Date: 2019-08-04
一、 iHandy2019校招-机器学习/算法工程师笔试题
1. 计算斐波那契数列第n项的函数定义如下:
int fib(int n){
if(n==0)
return 1;
else if(n==1)
return 2;
else
return fib(n-1)+fib(n-2);
}若执行函数调用表达式fib(9),函数fib被调用的次数是: 109
解释: (往前调用时,调用值n为0或者1的时候就不需要再往前进行调用了。)
对于小数据量的n来说
f(1) 调用1次
f(2) 调用3次
f(3) 调用5次
f(4) 调用9次
发现一个规律:从n=3开开始,调用次数为前两次和加1
即:f(3) =f(2) +f(1) +1=5
f(4) =f(3) +f(4) +1=9
f(5) =f(4) +f(3) +1=15
f(6) =f(5) +f(4) +1=25
f(7) =f(6) +f(5) +1=41
f(8) =f(7) +f(6) +1=67
f(9) =f(8) +f(7) +1=109
2. 程序段的执行结果是: 14,14
#include <iostream>
using namespace std;
void fun1(int &x) {
x++;
}
void fun2(int x) {
x++;
}
int main() {
int abc = 13;
fun1(abc);
printf("%d\n", abc);
fun2(abc);
printf("%d\n", abc);
}解释: fun1引用传递,fun2值传递 ;具体而言就是:fun1传入的是X的地址,进行++操作会直接改变x的值,进行fun1操作后x变为14,fun2中的x是形参,不会改变实参x的值。但是本题后面print的结果是abc的值,经过x++之后值会发生改变。但注意与++x的区别:x++是先x然后在进行++的操作;但是++x时先进行累加++的操作,然后再是x的运算。
3. 三次握手方法用于 传输层连接的建立。 (TCP传输层连接)
4.
假设磁头当前位于第99道,正在向磁道序号增加的方向移动。现有一个磁道访问请求序列为33,59,13,77,123,170,160,185,采用SCAN调度(电梯调度)算法得到的磁道访问序列是( 123,160,170,185,77,59,33,13 )。
解释SCAN调度算法(电梯调度的思想):从移动臂当前位置开始沿着臂的移动方向去选择离当前移动臂最近的那个柱面的访问者,如果沿臂的移动方向无请求访问时,就改变臂的移动方向再选择。但在本题中,磁头正在向磁道序号增加的方向移动。
首先,磁头选择与当前磁头所在磁道距离最近的请求作为首次服务的对象(123),当磁头沿途相应访问请求序列直到达到一端末(123,160,170,185),再反向移动响应另一端的访问请求(77,59,33,13)。
5. 已知二叉树的前序序列是ABCDEFGH,中序序列是CBEDFAGH,其后序序列是? 可以根据前序和中序将二叉树画出来,是如下的二叉树:
A
/ \
B G
/ \ \
C D H
/ \
E F
分析方法:先确定根节点,分为左右树,同理再迭代
则后序遍历结果是: CEFDBHGA
6. 下面哪个选项中哪一项属于确定性算法 (A)PCA?
