T-分布领域嵌入算法(T-降维算法)stochastic neighbor embedding
作用:是相似度高的数据点聚合在一起。
参考视频:
链接:
【t-SNE/三分钟动画/史上最简单版本/包教包会/数据降维】https://www.bilibili.com/video/BV1va411m74T?vd_source=c03a1943d3ab774517684e95fd773d40
高维度计算
第一步:计算两点间的相似度
使用正太分布衡量两点间的距离,离得近的点具有较高的值,离得远的点具有较低的值。
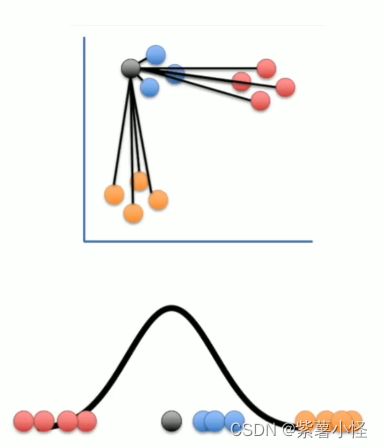
第二布 对相似度进行归一化,使每一个正态分布有相同的衡量标准。
第三步 把正太分布变成t-分布,因为t-分布受异常值影响更小。
最后得到相似度矩阵,红色表示具有较高相似性,白色代表低相似性
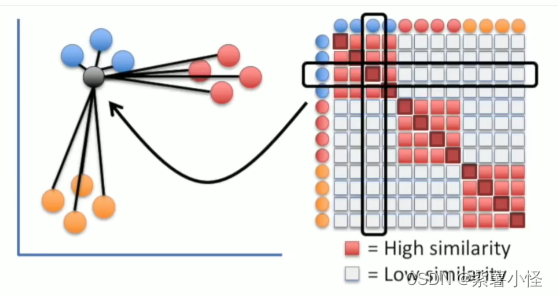
低纬度计算
先把点随机的投影在一条直线上,使用T分布来衡量两个点之间的距离,最终对随机的点计算出一个相似矩阵
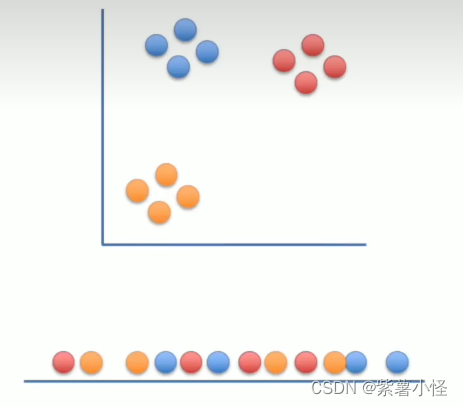
移动
把低维度的相似度矩阵通过移动变成高维度的相似矩阵
版权声明:本文为weixin_63629613原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。