训练误差:指模型在训练数据集上的误差
泛化误差:指模型在任意一个测试数据样本表现出的误差的期望
欠拟合:无法的到较小训练误差
过拟合:训练误差远小于测试数据得到的误差
影响因数:模型复杂度与训练数据的大小
交叉熵损失函数


ndarray.concat函数
x = [[1,1],[2,2]]
y = [[3,3],[4,4],[5,5]]
z = [[6,6], [7,7],[8,8]]
concat(x,y,z,dim=0) = [[ 1., 1.],
[ 2., 2.],
[ 3., 3.],
[ 4., 4.],
[ 5., 5.],
[ 6., 6.],
[ 7., 7.],
[ 8., 8.]]
Note that you cannot concat x,y,z along dimension 1 since dimension
0 is not the same for all the input arrays.
concat(y,z,dim=1) = [[ 3., 3., 6., 6.],
[ 4., 4., 7., 7.],
[ 5., 5., 8., 8.]]
激活函数
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素操作的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)
1.ReLU函数
ReLU(x)=max(x,0)(保留正数)
2.Sigmoid函数
他可以将元素的值变还到0-1之间
Sigmoid(x)=1/(1+exp(-x)

权重衰减:(应对过拟合的方法)
L2范数正则化就是在原来损失函数的基础上添加L2范数惩罚项(及权重参数的每个元素的平方之和与一个正常数的乘积)
丢弃法:(通常也是用来应对过拟合)
倒置丢弃法;
以一定的概率将多层感知机中的异常单元丢弃
不改变输入值的期望
深度模型有关数值稳定性的典型问题就是衰减与爆炸
填充与步幅
1 填充 指对输入矩阵高和宽的两侧填充元素(通常是0元素)
2 步幅 指卷积窗口每次滑动的行数和列数
池化层
目的:缓解卷积层对位置的过度敏感性(方便后面的模式识别)
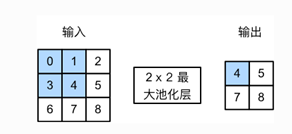
对输入采取2 * 2的池化窗口
并采取最大池化层 即:
输出为:
Max(0,1,3,4)=4
Max(1,2,4,5)=5
…
若采取平均池化层 即:
输出为:
Avg(0,1,3,4)=2
AVg(1,2,4,5)=3
…
池化层的填充与步幅与卷积层一样
对于处理多通道输入数据的时候,池化层与卷积层不一样,
池化层对每个输入通道分别池化,而不是像卷积层那样将各个通道的输入按通道进行相加。
卷积神经网络(LeNet)
它分为两个部分 a.卷积层块 b全连接层块
A. 卷积层块:卷积层用来识别图像里的空间模式,例如线条和物体局部,之后的最大池化层则用来降低卷积层对位置的敏感性。卷积层 5*5窗口对输出使用sigmoid激活函数
B. 全连接层块:全连接层的输入形状将变成二维,其中第一维为小批量中的样本,第二维为每个样本变平后的向量表示,且向量长度为通道、高和宽的乘积。全连接层块含三个全连接层。它们的输出个数分别是 120、84 和 10。其中 10 为输出的类别个数
。
***深度卷积神经网络(AlexNet)
8层卷积神经网络 包含5层卷积和2层全连接隐含层以及一个全连接输出层。
A:第一层:卷积窗口为11
11。
第二层:5
5
之后:3*3
此外,第一、第二和第五个卷积层之后都使用了窗口形状为 3×33×3、步幅为 2 的最大池化层
卷积通道数数十倍大于LeNet中的卷积通道数
紧接着最后一个卷积层的是两个输出个数为 4096 的全连接层。这两个巨大的全连接层带来将近 1GB 的模型参数
B:sigmoid 激活函数改成了更加简单的 ReLU 激活函数
C:使用丢弃法控制全连接层的模型复杂度
D:引入了大量的图像增广
*
使用重复元素的网络VGG
思想:可以通过重复使用简单的基础块来构建深度模型的思路。
VGG块的组成:连续使用多个相同的填充为1,窗口形状为3
3的卷积层后接上一个步幅为2的窗口形状为2
2的最大池化层。卷积层保持输入的高和宽不变,而池化层使得输入的高和宽减半。
***网络中的网络
思想:串联多个由卷积层和“全连接”层构成的小网络来构建一个深层网络
***含并行连结的网络(GOOGLENET)
基础卷积块(inception块)

一共有5个模块 ,每个模块有不同的块组成
***批量归一化
作用:让较深的神经网络的训练变得更加容易
a. 对全连接层做批量归一化
我们将批量归一化层置于全连接层中的仿射变换和激活函数之间
其中的平方计算是按元素求平方。接下来,我们使用按元素开方和按元素除法对 x(i)x(i) 标准化:
b. 对卷积层做批量归一化
***残差网络ResNet(何凯明提出)
残差块

