2020/12/14 sunhaiqi@bonc.com.cn
HDFS的HA机制(ZKFC、QJM)
一、HA(HighAvailable)概述
(1)所谓HA,即高可用(24小时不中断服务)
(2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
(3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
(4)NameNode主要在以下两个方面影响HDFS集群
-
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
-
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
(5)HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
二、HDFS-HA工作机制
通过双namenode消除单点故障
2.1、工作要点
(1)元数据管理方式需要改变:
- 内存中各自保存一份元数据
- Edits日志只有Active状态的namenode节点可以做写操作,standby状态的节点可读
- 两个namenode都可以读取Edits日志
- 共享的edits放在一个共享存储中管理(QJM和NFS两个主流实现方法)、
(2)ZKFC: ZooKeeperFailoverController ,是Hadoop中通过ZK实现FC功能的一个实用工具,作为一个ZK集群的客户端,用来监控NN的状态信息,在每个NN节点运行 ,功能如下:
- Health monitoring :zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点。
- ZooKeeper Session Management :当本地NN是健康的时候,zkfc将会在zk中持有一个session。如果本地NN又正好是active的,那么zkfc还有持有一个”ephemeral”的节点作为锁,一旦本地NN失效了,那么这个节点将会被自动删除。
- ZooKeeper-based election :如果本地NN是健康的,并且zkfc发现没有其他的NN持有那个独占锁。那么他将试图去获取该锁,一旦成功,那么它就需要执行Failover,然后成为active的NN节点。Failover的过程是:第一步,对之前的NN执行fence,如果需要的话。第二步,将本地NN转换到active状态。
(3)必须保证两个NameNode之间能够ssh无密码登录。
(4)隔离(Fence),即同一时刻仅有一个namenode对外提供服务
2.2、工作机制
(1)自动故障转移为HDFS部署增加了两个新组件:Zookeeper和ZKFailoverController(ZKFC)进程。zookeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转转移依赖于Zookeeper的以下功能:
- 故障检测:集群中的每个NameNode在Zookeeper中维持了一个持久会话,如果机器崩溃,Zookeeper中的会话将会终止,zookeeper通知另一个Name Node需要触发故障转移
- 现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从Zookeeper获得特殊的排外锁以表明它因该成为现役nameNode
(2)ZKFC是自动故障转移中的另一个新组件,是Zookeeper的客户端,也监视和管理nameNode的状态。每个运行namenode的主机也运行了一个ZKFC进程,ZKFC负责:
- 健康检测:ZKFC使用一个健康检查命令定期的PING在与之在相同主机的NameNode,只要该NameNode及时的回复健康状态,ZKFC认为该节点就是健康的,如果该节点崩溃,冻结过着进入了不健康的状态,健康检测器标识该节点是非健康的。
- Zookeeper会话管理:当本地的nameNode是健康的,ZKFC保持一个在Zookeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了Zookeeper对短暂节点的支持。如果会话终止,锁节点将自动解除
(3)基于Zookeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其他的节点当前持有znode锁,他将为自己获取该锁。如果成功则他已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前现役NameNode,然后本地nameNode转换为active状态。如果一个Active因HealthMonitor监控到状态异常,这里会作出判断,先通过Fencing功能关闭它(确保关闭或者不能提供服务),然后在ZK上删除它对应ZNode。发送上述事件后,在另外一台机器上的ZKFC中的ActiveStandbyElector 会收到事件,并重新进行选举(尝试创建特定ZNode),它将获得成功并更改NN中状态,从而实现Active节点的变更。
(4)zookeeper的基本特性:
- 可靠存储小量数据且提供强一致性
- ephemeral node(创建的锁节点), 在创建它的客户端关闭后,可以自动删除
- 对于node状态的变化,可以提供异步的通知(watcher)
(5)zookeeper在ZKFC中可以提供的功能
- Failure detector(通过watcher监听机制实现): 及时发现出故障的NN,并通知zkfc
