Neo4j进行数据建模
1.本教程适合学习了neo4j基本增删改查语法后进行学习
2.如果还不熟悉语法,本人非常详细的增删改查教程连接如下
3.学习本教程之后可以学习:
Neo4j 全网最详细教程
python对neo4j的api接口框架py2neo进阶教程:
py2neo框架学习全网最详细教程
1.学习资料
网站
-
Neo4j学习官网
感谢您下载 Neo4j – Neo4j 图形数据平台
2.开始简介
2.1图形数据建模(Graph Data Modeling)
neo4j的组成部分
- 节点
- 标签
- 关系
- 性能
数据建模过程
- 1.了解领域并定义特定的用例,枚举用例
-
2.开发初始图形数据模型
- 对节点(实体)建模
- 对关系建模
- 3.对初始数据测试模型
- 4.使用cypher创建图形实例
- 5.测试性能,定义的模型是否满足需求
- 6.如果由于用例更改或者性能原因,进行重构图形数据模型
- 7.重构后使用Cypher重新测试
图形数据建模是一个迭代过程。初始图形数据模型是一个起点,但随着了解有关用例的更多信息,或者如果用例发生更改,初始图形数据模型将需要更改。
此外,您可能会发现,特别是当图形缩放时,您需要修改图形(
重构
)以实现关键用例的最佳性能。
2.2数据领域(The Domain)
在数据建模过程中我们必须
- 描述具体项目的细节
- 确定用户和系统
-
对用例达成一致看法
- 用例就是具有哪些查询功能
- 枚举用例
电影领域
在
Neo4j基础
课程中,向您介绍了一个“入门”电影图。
该域名包括电影、演戏或执导电影的用户以及为电影评分的用户。使此域有趣的是图中节点之间的连接或关系。
使用案例
知识图谱项目的大多数用例都可以通过全面的问题列表来枚举。这些用例有助于定义知识图谱在运行时的行为方式。
以下是您将用于开发初始图形数据模型的用例:
- 电影中有哪些人表演?
- 谁导演了一部电影?
- 一个人出演了什么电影?
- 有多少用户对一部电影进行了评分?
- 谁是最年轻的电影演员?
- 一个人在电影中扮演了什么角色?
- 根据imDB的数据,特定年份收视率最高的电影是什么?
- 演员出演了哪些戏剧电影?
- 哪些用户给电影打了5分?
电影、演员、导演、用户四个类型的节点。
在我们的领域中,我们希望区分出演或执导电影的人和为电影评分的用户或评论者。我们有更多关于人们的信息,例如他们的出生日期,他们的tmdbId等。对电影进行评级的用户将被命名或识别。
2.3数据模型
模型类型
为应用程序执行图形数据建模过程时,至少需要两种类型的模型:数据模型、实例模型
– 数据模型
- 含义:数据模型描述图形的标签、关系和属性。它没有将在图表中创建的特定数据。
- 重要性:图形数据模型很重要,因为它定义了在应用程序创建和使用图形时将用于标签、关系类型和属性的名称。
-
格式:
- label命名首字母大写,Example: Person, Company, …
- relationship type命名全字母大写,Example: FOLLOWS, MARRIED_TO
- property key命名小写字母开头, Example: age, firstName
-
注意属性关键字property key名字可以不唯一,因为不同类型的节点也可以有同一个属性

– 实例模型
-
图形数据建模过程的一个重要部分是针对用例测试模型。为此,您需要有一组示例数据,您可以使用这些数据来查看是否可以使用模型来测试我们的用例。

3.模型节点(Modeling Nodes)
3.1模型节点
A 定义节点标签
实体是用例中的主要名词:食谱、成分、人、电影…
食谱中使用了哪些成分?谁嫁给了这个人?
电影中有哪些人表演?谁导演了一部电影?一个人出演了什么电影?
B 节点属性
节点属性的作用
- 唯一标识节点(上文提到不同节点属性关键字可以取相同,单内容必须唯一标识节点,可以拥有很多属性,起到唯一标识节点的作用的属性一个就够了)
- 回答用例的特定详细信息(对节点的信息补充)
- 返回数据(具有查询作用,利用属性返回相应的数据)
在Cypher中的体现
-
定位点(开始查询的位置)。
-
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]-(m:Movie) RETURN m
- 查询人物类型节点且名字是Tom的,电影类型节点,关系边时acted_in的数据
-
-
遍历图形(导航)。
-
MATCH (p:Person)-[:ACTED_IN]-(m:Movie {title: 'Apollo 13'})-[:RATED]-(u:User) RETURN p,u
- 查找人物类型节点,电影类型节点且标题为apollp13,用户类型的节点,前两个关系时actedin的,后两个关系时rated的演员和用户
- 简而言之就是查找对apollo13电影的演员和评分用户
-
-
从查询返回数据。
-
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]-(m:Movie) RETURN m.title, m.released
- 查找TomHanks演过的电影的标题和发布日期
-
电影节点属性的解释