A. PCA
B.K-Means
解释:
首先参考维基百科给出的确定性算法的定义:In
computer science
, a
deterministic algorithm
is an
algorithm
which, given a particular input, will always produce the same output, with the underlying machine always passing through the same sequence of states。简单来说,确定性算法就是对于一样的输入,我们总是可以得到一样的输出。
K-means: 不确定算法。按照定义,从结果上看,就是同样的数据集多次运行K-means算法会得到不同的结果(聚类),所以其不是确定算法。从其算法原理看,其不确定性在于我们必须随机选择初始的聚类中心,之后再进行迭代,所以会产生不同的结果。
PCA:确定算法。原因在与,PCA的本质在于求解一个方差最大化问题,给定数据集,最优问题的解是确定且唯一的。
7. 关于ensemble learning,下面说法正确的是 A
A.单个模型之间有低相关性(周志华的西瓜树上面有解释,单个模型的独立性越强,预测精度越高,有证明)
B.在集成学习中使用“平均权重”会好于使用“投票” (根据具体情况而定)
C.单个模型都是使用同一算法(No)
8. 决策树的父节点和子节点的熵的大小关系是什么 父节点的熵更大。
补充: 决策树分解策略是保证子结点的熵小于父结点的熵。但“子结点的熵”是该父结点所有孩子结点的熵的总和,因此,并保证任意一个子节点的熵都小于父结点熵。
9. (****)
测得某个采用按需调页策略的计算机系统部分状态数据为:CPU利用率5%,用于交换空间的磁盘利用率95%,其他I/O设备利用率5%。试问,这种情况下(AC)能提高CPU的利用率。
A.增大内存的容量
B.增大磁盘交换区的容量
C.减少多道程序的度数
D.使用更快速的磁盘交换区
解释1:由题目可以得出,大部分的运行时间都耗费在交换操作上,也就是说物理内存太小导致数据经常需要换入换出,因此需要提高内存大小,此外CPU和IO的的占用率都很低表示CPU一次读取的太多的程序放入内存中,因此需要降低多道程序的度数(个数)。
解释2:
CPU利用率5%,用于交换空间的磁盘利用率95%,其他I/O设备利用率5%。
CPU利用率
:
运行的程序占用的CPU资源,表示机器在某个时间点的运行程序的情况。
使用率
越高,说明机器
在这个时间上运行了很多程序
,反之较少。
CPU是负责运算和处理的,内存是交换数据的。
1.
可以看出CPU利用率低;
3
.I/O设备利用率低(
减少多道程序的度数
)
CPU一次读取的太多的程序放入内存中,因此需要降低多道程序的度数
2.交换空间的磁盘利用率高(增大内存的容量)
交换空间利用率高,因此需要扩大数据交换空间(增大内存的容量)
10. 对以下各搜索树进行删除操作,哪些树在最坏情况下时间复杂度不超过O(log(n))?其中n为关键码的数量。 AC
A.AVL树 (ok)
B.伸展树
C.红黑树 (ok)
D.二叉查找树
解释:
A.
AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为一,所以它也被称为高度平衡树。查找、插入和删除在
平均和最坏情况下都是O(log n)
。
B
.伸展树(Splay Tree),也叫分裂树,是一种二叉排序树,它能在O(log n)内完成插入、查找和删除操作。伸展树支持所有的二叉树操作。
伸展树不保证最坏情况下的时间复杂度为O(logN)。伸展树的时间复杂度边界是均摊的
。
C
.红黑树(Red Black Tree) 是一种自平衡二叉查找树,它虽然是复杂的,
但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除
,这里的 是树中元素的数目。
D
.在二叉查找树中查询元素的最优时间复杂度是O(logN)即在满二叉树的情况下,
最坏时间复杂度是O(n)
即除叶子节点外每个节点只有一个子节点,