ResNet 的前两层跟之前介绍的 GoogLeNet 一样:在输出通道数为 64、步幅为 2 的 7×77×7 卷积层后接步幅为 2 的 3×33×3 的最大池化层。不同之处在于 ResNet 每个卷积层后增加的批量归一化层。
GoogLeNet 在后面接了四个由 Inception 块组成的模块。ResNet 则使用四个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为 2 的最大池化层,所以无需减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并减半高和宽。
***稠密连接网络(DenseNet)
1.与残差网络的区别
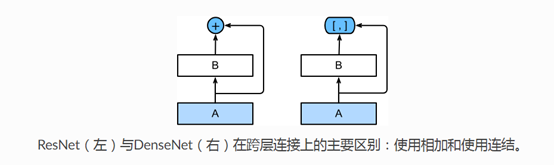
Densenet是通道维上的连接
其主要构件模块是:a.稠密块 b. 过渡层
A. 稠密块
Conv_block的定义如下:
Import gluonbook ad gb
from mxnet import gluon ,init,nd
from mxnet.gluon import nn
def conv_block(num_channels)
blk=nn.Sequential()
blk.add(nn.BatchNorm(),nn.Activation(‘relu’),
nn.Conv2D(num_channels,kernel_size=3,padding=1)
return blk
稠密块由多个conv_block块组成,每块使用相同的输出通道数,但是在进行前向计算的时候,将每块的输入输出在通道维上连结(使用nn.concat()函数连结)
B. 过渡层
用来控制模型复杂度(由于每个稠密块都会带来通道数的增加,是模型复杂)

将通道数降低为num_channels,并将输出高贺宽减半。
DenseNet模型:
- 首先是使用跟ResNet一样的单卷积层与最大池化层

2. 接着是4个稠密块

循环神经网络
循环神经网络被设计用来更好的处理时序信息
***语言模型
语言模型是自然语言处理的重要技术(可用于提升语音识别和机器翻译的性能)

N元语法 一个词的出现至于前面出现的n个词有关
***循环神经网络
他并非刚性的记忆所有固定的长度序列,而是通过隐藏状态来存储之前时间步的信息。
裁剪梯度

微调

物体检测和边界框
物体检测出了要知道图像中的物体是什么,还要知道它们的位置。
边界框就是用来描述物体的具体位置的
Dog_box=[x1,y1,x2,y2]
锚框
通过在图像中每个像素为中心生成数个大小和比例不同的边界框——锚框(anchor box)
使用contrib.ndarray中的MultiBoxPrior函数来根据坐标,大小和比例指定输入位置,然后返回数据的格式为(批量大小,锚框个数,4)
contrib.nd模块中的 MultiBoxTarget 函数来对锚框生成标号。返回第一项为真实框与锚框的偏移,返回值的第二项用来遮掩不需要的负类锚框,其形状为(批量大小,锚框数 ×4×4)。其中正类锚框对应的元素为 1,负类为 0。返回第三项为对应锚框的标号。
IoU:交集除并集
判断两个边界框的距离,通常用Jaccard距离
单发多框检测SSD
学习的第一个物体检测模型SSD
对于给定一个图像输入,首先使用卷积层来进行特征抽取,在特征输出上,以每个像素为中心构建多个锚框,然后用softmax来对每个锚框判断其包含的物体类别,以及用卷积直接预测它到真实物体边界框的距离。卷积层的输出同时被输入到一个高宽减半的模块来缩小图像尺寸。这个模块的输出将重复之前的•抽取特征,预测类别和边界框过程。这样是为了在不同尺度下进行物体检测。

首先类别预测,假设有n中不同物体类别,则对锚框进行n+1分类,0表示背景,设对输入像素为中心输入a个锚框,h,w分别为高和宽,则我们会预测hwa个锚框的分类结果。SSD为降低模型复杂度,将使用NiN中介绍的使用卷积层的通道数来输出类别预测。

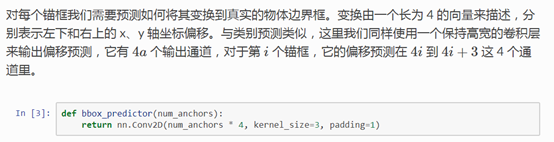
然后是边界框的预测
区域卷积神经网络(R-CNN)
首先选取多个提议区域(如锚框),然后使用卷积层对每个区域抽取特征,得到多个区域样本,在对样本进行物体分类和真实边界框预测。

