1 xgboost存在的问题以及可以改进的地方
在决策树的生成过程中采用了精确贪心的思路,寻找最佳分裂点的时候,使用了预排序算法, 对
所有特征
都按照特征的数值进行预排序, 然后
遍历所有特征上的所有分裂点位
,计算按照这些候选分裂点位分裂后的
全部样本
的目标函数增益,找到最大的那个增益对应的特征和候选分裂点位,从而进行分裂。这样一层一层的完成建树过程, xgboost训练的时候,是通过加法的方式进行训练,也就是每一次通过聚焦残差训练一棵树出来, 最后的预测结果是所有树的加和表示。
因此gboost寻找最优分裂点的复杂度=
特征数量×分裂点的数量×样本的数量
,因此如果我们相对xgboost做一些优化的话,我们可以从上面的三个角度下手,比如减少特征数量、分裂点的数量或样本的数量等。
2 lightgbm的改进
2.1 减少分裂点数量:直方图算法
直方图算法说白了就是把连续的浮点特征离散化为k个整数(也就是分桶bins的思想),并根据特征所在的bin对其进行梯度累加和个数统计。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
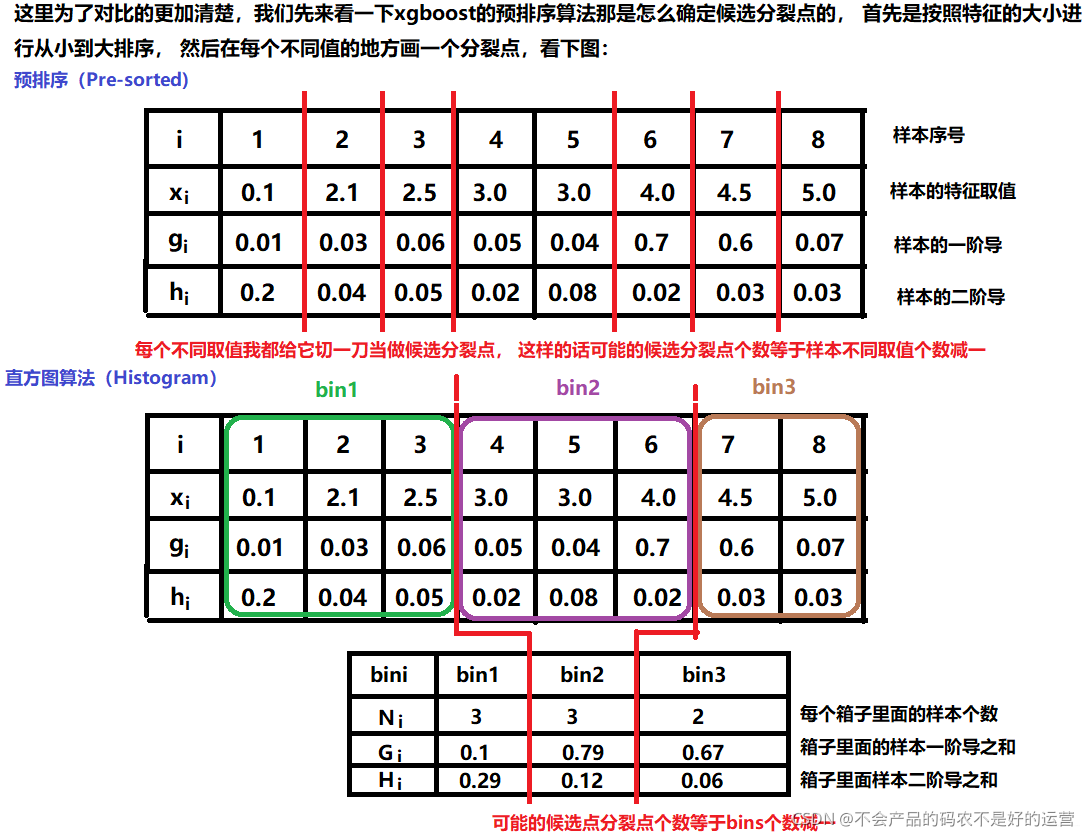
这样在遍历到该特征的时候,只需要根据直方图的离散值,遍历寻找最优的分割点即可,由于bins的数量是远小于样本不同取值的数量的,所以分桶之后要遍历的分裂点的个数会少了很多,这样就可以减少计算量。
离散化分桶的好处有:
1、减少了存储空间。xgboost需要32位int存储排序后的索引和32位float存储样本的特征取值。而lightgbm不仅不需要存储排序的结果,并且只需要8位int存储feature bins就行