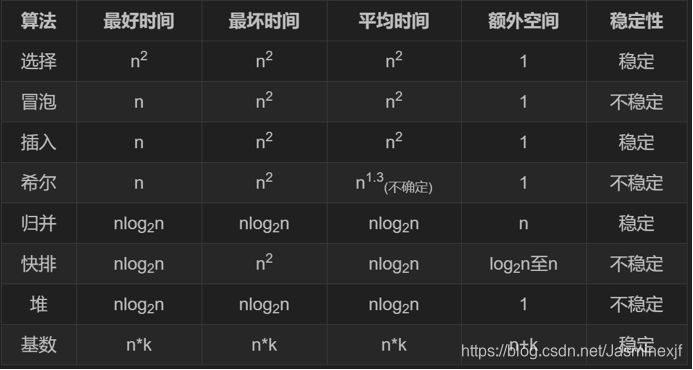
11. 所有排序算法中,最坏时间复杂度是 O(n log(n)) 的是? 归并排序算法+堆排序算法
12. 面哪些选项对 K 折交叉验证的描述是正确的 ABC
A. 增大 K 将导致交叉验证结果时需要更多的时间
B.更大的 K 值相比于小 K 值将对交叉验证结构有更高的信心
C.如果 K=N,那么其称为留一交叉验证,其中 N 为验证集中的样本数量(留一法就是每次只留下一个样本做测试集,其它样本做训练集,如果有n个样本,则需要训练n次,测试n次。 )
13. 以下哪些模型方法属于生成式模型 AD
A. Hidden Markov Model
B.SVM
C.Logistic Regression
D.Latent Dirichlet Allocation
补充:
生成式模型
- 判别式分析
- 朴素贝叶斯
- K近邻(KNN)
- 混合高斯模型
- 隐马尔科夫模型(HMM)
- 贝叶斯网络
- Sigmoid Belief Networks
- 马尔科夫随机场(Markov Random Fields)
- 深度信念网络(DBN)
- LDA(Latent Dirichlet Allocation)
判别式模型
- 线性回归(Linear Regression)
- 逻辑斯蒂回归(Logistic Regression)
- 神经网络(NN)
- 支持向量机(SVM)
- 高斯过程(Gaussian Process)
- 条件随机场(CRF)
- CART(Classification and Regression Tree)
- LDA(Linear Discriminant Analysis)
14. 在神经网络训练过程中,为什么会出现梯度消失的问题?如何防止?
神经网络在训练的时候随着网络层数的加深,激活函数的输入值的整体分布逐渐往激活函数的取值区间上下限靠近,从而导致在反向传播时低层的神经网络的梯度消失。
防止:
1)使用relu、LRelu、ELU、maxout等激活函数。
sigmoid函数的梯度会随着x的增大或减小和消失,而relu不会。
2)使用批规范化 (BN:BatchNormlization)
通过规范化操作将输出信号x规范化到均值为0,方差为1,保证网络的稳定性。从上述分析可以看到,反向传播中有w的存在,所以w的大小影响了梯度的消失和爆炸,BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大和缩小的影响,进而解决梯度消失和爆炸的问题
3) 预训练加微调
4) 梯度剪切
5) 权重正则化
6) 使用残差网络
7) 使用LSTM网络
15. 假设有一支手枪,每次扣动扳机,会有50%的概率发射子弹,50%的概率不会发射子弹。现在甲和乙轮流使用这支手枪朝对方射击,直到其中一方中弹。如果甲先开枪,最终乙先中弹的概率是多大?请给出计算过程和结果。

16. 给定一列非负整数,求这些数连接起来能组成的最大的数。(在线编程题)
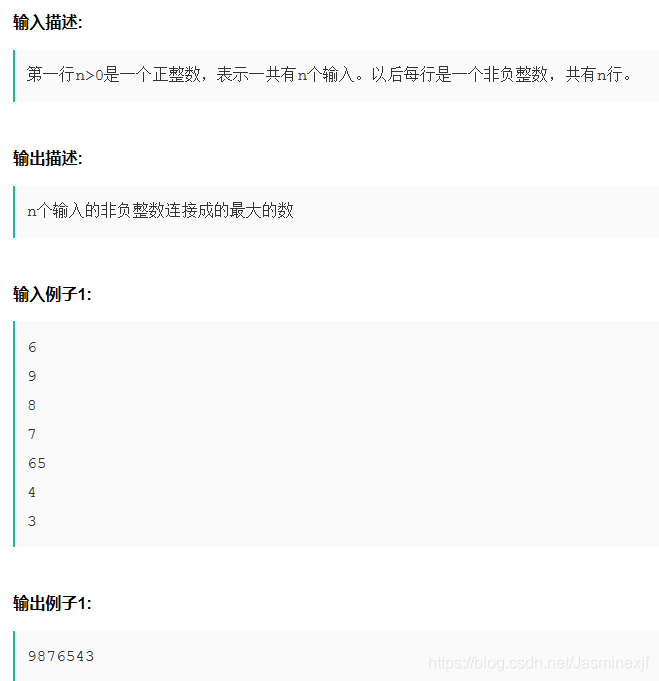

# my (60% error)
n = int(input())
A = []
for i in range(n):
A.append(int(input()))
A1 = []
for i in range(len(A)):
A1.append(int(str(A[i])[0]))
res = ''
while A1:
idx = A1.index(max(A1))
res += str(A[idx])
del A1[idx]
print(res)
# other:
num = int(input())
num_list = []
for i in range(num):
tmp_num = input()
for j in range(len(tmp_num)):
num_list.append(int(tmp_num[j]))
num_list.sort(reverse = True)
result = 0