- Active node locator: 帮助客户端定位哪个是Active的NN
- Mutual exclusion of active state(通过加锁): 保证某一时刻只有一个Active的NN
2.3、运行模块
2.3.1、ZKFailoverController(DFSZKFailoverController):
驱动整个ZKFC的运转,通过向HealthMonitor和ActiveStandbyElector注册回调函数的方式,subscribe HealthMonitor和ActiveStandbyElector的事件,并做相应的处理
2.3.2 、HealthMonitor:
定期check NN的健康状况,在NN健康状况发生变化时,通过回调函数把变化通知给ZKFailoverController
2.3.3 、ActiveStandbyElector:
管理NN在zookeeper上的状态,zookeeper上对应node的结点发生变化时,通过回调函数把变化通知给ZKFailoverController
2.3.4 、FailoverController:
提供做graceful failover的相关功能(dfs admin可以通过命令行工具手工发起failover)
2.4、系统架构
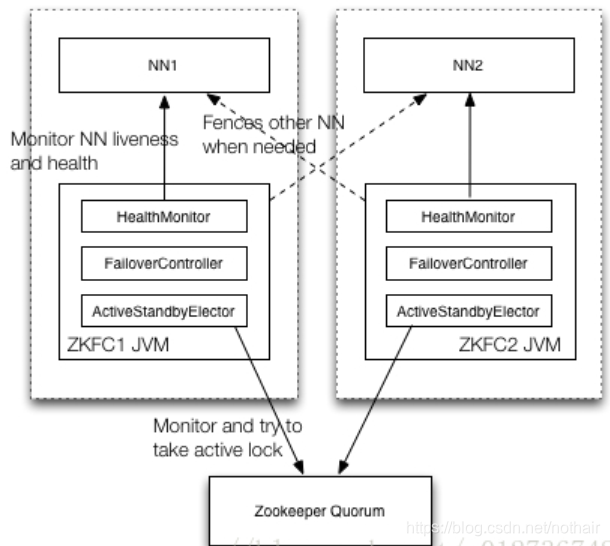
如上图所示,通常情况下Namenode和ZKFC同布署在同一台物理机器上, HealthMonitor, FailoverController, ActiveStandbyElector在同一个JVM进程中(即ZKFC), Namenode是一个单独的JVM进程。如上图所示,ZKFC在整个系统中有几个重要的作用:
- Monitor and try to take active lock: 向zookeeper抢锁,抢锁成功的zkfc,指导对应的NN成为active的NN; watch锁对应的znode,当前active NN的状态发生变化导致失锁时,及时抢锁,努力成为active NN
- Monitor NN liveness and health: 定期检查对应NN的状态, 当NN状态发生变化时,及时通过ZKFC做相应的处理
- Fences other NN when needed: 当前NN要成为active NN时,需要fence其它的NN,不能同时有多个active NN
2.5、线程模型
ZKFC的线程模型总体上来讲比较简单的,它主要包括三类线程,一是主线程;一是HealthMonitor线程; 一是zookeeper客户端的线程。它们的主要工作方式是:
(1) 主线程在启动所有的服务后就开始循环等待
(2) HealthMonitor是一个单独的线程,它定期向NN发包,检查NN的健康状况
(3) 当NN的状态发生变化时,HealthMonitor线程会回调ZKFailoverController注册进来的回调函数,通知ZKFailoverController NN的状态发生了变化
(4) ZKFailoverController收到通知后,会调用ActiveStandbyElector的API,来管理在zookeeper上的结点的状态
(5) ActiveStandbyElector会调用zookeeper客户端API监控zookeeper上结点的状态,发生变化时,回调ZKFailoverController的回调函数,通知ZKFailoverController,做出相应的变化
2.6、运行原理

在一个HA集群中,会配置两个独立的Namenode。在任意时刻,只有一个节点作为活动的节点,另一个节点则处于备份状态。活动的Namenode负责执行所有修改命名空间以及删除备份数据块的操作,而备份的Namenode则执行同步操作,以保持与活动节点命名空间的一致性。
2.6.1、命名空间(namespace)的一致性
为了使备份节点与活动节点的状态能够同步一致,两个节点都需要同一组独立运行的节点(JournalNodes,JNS)通信。当Active Namenode执行了修改命名空间的操作时,它会定期将执行的操作记录在editlog中,并写入JNS的多数节点中。而Standby Namenode会一直监听JNS上editlog的变化,如果发现editlog有改动,Standby Namenode就会读取editlog并与当前的命名空间合并。当发生了错误切换时,Standby节点会保证已经从JNS上读取了所有editlog并与命名空间合并,然后才会从Standby状态切换为Active状态。通过这种机制,保证了Active Namenode与Standby Namenode之间命名空间状态的一致性,也就是第一关系链的一致性。
2.6.2、数据块存储信息一致性
为了使错误切换能够很快的执行完毕,就要保证Standby节点也保存了实时的数据快的存储信息,也就是第二关系链。这样发生错误切换时,Standby节点就不需要等待所有的数据节点进行全量数据块汇报,而直接可以切换到Active状态。为了实现这个机制,Datanode会同时向这两个Namenode发送心跳以及块汇报信息。这样就实现了Active Namenode 和standby Namenode 的元数据就完全一致,一旦发生故障,就可以马上切换,也就是热备。
这里需要注意的是 Standby Namenode只会更新数据块的存储信息,并不会向namenode 发送复制或者删除数据块的指令,这些指令只能由Active namenode发送。
2.6.3、预防脑裂