以下是我们将为
Movie
节点定义的属性:
-
- 电影标题(字符串)- 电影上映(日期)- 电影评级(0-10 之间的十进制)- 电影流派(字符串列表)
以下是我们将为
Person
节点定义的属性:
-
- Person.name(字符串)- 出生人(日期)- 逝世人(日期)
3.2建立节点代码
MATCH (n) DETACH DELETE n;
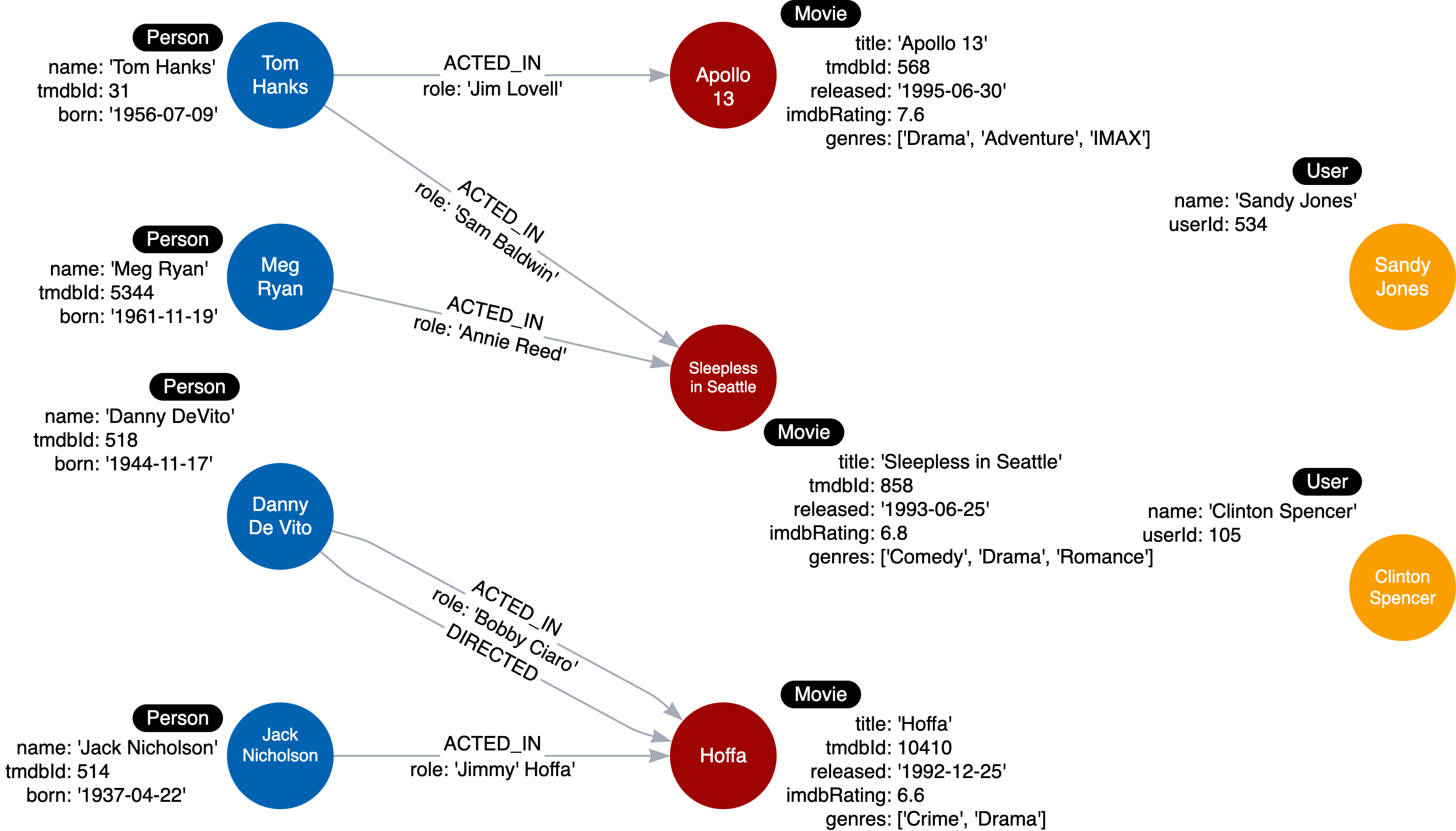
MERGE (:Movie {title: 'Apollo 13', tmdbId: 568, released: '1995-06-30', imdbRating: 7.6, genres: ['Drama', 'Adventure', 'IMAX']})
MERGE (:Person {name: 'Tom Hanks', tmdbId: 31, born: '1956-07-09'})
MERGE (:Person {name: 'Meg Ryan', tmdbId: 5344, born: '1961-11-19'})
MERGE (:Person {name: 'Danny DeVito', tmdbId: 518, born: '1944-11-17'})
MERGE (:Person {name: 'Jack Nicholson', tmdbId: 514, born: '1937-04-22'})
MERGE (:Movie {title: 'Sleepless in Seattle', tmdbId: 858, released: '1993-06-25', imdbRating: 6.8, genres: ['Comedy', 'Drama', 'Romance']})
MERGE (:Movie {title: 'Hoffa', tmdbId: 10410, released: '1992-12-25', imdbRating: 6.6, genres: ['Crime', 'Drama']})
MATCH (n) RETURN n
4.关系建模
4.1关系建模(定义关系)
A 关系定义:
关系是实体之间的连接**,连接是用例中的**谓词:
-
食谱
中使用
了哪些成分? -
谁
嫁给
了这个人?
B 关系类型命名标准:
全字母大写
C 关系方向
Neo4j 中创建关系时,必须显式指定方向(代码从左到右写)
在运行时,在查询期间,通常不需要方向。
D 节点属性的扇出
人可以有姓名属性,出生日期属性,但为了满足用例需求,可将姓、名、出生日期作为节点拿出来
例如,如果用例中存在满足某种条件的人物的姓氏是什么?

