一. 基础概念
简单来说,Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
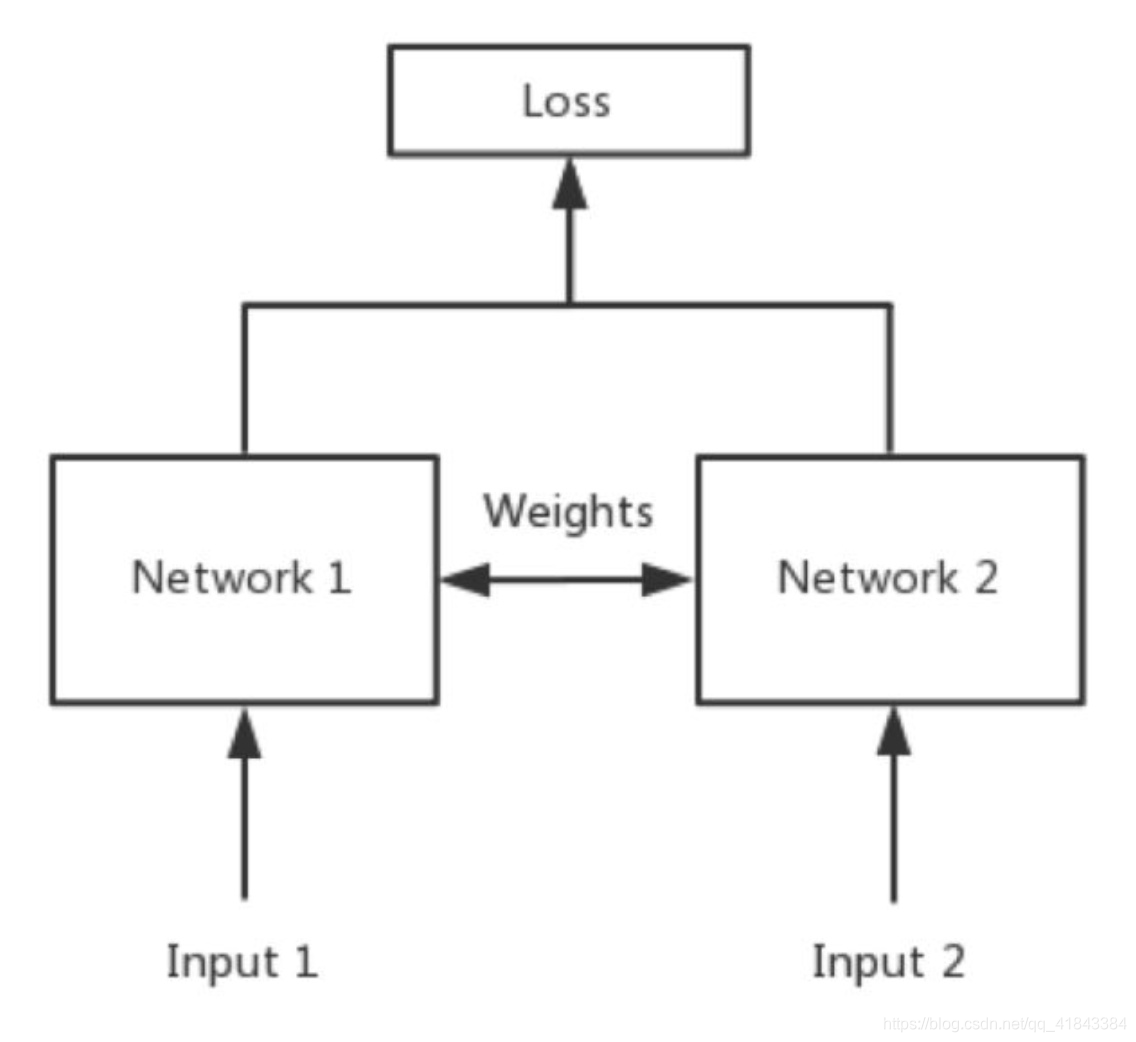
其中,network1 和network2 是两个共享权值的网络,实际上就是两个完全相同的网络。孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
如果左右两边不共享权值,而是两个不同的神经网络,叫做pseudo-siamese network,伪孪生神经网络。对于pseudo-siamese network,两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
孪生神经网络用于处理两个输入”比较类似”的情况。伪孪生神经网络适用于处理两个输入”有一定差别”的情况。比如,我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合;如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用pseudo-siamese network。也就是说,要根据具体的应用,判断应该使用哪一种结构,哪一种Loss。
其中,loss function 的选择很重要。Softmax当然是一种好的选择,但不一定是最优选择,即使是在分类问题中。传统的siamese network使用Contrastive Loss。损失函数还有更多的选择,siamese network的初衷是计算两个输入的相似度,。左右两个神经网络分别将输入转换成一个”向量”,在新的空间中,通过判断cosine距离就能得到相似度了。Cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,
训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大
二. tensorflow实现孪生神经网络
参考论文:
Learning a Similarity Metric Discriminatively, with Application to Face Verification
siamese网络和其他网络的不同之处在于,首先他是两个输入,它输入的不是标签,而是是否是同一类别,如果是同一类别就是0,否则就是1,文章中是用这个网络来做人脸识别,网络结构图如下:
