一、环境准备
- Centos7, 1 CPU , 2G Memory ,20G Disk , Virtual System
- Hosts : node110, node111 , node112
- 全部配置JDK
- 配置 Zookeeper集群
1.1、Linux环境准备
- 克隆node110 到node111, node112
-
修改机器名和IP配置
(有需要可以参考我这篇博客:
Hadoop集群部署模式、配置固定IP
)
1.2、Zookeeper配置
-
修改zoo.cfg 配置文件
(在zookeeper安装的conf目录下)
node110:(node111、node112一样都要改)
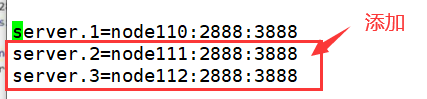
-
修改myid 配置文件
(进入我们建的/opt/apache-zookeeper-3.5.9-bin/zookeeper_data下)
node110结点的值:
1
node111结点的值:
2
node112结点的值:
3
-
启动
(分别启动三个结点上的zookeeper)



启动成功(三个结点上都有)
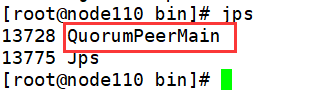
然后我们执行
./zkServer.sh status
,发现最新启动为leader其他两个为flower
(如果出现:Error contacting service. It is probably not running.可能就是你防火墙没关)



-
验证是集群
node111(
./zkCli.sh -server node110:2181
):

node112(
./zkCli.sh -server node111:2181
):

1.3、Kafka配置
-
修改server.properties 配置文件
node110:
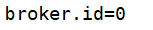

node111:
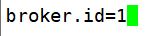
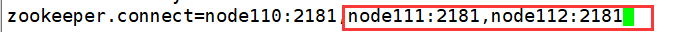
node112:
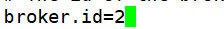
-
清空data 目录
(进入kafka安装目录下)
rm -rf kafka/*
(所有结点都要,这里就演示一个)
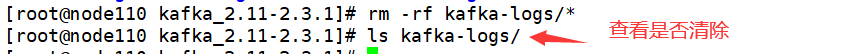
-
启动
分别启动这三个结点的kafka,然后我们可以通过zookeeper 的客户端查看:
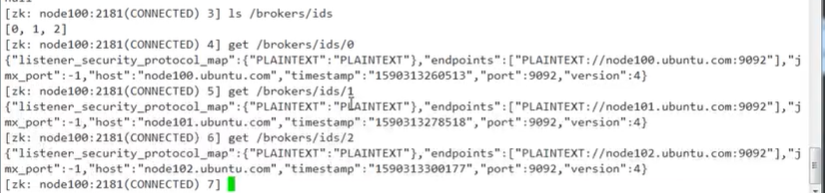
二、Kafka常用操作
2.1、Kafka Topcis
创建Topic (2 partitions & 2 replication-factor)
(2个分区、2个复制因子)
bin/kafka-topic.sh --bootstrap-server node110:9092 --partitions integer --replication-factor integer --topic topic-name

(2 partitions & 3 replication-factor)

(3 partitions & 3 replication-factor)

2.2、Kafka Producer && Consumer
1、Producer生产Topic
./kafka-console-producer.sh --broker-list node100:9092,node101:9092,node102:9092 --topic test_02_02

2、Consumer读取Topic
./kafka-console-consumer.sh --bootstrap-server node100:9092 --topic test_02_02 --partition 0 --from-beginning
./kafka-console-consumer.sh --bootstrap-server node100:9092 --topic test_02_02 --partition 1 --from-beginning

./kafka-console-consumer.sh --bootstrap-server node100:9092 --topic test_02_02 --from-beginning
