摘要
图对比学习在图表示学习领域树立了新的范式,不需要人工标注信息。但对GCL的分析却寥寥无几。本文通过分析一般化的GCL范式的各个部分包括增强函数,对比模式,对比目标和负采样技术,然后分析各个组件之间的相互作用。实验结论显示,简单的拓扑增强可以生成稀疏视图带来不错的性能提升;对比模型应该与最终任务的粒度一致。
引言
一个经典的图对比学习方法是首先通过对输入的随机增强构建多个图视图,然后通过对比正负样本学习表示。以每个节点作为中心节点为例,正样本一般是其他视图中表示一致的一些节点,而负样本则是在该Batch中的给定图或者其他图中选择其他节点作为负样本。
尽管图对比学习已经取得了很大的成功,但是已有工作只是在模型级别做了评估,对于到底是什么因子影响GCL的效果尚未可知。为了分析这些问题,我们首先提出了一个一般化的对比范式,将之前的工作分解为四个部分分别为1)数据增强函数,2)对比模式,3)对比目标函数,4)负采样策略
我们的工作企图回答如下三个问题:
1)一个有效的GCL算法中最重要的组成部分是什么?
2)不同的设计考虑如何影响模型性能?
3)这些设计考虑是否有利于某些特定类型的数据或终端任务?
为设计高效的GCL算法,实验得出几个指导原则:
1)生成稀疏视图的拓扑增强对GCL的提升最大。从拓扑结构和特征级别都做增强会进一步提升效果。
2)对比模式的尺度应该与下游任务的粒度一致,即下游任务是节点级任务,对比应该是节点级别的。
3)InfoNCE目标函数最稳定且效果提升最好,但是要求大量的负样本
4)一些免负采样的目标函数可以保证效果的同时降低计算复杂度
5)基于embedding相似度的负采样策略对GCL效果提升甚微
GCL范式和设计维度
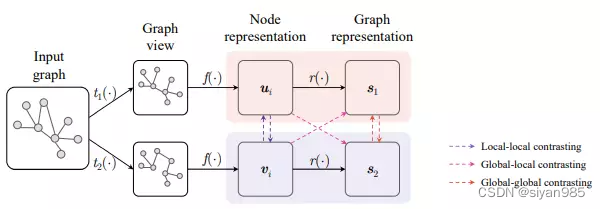
我们将GCL算法分解为四个部分:1)数据增强函数,2)对比模式,3)对比目标函数,4)负采样策略。在每一次迭代训练时,首先才能使用随机的增强技术为输入图生成多个视图。具体来讲就是从转化函数集T中采样两个增强函数t来生成两个视图;当得到两个视图后,使用一个共享参数的图编码器计算对应视图的节点表示。对于图级别的任务,可以选择readout函数为每个视图学习一个图级别的表示。
对于每一个节点,对比模式会指定一组正样本和一组负样本。在两个视图中,embedding对应同一节点或者图的组成正样本集。我们使用负采样策略通过考虑负样本的相对相似性提升负样本集。最终使用对比目标函数计算这些指定正负样本对的得分。
Data Augmentations
数据增强的目的是为给定图生成一致的,恒等的正样本。目前大多数GCL是使用两级的增强技术即结构转化和特征转化。
Topology augmentations
边:1)边移除(ER), 2)边添加(EA), 3)边翻转(EF),
点:1)点丢弃(ND),2)随机游走的子图(RWS), 3)使用个性化pagerank的扩散(PPR),4)使用马尔可夫扩散核的扩散(MDK)
Feature augmentations
1)特征遮掩(FM), 2)特征丢弃(FD)
Contrasting modes
对于每一个点,对比模式需要确定图上不同粒度的正负样本集、在主流的工作中广泛应用的三种对比模式即1)local-local,2)global-global,3)global-local。注意,对比模式的应用是依赖下游人物的,只有local-local和global-local能用于节点级任务,对于图级别的数据集,这三种模式都可以使用。
Contrastive objectives
目标函数是用于衡量正样本之间的相似性和负样本之间的差异性的。按照是否需要负采样分为
1)依赖负样本
a. InfoNCE,b. Jensen-Shannon Divergence,c. Triplet Margin loss
2)不依赖负样本
a. Boostrapping Latent loss,b. Barlow Twins loss,c. VICReg loss
Negative mining strategies
-
Hard Negative Mixing,2)Debiased Contrastive Learning,3)Hardness-Biased Negative Mining,4)Conditional Negative Mining

GCL模型的表达能力
Dual branches vs. single branch
大多数的对比学习模型都是借鉴SimCLR使用双同分支的,将原始输入图增强两次得到两个视图并跨视图设计正样本。但对于一些global-local模式的对比如DGI,GMI只用到了一个分支,这种情况下,负样本是通过在原始图上扰动得到的。不同于之前提到的增强方式,通过生成一致的节点对建模正样本对的联合分布,扰动函数估计的是边缘分布的乘积。
Stronger augmentations
不同于GRACE和GraphCL使用均匀的边或特征扰动,GCA基于边和特征的重要性采用自适应的增强方式。
Variants of contrasting modes
GMI在DGI的基础上进一步考虑节点(边)原生特征和对应表示之间的一致性,但是会需要更多的计算资源。最近一些方法受启发与图聚类算法,通过对比局部/全局和上下文表示来学习。
Empirical Studies
-
数据增强方式

