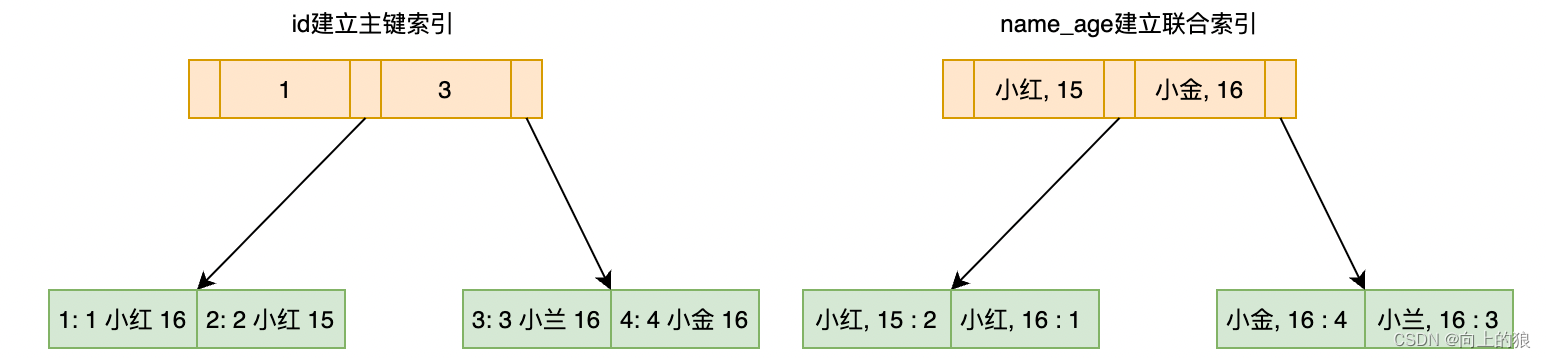
下面给出一条针对这个name_age的联合索引的查询语句
select id from T where name = ‘小红’ and age = 15 # 通过上面学习索引覆盖的知识点,你应该能分析出这条sql只会搜索右边的联合索引树,获得到id之后不需要再去回表搜索主键索引树
二、最左前缀原则
2.1、概念
还是以上面的这个联合索引为例,如果我的sql语句如下:
select id from T where name = ‘小红’ # name_age索引树在满足name有序的前提下,满足age有序,因此对单一name字段的查询也可以走这个索引,找到满足条件的第一条记录的id,然后按顺序向后遍历找到其他满足要求的记录id
select id from T where age = 15 # age字段是name_age索引的第二个字段,在name无序的前提下,age的有序是无意义的,索引无法利用这个联合索引,需要
全表扫描
获取满足age=15的记录select id from T where name like ‘小%’ # 首先name字段是name_age辅助索引的左侧第一个字段,且通配符%在右侧,因此也可以满足最左前缀原则,在查询时走这个辅助索引,定位到第一个满足name=’小%’的记录的id,然后向后遍历找到其他满足条件的记录
# ps.这三个语句都是不用回表的
最左前缀原则:只要你的查询语句涉及的字段满足已有辅助索引的左侧出现顺序(或者匹配字符串的左侧n个字符),而不出现越过某个字段的情况,查询就可以走这个辅助索引,这就是最左前缀原则,查询将返回第一个满足查询条件的记录对应的主键id,根据情况看是否需要回表搜索主键索引树。
提醒:为了方便,我上面作的B+树索引树叶子结点之间的双端链表结构没有标出,这里提醒一下,因为讲最左前缀原则的例子中出现了找到第一个满足条件的记录id之后,按顺序向后遍历的情况,这是得益于B+树叶子结点相互串连的结构
2.2、联合索引字段顺序
通过上面的分析,对于一个辅助索引
(a, b)
来说,不需要为
a
单独再建立索引,但可以再给
b
单独建立辅助索引(因为
b
为查询条件不满足辅助索引的最左前缀原则),那么思考一下,如果调整联合索引的顺序为
(b, a)
,那么就不用单独为
b
建立辅助索引,而需要为
a
建立辅助索引。此时
(a, b)
、
b
方案与
(b, a)
、
a
方案都能满足对
(a,b)
、
a
、
b
三个字段的查询调用辅助索引,差别在于哪?
