本文讲解的是机器学习中一个算法的应用:
关联规则分析
整个故事从一张校园卡开始。相信小伙伴们都用过校园卡,它是一种其个人身份认证、校园消费、数据共享等多功能于一体的校园信息集成与管理系统。在它里面存储着大量的数据,包含:学生消费、宿舍门禁、图书馆进出等。
本文使用的是南京某高校学生一卡通在2019年4月1-20号的消费明细数据,从
统计可视化分析、关联规则分析
,发现学生一卡通的使用情况和学生当中的情侣、基友、闺蜜、渣男和单身狗等有趣信息。

使用的数据集地址如下:https://github.com/Nicole456/Analysis-of-students-consumption-behavior-on-campus
导入数据
import pandas as pd
import numpy as np
import datetime
import plotly_express as px
import plotly.graph_objects as go
1、数据1:每个学生的校园卡基本信息
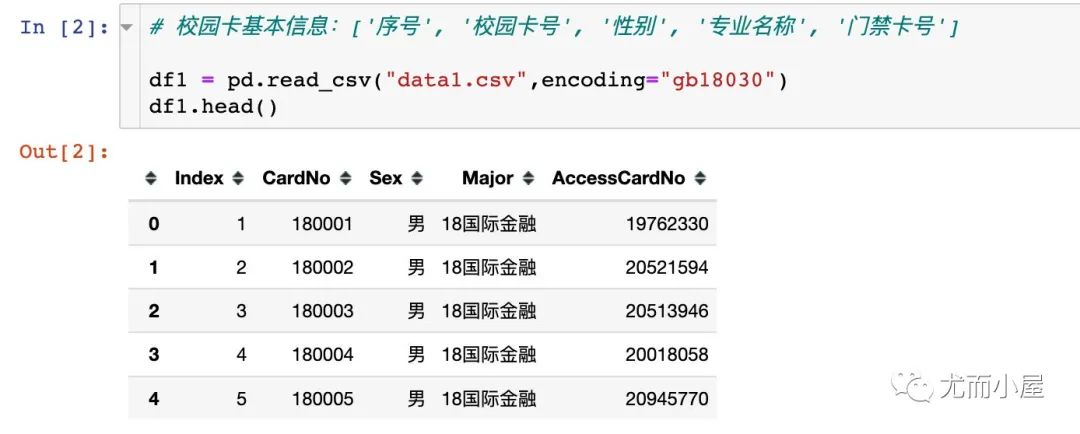
2、数据2:校园卡每次消费和充值的明细数据
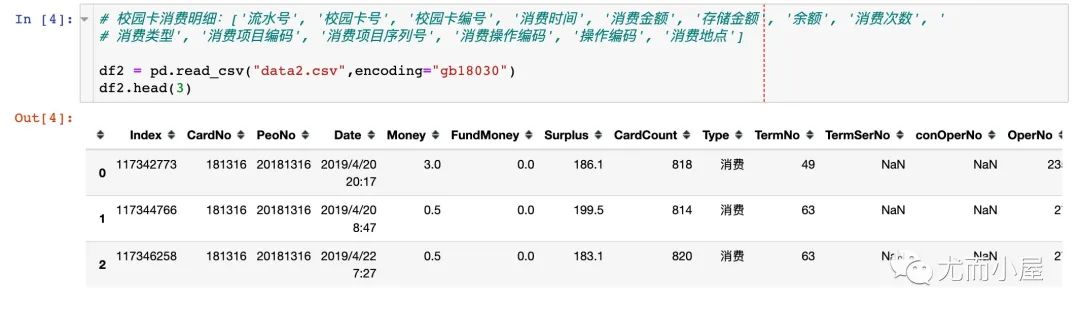
3、数据3:门禁明细数据
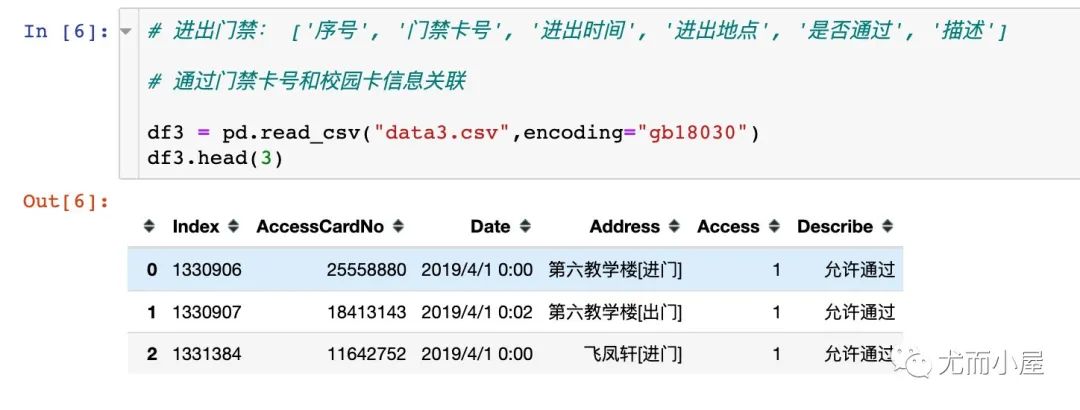
数据大小
In [8]:
print("df1: ", df1.shape)
print("df2: ", df2.shape)
print("df3: ", df3.shape)