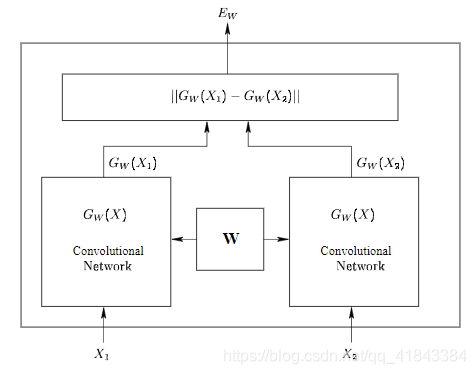
从图中可以看到,他又两个输入,分别是x1和x2,左右两个的网络结构是一样的,并且他们共享权重,最后得到两个输出,分别是Gw(x1)和Gw(x2),这个网络的很好理解,当输入是同一张图片的时候,我们希望他们之间的欧式距离很小,当不是一张图片时,我们的欧式距离很大。有了网络结构,接下来就是定义损失函数,这个很重要,而经过我们的分析,我们可以知道,损失函数的特点应该是这样的:
(1) 当我们输入同一张图片时,他们之间的欧式距离越小,损失是越小的,距离越大,损失越大
(2) 当我们的输入是不同的图片的时候,他们之间的距离越大,损失越小
怎么理解呢,很简单,我们就是最小化把相同类的数据之间距离,最大化不同类之间的距离
文章中定义的损失函数如下:
首先是定义距离,使用l2范数,公式如下:
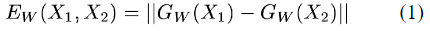
距离其实就是欧式距离,有了距离,我们的损失函数和距离的关系我上面说了,如何保证满足上面的要求呢,文章提出这样的损失函数:
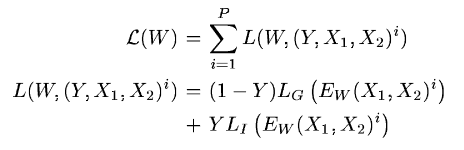
其中我们的Ew就是距离,Lg和L1相当于是一个系数,这个损失函数和交叉熵其实挺像,为了让损失函数满足上面的关系(注意,同类Y取0,不同类Y取1),让Lg满足单调递增,Li满足单调递减就可以。另外一个条件是:同类图片之间的距离必须比不同类之间的距离小。
文章经过一系列推导,给出损失函数为:
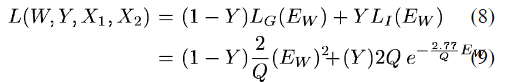
其中,Ew为距离,Q为大于0的常数。
在tensorflow中实现loss为:
def siamese_loss(out1,out2,y,Q=5):
Q = tf.constant(Q, name="Q",dtype=tf.float32)
E_w = tf.sqrt(tf.reduce_sum(tf.square(out1-out2),1))
pos = tf.multiply(tf.multiply(1-y,2/Q),tf.square(E_w))
neg = tf.multiply(tf.multiply(y,2*Q),tf.exp(-2.77/Q*E_w))
loss = pos + neg
loss = tf.reduce_mean(loss)
return loss
```y