for i in range(len(num_list)):
result = result * 10 + num_list[i]
print(result)二、旷视科技2019实习生春招算法研究员笔试(线上) 前46%
1. 在一长度为 N 的有序数列中寻找两个数,使得两数之和等于某指定值的最快的算法的平均时间复杂度是 ()O(N)
def func(A, target):
for i in range(len(A)):
x = target - A[i]
if A.index(x) and A.index(x) != i:
return (A[i], x)2. 平衡二叉树的插入节点操作平均时间复杂度是() O(logn)
平衡二叉树有: AVL树, 伸展树, (2,4)树, 红黑树 ,一般的时间复杂度或者均摊分销后的时间复杂度是O(logn).
3. 使用 KMP 算法在一长度为N 的字符串中寻找长度为 M 的子字符串的时间复杂度为() O(N + M)
解释;KMP为线性算法,处理文本串和匹配串的复杂度都为
O(N)
4. 设有一个栈,元素依次进栈的顺序是 A,B,C,D,E。下列不可能的出栈顺序有?()C
A. B,C,D,E,A
B.A,B,C,D,E
C.E,A,B,C,D
D.E,D,C,B,A
栈:先进后出;队列是先进先出
5. 数字 237468992357836701 转为 16 进制后其后两位为() 9d
根据十进制转为十六进制规则进行计算,但只需要判断最后两位,这样计算太耗时了。
1):
100%4 = 0
1000%8 = 0 16*375=6000
10000%16 = 0 16*625=10000
845678992357836701%16 = 6701%16 = 701%16 = 13
2)
|
|
输出
|
1 |
|
6. 快速排序的最坏情况时间复杂度是: o(n^2)
7. 0 到 9999 这 1 万个数中有多少个数字5? 4000
解析: 每一个位置上都有可能为5,举例说明,假如第一个位置上的元素是5的情况有10*10*10(后面三位数上的情况),然后第二位、第三位、第四位的情况。
加和为4*1000=4000种情况。
8. 有两整形数 a, b, 如何不使用第三个变量交换 a 和 b 的值?
在python中,可以利用自动解包和自动分配技术,具体而是: a,b = b,a
9. 由 0 – 9 组成的 1-N 位数字组合共有多少种? (0, 00 算两种有效组合) 10^1 + … + 10^N
一位数字: 10
2位数字:10^2
3位数字:10^3
……
N位数字: 10^N
进行求和:
10. AB 两人比赛投篮,假设两人命中率均为 50%。当 A 投了 51 次篮,B 投了 50 次篮时,A 的进球数比 B 多的概率是 1/2
解释: 该题相当于B没投篮,A投篮中了的概率就是1/2.
11. 给出两个分别有序的单链表,将其合并成一条新的有序单链表。?
思路:
假设现有两个有序单链表A,B,根据这两个单链表来生成合并后的有序链表。
1) 首先获取head,如果A,B两者的元素个数都大于1,则先比较两者的头部元素,获取小的哪一个元素作为头部;如果两个链表有一个为空链表,则此时可直接返回非空链表作为合并后的结果。
2) 在两个链表都非空的情况下,已经得到了合并后的链表的头部,然后逐一往后迭代比较,获取较小的元素作为合并的链表的后续元素。
def Merge(pHead1,pHead2):
p1,p2 = pHead1,pHead2
if p1 and p2:
if p1.value < p2.value:
head= p1
p1 = p1.next
else:
head= p2
p2 = p2.next
elif p1:
return p1
else:
return p2
while p1 and p2:
if p1.value < p2.value:
cur.next = p1
else:
cur.next = p2
if p1:
cur.next = p1
else:
cur.next = p212. 找出一个数组中出现次数超过半数的元素(保证答案存在) ?
