1 引言
今天学长说要像饿狼一样啃这份代码,虽然有点困难,但是对未来会一直有帮助
2 函数解析
def sparse_softmax_cross_entropy_with_logits(
_sentinel=None, # pylint: disable=invalid-name
labels=None,
logits=None,
name=None):
传入的logits为神经网络输出层的输出,shape为[batch_size,num_classes],传入的label为一个一维的vector,长度等于batch_size,每一个值的取值区间必须是[0,num_classes),其实每一个值就是代表了batch中对应样本的类别
【TensorFlow】关于tf.nn.sparse_softmax_cross_entropy_with_logits()
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=D_x,labels=tf.ones_like(D_x)
在我们这里呢我们的
logits=D_x
也就是输入真实图片是discriminator输出的评分,由于我们的batch_size是1,所以是一个[1,1]的张量。
labels=tf.ones_like(D_x)
给定一个张量 (
D_x)
),这个操作返回一个与
D_x
类型和形状相同的张量,所有元素都设置为 1,所以label也是一个[1,1]的张量,我们来算他们的交叉熵
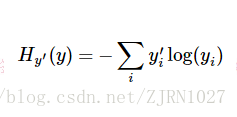
其中yi’为label中的第i个值,yi为经softmax归一化输出的vector中的对应分量,由此可以看出,当分类越准确时,yi所对应的分量就会越接近于1,从而Hyi’(y)的值也就会越小。
def reduce_mean(input_tensor,
axis=None,
keepdims=None,
name=None,
reduction_indices=None,
keep_dims=None):
这一步就是对交叉熵取平均
3 开始
首先判断是否使用
use_vanilla_GAN
,如果用使用
use_vanilla_GAN
那么就最小JS divergence,否则最小化
χ
2
\chi^2
χ
2
divergence
D_loss_real = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=D_x,
labels=tf.ones_like(D_x)))
D_loss_gen = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=D_Gz,
labels=tf.zeros_like(D_Gz)))
self.D_loss = D_loss_real + D_loss_gen
# G_loss = max log D(G(z))
self.G_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=D_Gz,
labels=tf.ones_like(D_Gz)))
第一种情况(使用
use_vanilla_GAN
)
D_loss_real:是先对D_x和labels=1归一化再取交叉熵最后对交叉熵取平均值
D_loss_gen:是对D_Gz和labels=0进行同样的操作
D_loss:为这两个loss的和
G_loss:是对D_Gz和labels=1归一化再取交叉熵最后对交叉熵取平均值
# Minimize $\chi^2$ divergence
self.D_loss = tf.reduce_mean(tf.square(D_x - 1.)) + tf.reduce_mean(tf.square(D_Gz))
self.G_loss = tf.reduce_mean(tf.square(D_Gz - 1.))
if config.multiscale:
self.D_loss += tf.reduce_mean(tf.square(D_x2 - 1.)) + tf.reduce_mean(tf.square(D_x4 - 1.))
self.D_loss += tf.reduce_mean(tf.square(D_Gz2)) + tf.reduce_mean(tf.square(D_Gz4))
第二种情况(不使用
use_vanilla_GAN
)
self.D_loss:(D_x – 1) ^2的平均值加上(D_Gz – 1)^2的平均值
self.G_loss:(D_Gz – 1)^2的平均值
判断是否使用多尺度(本项目是有的),如果使用了。还要加上前几层的D_x2, D_x4,D_Gz2, D_Gz4的信息,进行多尺度评价
distortion_penalty = config.lambda_X * tf.losses.mean_squared_error(self.example, self.reconstruction)
self.G_loss += distortion_penalty
定义了一个失真惩罚取得是样本和重建图像的均方误差然后在乘以一个参数lambda_X,在config文件中查看lambda_X 的值设置为12,G_loss再加上这个失真惩罚