(1)自注意力集中机制
我想学的是注意力机制但是好像一开始跑歪了,学了自注意力机制。该说不说,讲的挺不错的。
台大李宏毅自注意力机制
input:vector set


muti-head:可能会有不同的联系

在图片中的应用:

将一个像素上的rgb看作一个vector
模型上的应用包括:①self-attention GAN
②DETR
CNN和Self-attention的对比:
CNN只考虑receptive field,Self-attention考虑全局。因此可以将cnn看作是小范围的(简化版)Self-attention

②
小
资料量时CNN占优,
大
量时Self-attention会超过CNN
对于理由李宏毅的说法是:
Self-attention弹性大,CNN弹性小
RNN&SA
①SA平行化,RNN不可以平行话
②数据记忆量
(2)注意力机制
接下来就是正儿八经的注意力机制(Attention)
先上资料先上资料
pytorch应用的:
先上资料
其实csdn上是有网课的但是贫困小孩最近真是没钱花,但是我们还是可以参照他的架构进行学习

1.了解注意力机制
根据注意力作用的不同维度将注意力分成了四种
基本
类型:
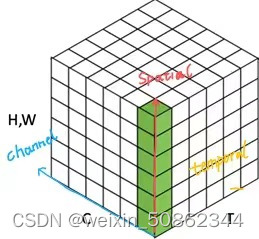
通道注意力、空间注意力、时间注意力和分支注意力
,以及两种
组合
注意力:
通道-空间注意力和空间-时间注意力
。

spatial:空间
temporal:时间
画出三维坐标轴大概就长下面这样:
2.正儿八经进入注意力模块
遇到问题先看看
b导的课
本小白遇到的不会的函数,例子更好理解一点
1)cat:拼接

2)view:改变cols和rows的排布

3)torch.mean通道平均值&torch.max通道最大值
torch.nn.AdaptiveAvgPool2d(
output_size
):提供2维的自适应平均池化操作 对于任何输入大小的输入,可以将输出尺寸指定为H*W
对比于全局平均池化可以理解成切片方式不一样!!!
注意力机制是一个
即插即用
的模块,理论上可以放在任何一个特征层后面。
由于放置在
主干会导致网络的预训练权重无法使用
,将注意力机制应用
加强特征提取网络
上
(3)实战部分
但是我写一半就发现有人已经写好了,这边可以参考一下:
yolov5添加注意力集中机制
实际使用时出现什么问题我再补充吧!!感觉b导已经讲的很好了
1.如果是添加一个独立的注意力机制层,可能会影响后面层数(从backbone接受的特征图的层的层数就变了)
2.一般不添加到主干提取网络避免影响预训练权重