E 关系属性
可以将属性添加到关系中以进一步描述关系,如结婚关系的日期属性,工作关系的角色属性

EXAMPLE1(根据用例确定关系模型)
以下是一些用例
-
电影中有哪些人
表演
? -
谁
导演了
一部电影? -
一个人
出演
了什么电影?
那么关系就是
- ACTED_IN
- DIRECTED
所以数据模型为

支持数据模型的实例模型

EXAMPLE2(根据用例确定关系属性模型)
一个人
在
某部电影
中
扮演
了什么角色?
- 检索人员的姓名。
- 遵循与电影ACTED_IN关系。
- 按影片标题筛选影片。
-
从两个节点之间的ACTED_IN关系中返回
角色
构建数据模型

构建数据模型的实力模型
4.2创建初始关系代码
MATCH (apollo:Movie {title: 'Apollo 13'})
MATCH (tom:Person {name: 'Tom Hanks'})
MATCH (meg:Person {name: 'Meg Ryan'})
MATCH (danny:Person {name: 'Danny DeVito'})
MATCH (sleep:Movie {title: 'Sleepless in Seattle'})
MATCH (hoffa:Movie {title: 'Hoffa'})
MATCH (jack:Person {name: 'Jack Nicholson'})
// create the relationships between nodes
MERGE (tom)-[:ACTED_IN {role: 'Jim Lovell'}]->(apollo)
MERGE (tom)-[:ACTED_IN {role: 'Sam Baldwin'}]->(sleep)
MERGE (meg)-[:ACTED_IN {role: 'Annie Reed'}]->(sleep)
MERGE (danny)-[:ACTED_IN {role: 'Bobby Ciaro'}]->(hoffa)
MERGE (danny)-[:DIRECTED]->(hoffa)
MERGE (jack)-[:ACTED_IN {role: 'Jimmy Hoffa'}]->(hoffa)
4.3更新新关系
我们需要为新的用例重构模型:
用例:哪些用户给电影的评分为5?

已经确定了人物、电影、和他们的关系,也确定了用户。
关系应该是:进行评级
RATED
关系属性应该是:评分的值
rating
4.4建立更多关系代码
MATCH (sandy:User {name: 'Sandy Jones'})
MATCH (clinton:User {name: 'Clinton Spencer'})
MATCH (apollo:Movie {title: 'Apollo 13'})
MATCH (sleep:Movie {title: 'Sleepless in Seattle'})
MATCH (hoffa:Movie {title: 'Hoffa'})
MERGE (sandy)-[:RATED {rating:5}]->(apollo)