df1: (4341, 5)
df2: (519367, 14)
df3: (43156, 6)
缺失值
# 每列缺失值
df1.isnull().sum()
# 每列的缺失值占比
df2.apply(lambda x : sum(x.isnull())/len(x), axis=0)
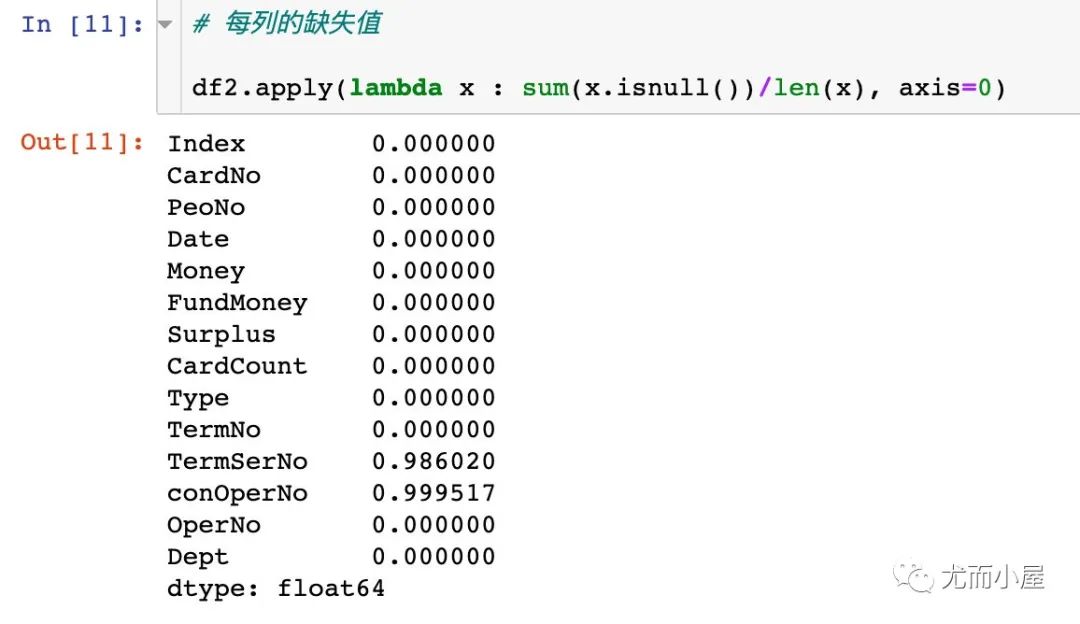
人数对比
不同性别人数
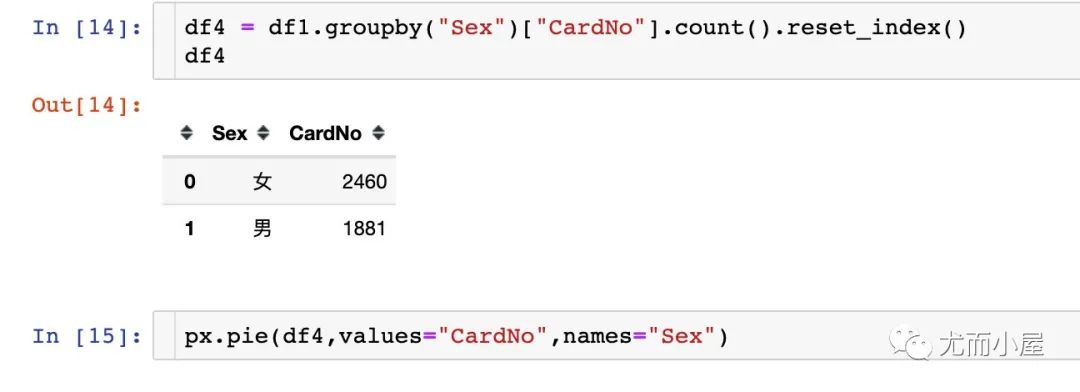
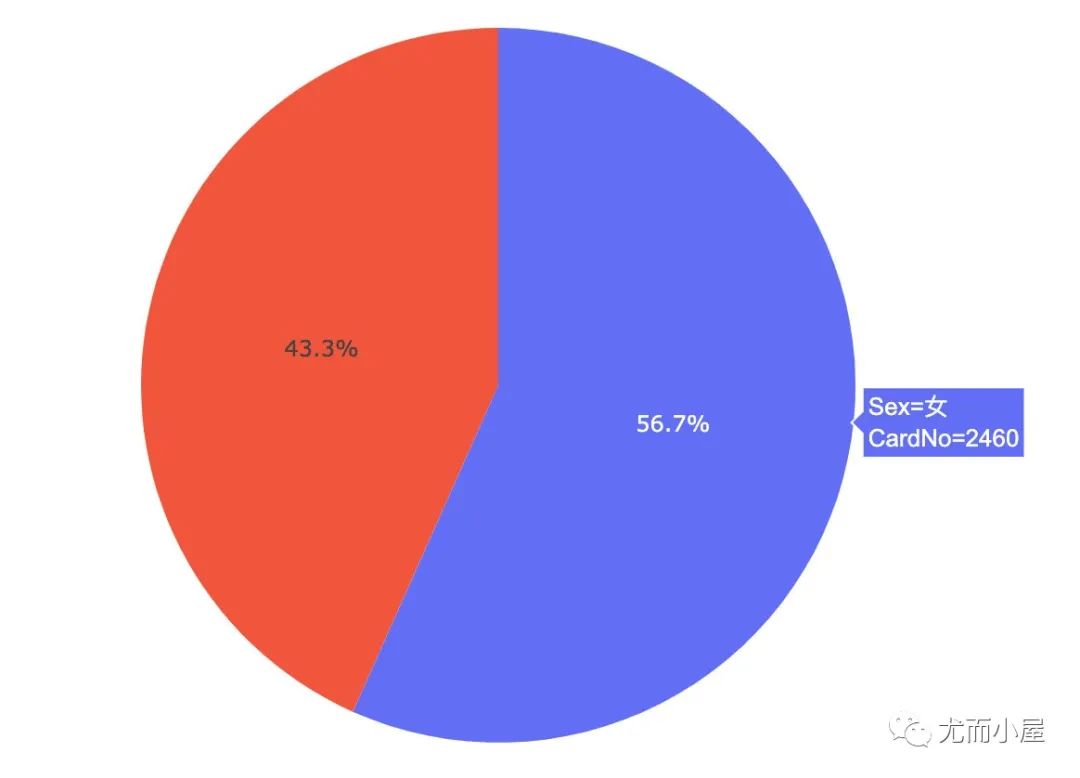
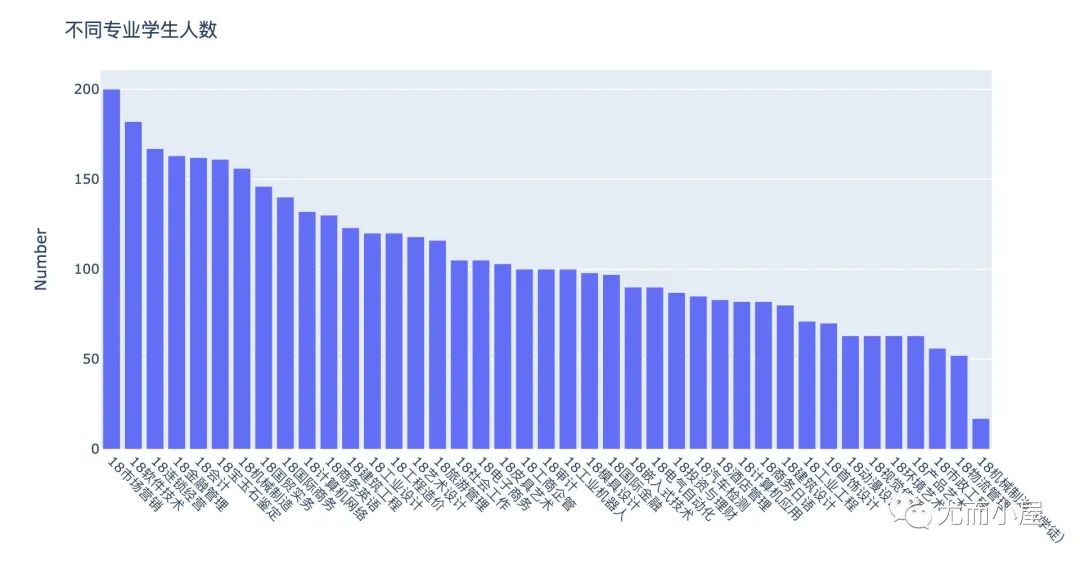
不同专业人数
In [16]:
df5 = df1["Major"].value_counts().reset_index()
df5.columns = ["Major","Number"]
df5.head()

不同专业不同性别人数
In [18]:
df6 = df1.groupby(["Major","Sex"])["CardNo"].count().reset_index()
df6.head()

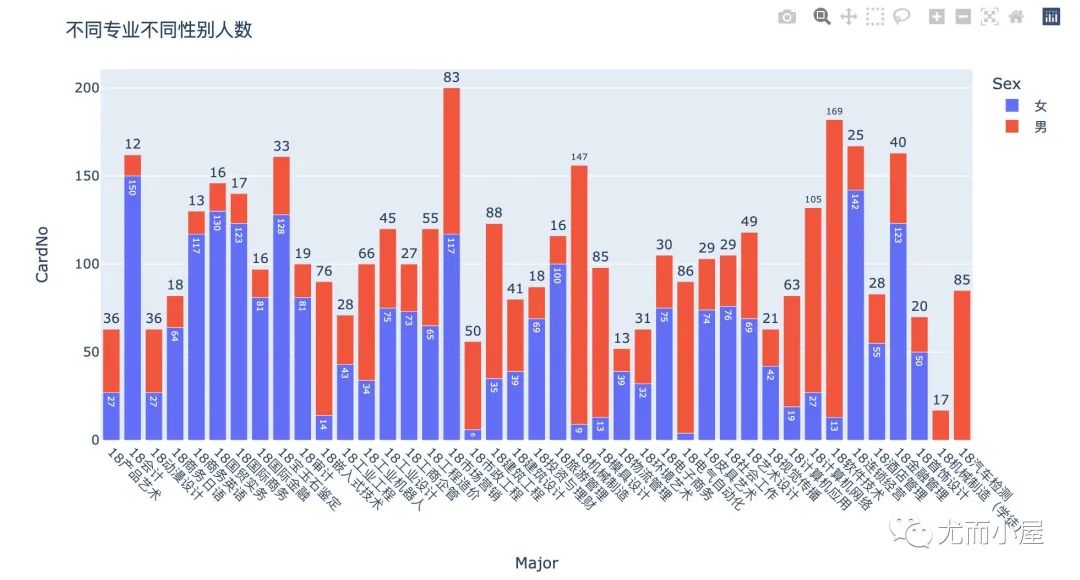
fig = px.treemap(
df6,
path=[px.Constant("all"),"Major","Sex"], # 重点:传递数据路径
values="CardNo",
color="Major" # 指定颜色变化的参数
)
