Nacos 原理
一、Nacos的整体架构
Nacos的整体架构还是比较清晰的,我们可以从下面这个官方提供的架构图进行简单分析。
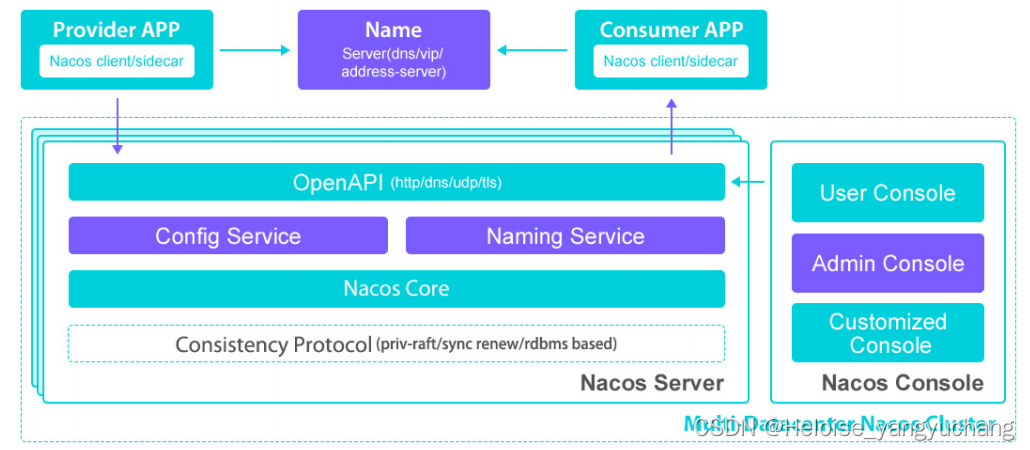
二、Nacos 原理
之前讲过注册中和配置中心的核心原理,信息的同步主要的几种方式:
- push (服务端主动push)
- pull (客户端的轮询), 超时时间比较短
- long pull (超时时间比较长)
2.1、配置中心原理
nacos 配置中心就是采用:客户端 long pull 的方式
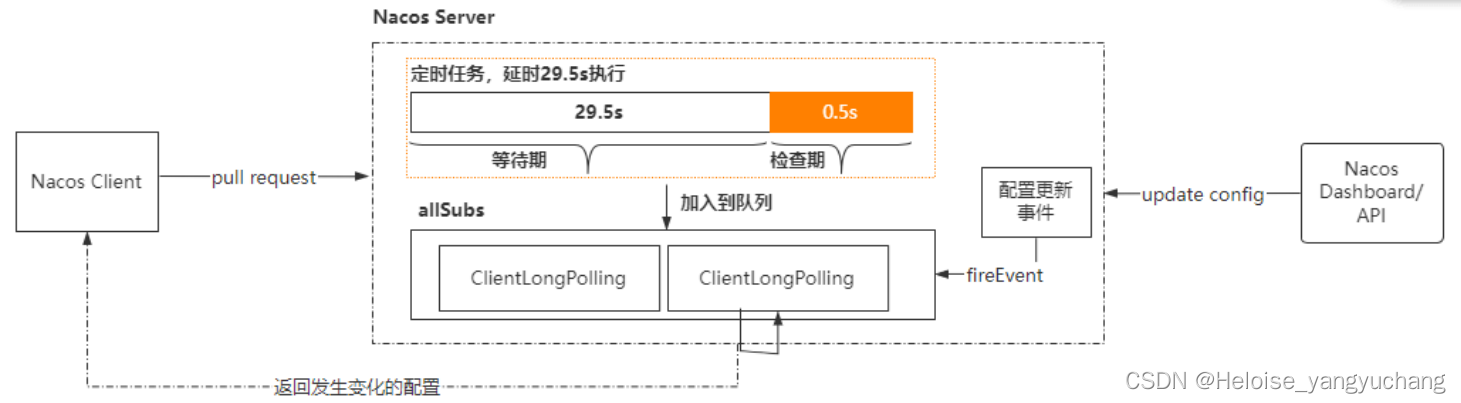
- Nacos 客户端会循环请求服务端变更的数据,并且超时时间设置为30s,当配置发生变化时,请求的响应会立即返回,否则会一直等到 29.5s+ 之后再返回响应
- 客户端的请求到达服务端后,服务端将该请求加入到一个叫 allSubs 的队列中,等待配置发生变更时 DataChangeTask主动去触发,并将变更后的数据写入响应对象。
- 与此同时服务端也将该请求封装成一个调度任务去执行,等待调度的期间就是等DataChangeTask 主动触发的,如果延迟时间到了 DataChangeTask 还未触发的话,则调度任务开始执行数据变更的检查,然后将检查的结果写入响应对象(基于文件的MD5)
2.2、注册中心原理
nacos注册中心采用了 :pull (客户端的轮询)和push (服务端主动push)
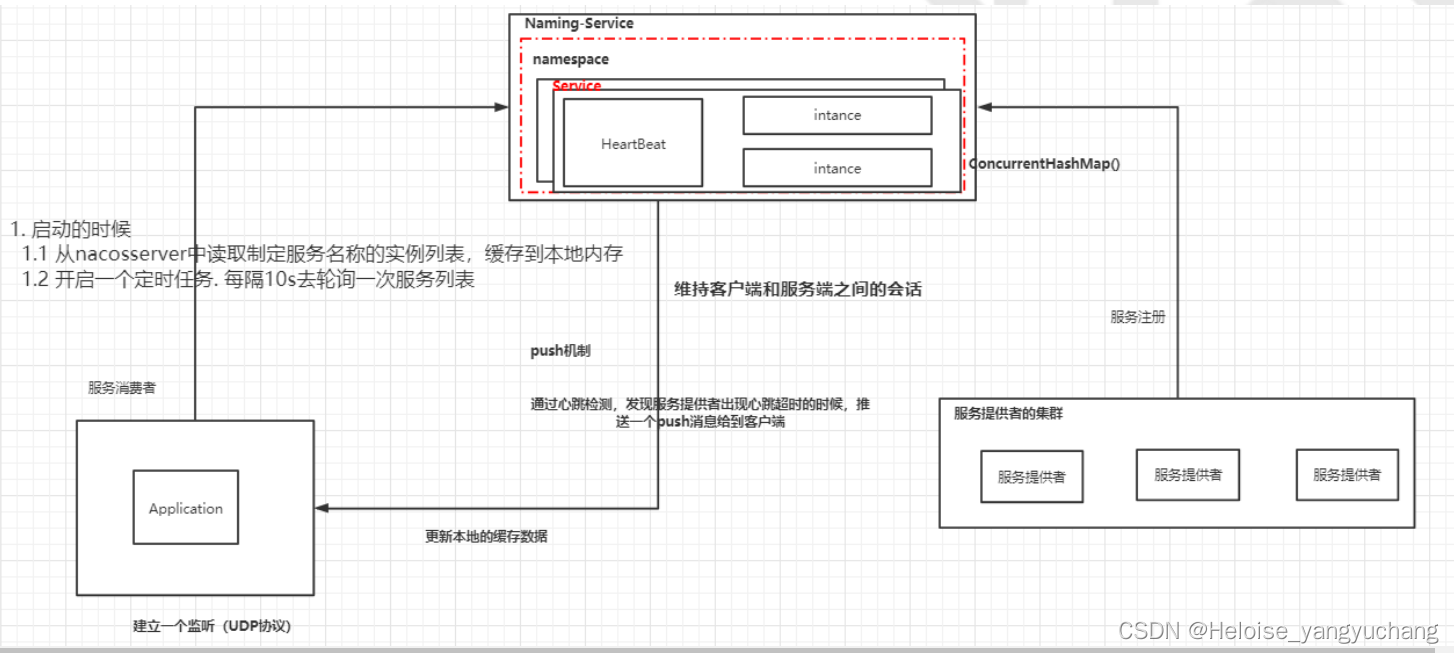
- 客户端启动时会将当前服务的信息包含ip、端口号、服务名、集群名等信息封装为一个Instance对象,然后创建一个定时任务,每隔一段时间向Nacos服务器发送PUT请求并携带相关信息。
- nacos服务器端在接收到心跳请求后,会去检查当前服务列表中有没有该实例,如果没有的话将当前服务实例重新注册,注册完成后立即开启一个异步任务,更新客户端实例的最后心跳时间,如果当前实例是非健康状态则将其改为健康状态。
- 心跳定时任务创建完成后,通过POST请求将当前服务实例信息注册进nacos服务器。
-
