目录
1. 使操作系统对访问或者映射的合法性检查,杀掉非法进程,从而保护数据安全。
2. 使物理内存分配与进程管理,通过页表进行解耦,在加载时确定映射关系后,相互独立
3. 保证每个进程以统一的视角(有序的区域划分)进行管理,完成进程独立性的实现

前言: 地址空间回顾
之前我们学习C是,对内存分布的了解

字符串常量在静态常量区(静态区)
那么这真的是内存吗?
答案是:不是
那我们之前所了解的上图又是什么? 那真正的内存又是指什么?让我们来解释其中的奥秘
验证:一个变量是否会有两个值?
我们运行下面的代码
#include <iostream>
2 #include <unistd.h>
3 using namespace std;
4
5 int _gar = 100;
6 int main()
7 {
8 pid_t pd = fork();
9
10 if (pd == 0)
11 {// 子进程
12 int cen = 0;
13 while (1)
14 {
15 cout << "I am child ,Pid :" << getpid() << " PPid:" << getppi d() << " _gar = " << _gar << "地址:" << &_gar << endl;
16 sleep(1);
17 cen++;
18 if (cen == 5)
19 {
20 _gar = 200;
21 cout << "100 -> 200 seccoss -gar = " << _gar << "++++++++++ +++++++++++" << endl;
22 }
23 }
24 }
25 else
26 {
27 // 父进程
28 while (1)
29 {
30 cout << "I am father ,Pid :" << getpid() << " PPid:" << getpp id() << "
_gar = " << _gar << "地址:" << &_gar << endl;
31 sleep(1);
32 }
33 }
34
35 return 0;
36 }
根据我们实验出来的结果:
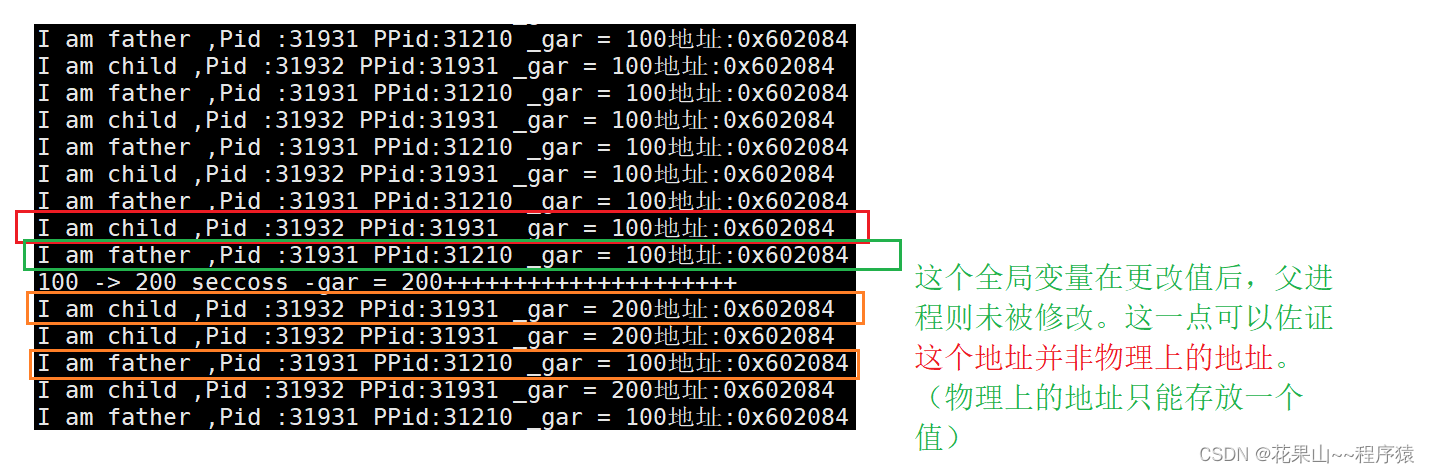
这其实是虚拟地址,也叫线性地址。
几乎所有的语言,所说的“地址”指的并非物理地址,而是虚拟地址!!!!