空间!这里比较好的方案是看a与b哪个字段长,则将其放在联合索引的前部,而需要额外建立辅助索引的用较短的字段,这样综合可以减少空间的使用(如果a字段长,则必有2a+b > 2b+a的空间使用)
2.3、索引失效
辅助索引会在最左前缀原则的基础上,一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
。范围列可以用到索引,
但是范围列后面的列无法用到索引
。举个例子:
create table T(
`id` int primary key,
`name` varchar(11) not null,
`age` int not null,
`sex` varchar(11) not null,
key `name_age` (`name`, `age`)
) # 5.5以后默认是InnoDB存储引擎
# 插入了四条数据:(1, 小红, 16, 女)、(2, 小红, 15, 女)、(3, 小兰, 16, 女)、(4, 小金, 17, 男)
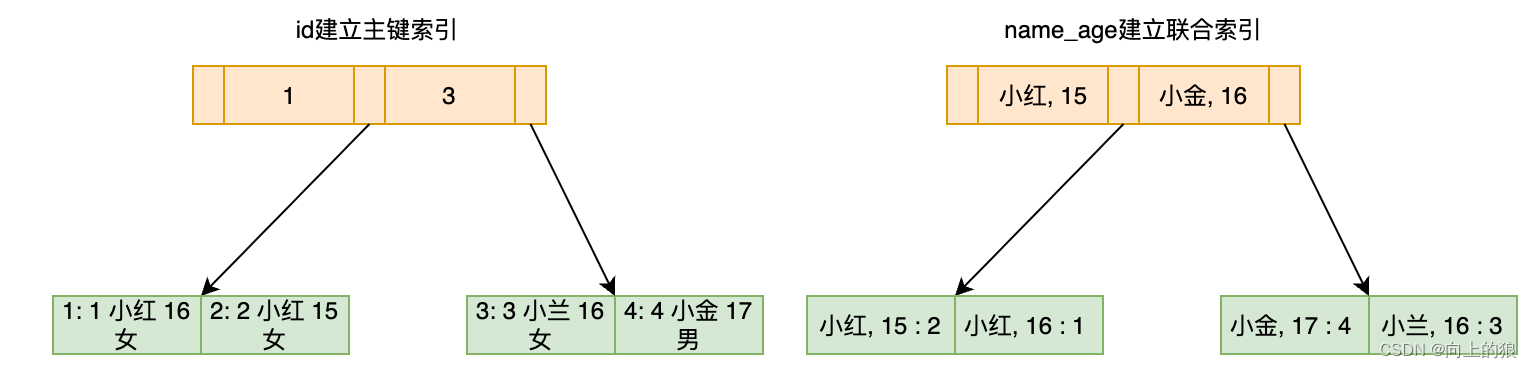
分析下面这条sql的索引调用情况:首先是匹配
name like '小%'
,可以走右侧辅助索引树,找到
id=2
的记录,然后
顺序向后扫描
满足
age=16
的记录,
并不能继续利用联合索引中age这个部分
,最终得到
id=1
和
id=3
的两条记录,
最后需要回表搜索主键索引树,因为这个联合索引并没有完全做到索引覆盖,缺少了sex字段。
解释:因为满足name like ‘小%’的记录可能有多条,而age字段的有序是建立的name有序的基础之上,上图中(小红, 15) (小红, 16) (小金, 17) (小兰, 16),
单独看age字段之间是无序的,因此在满足条件的name字段是多个的时候,age字段的索引就丧失功能了,只有当name字段匹配的结果唯一,age字段的有序才有意义。
select * from T where name like ‘小%’ and age = 16
2.4、索引下推(MySQL5.6)
对于上面这个查询语句,因为sex字段是没有被联合索引覆盖,因此需要二次回表查询主键索引树,但是显然age字段的值是联合索引的一部分,且查询的是age等于16,而有些记录必然不符合匹配,那还有必要回表吗?
索引下推:
在
MySQL5.5
以及之前的版本中,在满足范围匹配
name like '小%'
之后,并不会继续判断后面个
age字段
,直接就回表了,而从
MySQL5.6
开始,InnoDB存储引擎在匹配到满足
name like '小%'
之后,无法继续使用最左前缀原则的字段(如本例的age)依旧在联合索引中,则会根据这些字段多做一些过滤,不满足条件的记录将不会回表查询,减少了二次搜索的次数。
三、索引重建
这里补充一点额外的知识,之前听闻过一个索引使用的中出现的问题案例:
有一个线上的记录日志的表,定期会删除早期的数据,经过一段时间的维护,这个表中存放的记录空间稳定在10G,但是索引占用空间有30G,一共40G空间。
原因:InnoDB存储引擎表就是索引组织表,记录数据存放在主键索引叶子结点上,这张表会被不断插入日志记录,且定期删除日志记录,会导致维护索引的B+树频繁发生页的分裂,导致页空间中出现浪费的空间,提高了索引的占用空间。
解决:可以通过重建索引的方式,删除之前的旧索引,并重新创建这个索引,因为数据已经在表中,因此重建索引的过程会将表中的数据按顺序插入,使得页面结构重新恢复紧凑(当然具体重建索引的方案需要结合更多的因素去分析,并不是定期重建索引就一定是好的,这里不多深究)