nacos服务器端在接收到注册实例请求后,会将请求携带的数据封装为一个Instance对象,然后为这个服务实例创建一个服务Service,一个Service下可能有多个服务实例,服务在Nacos保存到一个ConcurrentHashMap中
Map(namespace,Map(group::serviceName, Service));
。 -
nacos将实例添加到对应服务列表中会根据AP和CP不同的模式,采用不同协议。
- CP模式就是基于Raft协议(通过leader节点将实例数据更新到内存和磁盘文件中,并且通过CountDownLatch实现了一个简单的raft写入数据的逻辑,必须集群半数以上节点写入成功才会给客户端返回成功)
- AP模式基于Distro协议(向任务阻塞队列添加一个本地服务实例改变任务,去更新本地服务列表,然后在遍历集群中所有节点,分别创建数据同步任务放进阻塞队列异步进行集群数据同步,不保证集群节点数据同步完成即可返回)
-
nacos在将服务实例更新到服务注册表中时,为了防止并发读写冲突,采用的是
写时复制
的思想,将原注册表数据拷贝一份,添加完成之后再替换回真正的注册表。
- nacos在更新完成之后,通过发布服务变化事件,将服务变动通知给客户端,采用的是UDP通信,客户端接收到UDP消息后会返回一个ACK信号,如果一定时间内服务端没有收到ACK信号,还会尝试重发,当超出重发时间后就不在重发。
- 客户端通过定时任务定时从服务端拉取服务数据保存在本地缓存。
服务端在发生心跳检测、服务列表变更或者健康状态改变时会触发推送事件,在推送事件中会基于UDP通信将服务列表推送到客户端,虽然通过UDP通信不能保证消息的可靠抵达,但是由于Nacos客户端会开启定时任务,每隔一段时间更新客户端缓存的服务列表,通过定时轮询更新服务列表做兜底,所以不用担心数据不会更新的情况,这样既保证了实时性,又保证了数据更新的可靠性。
2.3、心跳机制
服务的健康检查分为两种模式:
- 客户端上报模式:客户端通过心跳上报的方式告知nacos 注册中心健康状态(默认心跳间隔5s,nacos将超过超过15s未收到心跳的实例设置为不健康,超过30s将实例删除)
- 服务端主动检测:nacos主动检查客户端的健康状态(默认时间间隔20s,健康检查失败后会设置为不健康,不会立即删除)
