目录
B-tree
全称Balance-tree(平衡多路查找树),平衡的意思是左边和右边分布均匀。多路的意思是相对于二叉树而言的,二叉树就是二路查找树,查找时只有两条路,而B-tree有多条路,即父节点有多个子节点。
一、术语
阶:B树中所有孩子节点数的最大值
度:树的高度(一般不包括叶子节点的那层,实际上术语 叶子 的定义也不一致。
Bayer & McCreight(1972)
认为叶子层是最下面一层的键,但是 Knuth 认为叶子层是最下面一层键之下的一层 (
Folk & Zoellick 1992
,p.363)。可能的实现有许多。在一些设计中,叶子可能保存了完整的数据记录;在另一些设计中,叶子可能只保存了指向数据记录的指针。)
二、定义
根据 Knuth 的定义,一个 m 阶的B树是一个有以下属性的树:
- 每一个节点最多有 m 个子节点
- 每一个非叶子节点(除根节点)最少有 ⌈m/2⌉ 个子节点
- 如果根节点不是叶子节点,那么它至少有两个子节点
- 有 k 个子节点的非叶子节点拥有 k − 1 个键
- 所有的叶子节点都在同一层
当你学完B树后,我们可以总结一个更加详细的定义
(1)树中每个结点至多有m棵子树(注:m指的是树的阶);
(2)若根结点不是叶子结点,则至少有两棵子树(注:根节点至少有两个儿子);
(3)除根结点之外的所有非叶子结点至少有p个子节点([m/2] <= p <= m , [ ] 为向上取整)
(4)所有的非叶子结点中包含以下数据:(n,A0,K1,A1,K2,…,Kn,An)
其中:
Ki(i=1,2,…,n)为关键字,且Ki<Ki+1(注:ki是真实数据,存放在线性表当中,且从左至右升序排列)
Ai 为指向儿子的指针(i=0,1,…,n),且指针Ai-1 所指子树中所有结点的关键码均小于Ki (i=1,2,…,n),An 所指子树中所有结点的关键码均大于Kn。(注:每个ki数据两旁各安放了一个指针,即Ai-1和Ai,左边的子树数据统统小于ki,右边子树的数据统统大于ki)(注:总体来看指针数量比关键字量多1) n 为关键字的个数([m/2] – 1 <= n <= m-1)
(5)所有的叶子结点都出现在同一层次上,即所有叶节点具有相同的深度。并且不带信息(可以看作是外部结点或查找失败的结点,实际上这些结点不存在,指向这些结点的指针为空)。
三、n个关键字,阶数为m,高度为h,有如下公式:
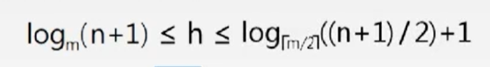
推导过程
:
(1) 总关键字数目 n = 每个节点的关键字数 * 总的节点数
所以 n 最大可取:
n <= (m-1) * (1+ m + m^2 + m^3 + … + m^h)
解释
:当阶数为m时,意味着每个非叶节点至多有m棵子树,即意味着每个节点中至多存在m个指向子树的指针,我们知道,每个非叶子结点中包含以下数据:(n,A0,K1,A1,K2,…,Kn,An),其中A为指针,K为关键字,不难发现,关键字的数目比指针数目少一。所以当n取最大时,每个节点的关键字数目要取满,即为m-1,对应式子中的(m-1)。式子中的(1+ m + m^2 + m^3 + … + m^h)怎么来的呢?这一项为节点数,第一层最多有一个节点,第二层有m个节点,第三层就应该有m*m即m^2个结点,以此类推。
反解得到
![]()
(2) 我们知道,树中的除根之外的非叶节点最少有[m/2]棵子树,而根结点若不是叶子结点,则至少有两棵子树。
所以第一层根节点有一个节点,第二层最少有2个节点,那第三层最少就有2*[m/2]个结点 ,第四层就有2*[m/2]^2个节点,以此类推,第h+1层就会有2*[m/2]^(h-1)个节点(h+1层为失败节点所在的层)。
这样我们就得到了第二个式子的左边,那右边 n+1 怎么来的呢?
