JavaSE – 对于文件操作的介绍
文章目录
一、IO原理
1. I/O是Input/Output的缩写, I/O技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文件,网络通讯等。
2. Java程序中,对于数据的输入/输出操作以 "流" 的方式进行。
3. java.io包下提供了各种 "流" 类和接口,可以获取不同种类的数据,通过 标准的方法输入或输出数据。
4. 输入input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
5. 输出output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
二、“流” 简介
流的分类
1. 按数据 操作数据单位 不同分为:字节流(8 bit) ,字符流(16 bit)
2. 按数据流的 流向 分为:输入流、输出流
3. 按流的 角色 的不同分为:节点流、处理流
| 抽象基类 | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
1. 在我们用的时候发现Java的IO流涉及到非常多的类,但是我们仔细观察会发现他们都是有规律的(都是从表格上面4个抽象基类派生的)。
2. 由这四个类派生出来的子类名称都是以其父类名作为子类名后缀。
3. 下图我们可以发现,每一列的 实现类名字 都是在最上面的 抽象基类的名字基础上 添加前缀形成的,这下就好记忆了。
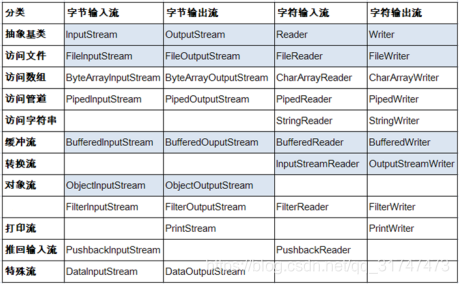
流的结构
节点流和处理流:
1. 节点流:直接从数据源或目的地读写数据
2. 处理流:不直接连接到数据源或目的地,而是 连接 在已存在的流(节点流或处理流)上,
通过对数据的处理为程序提供更为强大的读写功能。
| 抽象基类 | 节点流(文件流) | 缓冲流(处理流的一种) |
|---|---|---|
| InputStream | FileInputStream | BufferedInputStream |
| OutputStream | FileOutputStream | BufferedOutputStream |
| Reader | FileReader | BufferedReader |
| Writer | FileWriter | BufferedWriter |
三、代码实现
Java进行数据读写,都是通过字节流和字符流进行的数据传输
字符流操作文本文件的实现:
字符流简介
1. 一般用于 中文文件 处理过程中;
2. 优势:可读性高(自动的将字节转换成了字符 );
3. 劣势:中间要进行一步转换 相比较字节流 效率慢 ;
FileReader读取文件打印到控制台
文件在项目的根目录(idea中在Module根目录下)
① 利用read()空参方法进行读取
返回值就是读取的一个字符(结束时候返回-1)
public void testFileReader(){
FileReader fileReader = null;
try {
//1. 实例化File类对象, 指明要操作的文件
File file = new File("hello.txt");//项目根路径(idea中在Module根目录下)
//2. 提供具体的流
fileReader = new FileReader(file);
//3. 数据的读入
int data;//字符和整型都一样, 可以用整形来接收字符
//read()方法 返回读入的一个字符,到文件末尾的话, 返回-1
while((data = fileReader.read()) != -1){
System.out.print((char)data);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
//4.流的关闭(注意)
try {
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
② 利用read(char[] c)方法进行读取
返回值是一个整型的数据,代表读取到的数据(字符)数,返回值-1就代表文件末尾
<1> 错误的写法:
这样写的话,会导致一个后果,当读取了一次数据后,后面再读取都是进行的替换操作;
原来的char数组中已经被填满数据了,所以每次输出都会将char数组里面的所有数据输出;
如果最后一次的数据不能填满数组,输出最后一次读取的数据后,接着会再输出上一次剩余的没被替代的数据。
public void testFileReader2(){
FileReader fileReader = null;
try {
File file = new File("hello.txt");
fileReader = new FileReader(file);
char[] data = new char[6];
while(fileReader.read(data) != -1){
System.out.print(data);
}
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != fileReader)
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
-
文件中的内容:

-
输出结果:

<2> 正确的写法:
public void testFileReader2(){
FileReader fileReader = null;
try {
File file = new File("hello.txt");
fileReader = new FileReader(file);
char[] data = new char[6];
int len;
while((len = fileReader.read(data)) != -1){
System.out.print(new String(data , 0 , len));
}
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != fileReader)
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
FileWriter内存中写出到文件
说明:
1. 对应的File可以不存在,不会报异常。
2. 文件不存在会自动创建,文件存在的话:
2.1 利用FileWriter(file , false) / FileWriter(file): 覆盖原有文件
2.2 用FileWriter(file , true): 在原有文件后面追加
① 覆盖写出(覆盖文件中原有数据)
public void testFileWriter(){
FileWriter fileWriter = null;
try {
//1. 提供FIle类的对象
File file = new File("Hello4.txt");
//2. 提供FIleWriter对象,用于数据的写出
fileWriter = new FileWriter(file);//或者fileWriter = new FileWriter(file , false);
//3.写出的操作
fileWriter.write("I have a file!\n");
fileWriter.write("You need to have a file!");
} catch (Exception e) {
e.printStackTrace();
}finally {
//4.资源的关闭
try {
if(null != fileWriter)
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
② 追加写出(在原有数据后面追加)
public void testFileWriter(){
FileWriter fileWriter = null;
try {
//1. 提供FIle类的对象
File file = new File("Hello4.txt");
//2. 提供FIleWriter对象,用于数据的写出
fileWriter = new FileWriter(file, true);//这里变化
//3.写出的操作
fileWriter.write("I have a file!\n");
fileWriter.write("You need to have a file!");
} catch (Exception e) {
e.printStackTrace();