fig.update_traces(root_color="maroon")
# fig.update_traces(textposition="top right")
fig.update_layout(margin=dict(t=30,l=20,r=25,b=30))
fig.show()

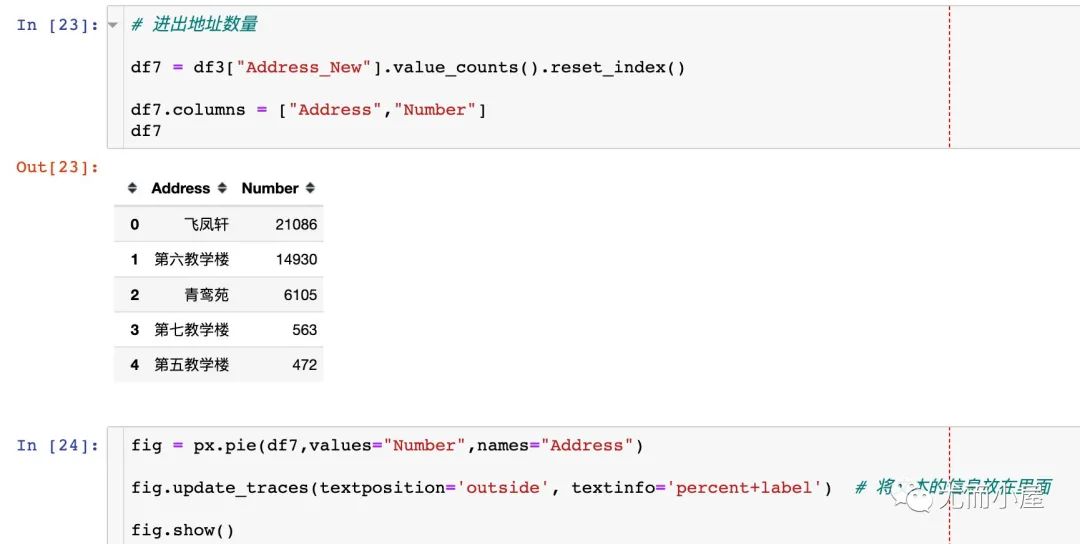
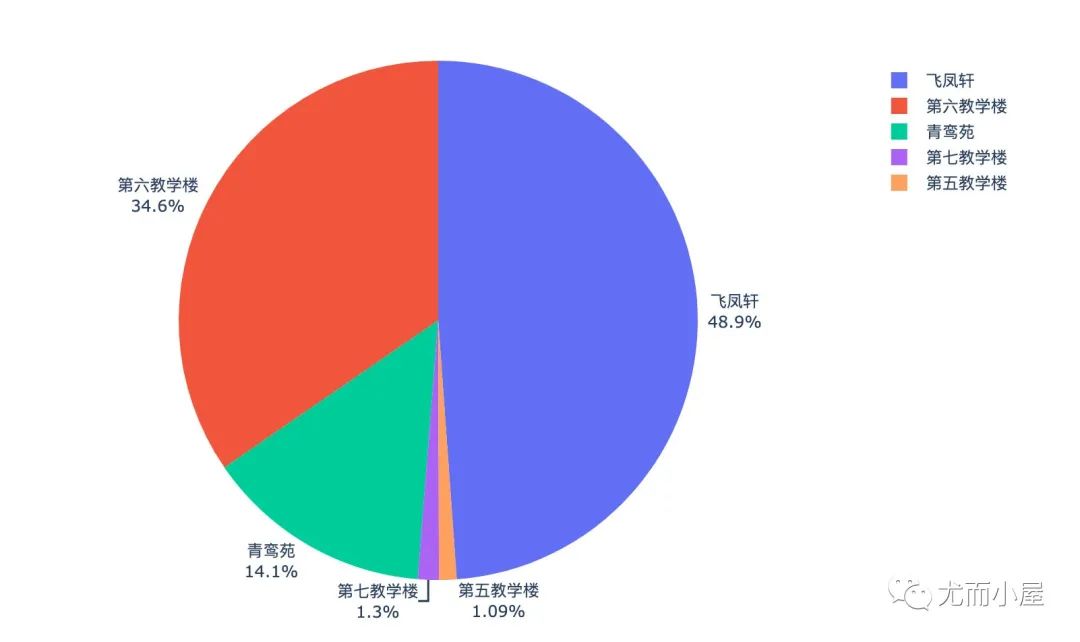
进出门禁信息
地址信息
In [21]:
# 1、处理address
address = df3["Address"].str.extract(r"(?P<Address_New>[\w]+)\[(?P<Out_In>[\w]+)\]")
address
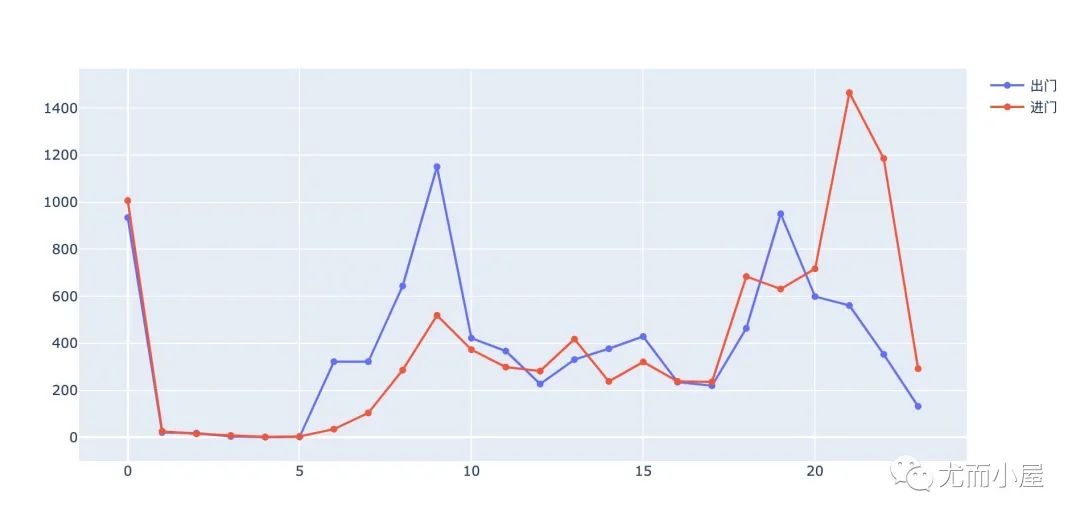
进出门禁时间
In [25]:
df8 = pd.merge(df3,df1,on="AccessCardNo")
df8.loc[:,'Date'] = pd.to_datetime(df8.loc[:,'Date'],format='%Y/%m/%d %H:%M',errors='coerce')
df8["Hour"] = df8["Date"].dt.hour
# df8["Minute"] = df8["Date"].dt.minute
# 进出门禁人数统计/小时
df9 = df8.groupby(["Hour","Out_In"]).agg({"AccessCardNo":"count"}).reset_index()
