Hbase最基本的单位是列(column)。一列或多列形成一行(row),并由唯一的行键(row key)来确定存储。反过来说,一个表(table)中有若干行,其中每列可能有多个版本,在每一个单元格(cell)中存储了不同的值
Hbase表结构:建表时,不需要限定表中的字段,只需要指定若干个列族。
插入数据时,列族中可以存储任意多个列(以kv对的形式存储, 列名-列值)
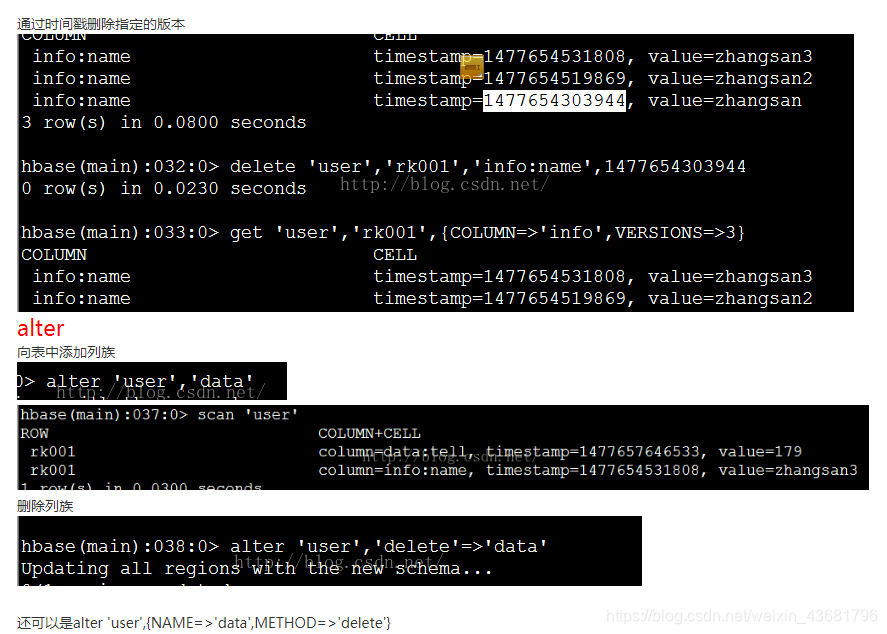
一个value可以有多个版本,通过版本号来区分(时间戳)
要查询某一个具体字段的值,需要指定的坐标:表名–>行键–>列族(ColumnFamily):列名(Qualifier)-
Table-表(大表)
Rowkey-行键(主键)
行键是字节数组,任何字符串都可以作为行键
表中的行键进行排序,数据按照Rowkey的字节(byte order) 排序存储
所有的对表的访问都要通过行键(单个Rowkey访问,或Rowkey范围访问,全表扫描0
Column family(列族)
列族必须定义表时给出,但已可以动态添加列族
每个列族可以有一个或多个列成员(Column Qualigier),列成员不需要在定义表时给出,新的列族成员可以随后按需动态加入
数据按列族分开存储,HBase所谓的列式存储就是根据列族分开存储(每个列族对应一个Store)
TimeStamp(时间戳)
每个Cell可能有多个版本,他们之间用时间戳区分。
Cell(单元格)
Cell由行键,列族:限定符,时间戳唯一决定。
Cell中的数据是没有类型的,全部以字节码形式存储
每个单元格保存着同一份数据的多个版本
不同时间版本的数据按照时间顺序倒序排序
Region(区域)
HBase自动把表水平(按row)划分成多个区域(region),每个region会保存一个表里面某段连续的数据
HRegion是HBase中分布式存储和负载均衡的最小单元,最小单元表示不同的HRegion可以分布在不同的HRegionServer上。但一个HRegion不会拆分到多个server上。
因为hbase与hive的区别
hbase查询快
硬件需求高于hadoop集群 硬盘 内存 CPU
模式设计
数据库的模式设计不是一个新概念,只要成为数据库的系统都存在模式设计问题。
HBase的模式结构包括表、Rowkey,列族,timestamp
模式是一个三维有序结构,表,Rowkey,列族三个维度确定一行数据
Rowkey(行键设计)
Rowkey是不可分割的字节数,按字典排序由低到高存储在表中。
RowKey唯一原则
Rowkey尽量散列
RowKey长度原则
Column Family 列族定义
列族,是一些列的集合
一个列族的所有成员都有着相同的前缀。
在物理上,列族的成员在文件系统上都存储在一起。
多个列族在执行flush和compaction时,造成很多IO负载
Flush和compaction操作是针对一个Region的,当一个列族操作大量数据时会引发一个flush
那些不相关的列族也要进行flush,会造成很多没用的I/O浮躁。



———————
作者:Gedeon
来源:CSDN
原文:https://blog.csdn.net/qq_24908345/article/details/53230169
版权声明:本文为博主原创文章,转载请附上博文链接!