按照服务器程序的一般原理,讲服务器结构为如下三个主要模块:
- I/O处理单元
- 逻辑单元
- 存储单元
服务器模型
第一种:C/S模型
TCP/IP协议在设计和实现上并没有客户端和服务器的概念,在通信 过程中所有机器都是对等的。但由于资源(视频、新闻、软件等)都被数据提供者所垄断,所以几乎所有的网络应用程序都很自然地采用了图C/S(客户端/服务器)模型:所有客户端都通过访问服务器来获取所需的资源。
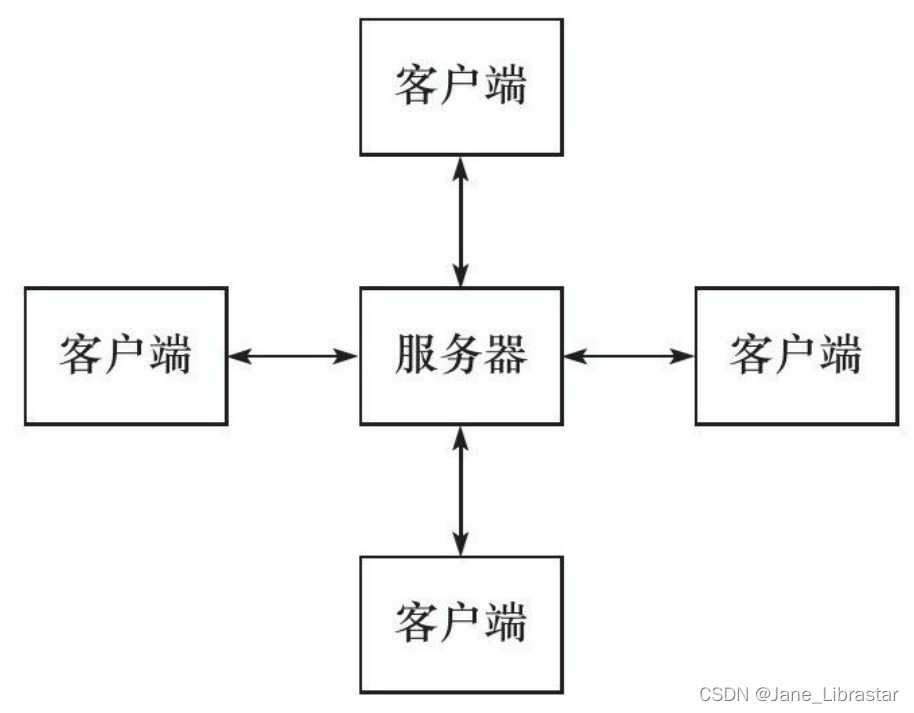
C/S模型的逻辑很简单:服务器启动后,首先创建一个(或多个)监听socket,并调用bind函数将其绑定到服务器感兴趣的端口上,然后调用listen函数等待客户连接。服务器稳定运行之后,客户端就可以调用connect函数向服务器发起连接了。由于客户连接请求是随机到达的异步事件,服务器需要使用某种I/O模型来监听这一事件。
C/S模型
非常
适合资源相对集中的场合
,并且它的实现也很简单,但其
缺点
也很明显:
服务器是通信的中心,当访问量过大时,可能所有客户都将得到很慢的响应
。
第二种:P2P模型
P2P模型比C/S模型更符合网络通信的实际情况。它摒弃了以服务器为中心的格局,让网络上所有主机重新回归对等的地位。P2P模型如图所示:以实际使用的P2P模型通常带有一个专门的发现服务器。这个发现服务器通常还提供查找服务(甚至还可以提供内容服务),使每个客户都能尽快地找到自己需要的资源。
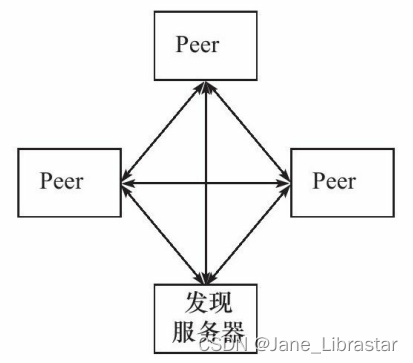
P2P模型
使得每台机器
在消耗服务的同时也给别人提供服务
,这样资源能够充分、自由地共享。云计算机群可以看作P2P模型的一个典范。但P2P模型的
缺点
也很明显:
当用户之间传输的请求过多时,网络的负载将加重
。
从编程角度来讲,P2P模型可以看作C/S模型的扩展:每台主机既是客户端,又是服务器。
服务器编程框架
服务器程序虽然种类繁多,但是其基本框架都一样,不同之处在于逻辑处理。服务器的基本框架如下:
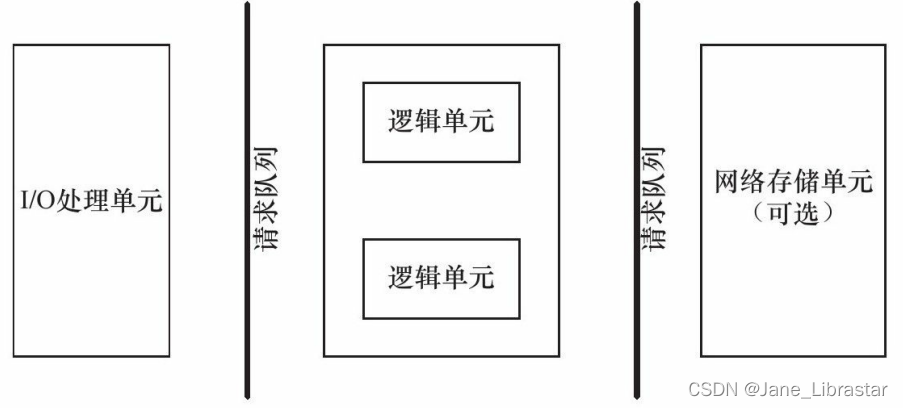
- I/O处理单元:是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。但是,数据的收发不一定在I/O处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。对于一个服务器机群来说,I/O处理单元是一个专门的接入服务器。它实现负载均衡,从所有逻辑服务器中选取负荷最小的一台来为新客户服务。
- 逻辑单元:通常是一个进程或线程。它分析并处理客户数据,然后将结果传递给I/O处理单元或者直接发送给客户端。对服务器机群而言,一个逻辑单元本身就是一台逻辑服务器。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并行处理。