df9.head()

# 准备画布
fig = go.Figure()
# 添加不同的数据
fig.add_trace(go.Scatter(
x=df9.query("Out_In == '出门'")["Hour"].tolist(),
y=df9.query("Out_In == '出门'")["AccessCardNo"].tolist(),
mode='lines + markers', # mode模式选择
name='出门')) # 名字
fig.add_trace(go.Scatter(
x=df9.query("Out_In == '进门'")["Hour"].tolist(),
y=df9.query("Out_In == '进门'")["AccessCardNo"].tolist(),
mode='lines + markers',
name='进门'))
fig.show()
消费信息
In [30]:
# 数据合并 只取出两个字段:卡号和性别
df10 = pd.merge(df2,df1[["CardNo","Sex"]],on="CardNo")
合并信息
In [32]:
df10["Card_Sex"] = df10["CardNo"].apply(lambda x: str(x)) + "_" + df10["Sex"]
主要地点
In [33]:
# Card_Sex:统计消费人次
# Money:统计消费金额
df11 = (df10.groupby("Dept").agg({"Card_Sex":"count","Money":sum})
.reset_index().sort_values("Money",ascending=False))
df11.head(10)
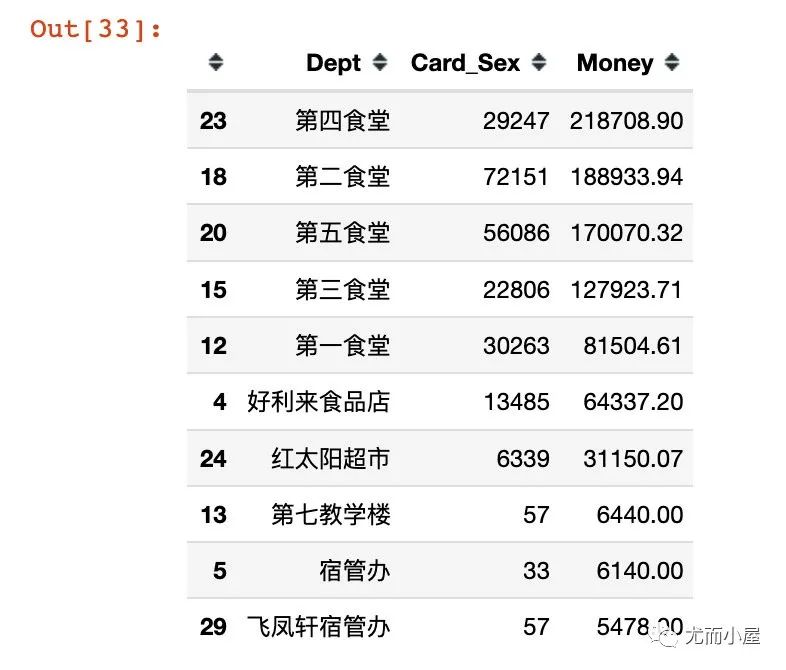
fig = px.bar(df11,x="Dept",y="Card_Sex")
fig.update_layout(title_text='不同地方的消费人数',xaxis_tickangle=45)
fig.show()
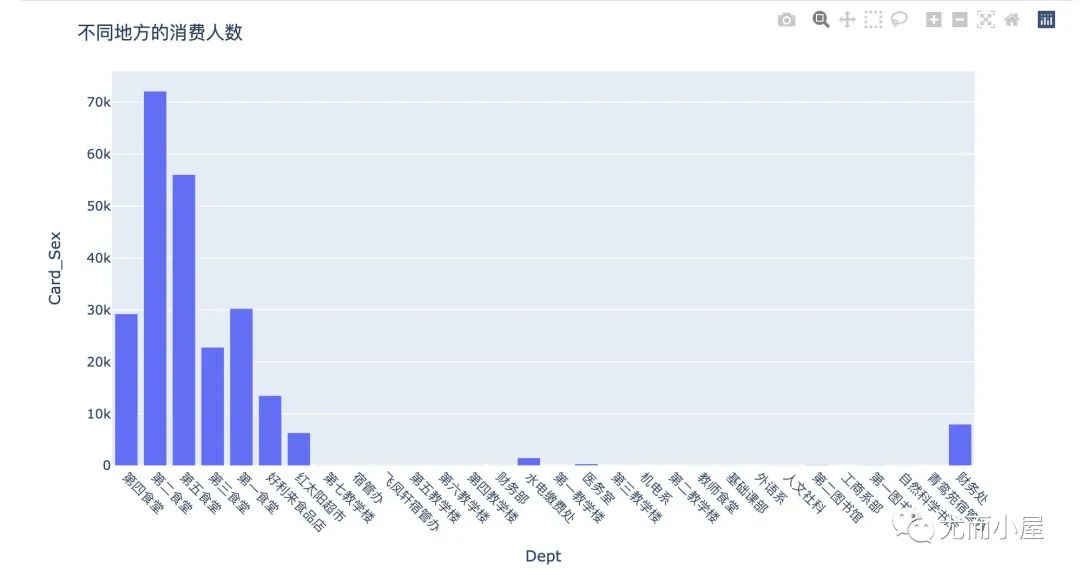
fig = px.bar(df11,x="Dept",y="Money")
fig.update_layout(title_text='不同地方的消费金额',xaxis_tickangle=45)
fig.show()
关联规则挖掘
时间处理
时间处理主要是两个点:
-
时间格式的转换
-
时间离散化:每5分钟一个类型
在这里我们默认:如果两个时间在同一个类型中,认为两人在一起消费
import datetime
def change_time(x):
# 转成标准时间格式
result = str(datetime.datetime.strptime(x, "%Y/%m/%d %H:%M"))
return result
def time_five(x):
# ‘2022-02-24 15:46:09’ ---> '2022-02-24 15_9'
res1 = x.split(":")[0]
res2 = str(round(int(x.split(":")[1]) / 5))
return res1 + "_" + res2
df10["New_Date"] = df10["Date"].apply(change_time)
df10["New_Date"] = df10["New_Date"].apply(time_five)
df10.head(3)

提起每个时间类型的人员信息:
# 方式1
df11 = df10.groupby(["New_Date"])["Card_Sex"].apply(list).reset_index()
# 每个列表中的元素去重
df11["Card_Sex"] = df11["Card_Sex"].apply(lambda x: list(set(x)))
all_list = df11["Card_Sex"].tolist()
# 方式2
# all_list = []
# for i in df10["New_Date"].unique().tolist():
# lst = df10[df10["New_Date"] == i]["Card_Sex"].unique().tolist()
# all_list.append(lst)

频繁项集寻找
In [44]:
import efficient_apriori as ea
# itemsets:频繁项 rules:关联规则
itemsets, rules = ea.apriori(all_list,
min_support=0.005,
min_confidence=1
)
一个人
一个人消费的数据最多:2565条数据,单身毕竟多!
