第一章:数据载入及初步观察
参加了十二月份的datawhale,数据分析班级,使用csdn记录学习过程。
1.1 载入数据
数据集下载
https://www.kaggle.com/c/titanic/overview
1.1.1 任务一:导入numpy和pandas
#写入代码
import numpy as np
import pandas as pd
import os
基础python语法
1.1.2 任务二:载入数据
(1) 使用相对路径载入数据
(2) 使用绝对路径载入数据
本人的数据集路径是
D:\learn\python\数据挖掘\hands-on-data-analysis-master\第一单元项目集合\titanic
数据集结构为:
#写入代码
data = pd.read_csv('titanic/train.csv')#相对路径
data1 = pd.read_csv('D://learn/python/数据挖掘/hands-on-data-analysis-master/第一单元项目集合/titanic/train.csv')#绝对路径
注意:路径文件夹符合不能用系统的\\符号,而是用/符合,否则会报错

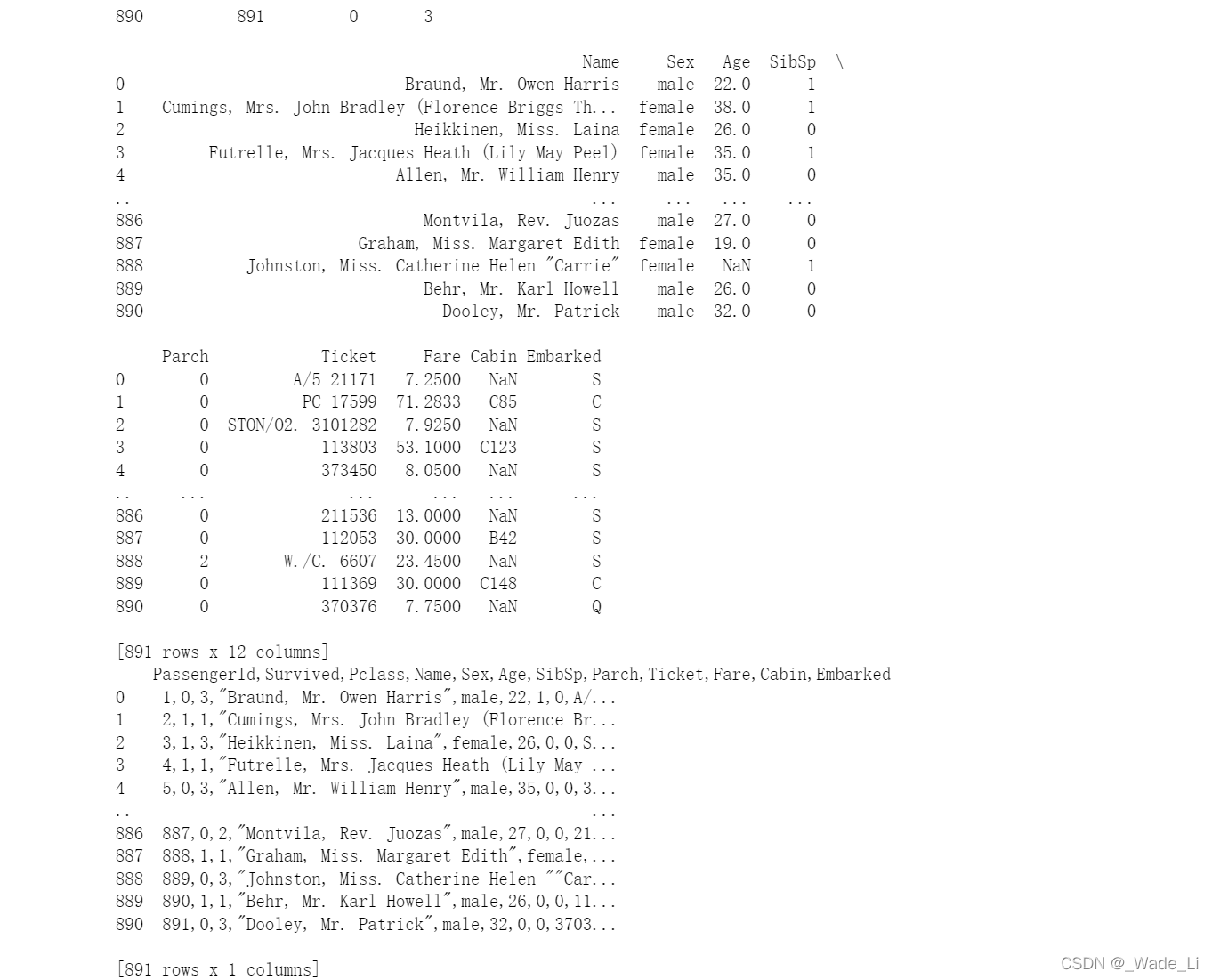
最后结果data和data1输出数据是一样的。
【提示】相对路径载入报错时,尝试使用os.getcwd()查看当前工作目录。
答:我的os.getcwd()结果是
D:\learn\python\数据挖掘\hands-on-data-analysis-master\第一单元项目集合
【思考】知道数据加载的方法后,试试pd.read_csv()和pd.read_table()的不同,如果想让他们效果一样,需要怎么做?了解一下’.tsv’和’.csv’的不同,如何加载这两个数据集?