nacos 目前的instance有一个ephemeral字段属性,该字段表示实例是否是临时实例还是持久化实例。如果是临时实例则不会在nacos中持久化,需要通过心跳上报,如果一段时间没有上报心跳,则会被nacos服务端删除。删除后如果又重新开始上报,则会重新实例注册。而持久化实例会被nacos服务端持久化,此时即使注册实例的进程不存在,这个实例也不会删除,只会将健康状态设置成不健康。
这里就涉及到了nacos的
AP和CP
模式 ,默认是AP,即nacos的client的节点注册时
ephemeral=true
,那么nacos集群中这个client节点就是AP,采用的是distro 协议,而
ephemeral=false
时就是CP采用的是raft协议实现。所以nacos可以很好的解决了业务常见的不同需求。
#false为永久实例,true表⽰临时实例开启,注册为临时实例,默认是true
spring.cloud.nacos.discovery.ephemeral=true
为什么nacos有两种心跳机制?
对于临时实例,健康检查失败,则直接删除。这种特性适合于需要应对流量突增的场景,服务可以弹性扩容,当流量过去后,服务停掉即可自动注销。
对于持久化实例,健康检查失败,会设置为不健康状态。它的优点就是可以实时的监控到实例的健康状态,便于后续的告警和扩容等一系列处理。
2.4、自我保护
nacos也有自我保护机制(当前健康实例数/当前服务总实例数),值为0-1之间的浮点类型。正常情况下nacos 只会健康的实例。单在高并发场景,如果只返回健康实例的话,流量洪峰到来可能直接打垮剩下的健康实例,产生雪崩效应。
保护阈值存在的意义在于当服务A健康实例数/总实例数 < 保护阈值时,Nacos会把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费者可能访问到不健康的实例,请求失败,但这样远比造成雪崩要好。牺牲了请求,保证了整个系统的可用。
简单来说不健康实例的另外一个作用:防止雪崩
如果所有的实例都是临时实例,当雪崩出现时,Nacos的阈值保护机制是不是就没有足够的(包含不健康实例)实例返回了,其实如果有部分实例是持久化实例,即便它们已经挂掉,状态为不健康,但当触发自我保护时,还是可以起到分流的作用。