GCL的效果高度依赖于数据增强方式的选取。

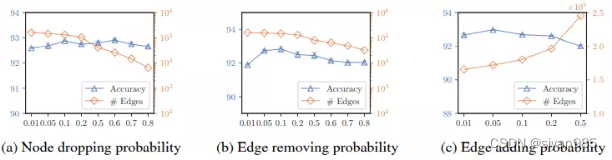
观察一:拓扑结构上的增强对模型结果影响最大。产生稀疏图的增强函数能得到更好的效果。
实验发现,与添加边相比移除边一般能达到更好的效果。也就是说得到一个稀疏的视图会更好一些。但稀疏的程度达到什么地步时可以取得最好的效果?本文分析了节点丢弃,边移除和边添加三种增强方式在CS数据集上的效果。实验发现,随着节点或边的减少,准确率会有一定的提升但随着大量的节点或边丢失,效果会极具下降。当边添加的越多时,准确率下降,这是因为大多数现实的图一般是稀疏的,太多的边添加进来会引入噪声,降低学习到的表示的质量。
观察二:特征增强可以带来额外的提升,综合结构和属性级别的增强对GCL更有利。
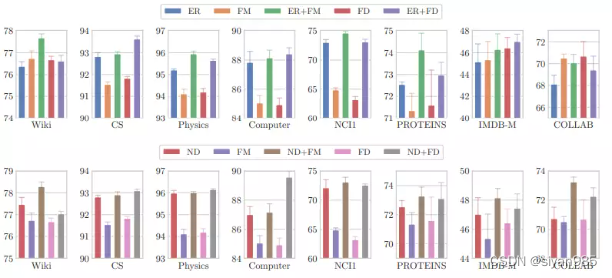
观察三:确定性的增强模式应该和随机的增强方式配合使用
实验发现,单一使用确定性的增强并不一定会达到最好的结果。对比学习的目标函数就是区分从真实数据分布中采样的样本和从噪声分布中采样的样本。因此,随机增强可以更好的近似噪声分布。
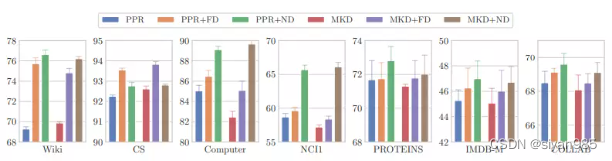
-
对比模式和目标函数

观察四:相同尺度的对比一般效果更好。不同粒度的下游任务使用不同的对比模式。
实验发现,local-local在节点分类任务中效果最好,global-global在图级任务中效果最好。一种可能的解释是在global-local模式中,图中所有的节点表示可能恰好是每个图嵌入的正样本即在这种模式下,会把所有node-graph对拉入一个嵌入空间中,造成次优结果。
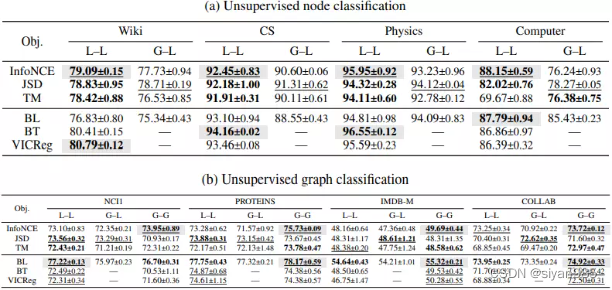
观察五:在所有基于负样本的目标函数中,InfoNCE的效果最好。
观察六:Bootstrapping Latent and Barlow Twins losses可以获得与对应基于负样本的方法相同的效果且不需要显示的负采样,不会增加计算负担。 -
负采样策略

观察七:现存的基于计算嵌入相似性的负采样策略对GCL效果的提升影响不大。
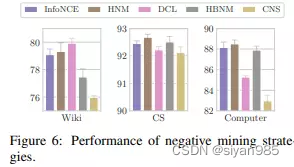
我们发现,目前的负采样技术一般是通过计算样本嵌入的内积来计算样本之间相似性的。在无监督情况下,目标函数会把不同的表示分开而不考虑真实的语义关系。更糟糕的是,大多是GCN会倾向于为邻居节点生成相似的表示并不会考虑语义信息,这样会加重负采样选择的偏差。一些可能是正样本的样本被选为负样本会阻碍训练效果。
结论
本文从数据增强,对比模型,对比目标函数和负采样策略四个角度分析了现有的GCL算法,我们的实验发现对今后的算法设计起到指导作用。但是GCL依旧存在很多问题等待解决。
1)影响因素的局限。本文只从四个角度分析了影响GCL效果的因素,但是对于模型相关的因素如是否在InfoNCE目标函数中加入映射头以及在GCL中应该用什么图编码器有还没有分析到。
2)下游任务的局限。本文主要从节点和图级别的分类任务,图级别的回归任务上做了处理。大量下游任务如连接预测,社区检测都尚未考虑
3)缺乏理论分析。本文只是从实验角度分析了结果,缺乏理论解释。
未来方向
1)自动增强。我们知道拓扑结构增强对于GCL是至关重要的,但是现存工作还是要手动设计增强策略,这样可能会导致次优化。目前,图结构学习上的工作可以学习最优的图结构,可以用于自动学习合适的增强函数
2)理解前置任务和下游任务之间的表现差异。我们的工作分析了最终任务和对比目标函数的关系,但是前置任务和下游任务之间的效果差异并未分析
3)基于结构感知的负采样。在视觉领域,相似的视觉特征一般语义类别也相似,但是在图结构中很难通过嵌入相似性进行衡量。以前的图嵌入工作在结构角度设计了一些方法,但是如何整合丰富的结构信息为GCL建模更好的负分布尚未探索。