这里对本文刚开始的内存进行解释:
内存可以分为主存储器(主内存)和辅助存储器(如硬盘、固态硬盘等)。主内存是计算机中直接与CPU交互的存储器,用于存储当前正在执行的程序和数据。辅助存储器则用于长期存储数据,当程序或数据不再需要时,可以将其保存在辅助存储器中。(来源:chatgpt)
一. 什么是地址空间
虚拟地址与物理地址之间的关系
任何数据,都需要加载到内存中,都有各自的物理地址。如果我们进程A,B同时运行,相互独立,万一出现错误,将A将B中的数据读取了,这是极不安全的,而如果在虚拟地址上先操作,再通过一定的机制,确保访问的安全性。因此虚拟地址的存在,保护了物理地址上的数据安全。
地址空间
的本质是:
一种内核的
数据结构
,里面至少有各个区域的划分。

二. 地址空间是如何设计的
我们知道每个进程都有自己的PCB,同时task_struct里面有进程地址空间数据的存储结构,也就是
mm_struct
。虚拟地址经过页表映射,指向物理地址。
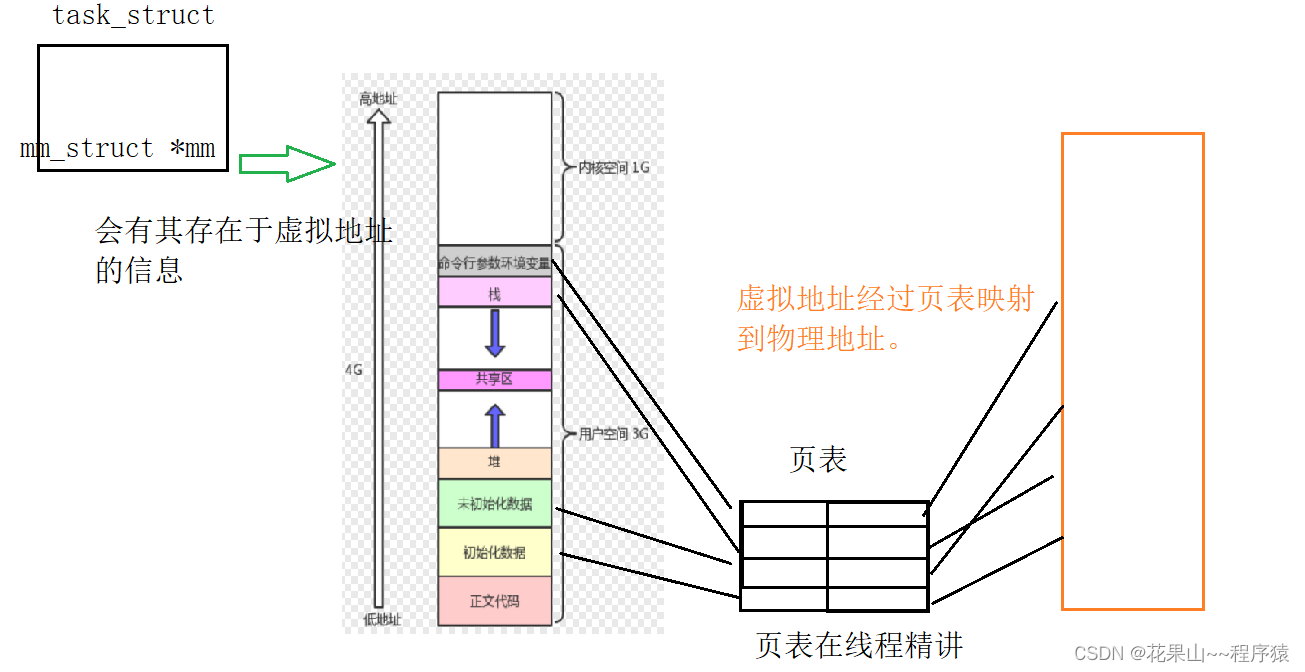
注意:每个进程中,不只是地址空间,页表也有自己私有一份。
这样我们只要