思路:借助collections库中的Counter对数组中的元素进行频次计算,并返回一个相应的字典,然后对该字典进行升序排列;根据元素的半数值,对字典进行遍历得到相应的满足条件的打印。
from collections import Counter
c = Counter()
half_c = len(A)/2
res_A = c(A).sorted(reverse=True)
for a,b in res_A.items():
if b >= half_c:
print(a)
else:
return 0三、 京东2019春招京东算法类试卷
1. 在对问题的解空间树进行搜索的方法中,一个结点有多次机会成为活结点的是:()回朔法
回朔法(深度优先法): 深度优先,可以回到此节点,此节点再次成为活结点延伸
分支界限法(广度优先法): 活节点一旦成为扩展节点,就不可再回转回活节点。
- 以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树
- 分支限界法中,每一个活结点只有一次机会成为扩展结点,活结点一旦成为扩展结点,就一次性产生其所有儿子结点,其中导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中
- 然后从活结点表中取下一结点成为当前扩展结点
- 重复上述结点扩展过程,直至到找到所需的解或活结点表为空时为止
从中可以看出,广度优先且不满足的被舍弃,满足的找其儿子节点,所以其不可能再次成为活结点
2. 下列有关图的说法错误的是() C
A. 在有向图中,出度为0的结点成为叶子结点
B. 用邻接矩阵表示图,容易判断任意两个结点之间是否有边相连,并求得各结点的度
C. 按深度方向遍历图和前序遍历树类似,得到的结果是唯一的(x)
D.若有向图G中从结点Vi到结点Vj有一条路径,则在图G的结点的线性序列中结点Vi必在结点Vj之前的话,则称为一个拓扑序列
解释:
* 深度优先搜索(DFS)序列不唯一,其与算法、图的存储结构及出发点有关
* 在邻接表不确定或者没给出的情况下,深度优先和广度优先均有多种可能。
3. 在软件开发过程中,我们可以采用不同的过程模型,下列有关增量模型描述正确的(B) (没懂)
A. 已使用一种线性开发模型,具有不可回溯性 (x)
B.把待开发的软件系统模块化,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件
C. 适用于已有产品或产品原型(样品),只需客户化的工程项目 (x)
D.软件开发过程每迭代一次,软件开发又前进一个层次 (x)
解释: 增量模型是把待开发的软件系统模块化,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件。运用增量模型的软件开发过程是递增式的过程。相对于瀑布模型而言,采用增量模型进行开发,开发人员不需要一次性地把整个软件产品提交给用户,而是可以分批次进行提交。
4. 要交换变量A和B的值,应使用的语句组( )
C=A;A=B;B=C
5. 用俩个栈模拟实现一个队列,如果栈的容量分别是O和P(O>P),那么模拟实现的队列最大容量是多少? 2P+1
栈A的容量为O,栈B的容量为P,由于O>P,则A为存储栈,B为缓存区
1.将1,..,P元素入栈A,栈底到栈顶的顺序为P,…,1,然后A栈弹出,依次入栈B,然后输出1,,..P
2.将P+1,…,2P+1元素入栈A,然后依次弹出2P+1,…,P+1共P个元素,然后依次入栈B,栈A弹出输出P+1,栈B依次弹出P+2,..,2P+1元素,则实现队列容量为2P+1
6. 下列关于队列的叙述中正确的是() 队列是先进先出的线性表
7. 栈的特点是先进后出。栈底至栈顶依次存放元素A、B、C、D, 在第五个元素E入栈前,栈中元素可以出栈,则出栈序列可能是:()A
A. DCBEA
B.DEBCA
C.DBCEA
D.DCAEB
8. 下列叙述中,有关线性链表叙述正确的是(D)(注意:存储方式分为:顺序存储和链式存储)
A. 线性链表中的表头元素一定存储在其他元素的前面 (若是顺序存储,则是如此)
B. 线性链表中的各元素在存储空间中的位置不一定是连续的,但表头元素一定存储在其他元素的前面(后半句有问题)
C. 线性链表中的各元素在存储空间中的位置必须是连续的 (若是顺序存储,则是如此)
D. 线性链表中的各元素在存储空间中的位置不一定是连续的,且各元素的存储顺序也是任意的
9. 关系型数据库创建表都有主键。以下对主键描述正确的是:C