2、时间复杂度降低:从之前的O(featurevalue_nums-1
features_num )降低到O(bin_nums-1
features_num )
3、速度进一步加快:直方图作差加速,当节点分裂成两个时,右边的子节点的直方图其实等于其父节点的直方图减去左边子节点的直方图
4、可以防止过拟合:采用Histogram算法会起到正则化的效果,bin数量决定了正则化的程度,bin越少惩罚越严重,欠拟合风险越高
2.2 减少采样:单边梯度抽样算法(GOSS)
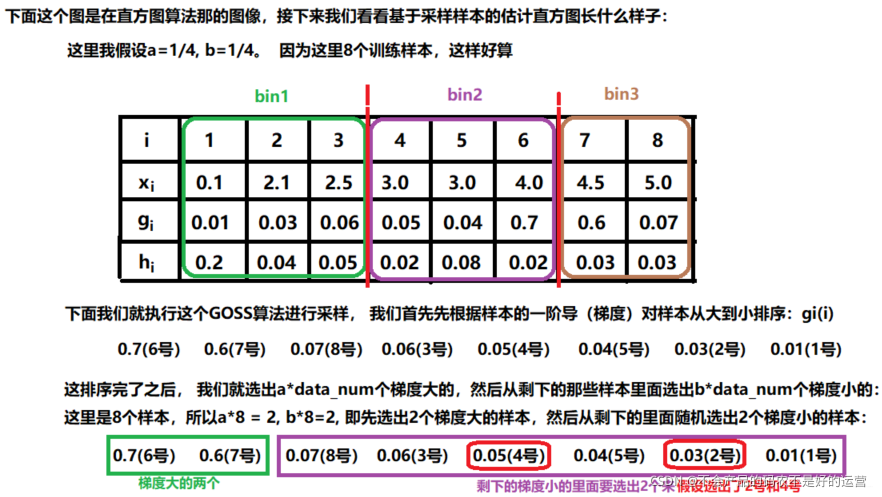
排除梯度小的样本,侧重梯度大的样本(在gbdt中,当损失函数为平凡损失函数时,梯度就是残差)。但是要是盲目的直接去掉这些梯度小的数据,这样就会改变数据的分布。
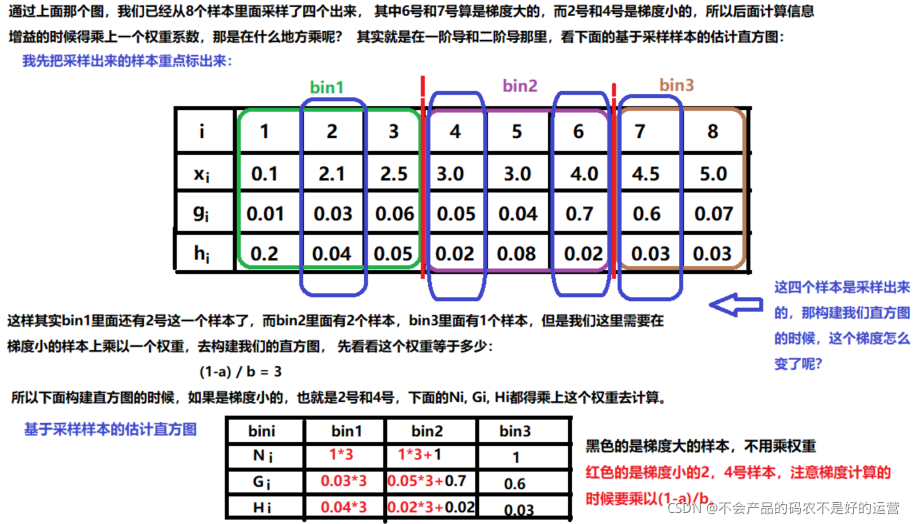
GOSS 算法保留了梯度大的样本,并对梯度小的样本进行随机抽样,为了不改变样本的数据分布,在计算增益时为梯度小的样本引入一个常数进行平衡。首先将要进行分裂的特征的所有取值按照绝对值大小降序排序(xgboost也进行了排序,但是LightGBM不用保存排序后的结果),然后拿到前a %的梯度大的样本,和剩下样本的b %,在计算增益时,后面的这b% 通过乘上(1-a)/b来放大梯度小的样本的权重。一方面算法将更多的注意力放在训练不足的样本上,另一方面通过乘上权重来防止采样对原始数据分布造成太大的影响。
2.3减少特征:互斥特征捆绑算法

- 怎么判定哪些特征应该绑在一起?