保证每个进程之间
经过页表映射后的
物理地址不同
,即可保证进程之间互不干涉。
1. 回答一个变量两个值
解释:
父进程通过自己的
task_struct
中地址空间数据访问到在物理空间上的数据,子进程则是共享父进程的代码,但当子进程想对数据进行修改,为了保证进程之间的独立性,系统决定进行写时拷贝,为子进程拷贝一份数据,同时修改子进程页表映射数据。这样就在表面上看就是相同变量,不同的值,但本质上是相同的虚拟地址,不同的页表,不同的物理地址,不同的值。
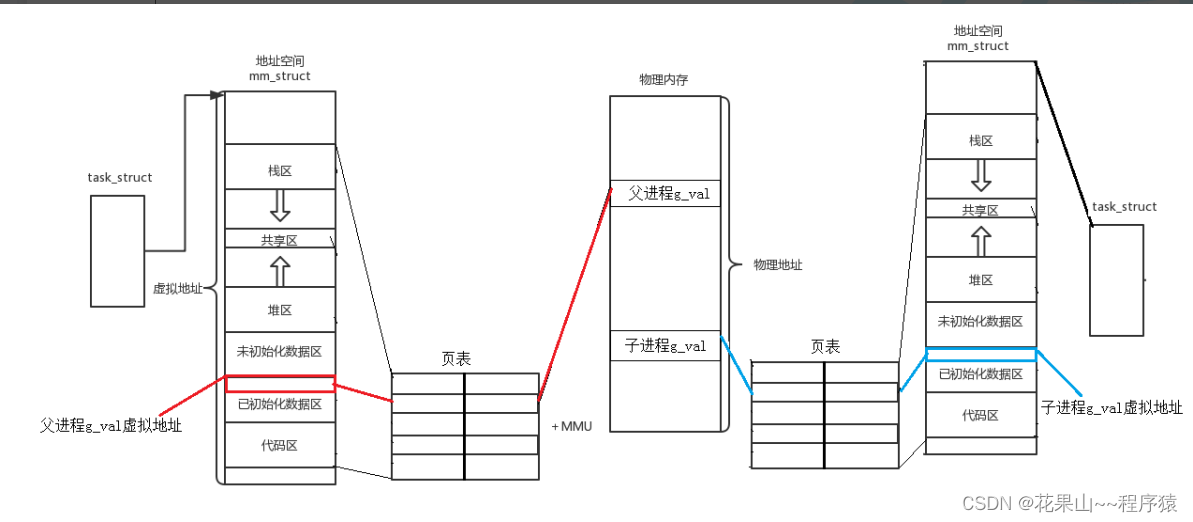
具体
的就体现在
id
的两次写入:

2.扩展
结论:在可执行程序,编译时
内部
就有地址了
我们在分析地址空间时,一直使用的是OS的视角,而不只是操作系统要遵守,编译器也要遵守! 即在编译器编译代码时,就已经在
内部
形成了地址,而且有各个区域:代码区,数据区…并且采用与linux内核一样的编址方式,每一个变量,每一行代码都有其虚拟地址。
继续深入理解
我们知道执行进程是通过虚拟地址+页表的方式来访问物理地址的,那可执行程序的虚拟地址和页表的数据又是从那里来的呢?