答:尝试使用两个不同的函数,发现输出的结果主要是格式有点不一样,其实内容都一样的。
搜索了一下两个函数的区别:

原文地址:
Python常用的读取文件的方式(read_csv,read_table)
那么实际返回的都是一个dataframe,思考可以通过控制sep参数来使得两者输出结果一致。
data = pd.read_csv('titanic/train.csv')
data2 = pd.read_table('titanic/train.csv',sep=",")
可以发现把read_table的sep参数改为”,”后,两者输出的结果就一致了。
同理,把read_csv的sep参数改为”\t”,输出结果一样。
data = pd.read_csv('titanic/train.csv',sep="\t")
data2 = pd.read_table('titanic/train.csv')
以泰坦尼克号数据集为例:使用”,”隔开读取数据为891
12的一个dataframe,使用”\t”读取数据则为891
1的一个dataframe,意思是这个数据集的数据实际上是用逗号分隔。我们可以用记事本打开看看。以后的数据集可以用记事本先查看数据集分割符号,再确定如何用pandas读取。

【总结】加载的数据是所有工作的第一步,我们的工作会接触到不同的数据格式(eg:.csv;.tsv;.xlsx),但是加载的方法和思路都是一样的,在以后工作和做项目的过程中,遇到之前没有碰到的问题,要多多查资料吗,使用google,了解业务逻辑,明白输入和输出是什么。
1.1.3 任务三:每1000行为一个数据模块,逐块读取
先查相关资料,什么是逐块读取。
pandas逐块读取文件
#写入代码
chunker = pd.read_csv('titanic/train.csv',chunksize=1000)
print(type(chunker))
for data in chunker:
print(data)
print(len(data))
结果输出的data和上面的read_csv的data一样。原因是我们分割的是1000行。而实际只有891行。
假如我们变成100行一个数据模块的话,就会分9次print出来,前8次的datafram是100行12列,最后一次是91行12列
【思考】什么是逐块读取?为什么要逐块读取呢?
答:就是把数据集分为多少块,原因的话,可能是方便后面划分验证集数据集?
【提示】大家可以chunker(数据块)是什么类型?用for循环打印出来出处具体的样子是什么?
答:是一个TextFileReader类型,打印出来的结果就是:
<pandas.io.parsers.readers.TextFileReader object at 0x0000019FFAE0BE50>
就说是一个对象,储存空间在哪。
1.1.4 任务四:将表头改成中文,索引改为乘客ID [对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据]
pandas 修改列名
上面是查找的资料,有两种方法修改列名称:
第一种,暴力修改列名;
#写入代码
data = pd.read_csv('titanic/train.csv')
data.columns = ['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名',
'性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','登船港口']
print(data)
暴力修改的缺点就是,如果数据行的英文顺序与修改的中文不一样,那么很可能行的名称会弄混淆。
方法二,利用rename修改,加入inplace参数:
必须加入inplace参数,否则会修改失败。
rename的好处就是会使得英文与中文一一对应。
data.rename(columns={'PassengerId':'乘客ID','Survived':'是否幸存','Pclass':'乘客等级(1/2/3等舱位)',
'Name':'乘客姓名','Sex':'性别','Age':'年龄','SibSp':'堂兄弟/妹个数','Parch':'父母与小孩个数'
,'Ticket':'船票信息','Fare':'票价','Cabin':'客舱','Embarked':'登船港口'},inplace=True)
【思考】所谓将表头改为中文其中一个思路是:将英文列名表头替换成中文。还有其他的方法吗?
