传统关系型数据库存储时序数据的问题
有了时序数据后,该存储在哪里呢?首先我们看下传统的关系型数据库解决方案在存储时序数据时会遇到什么问题。
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题。但时序数据往往是由百万级甚至千万级终端设备产生的,写入并发量比较高,属于海量数据场景。
MySQL在海量的时序数据场景下存在如下问题:
存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
查询性能差:适用于交易处理,海量数据的聚合分析性能差。
另外,使用Hadoop生态(Hadoop、Spark等)存储时序数据会有以下问题:
数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。
可以看到时序数据库需要解决以下几个问题:
时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
时序数据的读取:如何支持在秒级对上亿数据的分组聚合运算。
成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
****
时序数据库的优势
***时序数据库产品的发明都是为了解决传统关系型数据库在时序数据存储和分析上的不足和缺陷,这类产品被统一归类为时序数据库。***针对时序数据的特点对写入、存储、查询等流程进行了优化,这些优化与时序数据的特点息息相关:
存储成本:
利用时间递增、维度重复、指标平滑变化的特性,合理选择编码压缩算法,提高数据压缩比;
通过预降精度,对历史数据做聚合,节省存储空间。
高并发写入:
批量写入数据,降低网络开销;
数据先写入内存,再周期性的dump为不可变的文件存储。
低查询延时,高查询并发:
优化常见的查询模式,通过索引等技术降低查询延时;
通过缓存、routing等技术提高查询并发。
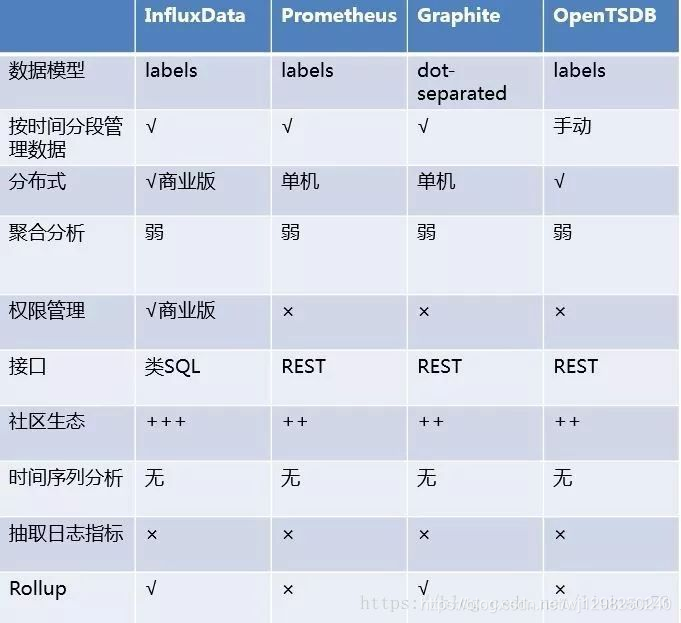
开源时序数据库对比
目前行业内比较流行的开源时序数据库产品有 InfluxDB、OpenTSDB、Prometheus、Graphite等,其产品特性对比如下图所示:
参考:https://blog.csdn.net/liukuan73/article/details/79950329