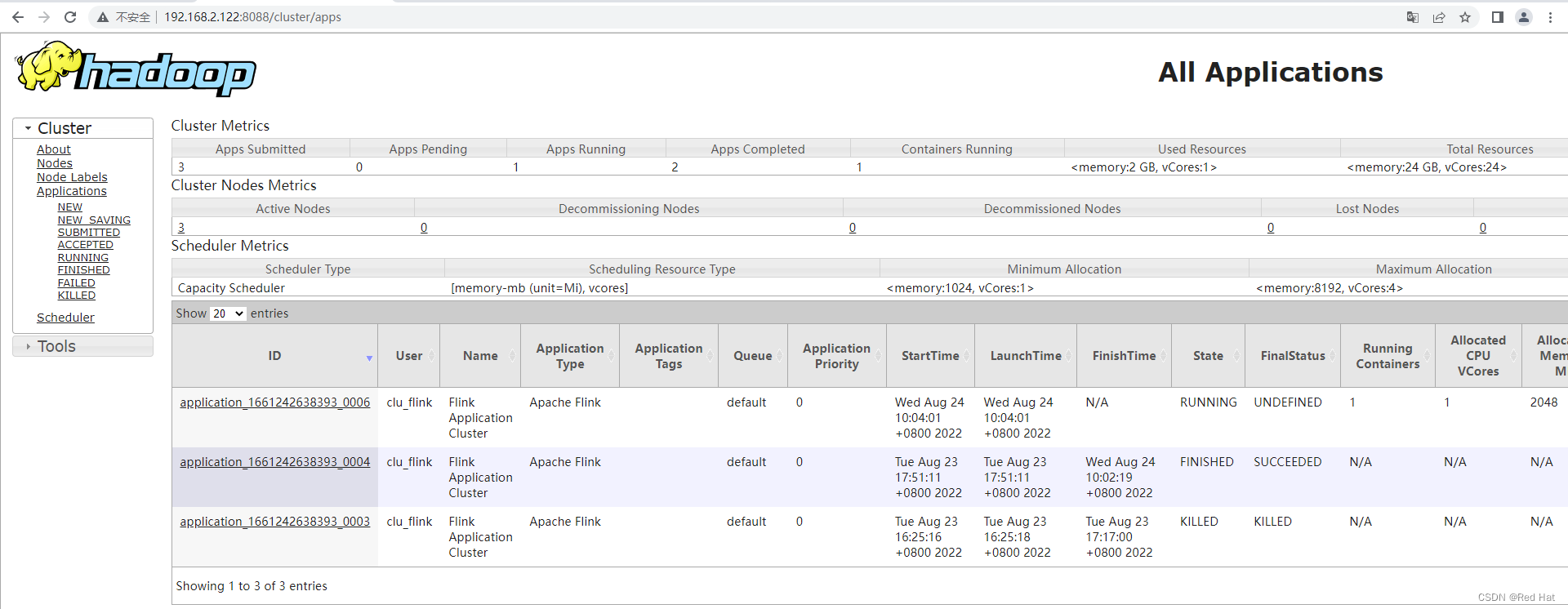
1、hadoop概述
HDFS的块是计算机系统最小的存储单元。它是分配给文件的最小的连续存储单元。在 Hadoop,也有块的概念,只是比计算机系统的块要大得多,默认是128MB或者256MB
NameNode是运行master节点的进程,它负责命名空间管理和文件访问控制。
DataNode是运行在slave节点的进程,它负责存储实际的业务数据。
Yarn内部有两个守护进程,分别是ResourceManager和NodeManager。ResourceManager 负责给application分配资源,而NodeManager负责监控容器使用资源情况,并把资源使用情况报告给ResourceManager。
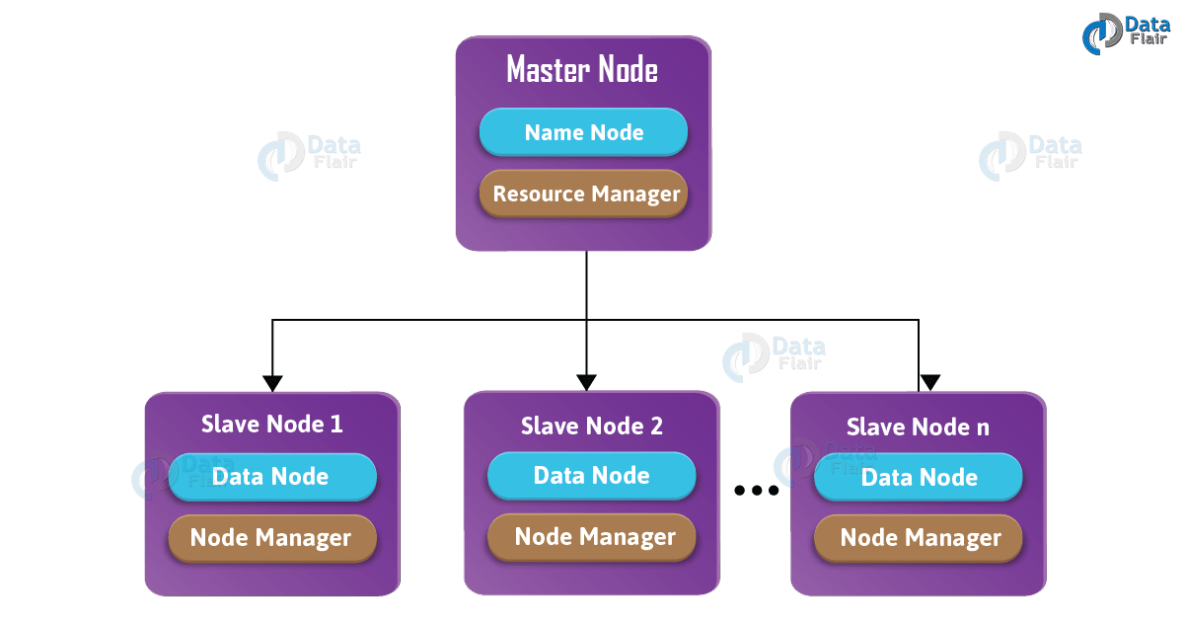
2、hadoop配置
基础环境可以参考:https://blog.csdn.net/weixin_43833235/article/details/126494345?spm=1001.2014.3001.5502
相关软件包:
链接:https://pan.baidu.com/s/1MrOG83wXaLdArsWxh_z8Og
提取码:gEt5
[root@node01 flink]# tar -xf hadoop-3.3.1.tar.gz -C /data/
[root@node01 flink]# mv /data/hadoop-3.3.1/ /data/hadoop
创建pids和logs文件
[root@node01 flink]# mkdir -p /data/hadoop/{pids,logs}
修改hadoop-env.sh配置
[root@node01 flink]# vim /data/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_92
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_LOG_DIR=/data/hadoop/logs
export HDFS_NAMENODE_USER=clu_flink
export HDFS_DATANODE_USER=clu_flink
export HDFS_SECONDARYNAMENODE_USER=clu_flink
export YARN_RESOURCEMANAGER_USER=clu_flink
export YARN_NODEMANAGER_USER=clu_flink
export HDFS_JOURNALNODE_USER=clu_flink
export HDFS_ZKFC_USER=clu_flink
修改/data/hadoop/etc/hadoop/core-site.xml