在B树中,每一个叶子节点代表着一次查询的失败,如果你把一颗B树展开成一条数轴,那么B树上的关键字对应数轴上一个个标记出来的点,你每一次在B书中的查询就是为了找到其中的一个点,那点和点之间存在的区间,就是你查询失败所落在的地方,对应到B树,就是一个叶子节点。
存在 n 个关键字,那就存在 n+1 个区间即 n+1个叶子节点,这是那么就有:
2*[m/2]^(h-1) <= n+1
反解得到
![]()
四、B树的查找:
总结两点:
(1)找节点 (2)比较关键字
因为关键字与关键字之间存在指针,所以比关键字小的沿左边的指针继续找,比关键字大的沿右边的指针继续找,直至找到为止
五、B树的插入:
所有的插入都从根节点开始。要插入一个新的元素,首先搜索这棵树找到新元素应该被添加到的对应节点。将新元素插入到这一节点中的步骤如下:
- 如果节点拥有的元素数量小于最大值,那么有空间容纳新的元素。将新元素插入到这一节点,且保持节点中元素有序。
- 否则的话这一节点已经满了,将它平均地分裂成两个节点:
-
- 从该节点的元素和新的元素中选择出中位数
- 小于这一中位数的元素放入左边节点,大于这一中位数的元素放入右边节点,中位数作为分隔值。
- 分隔值被插入到父节点中,这可能会造成父节点分裂,分裂父节点时可能又会使它的父节点分裂,以此类推。如果没有父节点(这一节点是根节点),就创建一个新的根节点(增加了树的高度)。
如果分裂一直上升到根节点,那么一个新的根节点会被创建,它有一个分隔值和两个子节点。这就是根节点并不像内部节点一样有最少子节点数量限制的原因。每个节点中元素的最大数量是 U-1。当一个节点分裂时,一个元素被移动到它的父节点,但是一个新的元素增加了进来。所以最大的元素数量 U-1 必须能够被分成两个合法的节点。如果 U-1 是奇数,那么设 U=2L ,总共有 2L-1 个元素,一个新的节点有 L-1 个元素,另外一个有 L 个元素,都是合法的节点。如果 U-1 是偶数,那么设 U-1=2L,总共有 2L 个元素。每 一半都是 L,正好是节点允许的最小元素数量。
六、B树的删除:
- 搜索要删除的元素
- 如果它为最底层元素(不是叶子节点,是叶子节点上一层的节点,因为前文提到,叶子节点不存储任何信息),将它从中删除
- 若该元素为非最底层元素,则按下列步骤:
内部节点中的每一个元素都作为分隔两颗子树的分隔值,因此我们需要重新划分。值得注意的是左子树中最大的元素仍然小于分隔值。同样的,右子树中最 小的元素仍然大于分隔值。这两个元素任何一个都可以作为两颗子树的新分隔值。算法的描述如下:
3.1 选择一个新的分隔符(左子树中最大的元素或右子树中最小的元素),将它从该节点中移除,替换掉被删除的元素作为新的分隔值。
3.2 前一步删除了一个节点中的元素。如果这个节点拥有的元素数量小于最低要求,那么从这一节点开始重新进行平衡。
3.3 删除后的重新平衡:
重新平衡从叶子节点开始向根节点进行,直到树重新平衡。如果删除节点中的一个元素使该节点的元素数量低于最小值,那么一些元素必须被重新分配。重新平衡树的算法如下:
如果缺少元素节点的右兄弟存在且拥有多余的元素,那么:
-
- 将父节点的分隔值复制到缺少元素节点的最后(分隔值被移下来;缺少元素的节点现在有最小数量的元素)
- 将父节点的分隔值替换为右兄弟的第一个元素(右兄弟失去了一个节点但仍然拥有最小数量的元素)
- 树又重新平衡
否则,如果缺少元素节点的左兄弟存在且拥有多余的元素,那么:
-
- 将父节点的分隔值复制到缺少元素节点的第一个节点(分隔值被移下来;缺少元素的节点现在有最小数量的元素)
- 将父节点的分隔值替换为左兄弟的最后一个元素(左兄弟失去了一个节点但仍然拥有最小数量的元素)
- 树又重新平衡
否则,如果它的两个直接兄弟节点都只有最小数量的元素,那么将它与一个直接兄弟节点以及父节点中它们的分隔值合并
-
- 将分隔值复制到左边的节点(左边的节点可以是缺少元素的节点或者拥有最小数量元素的兄弟节点)
- 将右边节点中所有的元素移动到左边节点(左边节点现在拥有最大数量的元素,右边节点为空)
- 将父节点中的分隔值和空的右子树移除(父节点失去了一个元素)
3.1如果父节点是根节点并且没有元素了,那么释放它并且让合并之后的节点成为新的根节点(树的深度减小)
3.2否则,如果父节点的元素数量小于最小值,重新平衡父节点