A. 主键是唯一索引,唯一索引也是主键 (主键一定是唯一索引,但唯一索引不一定就是主键。其他列也可以成为唯一索引,一张表中可以有除了主键之外的其他的唯一索引)
B. 主键是一种特殊的唯一性索引,只可以是聚集索引 (后半句错误)
C. 主键是唯一、不为空值的列(既是唯一索引列,也是唯一不为空值的列)
D. 对于聚集索引来说,创建主键时,不会自动创建主键的聚集索引
10. 如果ORDER BY子句后未指定ASC或DESC,默认使用以下哪个?默认是升序的ASC,如果想要升序的效果,则采用DESC。
11. 以下程序统计给定输入中每个大写字母的出现次数(不需要检查合法性)
void
AlphabetCounting(char a[],int n){
int
count[26]={},i,kind=0;
for(i=0;i<n;++i) (____________);
for(i=0;i<26;++i){
if(++kind>1) putchar(';');
printf("%c=%d",(____________));
}
}以下能补全程序,正确功能的选项是()
++count['Z'-a[i]]
'Z'-i,count[i]解析:
题意为输入设定全是大写 (ASCII码A-Z为65-90,递增):
一、count存储A-Z的个数,即count[0]存储A的个数,于是 ++count[a[i]-‘A’]; ‘A’+i,count[i];
二、count存储Z~A的个数,即count[0]存储Z的个数,于是 ++count[‘Z’-a[i]]; ’Z’-i,count[i]
12. 已知int占4个字节,bool占1个字节。
unsigned int
value = 1024;
bool condition =
*((bool *)(&value));
if (condition)
value += 1; condition = *((bool *)(&value));
if (condition)
value += 1; condition = *((bool *)(&value));问value, condition 的值为____。 1024, 0
解释:1024——100 00000000 :共10个0, bool condition =*((bool *)(&value)); 取了后面8位的0作为bool变量值,一直是0,没执行过value +=1;
13. 关于类的静态成员的不正确描述是()D
A. 静态成员不属于对象,是类的共享成员 (对)
B. 静态成员要在类外定义和初始化 (对)
C. 静态成员函数不拥有this指针,需要通过类参数访问对象成员 (对)
D. 只有静态成员函数可以操作静态数据成员
14. 以下程序 运行后的结果是: (主要是考察:++x是先进行累加,然后输出x;而x++是先输出x然后才进行累加)
main()
{
int m=12,n=34;
printf("%d%d",m++,++n);
printf("%d%d\n",n++,++m);
}结果: 12353514
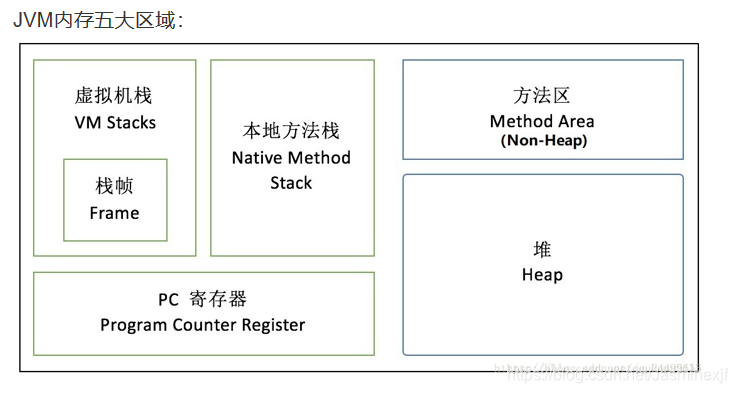
15. JVM内存不包含如下哪个部分( ) Heap Frame
直接上JVM的示意图:
16. 下列哪些操作会使线程释放锁资源?BC
A. sleep()
B.wait()
C.join()
D.yield()
解释:
1)
所谓的释放锁资源实际是通知对象内置的monitor对象进行释放,而只有所有对象都有内置的monitor对象才能实现任何对象的锁资源都可以释放。又因为所有类都继承自Object,所以wait()就成了Object方法,也就是通过wait()来通知对象内置的monitor对象释放,而且事实上因为这涉及对硬件底层的操作,所以wait()方法是native方法,底层是用C写的。
其他都是Thread所有,所以其他3个是没有资格释放资源的
而join()有资格释放资源其实是通过调用wait()来实现的
2)
1.sleep()方法
在指定时间内让当前正在执行的线程暂停执行,但不会释放“锁标志”。不推荐使用。
sleep()使当前线程进入阻塞状态,在指定时间内不会执行。
2.wait()方法
在其他线程调用对象的notify或notifyAll方法前,导致当前线程等待。线程会释放掉它所占有的“锁标志”,从而使别的线程有机会抢占该锁。
当前线程必须拥有当前对象锁。如果当前线程不是此锁的拥有者,会抛出IllegalMonitorStateException异常。
唤醒当前对象锁的等待线程使用notify或notifyAll方法,也必须拥有相同的对象锁,否则也会抛出IllegalMonitorStateException异常。