在HA架构中有一个非常重非要的问题,就是需要保证同一时刻只有一个处于Active状态的Namenode,否则机会出现两个Namenode同时修改命名空间的问,也就是脑裂。脑裂的HDFS集群很可能造成数据块的丢失,以及向Datanode下发错误的指令等异常情况。为了预防脑裂的情况,HDFS提供了三个级别的隔离机制(fencing):
- 共享存储隔离:同一时间只允许一个Namenode向JournalNodes写入editlog数据。
- 客户端隔离:同一时间只允许一个Namenode响应客户端的请求。
- Datanode隔离:同一时间只允许一个Namenode向Datanode下发名字节点指令,李如删除、复制数据块指令等等。
三、QJM(Quorum Journal Manager)
3.1、Active NN和Standby NN之间如何共享editlog日志文件
- Active Namenode会将日志文件写到共享存储上。
- Standby Namenode会实时的从共享存储读取edetlog文件,然后合并到Standby Namenode的命名空间中。
- 一旦Active Namenode发生错误,Standby Namenode可以立即切换到Active状态。
在Hadoop2.6中,提供了QJM(Quorum Journal Manager)方案来解决HA共享存储问题。所有的HA实现方案都依赖于一个保存editlog的共享存储,这个存储必须是高可用的,并且能够被集群中所有的Namenode同时访问。Quorum Journa是一个基于paxos算法的HA设计方案。
3.2、Quorum Journal方案中有两个重要的组件
- JournalNode(JN):运行在N台独立的物理机器上,它将editlog文件保存在JournalNode的本地磁盘上,同时JournalNode还对外提供RPC接口QJournalProtocol以执行远程读写editlog文件的功能。
- QuorumJournalManager(QJM):运行在NmaeNode上,(目前HA集群只有两个Namenode),通过调用RPC接口QJournalProtocol中的方法向JournalNode发送写入、排斥、同步editlog
3.3、Quorum Journal方案基础
HDFS集群中有2N+1个JN存储editlog文件,这些editlog 文件是保存在JN的本地磁盘上的。每个JN对QJM暴露QJM接口QJournalProtocol,允许Namenode读写editlog文件。当Namenode向共享存储写入editlog文件时,它会通过QJM向集群中所有的JN发送写editlog文件请求,当有一半以上的JN返回写操作成功时,即认为写成功。这个原理是基于Paxos算法的。
3.4、使用Quorum Journal实现的HA方案优点:
-
JN进程可以运行在普通的PC上,而无需配置专业的共享存储硬件。
-
不需要单独实现fencing机制,Quorum Journal模式中内置了fencing功能。
-
Quorum Journa不存在单点故障,集群中有2N+1个Journal,可以允许有N个Journal Node死亡。
-
JN不会因为其中一个机器的延迟而影响整体的延迟,而且也不会因为JN数量的增多而影响性能(因为Namenode向JournalNode发送日志是并行的)
3.5、互斥(隔离)机制
当HA集群中发生Namenode异常切换时,需要在共享存储上fencing上一个活动的节点以保证该节点不能再向共享存储写入editlog。
基于Quorum Journal模式的HA提供了epoch number来解决互斥问题,具有以下几个性质:
- 当一个Namenode变为活动状态时,会分配给他一个epoch number。
- 每个epoch number都是唯一的,没有任意两个Namenode有相同的epoch number。
- epoch number 定义了Namenode写editlog文件的顺序。对于任意两个namenode ,拥有更大epoch number的Namenode被认为是活动节点。
当一个Namenode切换为活动状态时,它的QJM会向所有的JN发送命令,以获取该JN的最后一个promise epoch变量值。当QJM接受到了集群中多于一半的JN回复后,它会将所接收到的最大值加一,并保存到myepoch 中,之后QJM会将该值发送给所有的JN并提出更新请求。每个JN会将该值与自身的epoch值相互比较,如果新的myepoch比较大,则JN更新,并返回更新成功;如果小,则返回更新失败。如果QJM接收到超过一半的JN返回成功,则设置它的epoch number为myepoch;,否则它终止尝试为一个活动的Namenode,并抛出异常。
当活动的NameNode成功获取并更新了epoch number后,调用任何修改editlog的RPC请求都必须携带epoch number。当RPC请求到达JN后,JN会将请求者的epoch与自身保存的epoch相互对比,若请求者的epoch更大,JN就会更新自己的epoch,并执行相应的操作,如果请求者的epoch小,就会拒绝相应的请求。当集群中大多数的JN拒绝了请求时,这次操作就失败了。
当HDFS集群发生Namenode active节点切换后,原来的standby Namenode将集群的epoch number加一后更新。这样原来的Active namenode的epoch number肯定小于这个值,当原active节点执行写editlog操作时,由于JN节点不接收epoch number小于自身的promise epoch的写请求,所以这次写请求会失败,也就达到了fencing的目的。