len(itemsets[1]) # 2565条
# 部分数据
{('181539_男',): 52,
('180308_女',): 47,
('183262_女',): 100,
('182958_男',): 88,
('180061_女',): 83,
('182936_男',): 80,
('182931_男',): 87,
('182335_女',): 60,
('182493_女',): 75,
('181944_女',): 67,
('181058_男',): 93,
('183391_女',): 63,
('180313_女',): 82,
('184275_男',): 69,
('181322_女',): 104,
('182391_女',): 57,
('184153_女',): 31,
('182711_女',): 40,
('181594_女',): 36,
('180193_女',): 84,
('184263_男',): 61,
两个人
len(itemsets[2]) # 378条
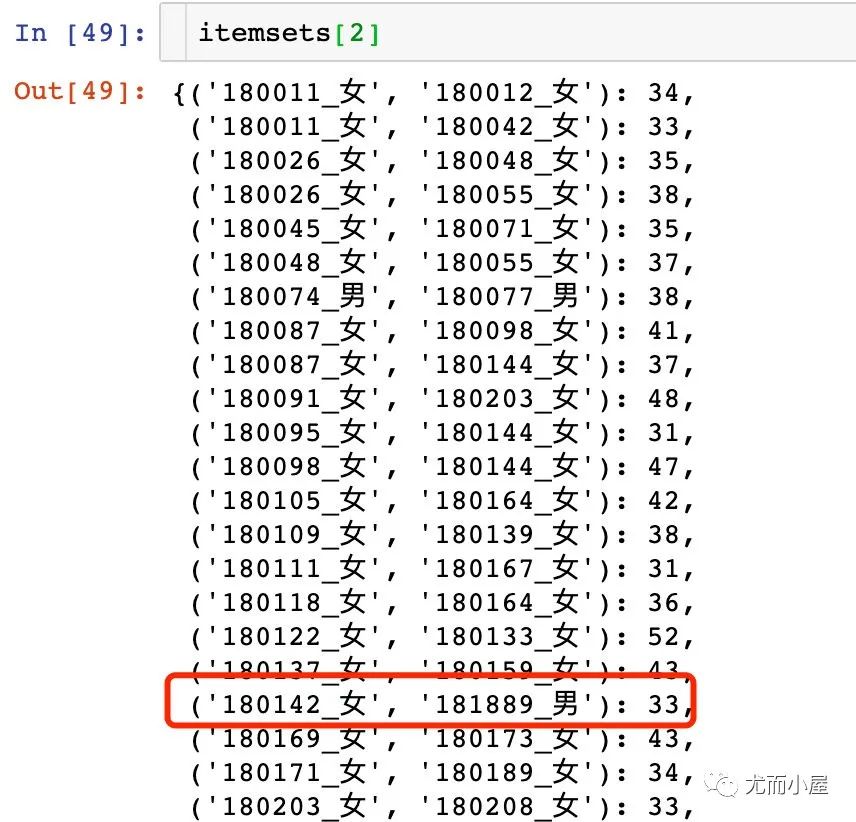
查看了全部的数据,统计了下面的结果:
('180433_男', '180499_女'): 34
# 可疑渣男1
('180624_男', '181013_女'): 36,
('180624_男', '181042_女'): 37,
# 可疑渣男2
('181461_男', '180780_女'): 38,
('181461_男', '180856_女'): 34,
('181597_男', '183847_女'): 44,
('181699_男', '181712_女'): 31,
('181889_男', '180142_女'): 33,
# 可疑渣男3:NB
('182239_男', '182304_女'): 39,
('182239_男', '182329_女'): 40,
('182239_男', '182340_女'): 37,
('182239_男', '182403_女'): 35,
('182873_男', '182191_女'): 31,
('183343_男', '183980_女'): 44,
1、可疑男生1-180624
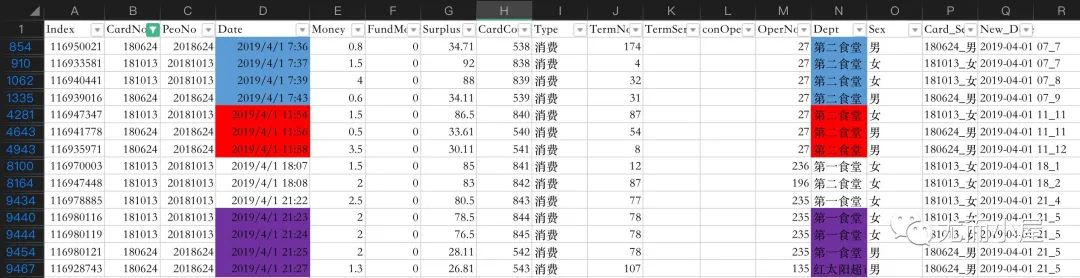
回到原始数据,查看他和不同女生在时间上消费的交集情况。
(1)和女生181013的交集:
-
4月1号早上7.36:应该是一起吃了早餐;11点54一起吃了午饭
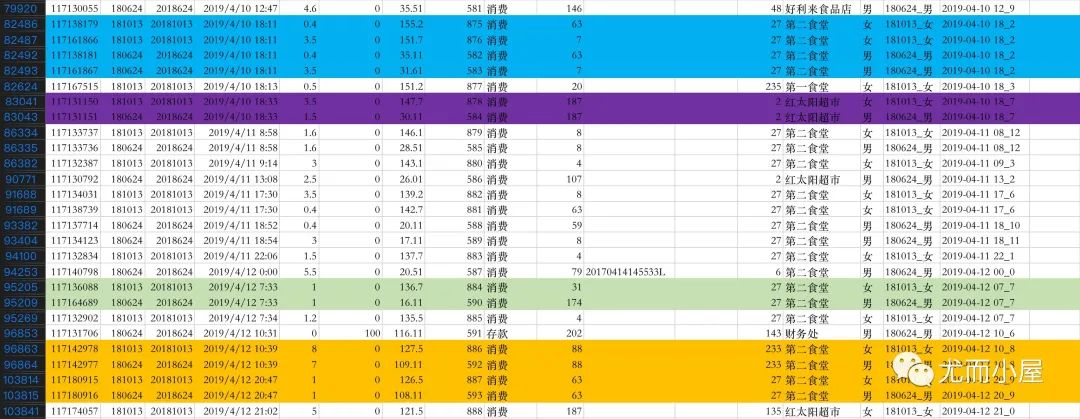
-
4.10、4.12等不同时间点的交集
(2)和女生181042的交集:
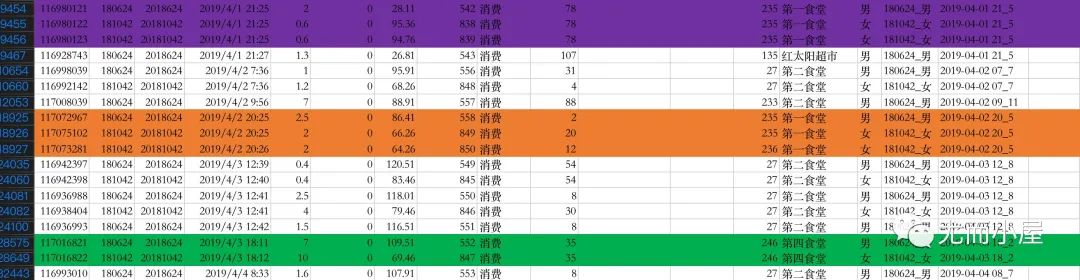
2、看看可疑的渣男3
这哥们实在是厉害呀~数据挖掘显示居然和4个女生同时存在一定的关联!
('182239_男', '182304_女'): 39
('182239_男', '182329_女'): 40
('182239_男', '182340_女'): 37
('182239_男', '182403_女'): 35
除了可能的男女朋友关系,在2元数据中更多的是基友或者闺蜜:
('180450_女', '180484_女'): 35,
('180457_女', '180493_女'): 31,
('180460_女', '180496_女'): 31,
('180493_女', '180500_女'): 47,
('180504_女', '180505_女'): 43,