两种方法应该差不多了吧
1.2 初步观察
导入数据后,你可能要对数据的整体结构和样例进行概览,比如说,数据大小、有多少列,各列都是什么格式的,是否包含null等。
df.info(): # 打印摘要
df.describe(): # 描述性统计信息
df.values: # 数据 <ndarray>
df.to_numpy() # 数据 <ndarray> (推荐)
df.shape: # 形状 (行数, 列数)
df.columns: # 列标签 <Index>
df.columns.values: # 列标签 <ndarray>
df.index: # 行标签 <Index>
df.index.values: # 行标签 <ndarray>
df.head(n): # 前n行
df.tail(n): # 尾n行
pd.options.display.max_columns=n: # 最多显示n列
pd.options.display.max_rows=n: # 最多显示n行
df.memory_usage(): # 占用内存(字节B)
一个个去尝试,看看结果。具体结果不贴出来了。
1.2.4 任务三:判断数据是否为空,为空的地方返回True,其余地方返回False
#写入代码
pd.isnull(df)
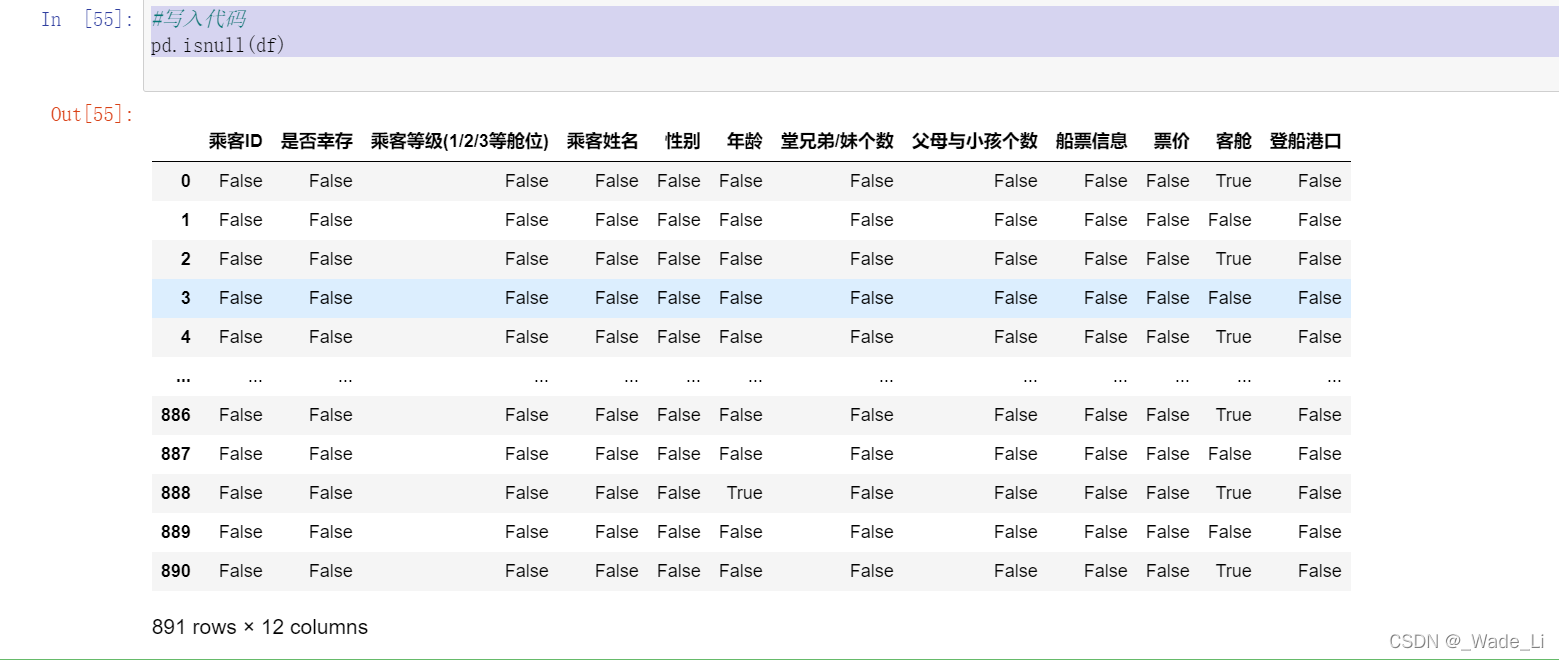
【总结】上面的操作都是数据分析中对于数据本身的观察
【思考】对于一个数据,还可以从哪些方面来观察?找找答案,这个将对下面的数据分析有很大的帮助
观察数据上面贴出来一篇博客,感觉归纳的挺全的。
1.3 保存数据
1.3.1 任务一:将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
#写入代码
# 注意:不同的操作系统保存下来可能会有乱码。大家可以加入`encoding='GBK' 或者 ’encoding = ’utf-8‘‘`
df.to_csv('/train_chinese.csv',header=1,index=1)
过程中出现了点小错误
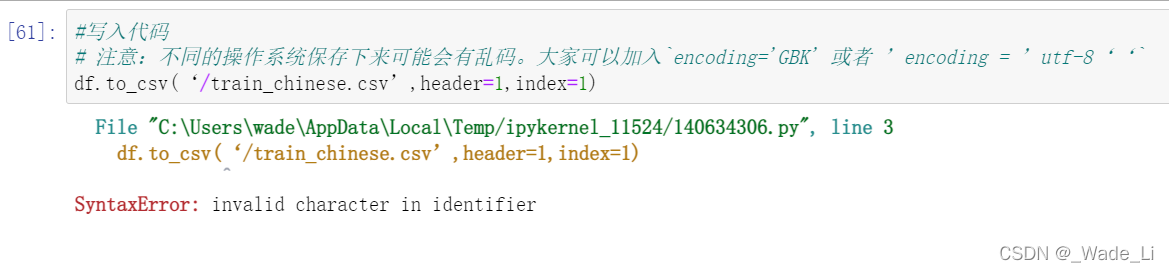
SyntaxError: invalid character in identifier
因为我直接复制别人的代码,最后发现原来他的分割符号是中文的,改成英文就ok了。
header和index为是否把列的名字和列标签写入文件,选true或者false就行(0或者1)