3.6、Editlog写流程
(1)将editlog输出流中缓存的数据写入JN,对于集群中的每一个JN,对于集群中的每一个JN都存在一个独立的线程调用RPC接口中的方法向JN写入数据
(2)当JN接收到请求后执行以下操作:
- 验证epoch number是否正确
- 确认写入数据对应的txid是否连续
- 将数据持久化到JN的本地磁盘
- 向QJM发送正确的响应
(3)QJM等待集群JN的响应,如果多数JN返回成功,则写操作成功;否则写操作失败,QJM会抛出异常。
Namenode会调用FSEditlogLog下面的方法初始化editlog文件的输出流,然后使用输出流对象向editlog文件写入数据。
获取了QuorumOutputStream输出流对象之后,Namenode会调用write方法向editlog文件中写入数据,QuorumOutputStream的底层也调用了EditsDoubleBuffer双缓存区。数据回先写入其中一个缓冲区中,然后调用flush方法时,将缓冲区中的数据发送给JN。
3.7、Editlog读流程
Standby Namenode会从JN读取editlog,然后与Sdtandby Namenode的命名空间合并,以保持和Active Namenode命名空间的同步。当Sdtandby Namenode从JN读取editlog时,它会首先发送RPC请求到集群中所有的JN上。JN接收到这个请求后会将JN本地存储上保存的所有FINALIZED状态的editlog段落文件信息返回,之后QJM会为所有JN返回的editlog段落文件构造输入流对象,并将这些输入流对象合并到一个新的输入流对象中,这样Standby namenode就可以从任一个JN读取每个editlog段落了。如果其中一个JN失败了输入流对象会自动切换到另一个保存了该edirlog段落的JN上。
3.8、恢复流程
日志恢复操作可以分为以下几个阶段:
3.8.1、确定需要执行恢复操作的editlog段落:
在执行恢复操作之前,QJM会执行newEpoch()调用以产生新的epoch number,JN接收到这个请求后除了执行更新epoch number外,还会将该JN上保存的最新的editlog段落的txid返回。当集群中的大多数JN都发回了这个响应后,QJM就可以确定出集群中最新的一个正在处理editlog段落的txid,然后QJM就会对这个txid对应的editlog段落执行恢复操作了。
3.8.2、准备恢复
QJM向集群中的所有JN发送RPC请求,查询执行恢复操作的editlog段落文件在所有JN上的状态,这里的状态包括editlog文件是in-propress还是FINALIZED状态,以及editlog文件的长度。
3.8.3、接受恢复
QJM接收到JN发回的JN发回的响应后,会根据恢复算法选择执行恢复操作的源节点。然后QJM会发送RPC请求给每一个JN,这个请求会包含两部分信息:源editlog段落文件信息,以及供JN下载这个源editlog段落的url。
接收到这个RPC请求之后,JN会执行以下操作:
- 同步editlog段落文件,如果JN磁盘上的editlog段落文件与请求中的段落文件状态不同,则JN会从当前请求中的url上下载段落文件,并替换磁盘上的editlog段落文件。
- 持久化恢复元数据,JN会将执行恢复操作的editlog段落文件的状态、触发恢复操作的QJM的epoch number等信息(恢复的元数据信息)持久化到磁盘上。
- 当这些操作都执行成功后,JN会返回成功响应给QJM,如果集群中的大多数JN都返回了成功,则此次恢复操作执行成功。
3.8.4、完成editlog段落文件
到这步操作时,QJM 就能确定集群中大多数的JN保存的editlog文件的状态已经一致了,并且JN持久化了恢复信息。QJM就会向JN发送指令,将这个editlog段落文件的状态转化为FINALIZED状态,,并且JN会删除持久化的恢复元数据,因为磁盘上保存的editlog文件信息已经是正确的了,不需要保存恢复的元数据
参考资料:
https://blog.csdn.net/Baron_ND/article/details/103782481?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160793429719726891185963%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=160793429719726891185963&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2
all
first_rank_v2~rank_v29-11-103782481.pc_search_result_cache&utm_term=ZKFC&spm=1018.2118.3001.4449https://blog.csdn.net/u012736748/article/details/79534019
=0&utm_medium=distribute.pc_search_result.none-task-blog-2
all
first_rank_v2~rank_v29-11-103782481.pc_search_result_cache&utm_term=ZKFC&spm=1018.2118.3001.4449
https://blog.csdn.net/u012736748/article/details/79534019