}finally {
//4.资源的关闭
try {
if(null != fileWriter)
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件的复制(前两个结合起来)
先读取文件,然后再写入另一个文件即可(和上面的基本一致):
代码如下:
public void testFileReaderFileWriter(){
//读入的File对象
File readFile = new File("hello.txt");
//写出的对象:
File writeFile = new File("hello5.txt");
//创建输入流和输出流:
FileReader fileReader = null;
FileWriter fileWriter = null;
try {
fileReader = new FileReader(readFile);
fileWriter = new FileWriter(writeFile);
//读入并写出:
char[] readData = new char[5];
int readLen;
while((readLen = fileReader.read(readData)) != -1){
fileWriter.write(readData , 0 , readLen);
}
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != fileWriter)
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != fileReader)
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
字节流操作非文本文件的实现:
字节流简介
1. 一般用于 英文文件、图片、压缩包、视频、音频 等等 适用于用字节流读写;
2. 优势:因为计算机上存储数据的时候就是字节,所以这种方式 速度快、效率高;
3. 劣势:字节的可读性比较差,对于中文数据来说容易乱码;
FileInputStream && FileOutputStream实现图片(非文本)的复制
public void testFileInputOutputStream(){
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
try {
//源文件
File oldFile = new File("hello.png");
//复制的新文件
File newFile = new File("hello2.png");
//流
fileInputStream = new FileInputStream(oldFile);
fileOutputStream = new FileOutputStream(newFile);
//复制的过程
byte[] bytes = new byte[1024];
int len;
while((len = fileInputStream.read(bytes)) != -1){
fileOutputStream.write(bytes , 0 , len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(null != fileOutputStream)
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != fileInputStream)
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
通用方法实现指定路径下文件的复制,并获取耗时
我们也可以通过获取文件后缀名来调用不同的方法来进行文件复制操作;
//方法
public void copyFile(String oldPath , String newPath){
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
try {
//源文件
File oldFile = new File(oldPath);
//复制的新文件
File newFile = new File(newPath);
//流
fileInputStream = new FileInputStream(oldFile);
fileOutputStream = new FileOutputStream(newFile);
//复制的过程
byte[] bytes = new byte[1024];
int len;
while((len = fileInputStream.read(bytes)) != -1){
fileOutputStream.write(bytes , 0 , len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(null != fileOutputStream)
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != fileInputStream)
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//调用:
public void testCopyFile(){
long start = System.currentTimeMillis();
String oldPath = "";
String newPath = "";
copyFile(oldPath , newPath);
long end = System.currentTimeMillis();
System.out.println("复制操作花费时间: " + (end - start));
}
?缓冲流来进行数据处理(效率高)
缓冲流:
BufferedInputStream
BufferedOutputStream
BufferedReader
BufferedWriter
主要作用:
提供流的读取、写入的速度
BufferedInputStream && BufferedOutputStream 实现复制操作
public void BufferedStreamTest(){
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
BufferedInputStream bufferedInputStream = null;
BufferedOutputStream bufferedOutputStream = null;
try {
//1. 文件
File oldFile = new File("hello.png");
File newFile = new File("hello3.png");
//2.流
//2.1 文件流(节点流)
fileInputStream = new FileInputStream(oldFile);
fileOutputStream = new FileOutputStream(newFile);
//2.2 缓冲流:
bufferedInputStream = new BufferedInputStream(fileInputStream);
bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
//3. 复制操作:
byte[] buffer = new byte[1024];
int len;
while((len = bufferedInputStream.read(buffer)) != -1){
bufferedOutputStream.write(buffer, 0 , len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. 关闭资源:
//先关闭外层的流,再关闭内层的流
//关闭外层流的同时, 内层流也会关闭
try {
if(null != bufferedOutputStream)
bufferedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != bufferedInputStream)
bufferedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
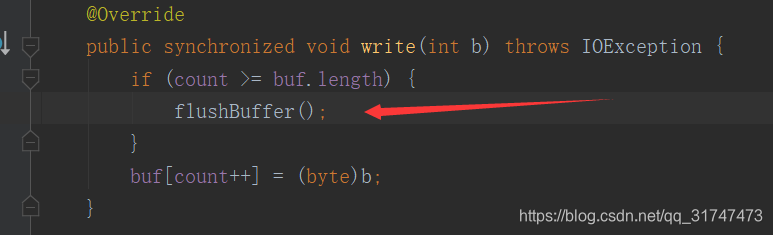
为什么缓冲流的效率高?