('180505_女', '180506_女'): 35,
('180511_女', '181847_女'): 42,
('180523_男', '182415_男'): 34,
('180526_男', '180531_男'): 33,
('180545_女', '180578_女'): 41,
('180545_女', '180615_女'): 47,
('180551_女', '180614_女'): 31,
('180555_女', '180558_女'): 36,
('180572_女', '180589_女'): 31,
('181069_男', '181103_男'): 44,
('181091_男', '181103_男'): 33,
('181099_男', '181102_男'): 31,
('181099_男', '181107_男'): 34,
('181102_男', '181107_男'): 35,
('181112_男', '181117_男'): 43,
('181133_男', '181136_男'): 52,
('181133_男', '181571_男'): 45,
('181133_男', '181582_男'): 33,
3-4个人
3-4元的数据可能是一个宿舍的同学或者朋友一起的,相对数量会比较少:
len(itemsets[3]) # 18条
{('180363_女', '181876_女', '183979_女'): 40,
('180711_女', '180732_女', '180738_女'): 35,
('180792_女', '180822_女', '180849_女'): 35,
('181338_男', '181343_男', '181344_男'): 40,
('181503_男', '181507_男', '181508_男'): 33,
('181552_男', '181571_男', '181582_男'): 39,
('181556_男', '181559_男', '181568_男'): 35,
('181848_女', '181865_女', '181871_女'): 35,
('182304_女', '182329_女', '182340_女'): 36,
('182304_女', '182329_女', '182403_女'): 32,
('183305_女', '183308_女', '183317_女'): 32,
('183419_女', '183420_女', '183422_女'): 49,
('183419_女', '183420_女', '183424_女'): 45,
('183419_女', '183422_女', '183424_女'): 48,
('183420_女', '183422_女', '183424_女'): 51,
('183641_女', '183688_女', '183690_女'): 32,
('183671_女', '183701_女', '183742_女'): 35,
('183713_女', '183726_女', '183737_女'): 36}
4元数据只有一条:

总结
关联规则分析是一个经典数据挖掘算法,在消费明细数据、超市购物篮数据、金融保险、信用卡等领域应用的十分广泛。
当我们运用关联分析技术挖掘出频繁出现的组合和强关联规则之后,就可以指定相应的营销策略或者找到不同对象之间的关系。
上面的数据挖掘过程,其实也存在一定的缺陷:
-
约束太宽:仅仅是根据时间间隔类型进行分组统计,忽略了学生的专业、消费地点等信息
-
时间太窄:5分钟的时间间隔过去窄,会过滤掉很多信息