(1)处理数据集
YOLO训练需要这样的三个文件:
annotation_path = 'data.txt'
classes_path = 'model_data/fei_classes.txt'
anchors_path = 'model_data/fei_anchors.txt'
data.txt:
把数据集里自带的表格信息转化成.txt文件,需要注意的一点是因为YOLO训练的时候用到的是(x0,y0,x1,y1),而数据集里给的信息是(x0,y0,w,h)。因为有标记的数据太少,对数据集进行扩充,分别旋转90,180,270度。


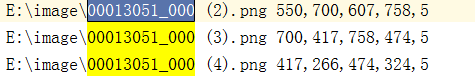
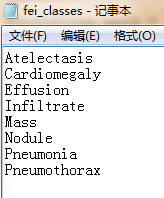
fei_classes.txt:
fei_anchors.txt:
用k-means方法,对表格中的w和h得到9个anchors。注意,因为YOLO训练的时候是把1024的图片先缩小到416×416的,所以这里的输入是先变为416×416时相对的w和h,对这样大小的高和宽进行聚类。

yolo3训练和测试参考的是这里的程序:
https://github.com/qqwweee/keras-yolo3
训练完之后保存整个模型(原程序是保存权值,这里保存模型是为了测试的时候):
model.save(log_dir + ‘trained_model.h5’)
测试的时候在yolo.py里边执行下载模型:
self.yolo_model = load_model(model_path, compile=False)
出现的问题:
保存模型,再下载模型时,自己的模型比网上直接下载的yolo.h5多了4层(input_2;input_3,input_4,yolo_loss),这样在load_model这句会出错。开始想到了两种解决办法:在保存的时候修改程序,使之保存成和yolo.h5一样的;或者在测试的时候修改,把多出来的几层删掉。
最终得到的结果(一个框框是标签,一个框框是预测的结果,可以看出效果还是不错的):