我们打开源码可以看到一个常量等于 8192:

移步构造方法,可以得知它默认的缓存区为8192(1024 * 8):

在读取文件中,他会把文件存到缓冲区(8192)中, 当此区域满了后,一起写出,通过此方法提高效率;
我们可以看到在BufferedOutputStream源码中,当他的缓存区满了后可以调用flush()方法,刷新缓冲区, 将数据写出:
BufferedReader && BufferedWriter 实现文本文档复制
①方式一:使用write(char[] , 0 , len)写入:
public void testBufferedWriterBufferedReader(){
BufferedWriter bufferedWriter = null;
BufferedReader bufferedReader = null;
try {
bufferedWriter = new BufferedWriter(new FileWriter("hello6.txt"));
bufferedReader = new BufferedReader(new FileReader("hello.txt"));
int len;
char[] chars = new char[1024];
while((len = bufferedReader.read(chars)) != -1){
bufferedWriter.write(chars , 0 , len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭资源:
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != bufferedWriter)
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
②使用write(String )进行写入:
public void testBufferedWriterBufferedReader(){
BufferedWriter bufferedWriter = null;
BufferedReader bufferedReader = null;
try {
bufferedWriter = new BufferedWriter(new FileWriter("hello6.txt"));
bufferedReader = new BufferedReader(new FileReader("hello.txt"));
//使用String:
String data;
while((data = bufferedReader.readLine()) != null){
// bufferedWriter.write(data);//不包含换行符
bufferedWriter.write(data);
bufferedWriter.newLine();//换行
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭资源:
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != bufferedWriter)
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
转换流(分辨也是看后缀)- 相对难
转换流(属于字符流)
InputStreamReader //字节的输入流转换为字符的输入流
OutputStreamWriter //字符的输出流转换为字节的输出流
作用
1. 可以在输入的字节流转换成输入的字符流,再将输出的字符流转换成输出的字节流
2. 解码:字节、字节数组 ----> 字符数组、字符集
3. 编码:字符数组、字符串 ---> 字节、 字节数组
InputStreamReader实现字节的输入流到字符的输入流的转换
public void test01() throws IOException {
FileInputStream fileInputStream = new FileInputStream("hello.txt");
//参数2:指明了字符集, 根据文件当初存的时候决定的
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream , "UTF-8");//不写的话就是默认的
char[] chars = new char[1024];
int len;
while((len = inputStreamReader.read(chars)) != -1){
System.out.println(new String(chars , 0 , len));
}
inputStreamReader.close();
}
InputStreamReader 和 OutputStreamWriter综合(将UTF-8的转为gbk的存储)
public void test02()throws IOException{
File oldFile = new File("hello.txt");
File newFile = new File("hello7.txt");
FileInputStream fileInputStream = new FileInputStream(oldFile);
FileOutputStream fileOutputStream = new FileOutputStream(newFile);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream , "UTF-8");
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream , "gbk");
char[] chars = new char[1024];
int len;
while((len = inputStreamReader.read(chars)) != -1){
outputStreamWriter.write(chars , 0 , len);
}
inputStreamReader.close();
outputStreamWriter.close();
}
一些字符集的介绍
ASCII: 美国信息交换标准代码,用一个字节的7位表示;
ISO8859-1:拉丁码表,欧洲码表,用一个字节的8位表示;
GB2312:中国的中文编码表,最多两个字节编码所有字符;
GBK:中国的中文编码表升级,融合了更多中文文字符号。最多两个字节编码;
Unicode:国际标准码,融合了目前人类使用的所有字符集。为每个字符分配唯一的字符码,所有的文字都用两个字节表示;
UTF-8:变长的编码方式,可用1-4个字节表示一个字符;
Unicode不完美,这里就有三个问题:
1. 我们已经知道,英文字母只用一个字节表示就够了;
2. 如何才能区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢?
3. 如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符。
所以Unicode在很长一段时间内无法推广,直到互联网的出现。
面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据;
而UTF-16就是每次16个位。这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。
推荐的Unicode编码是UTF-8和UTF-16。
总结
1. 对于文本文件 使用字符流处理(显示在控制台上)(.txt,.java,.c,.c++……)
2. 对于图片、视频等非文本文件 使用字节流处理(.avi,.mp4,.doc,.ppt……)
3. 如果不讲数据显示在控制台,只保存在本地,用 字节流 或 字符流 都可以;
4. 缓冲流可以提高效率:原因使内部提供了一个缓冲区;
5. write()方法默认是覆盖原来的数据,write(file , true)才是追加方式
6. BufferedWrite.write(String)写入一行数据的话,不要忘记换行(BufferedReader.readLine()读取的数据不包含换行符);