[root@node01 flink]# vim /data/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://nnha</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>Hadoop的超级用户root能代理的节点</description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>Hadoop的超级用户root能代理的用户组</description>
</property>
</configuration>
修改/data/hadoop/etc/hadoop/hdfs-site.xml和新建namenode和datanode文件夹
[root@node01 flink]# mkdir -p /data/hadoop/{namenode,datanode,journalnode}
[root@node01 flink]# vim /data/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/datanode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>nnha</value>
</property>
<property>
<name>dfs.ha.namenodes.nnha</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nnha.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nnha.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nnha.nn3</name>
<value>node03:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.nnha.nn1</name>
<value>node01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.nnha.nn2</name>
<value>node02:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.nnha.nn3</name>
<value>node03:9870</value>
</property>
<!-- JournalNodes的URI设置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/nnha</value>
</property>
<!-- HDFS客户端使用该Java类连接到active NameNode -->
<property>
<name>dfs.client.failover.proxy.provider.nnha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 为了防止原来的active NameNode继续提供服务,ssh过去kill它的进程 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/clu_flink/.ssh/id_rsa</value>
</property>
<!-- journalnode本地目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/journalnode</value>
</property>
<!-- 安全模式下,standby NameNode也可以变为active -->
<property>
<name>dfs.ha.nn.not-become-active-in-safemode</name>
<value>false</value>
</property>
</configuration>
修改/data/hadoop/etc/hadoop/mapred-site.xml
[root@node01 flink]# vim /data/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改/data/hadoop/etc/hadoop/yarn-site.xml
新建nm-local-dir,nm-log-dir,nm-remote-app-log-dir目录
[root@node01 flink]# mkdir -p /data/hadoop/{nm-local-dir,nm-log-dir,nm-remote-app-log-dir}
[root@node01 flink]# vim /data/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.acl.enable</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/nm-local-dir</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/nm-log-dir</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/hadoop/nm-remote-app-log-dir</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmha</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>node03:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