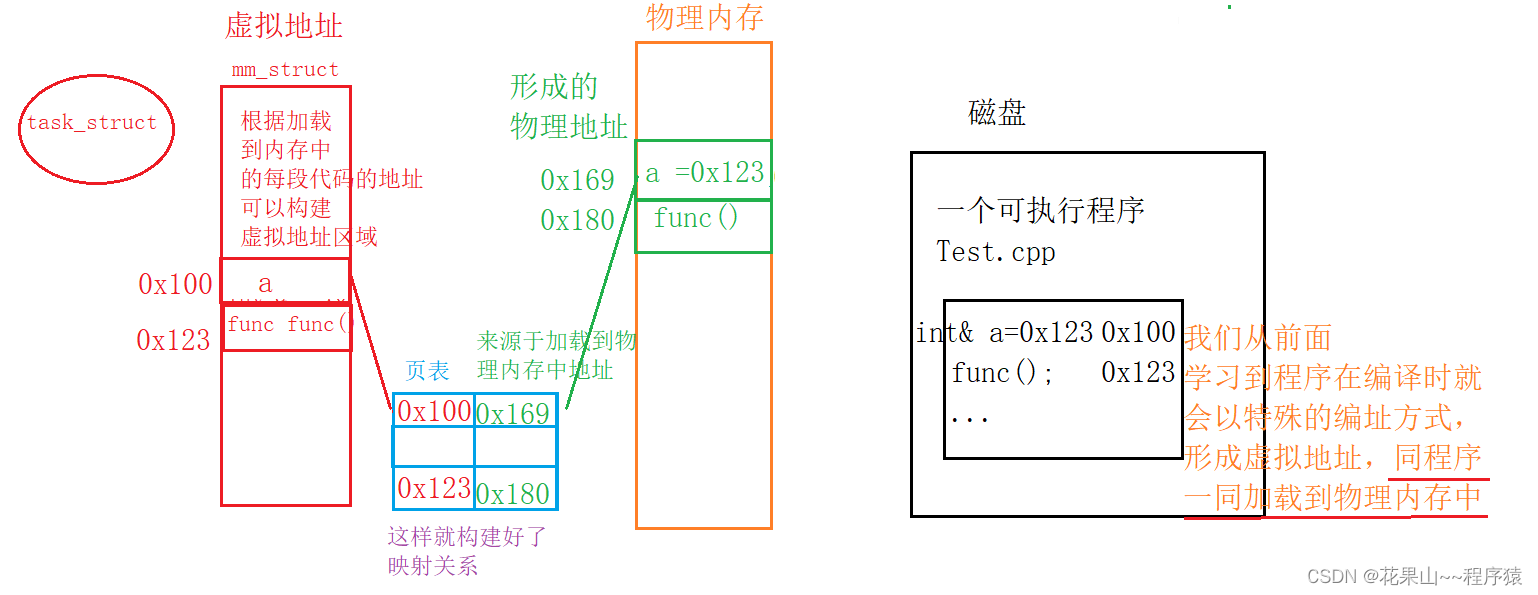
流程分析 :
所以CPU在读取到变量a时,根据虚拟地址0x100在代码段中寻找,在代码段查询页表后,再跳转0x169地址找到数据a,CPU获取其内部跳转虚拟地址0x123,再从虚拟地址中寻找,通过页表访问到函数func。(物理内存位置随便加载)
三. 为什么要有地址空间
原因:
1. 使操作系统对访问或者映射的合法性检查,杀掉非法进程,从而保护数据安全。
例:假设char* man = “鸡你太美”; *man = ‘寄’ , 我们在C语言期间就清楚字符常量无法修改,其原因来自底层
页表
中会
记录代码段地址
,并且
记录其读写权限
,操作系统检测到非法操作后就会中断结束进程,保护数据。(在物理内存我们是可以任意修改的,所以页表上的判断确保了操作的合法性,保护了数据的安全)
2. 使物理内存分配与进程管理,通过页表进行解耦,在加载时确定映射关系后,相互独立
问:是否可以提前加载未来的数据到物理内存中呢?
答:可以解析: 物理内存的分配和进程管理,之间可以说没有关系。这种关系叫做解耦合,那什么是强耦合呢?就是之间关系紧密,不容易分开,例如:你把函数内容写在main函数里面。
我们在学习C,C++时,在语言层面上new,malloc等内存分配上的操作都是在对
虚拟地址上的操作。
那疑问来了问:在进行
虚拟地址分配的时候
是否在
物理内存上分配资源
?答:
不会
,只在你访问时,才申请物理内存空间,通过这延迟分配的策略,提高整机效率。(这个操作仅操作系统自动完成,用户,进程0感知)
3. 保证每个进程以统一的视角(有序的区域划分)进行管理,完成进程独立性的实现
页表补充
以现在的视角看进程,加载内存就好像是创建进程,那是否会加载全部的数据到内存上呢?
我们在玩游戏时有的游戏动则40G,甚至是100G,我们的电脑是绝对装不下的,因此内存有一种内存换下机制,一些数据在一定时间内不再使用则被换下,加载新数据,(说到这里要对页表进行补充,
页表不只映射物理内存,也映射硬盘地址
)再次使用被换下的数据直接查询页表,用磁盘地址快速访问加载到内存中。
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获请留下你的小赞,
你的点赞和关注将会成为博主创作的动力
。