- 网络存储单元:可以是数据库、缓存和文件,甚至是一台独立的服务器。但它不是必须的,比如ssh、telnet等登录服务就不需要这个单元。
- 请求队列:是各单元之间的通信方式的抽象。I/O处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。同样,多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理 竞态条件。请求队列通常被实现为池的一部分,我们将在后面讨论池的概念。对于服务器机群而言,请求队列是各台服务器之间预先建立的、 静态的、永久的TCP连接。这种TCP连接能提高服务器之间交换数据的效率,因为它避免了动态建立TCP连接导致的额外的系统开销。
I/O模型
socket在创建的时候默认是阻塞的。我们可以给socket 系统调用的第2个参数传递SOCK_NONBLOCK标志,或者通过fcntl系统 调用的F_SETFL命令,将其设置为非阻塞的。阻塞和非阻塞的概念能应 用于所有文件描述符,而不仅仅是socket。我们称阻塞的文件描述符为 阻塞I/O,称非阻塞的文件描述符为非阻塞I/O。
- 针对阻塞I/O执行的系统调用可能因为无法立即完成而被操作系统挂起,直到等待的事件发生为止。
- 针对非阻塞I/O执行的系统调用则总是立即返回,而不管事件是否已经发生。如果事件没有立即发生,这些系统调用就返回-1,和出错的情况一样。
显然,我们只有在事件已经发生的情况下操作非阻塞I/O(读、写等),才能提高程序的效率。因此,非阻塞I/O通常要和其他I/O通知机制一起使用,比如I/O复用和SIGIO信号。
I/O复用是最常使用的I/O通知机制。它指的是,应用程序通过I/O复用函数向内核注册一组事件,内核通过I/O复用函数把其中就绪的事件通知给应用程序。I/O复用函数本身是阻塞的,它们能提高程序效率的原因在于它们具有同时监听多个I/O事件的能力。
SIGIO信号也可以用来报告I/O事件,我们可以为一个目标文件描述符指定宿主进程,那么被指定的宿主进程将捕获到SIGIO信号。这样,当目标文件描述符上有事件发生时,SIGIO信号的信号处理函数将被触发,我们也就可以在该信号处理函数中对目标文件描述符执行非阻塞I/O操作了。
同步I/O向应用程序通知的是I/O就绪事件,而异步I/O向应用程序通知的是I/O完成事件。
两种高效的事件处理模式
随着网络设计模式的兴起,Reactor和Proactor事件处理模式应运而生。
同步I/O模型
通常用于实现
Reactor模式
,
异步I/O模型
则用于实现
Proactor模式
。不过后面我们将看到,如何使用同步I/O方式模拟出Proactor模式。
Reactor模式