</configuration>
修改/data/hadoop/etc/hadoop/workers文件
[root@node01 hadoop]# vim /data/hadoop/etc/hadoop/workers
node01
node02
node03
[root@node01 hadoop]# scp -r /data/hadoop node02:/data
[root@node01 hadoop]# scp -r /data/hadoop node03:/data
[root@node01 hadoop]# vim /etc/profile
#hadoop
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@node01 hadoop]# source /etc/profile
[root@node01 hadoop]# chmod -R 777 /data/hadoop/pids/ /data/hadoop/logs
启动journalnode
[root@node01 hadoop]# /data/hadoop/bin/hdfs --daemon start journalnode
3、hadoop初始化
[root@node02 hadoop]# chmod -R 777 /data/hadoop/pids/ /data/hadoop/logs
启动journalnode
[root@node02 hadoop]# /data/hadoop/bin/hdfs --daemon start journalnode
[root@node03 hadoop]# chmod -R 777 /data/hadoop/pids/ /data/hadoop/logs
启动journalnode
[root@node03 hadoop]# /data/hadoop/bin/hdfs --daemon start journalnode
[root@node01 hadoop]# vim /etc/init.d/hadoop
#!/bin/bash
ZK_BIN_START='/data/hadoop/sbin/start-all.sh'
ZK_BIN_STOP='/data/hadoop/sbin/stop-all.sh'
case $1 in
start)
echo "---------- hadoop 启 动 ------------"
sudo -H -u clu_flink bash -c "${ZK_BIN_START}"
;;
stop)
echo "---------- hadoop 停 止 ------------"
sudo -H -u clu_flink bash -c "${ZK_BIN_STOP}"
;;
restart)
echo "---------- hadoop 重 启 ------------"
$0 stop
$0 start
;;
status)
echo "---------- hadoop 状 态 ------------"
jps
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
[root@node01 hadoop]# chmod +x /etc/init.d/hadoop
[root@node01 hadoop]# /etc/init.d/hadoop start 特别注意先启动再hdfs初始化
hdfs初始化
[root@node01 hadoop]# hdfs namenode -format
启动node01上的NameNode
[root@node01 hadoop]# hdfs --daemon start namenode
启动node02和node03上的NameNode, 并同步active NameNode的数据(只在node02和node03上执行)
[root@node02 ~]# /data/hadoop/bin/hdfs namenode -bootstrapStandby
[root@node03 ~]# /data/hadoop/bin/hdfs namenode -bootstrapStandby
[root@node01 hadoop]# /etc/init.d/hadoop stop 先关闭hadoop集群
初始化zookeeper中NameNode的数据
[root@node01 hadoop]# hdfs zkfc -formatZK
[root@node01 hadoop]# /etc/init.d/hadoop start
[root@node01 hadoop]# scp /etc/init.d/hadoop node02:/etc/init.d/hadoop
[root@node01 hadoop]# scp /etc/init.d/hadoop node03:/etc/init.d/hadoop
4、检查hadoop集群
通过http://node01:9870、http://node02:9870、http://node03:9870进行访问,只有node02上的NameNode是active状态
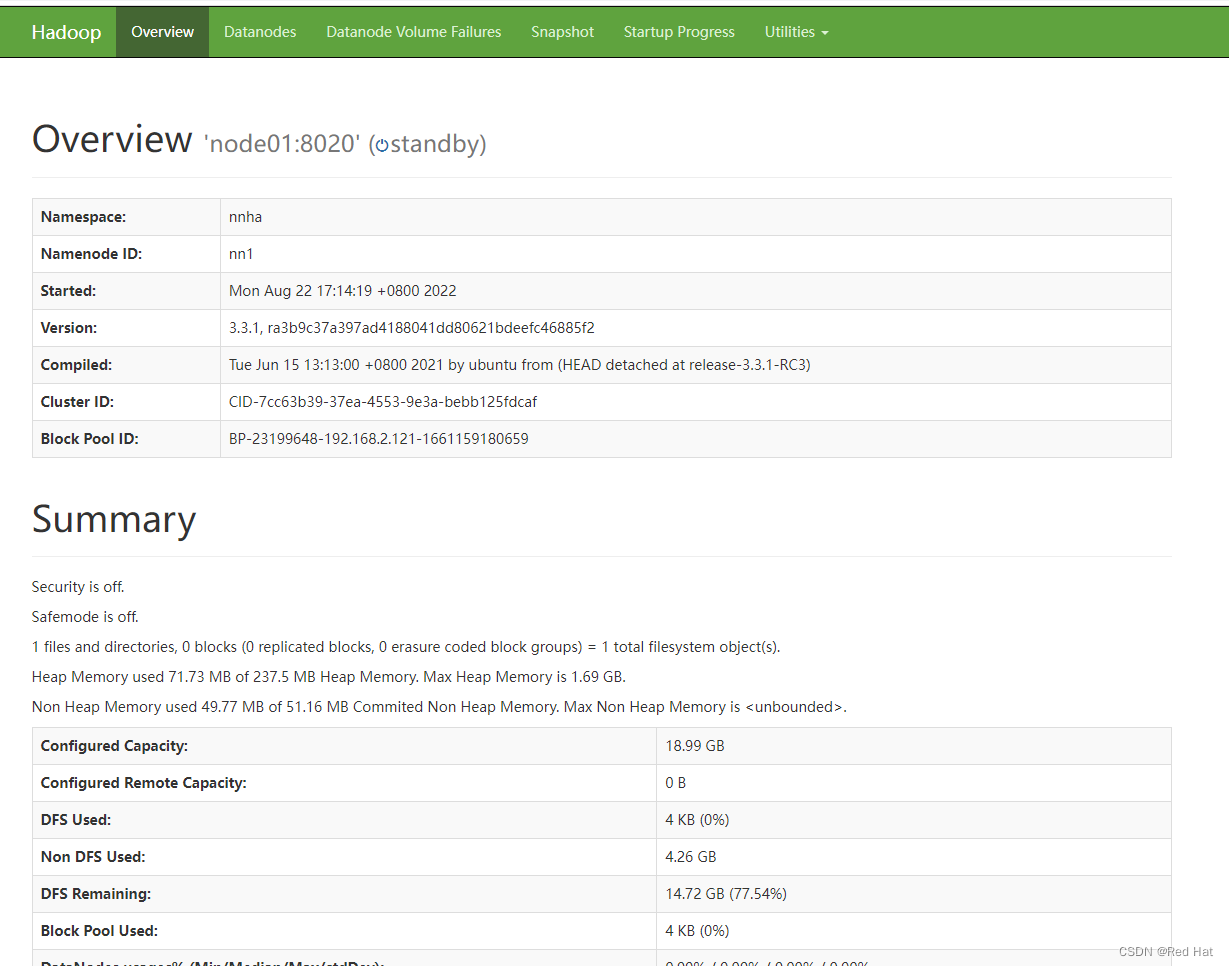
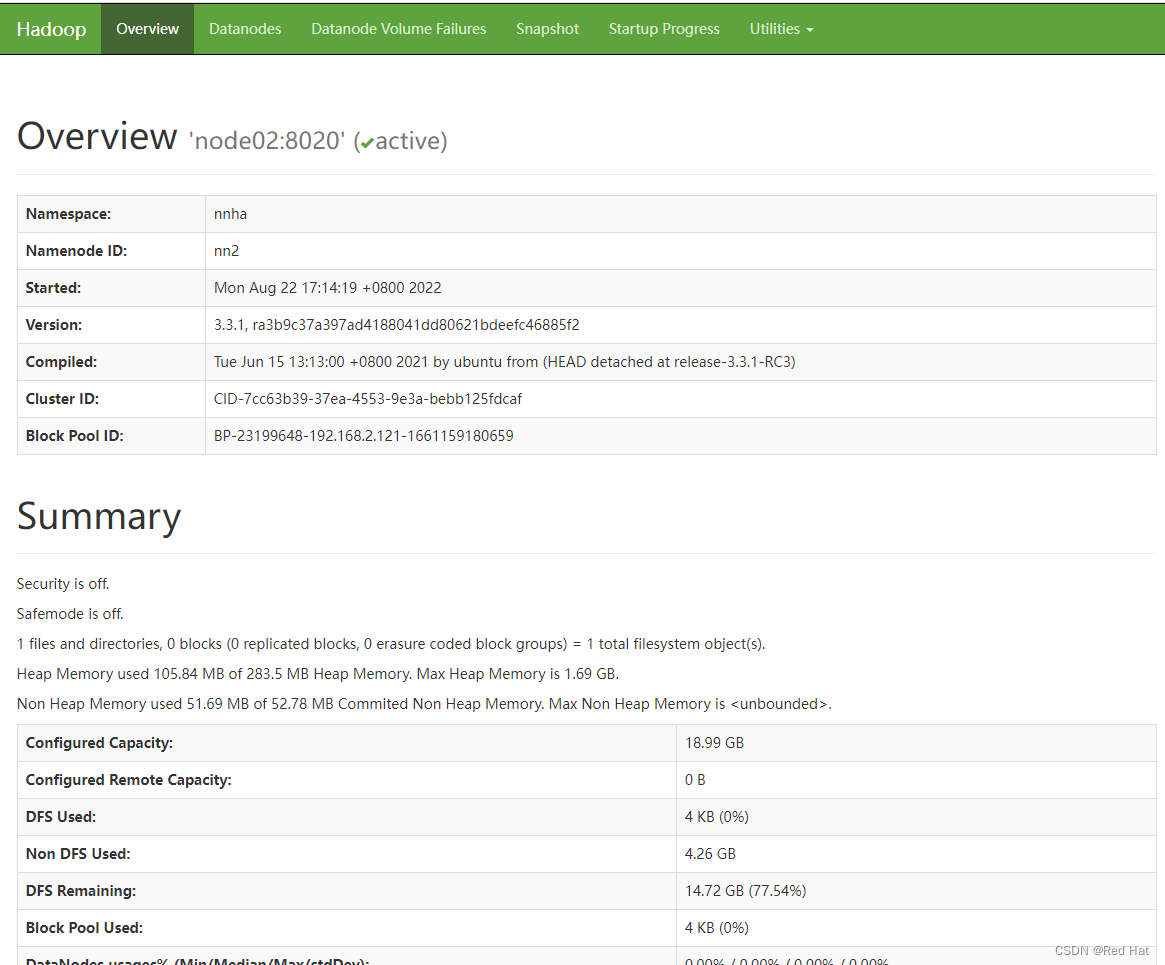

通过http://node02:8088/进行访问(只能访问active节点)