1、支持向量机
支持向量机(Support Vector Machine)是一种二类分类模型,支持向量机的间隔最大化使它有别于感知机,同时支持向量机还包括核技巧,使得它解决非线性分类的问题。
这里的间隔分为
硬间隔
和
软间隔
。硬间隔是指间隔内没有误分类点,软间隔是允许间隔内有误分类点。
支持向量机学习方法包括构建由简至繁的模型:线性可分支持向量机、线性支持向量机及非线性支持向量机。当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机;当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
2、模型
支持向量机是定义在特征空间上的间隔最大的线性分类器,所以,支持向量机的模型是一个具有“最大间隔”的划分超平面。
因此,支持向量机的划分超平面是
w
T
∗
x
+
b
=
−
1
w^T*x+b=-1
w
T
∗
x
+
b
=
−
1
到
w
T
∗
x
+
b
=
1
w^T*x+b=1
w
T
∗
x
+
b
=
1
的超平面,所以,预测样本点:
{
w
T
∗
x
+
b
≤
−
1
,
y
i
=
−
1
w
T
∗
x
+
b
≥
1
,
y
i
=
1
\begin{cases} w^T*x+b≤-1, & y_i=-1 \\ w^T*x+b≥1, & y_i=1 \end{cases}
{
w
T
∗
x
+
b
≤
−
1
,
w
T
∗
x
+
b
≥
1
,
y
i
=
−
1
y
i
=
1
3、策略
支持向量机的间隔:
r
=
2
∣
∣
w
∣
∣
r = \frac{2}{||w||}
r
=
∣
∣
w
∣
∣
2
支持向量机在最大化间隔,那么也就是最小化:
∣
∣
w
∣
∣
||w||
∣
∣
w
∣
∣
,等价于最小化
∣
∣
w
∣
∣
2
2
\frac{||w||^2}{2}
2
∣
∣
w
∣
∣
2
(方便计算)。
所以,对于
硬间隔
,其损失函数就是:
l
o
s
s
=
∣
∣
w
∣
∣
2
2
loss = \frac{||w||^2}{2}
l
o
s
s
=
2
∣
∣
w
∣
∣
2
∣
∣
w
∣
∣
2
2
\frac{||w||^2}{2}
2
∣
∣
w
∣
∣
2
越小,间隔越大,而软间隔是允许可以有错误分类的,那间隔就可以无限大了,所以软间隔不能直接使用它来做损失函数,必须对误分类的样本做“惩罚”,而支持向量机使用误分类样本的计数来正则化
软间隔
的损失函数:
l
o
s
s
=
∣
∣
w
∣
∣
2
2
+
C
∑
i
=
1
m
l
0
/
1
(
y
i
∗
(
w
T
∗
x
+
b
)
−
1
)
loss = \frac{||w||^2}{2} + C\sum_{i=1}^ml_{0/1}(y_i*(w^T*x+b)-1)
l
o
s
s
=
2
∣
∣
w
∣
∣
2
+
C
i
=
1
∑
m
l
0
/
1
(
y
i
∗
(
w
T
∗
x
+
b
)
−
1
)
其中:
l
0
/
1
(
z
)
=
{
1
,
z
<
0
0
,
z
≥
0
l_{0/1}(z)=\begin{cases} 1, & z<0 \\ 0, & z≥0 \end{cases}
l
0
/
1
(
z
)
=
{
1
,
0
,
z
<
0
z
≥
0
对于误分类的样本点,有:
如果
y
i
=
−
1
,
而
w
T
∗
x
+
b
≥
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
<
0
y_i=-1,而w^T*x+b≥1,则y_i*(w^T*x+b)-1<0
y
i
=
−
1
,
而
w
T
∗
x
+
b
≥
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
<
0
,
l
0
/
1
(
z
)
=
1
l_{0/1}(z)=1
l
0
/
1
(
z
)
=
1
;
如果
y
i