它要求主线程(I/O处理单元)只负责监听文件描述上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元)。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
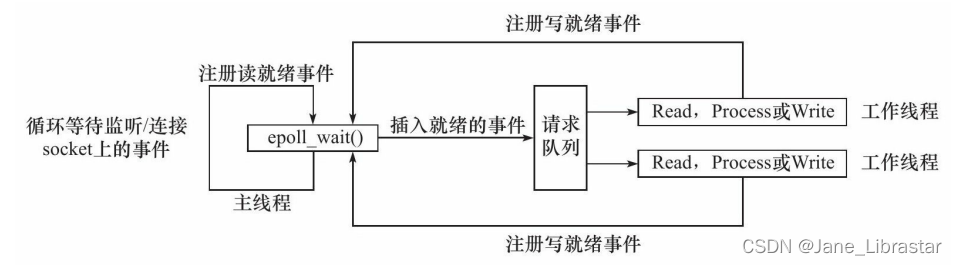
使用同步I/O模型实现的Reactor模式的工作流程是:
- 主线程往epoll内核事件表中注册socket上的读就绪事件
-
主线程调用epoll_wait等待socket上有数据可读
-
当socket上有数据可读时,epoll_wait通知主线程。主线程则将 socket可读事件放入请求队列
-
睡眠在请求队列上的某个工作线程被唤醒,它从socket读取数据,并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件
-
主线程调用epoll_wait等待socket可写
-
当socket可写时,epoll_wait通知主线程。主线程将socket可写事件放入请求队列
-
睡眠在请求队列上的某个工作线程被唤醒,它往socket上写入服务器处理客户请求的结果。
Proactor模式
与Reactor模式不同,Proactor模式将所有I/O操作都交给主线程和内核来处理,工作线程仅仅负责业务逻辑。使用异步I/O模型实现的Proactor模式的工作流程是:
-
主线程调用aio_read函数向内核注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序
- 主线程继续处理其他逻辑
-
当socket上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据已经可用
-
应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求之后,调用aio_write函数向内核注册socket上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序
- 主线程继续处理其他逻辑
-
当用户缓冲区的数据被写入socket之后,内核将向应用程序发送一个信号,以通知应用程序数据已经发送完毕
-
应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭socket。
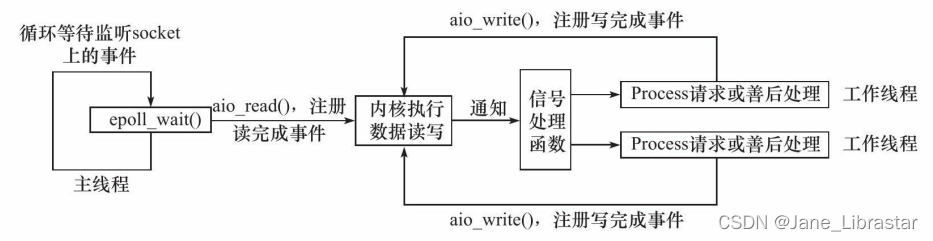
连接socket上的读写事件是通过aio_read/aio_write向内核注册的,因此
内核将通过信号来向应用程序报告连接socket上的读写事件
。所以,主线程中的epoll_wait调用仅能用来检测监听socket上的连接请求事件,而不能用来检测连接socket上的读写事件(跟Reactor的区别)。