waite()和notify()必须在synchronized函数或synchronized block中进行调用。如果在non-synchronized函数或non-synchronized block中进行调用,虽然能编译通过,但在运行时会发生IllegalMonitorStateException的异常。
3.yield方法
暂停当前正在执行的线程对象。
yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
yield()只能使同优先级或更高优先级的线程有执行的机会。
4.join方法
join()等待该线程终止。
等待调用join方法的线程结束,再继续执行。如:t.join();//主要用于等待t线程运行结束,若无此句,main则会执行完毕,导致结果不可预测
17. 下列说法正确的是( )C
A. volatile,synchronized都可以修改变量,方法以及代码块
B.volatile,synchronized 在多线程中都会存在阻塞问题
C.volatile能保证数据的可见性,但不能完全保证数据的原子性,synchronized即保证了数据的可见性也保证了原子性
D.volatile解决的是变量在多个线程之间的可见性、原子性,而sychroized解决的是多个线程之间访问资源的同步性
补充:
volatile和synchronized的区别
* volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
* volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
* volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
* volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
* volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
18. java8中,下面哪个类用到了解决哈希冲突的开放定址法 (不会java)
答案是: ThreadLocal,并有:threadlocalmap使用开放定址法解决haah冲突,hashmap使用链地址法解决hash冲突
19. 当一个嵌套函数在其外部区域引用了一个值时,该嵌套函数就是一个闭包,以下代码输出值为:
def adder(x):
def
wrapper(y):
return x + y
return wrapper
adder5 = adder(5)
print(adder5(adder5(6)))16(5+6+5)
解释:
1. 如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数。
2. 在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
3. 一般情况下,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
因为wrapper是闭包 所以adder5返回的是wrapper函数 接下来adder5(6) 返回的是11=5+6 同理 再调用一次就是16 = 11+5
20. 关于Python中的复数,下列说法错误的是()D
A.表是复数的语法是real + image j (OK)
B. 实部和虚部都是浮点数
C.虚部必须后缀j,且必须小写 (错误,可以是j,也可以是J)
D.方法conjugate返回复数的共轭复数
21. 下面哪个是Python中的不变的数据结构?tuple (元组可以理解为一个固定的列表,一旦初始化其中的元素便不可修改(认真理解这句话),只能对元素进行查询 )
而 set、list、dict均是可以改变的数据结构。
22. 已知print_func.py的代码如下:
print('Hello World!')
print('__name__value: ', __name__)
def main():
print('This message is from main function')
if __name__ =='__main__':
main()
# 而print_module.py是这样的
import print_func
print("Done!")结果是这样的“:
Hello World!