- 特征绑在一起之后,特征值应该如何确定呢
对于问题一,捆绑特征就是在干这样的一件事:
- 首先将所有的特征看成图的各个顶点,将不相互独立的特征(某个特征的所有非0样本和另一个样本所有非0样本都不相同)用一条边连起来,边的权重就是两个相连接的特征的总冲突值(也就是这两个特征上同时不为0的样本个数)。
- 然后按照节点的度对特征降序排序, 度越大,说明与其他特征的冲突越大
-
对于每一个特征, 遍历已有的特征簇,如果发现该特征加入到特征簇中的矛盾数不超过某一个阈值,则将该特征加入到该簇中。 如果该特征不能加入任何一个已有的特征簇,则新建一个簇,将该特征加入到新建的簇中。
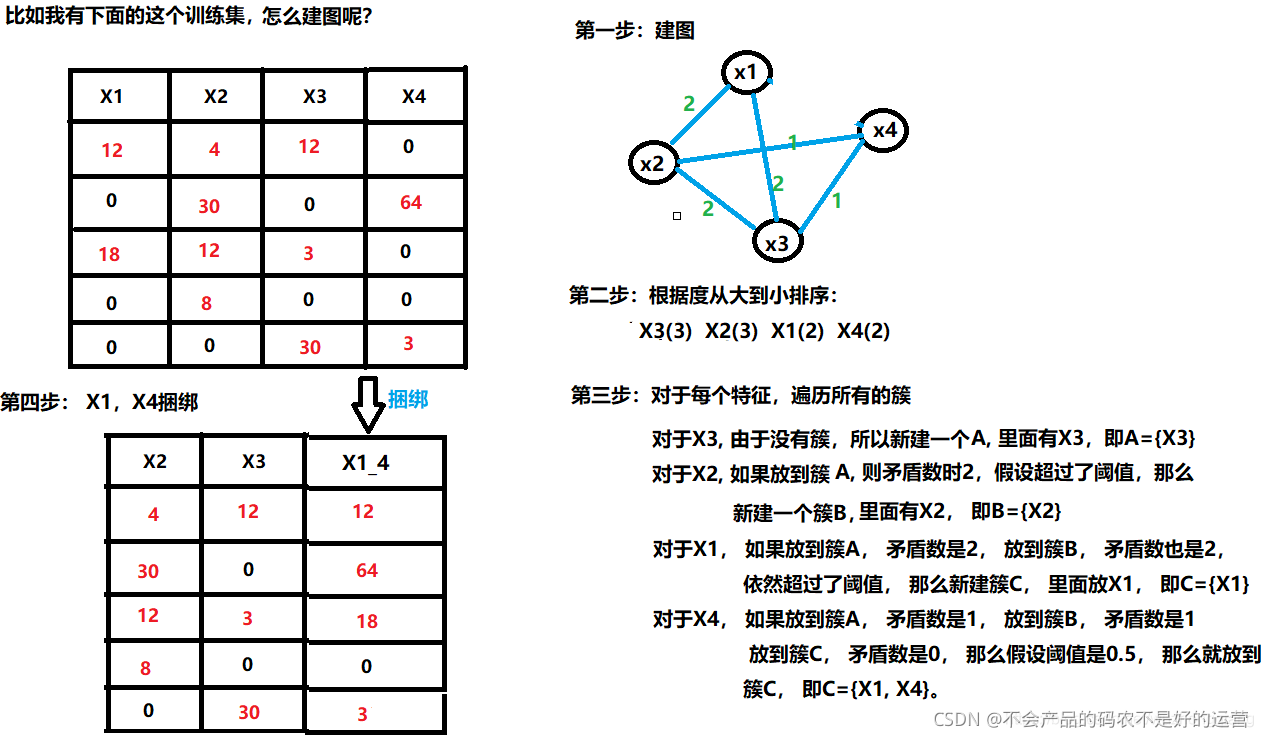
对于问题二,关键在于绑定几个特征在同一个bundle里需要保证绑定前的原始特征的值可以在bundle里面进行识别。比如,我们把特征A和B绑定到了同一个bundle里面, A特征的原始取值区间[0,10), B特征原始取值区间[0,20), 这样如果直接绑定,那么会发现我从bundle里面取出一个值5, 就分不出这个5到底是来自特征A还是特征B了。 所以我们可以再B特征的取值上加一个常量10转换为[10, 30),这样绑定好的特征取值就是[0,30), 我如果再从bundle里面取出5, 就一下子知道这个是来自特征A的。
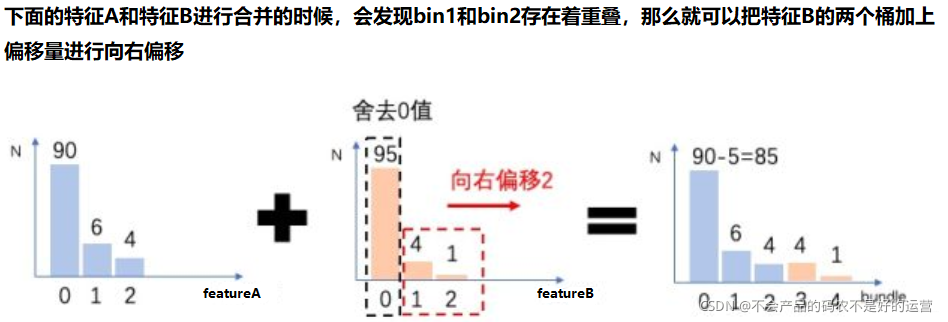
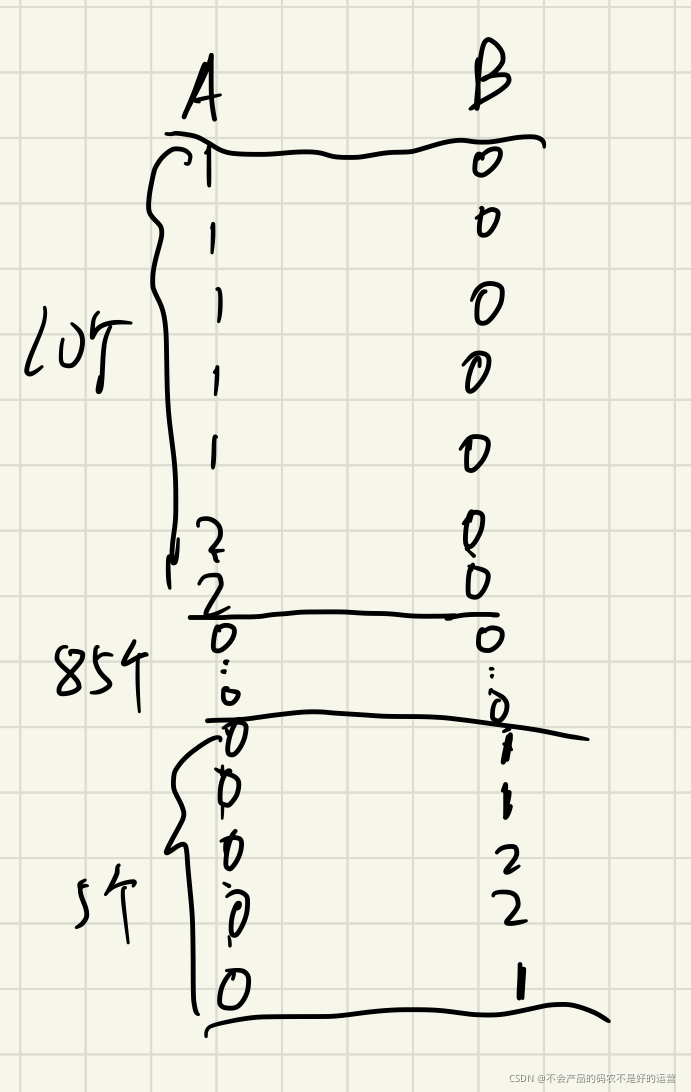
A这边10个非0,对应了B的10个0, B的5个非0,对应了A的5个0, 而剩下的就是B和A的0对应0, 这时候A还有85个0, B还有85个0, 此时只需要去掉B那边的非0值的下标,合并之后,就能直接区分开0值来自A了
2.4 leaf-wise和level-wise决策树生成算法
lightgbm除了在寻找最优分裂点过程中进行了优化,其实在树的生成过程中也进行了优化, 它抛弃了xgboost里面的按层生长(level-wise), 而是使用了带有深度限制的按叶子生长(leaf-wise)
————————————————
XGBoost 在树的生成过程中采用 Level-wise 的增长策略,该策略遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂,因此带来了很多没必要的计算开销(一层一层的走,不管它效果到底好不好)
————————————————
Leaf-wise 则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同 Level-wise 相比,在分裂次数相同的情况下,Leaf-wise 可以降低更多的误差,得到更好的精度。Leaf-wise 的缺点是可能会长出比较深的决策树,产生过拟合。因此 LightGBM 在 Leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。 (最大信息增益的优先, 我才不管层不层呢)
————————————————
3 lightgbm实战
3.1 基本使用
sklearn接口调用
# 创建模型,训练模型
gbm = LGBMRegressor(objective='regression'
,num_leaves=31
,learning_rate=0.05
,n_estimators=20)
gbm.fit(x_train,y_train
,eval_set=[(x_test,y_test)]
,eval_metric='l1'
,early_stopping_rounds=5)
gbm.score(x_test,y_test)
3.2 调参
1、针对leaf-wise树的参数优化:
· max_depth: 控制了树的最大深度
· num_leaves:控制了叶节点的数
· min_data_in_leaf: 每个叶节点的最少样本数量
2、针对更快的训练速度
· bagging_fraction 和 bagging_freq 参数来使用bagging方法
· feature_fraction 参数来使用特征的子抽样
· max_bin
· save_binary 在未来的学习过程对数据加载进行加速
3、获得更好的准确率
· 使用较大的 max_bin (学习速度可能变慢)
· 使用较小的 learning_rate 和较大的 num_iterations
· 使用较大的 num_leaves (可能导致过拟合)
· 使用更大的训练数据
· 尝试DART
4、缓解过拟合
· 使用较小的 max_bin,分桶粗一些
· 使用较小的 num_leaves 不要在单棵树分的太细
· 使用 lambda_l1, lambda_l2 和 min_gain_to_split 来使用正则
· 尝试 max_depth 来避免生成过深的树
· 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf,确保叶子节点有足够多的数据
4 LightGBM的工程优化
4.1 类别特征的支持
4.2 高效并行
4.3 Cache命中率优化
5 参考资料
https://zhongqiang.blog.csdn.net/article/details/105350579