=
1
,
而
w
T
∗
x
+
b
≤
−
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
<
0
y_i=1,而w^T*x+b≤-1,则y_i*(w^T*x+b)-1<0
y
i
=
1
,
而
w
T
∗
x
+
b
≤
−
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
<
0
,
l
0
/
1
(
z
)
=
1
l_{0/1}(z)=1
l
0
/
1
(
z
)
=
1
;
对于正确分类的样本点,有:
如果
y
i
=
−
1
,
而
w
T
∗
x
+
b
≤
−
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
≥
0
y_i=-1,而w^T*x+b≤-1,则y_i*(w^T*x+b)-1≥0
y
i
=
−
1
,
而
w
T
∗
x
+
b
≤
−
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
≥
0
,
l
0
/
1
(
z
)
=
0
l_{0/1}(z)=0
l
0
/
1
(
z
)
=
0
;
如果
y
i
=
1
,
而
w
T
∗
x
+
b
≥
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
≥
0
y_i=1,而w^T*x+b≥1,则y_i*(w^T*x+b)-1≥0
y
i
=
1
,
而
w
T
∗
x
+
b
≥
1
,
则
y
i
∗
(
w
T
∗
x
+
b
)
−
1
≥
0
,
l
0
/
1
(
z
)
=
0
l_{0/1}(z)=0
l
0
/
1
(
z
)
=
0
;
所以
∑
i
=
1
m
l
0
/
1
(
y
i
∗
(
w
T
∗
x
+
b
)
−
1
)
\sum_{i=1}^ml_{0/1}(y_i*(w^T*x+b)-1)
∑
i
=
1
m
l
0
/
1
(
y
i
∗
(
w
T
∗
x
+
b
)
−
1
)
是对误分类点的计数,而参数
C
C
C
决定了误分类点的重要程度;如果
C
C
C
无限大,那么对误分类点的“惩罚”也就无限大,也就是无法忍容有错误分类,那就是硬间隔了。
4、内核
在现实中,数据往往是非线性可分的,而支持向量机可以使用核函数来划分非线性的数据。
1、多项式核函数
如图所示,在坐标轴上,有八个样本点,很明显,没有任何一条线能完美划分红蓝色的样本点,但如果使用多项式就可以完美划分;
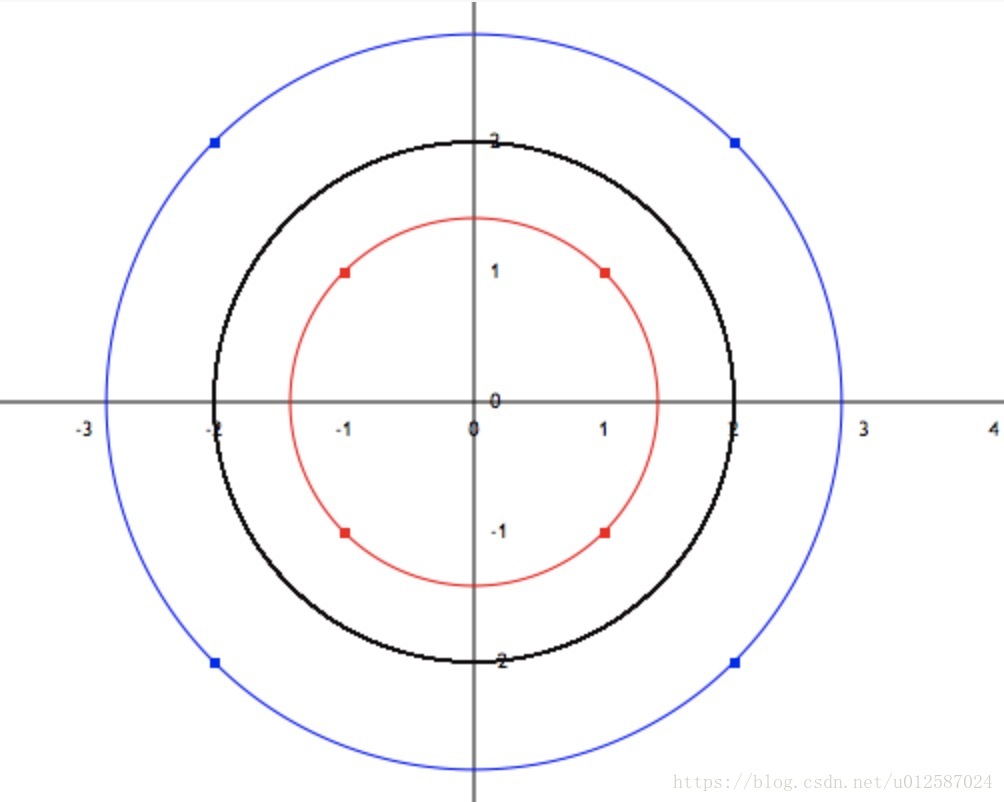
红点所在的圆的方程
x
2
+
y
2
=
2
x^2+y^2 = 2
x
2
+
y
2
=
2
,蓝点所在的圆的方程
x
2
+
y
2
=
8
x^2+y^2 = 8
x
2
+
y
2
=
8
,根据支持向量机的间隔最大化可得,划分红蓝点的圆的方程为
x
2
+
y
2
=
4
x^2+y^2 = 4
x
2
+
y
2
=
4
,这就是支持向量机的核函数了。
2、高斯径向基函数(rbf)
略!(没找到绘制高斯分布的工具,就不知道要怎么用文字简单地表达出来了)
5、sklearn上的SVM
from sklearn.svm import SVC
clf = SVC()
clf.fit(X_train, y_train)
clf.predict(X_test)
参数说明:
C:误分类的正则系数;
kernel:”linear”线性内核,”poly”多项式内核,”rbf”高斯径向基内核;
gamma:当kernel=”rbf”时,gamma是指
γ
\gamma
γ
参数,
γ
=
1
2
σ
2
\gamma = \frac{1}{2\sigma^2}
γ
=
2
σ
2
1
,gamma的值越大,高斯曲线越细高,gamma的值越小,高斯曲线越宽矮;
degree:当kernel=”poly”时,degree为最大单项式次数;