__name__value: print_func
Done!23. Zookeeper在 config 命名空间下,每个znode最多能存储()数据? 1M (不懂,多看)
ZooKeeper数据模型中的每个znode都维护着一个
stat
结构。一个stat仅提供一个znode的
元数据
。它由版本号,操作控制列表(ACL),时间戳和数据长度组成。
-
版本号
– 每个znode都有版本号,这意味着每当与znode相关联的数据发生变化时,其对应的版本号也会增加。当多个zookeeper客户端尝试在同一znode上执行操作时,版本号的使用就很重要。 -
操作控制列表(ACL)
– ACL基本上是访问znode的认证机制。它管理所有znode读取和写入操作。 -
时间戳
– 时间戳表示创建和修改znode所经过的时间。它通常以毫秒为单位。ZooKeeper从“事务ID”(zxid)标识znode的每个更改。
Zxid
是唯一的,并且为每个事务保留时间,以便你可以轻松地确定从一个请求到另一个请求所经过的时间。 -
数据长度
– 存储在znode中的数据总量是数据长度。你最多可以存储1MB的数据。
24.
一般情况下,串行程序并行化设计需要将工作进行拆分,使得分布在每个进程中的工作量大致相仿,并行让它们之间的通信量最少。以下串行程序并行化设计步骤正确的是:
1、将串行程序中需要要执行的指令和数据按照计算部分拆分成多个小任务
2、将上一步聚合好的任务分配到进程/线程中。这一步还主要注意的是,要使得通信量最小化,让各个进程/线程所得到的工作量大致均衡
3、确定第一步识别出来的任务之间需要执行何种通信
4、将第一步确定的任务与通信结合成更大的任务
答案: 1–> 3 –>4 –>2
25. 以下哪个模型是生成式模型: 常见的有HMM、高斯模型、贝叶斯模型、潜在狄利克雷函数等;而常见的SVM、LR、CRF、LDA(线性判别分析)是判别式分析。
26. 因为文本数据在可用的数据中是非常无结构的,它内部会包含很多不同类型的噪点,所以要做数据预处理。以下不是自然语言数据预处理过程的是:B
A.词汇规范化
B.词汇关系统一化(NO)
C. 对象标准
D.噪声移除
27. 可以从新闻文本数据中分析出名词短语,动词短语,主语的技术是?
依存分析和句法分析
28. 均值移动(Mean Shift)算法的核心思想是: B
A. 构建Hessian矩阵,判别当前点是否为比邻域更亮或更暗的点,由此来确定关键点的位置
B.找到概率密度梯度为零的采样点,并以此作为特征空间聚类的模式点(核心思想)
C.从每一个点开始作为一个类,然后迭代的融合最近的类。能创建一个树形层次结构的聚类模型
29. 随机抽样一致算法(random sample consensus,RANSAC),采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。对于RANSAC的基本假设描述不正确的是: B
A. 给定一组(通常很小)的内群,存在一个程序,这个程序可以估算最佳解释或最适用于这一数据模型的参数
B.离群点离inliers集中区域的差距再可控范围内(在不可控制范围内)
C. “内群”数据可以通过几组模型的参数来叙述其分别,而“离群”数据则是不适合模型化的数据
D.数据会受噪声影响,噪声指的是离群,例如从极端的噪声或错误解释有关数据的测量或不正确的假设
30. (在线编程题) (个人没太懂题目的要求)
有一个含有n个数字的序列,每个数字的大小是不超过200的正整数,同时这个序列满足以下条件:
1. a_1<=a_2
2. a_n<=a_(n-1) (此时n>2)
3. a_i<=max(a_{i-1},a_{i+1})
但是很不幸的是,在序列保存的过程中,有些数字丢失了,请你根据上述条件,计算可能有多少种不同的序列可以满足以上条件。
解析:
