问题描述
输入:一个最多包含n个正整数的文件,每个数都小于n,其中n=10^7。如果在输入文件中有任何正数重复出现就是致命错误。没有其他数据与该正数相关联。
输出:按升序排列的输入正数的列表。
约束:最多有1MB的内存空间可用,有充足的磁盘存储空间可用。运行时间最多几分钟,运行时间为10秒就不需要进一步优化。
程序设计与实现概要:
应用位图或位向量表示集合。可用一个10位长的字符串来表示一个所有元素都小于10的简单的非负整数集合,例如,可以用如下字符串表示集合{1,2,4,5,8}:
0 1 1 1 0 1 0 0 1 0 0
代表集合中数值的位都置为1,其他左所有的位置为0.编程珠玑当中建议是一年个一个具有1000万个位的字符串来表示这个文件,那么这个文件的所占容量为10000000 bit=10^7bit,不到1MB的大小,其中,当且精当整数i在文件中存在,第i为1,这个表示利用了该问题的三个在排序问题中不常见的属性:输入数据限制在相对较小的范围内;数据没有重复;而且对于每条记录而言,除了单一个整数外没有其他关联数据。
如给定表示文件中整数集合的位图数据结构,则可以分三个阶段来编写程序
第一阶段:将所有的位都置为0,从而将集合初始化为空。
第二阶段:通过读入文件中的每个整数来建立集合,将每个对应的位置都置为1。
第三阶段:检验每一位,如果该为为1,就输出对应的整数,有此产生有序的输出文件。
下面的C语言的实现和C++的实现代码
C语言:
所申请的int数组如下所示:
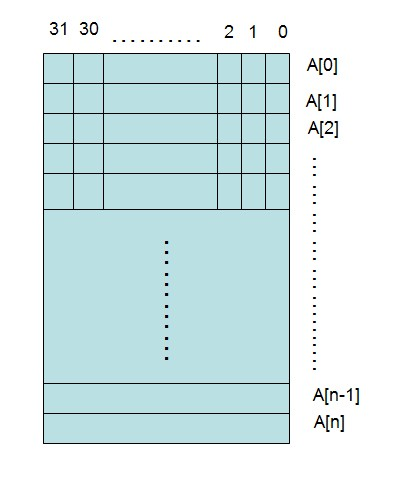
32位机器上,一个整形,比如int a; 在内存中占32bit位,可以用对应的32bit位对应十进制的0-31个数,bitmap算法利用这种思想处理大量数据的排序与查询.
字节位置=数据/32;(采用位运算即右移5位)
位位置=数据%32;(采用位运算即跟0X1F进行与操作)。
优点:
1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:所有的数据不能重复。即不可对重复的数据进行排序和查找。
如给定表示文件中整数集合的位图数据结构,则可以分三个阶段来编写程序:
第一阶段:将所有的位都置为0,从而将集合初始化为空。
第二阶段:通过读入文件中的每个整数来建立集合,将每个对应的位置都置为1。
第三阶段:检验每一位,如果该为为1,就输出对应的整数,有此产生有序的输出文件。
字节位置=数据/32;(采用位运算即右移5位)
位位置=数据%32;(采用位运算即跟0X1F进行与操作)。
思想比较简单,关键是十进制和二进制bit位需要一个map图,把十进制的数映射到bit位。
下面详细说明这个map映射表。
map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],
其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]———>0-31
a[1]———>32-63
a[2]———>64-95
a[3]———>96-127
……….
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
位移转换
1.求十进制0-N对应在数组a中的下标:
十进制0-31,对应在a[0]中,先由十进制数n转换为与32的余可转化为对应在数组a中的下标。
比如n=24,那么 n/32=0,则24对应在数组a中的下标为0。又比如n=60,那么n/32=1,
则60对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
2.求0-N对应0-31中的数:
十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
3.利用移位0-31使得对应32bit位为1.
解析:void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }
1.i>>SHIFT:
其中SHIFT=5,即i右移5为,2^5=32,相当于i/32,即求出十进制i对应在数组a中的下标。 比如i=20,通过i>>SHIFT=20>>5=0 可求得i=20的下标为0;
2.i & MASK:
其中MASK=0X1F,十六进制转化为十进制为31,二进制为0001 1111,i&(0001 1111)相当于保留i的后5位。 比如i=23,二进制为:0001 0111,那么 0001 0111 & 0001 1111 = 0001
0111 十进制为:23 比如i=83,二进制为:0000 0000 0101 0011,那么 0000 0000 0101 0011 &
0000 0000 0001 0000 = 0000 0000 0001 0011 十进制为:19 i & MASK相当于i%32。
3.1<<(i & MASK)
相当于把1左移 (i & MASK)位。 比如(i & MASK)=20,那么i<<20就相当于: 0000 0000 0000 0000 0000 0000 0000 0001 >>20
=0000 0000 0000 1000 0000 0000 0000 0000
4.void set(int i)
{ a[i>>SHIFT] |= (1<<(i & MASK)); }等价于: void set(int i) { a[i/32] |= (1<<(i%32)); }
#include <iostream>
#include <algorithm>
#include <ctime>
using namespace std;
#define DATA_NUM 100000
#define SHIFT 5
#define MASK 0x1f
int bigrand()
{
return rand()*RAND_MAX + rand() + rand();
}
int randint(int m, int n)
{
return (bigrand() % (n - m) + m);
}
void make_data(int num)
{
int *temp = new int[DATA_NUM];
if (temp == NULL)
{
cout << "new error in make_data!" << endl;
return;
}
for (int i = 0; i < DATA_NUM; i++)
{
temp[i] = i + 1;
}
for (int i = 0; i < DATA_NUM; i++)
{
swap(temp[i], temp[randint(i, DATA_NUM)]);
}
FILE *fp;
fp = fopen("data.txt", "w");
if (fp == NULL)
{
cout << "fopen() error int make_data!" << endl;
}
for (int i = 0; i < DATA_NUM; i++)
{
fprintf(fp, "%d ", temp[i]);
}
fclose(fp);
cout << "随机数文件生成成功!" << endl;
}
void set(int *bigMap,int i)
{
bigMap[i >> SHIFT] |= (1 << (i&MASK));
}
void clr(int *bigMap, int i)
{
bigMap[i >> SHIFT] &= ~(1 << (i&MASK));
}
int test(int *bigMap, int i)
{
return bigMap[i >> SHIFT] & (1 << (i&MASK));
}
void bigMapSort()
{
int bigmap[DATA_NUM];
for (int i = 0; i < DATA_NUM; i++)
{
clr(bigmap, i);
}
FILE *fpsrc;
fpsrc = fopen("data.txt", "r");
if (fpsrc == NULL)
{
cout << "fopen() error in bigMapSort!" << endl;
return;
}
int data;
while (fscanf(fpsrc, "%d ", &data)!=EOF)
{
if (data <= DATA_NUM)
{
set(bigmap, data);
}
}
FILE *fpdst;
fpdst = fopen("result.txt", "w");
if (fpdst == NULL)
{
cout << "fopen() error in bigMapSort!" << endl;
return;
}
for (int i = 0; i < DATA_NUM; i++)
{
if (test(bigmap,i) == 1)
{
fprintf(fpdst, "%d ", i);
}
}
cout << "排序成功!" << endl;
fclose(fpdst);
fclose(fpsrc);
}
int main()
{ //初始化随机数种子
srand((unsigned)time(NULL));
make_data(DATA_NUM);
clock_t start = clock();
bigMapSort();
clock_t end = clock();
cout << "程序执行所需要的时间为:" << end - start << endl;
system("pause");
return 0;
}
C++(使用bitset)
#include <iostream>
#include <algorithm>
#include <ctime>
#include <bitset>
using namespace std;
#define DATA_NUM 100000
#define SHIFT 5
#define MASK 0x1f
int bigrand()
{
return rand()*RAND_MAX + rand() + rand();
}
int randint(int m, int n)
{
return (bigrand() % (n - m) + m);
}
void make_data(int num)
{
int *temp = new int[DATA_NUM];
if (temp == NULL)
{
cout << "new error in make_data!" << endl;
return;
}
for (int i = 0; i < DATA_NUM; i++)
{
temp[i] = i + 1;
}
for (int i = 0; i < DATA_NUM; i++)
{
swap(temp[i], temp[randint(i, DATA_NUM)]);
}
FILE *fp;
fp = fopen("data.txt", "w");
if (fp == NULL)
{
cout << "fopen() error int make_data!" << endl;
}
for (int i = 0; i < DATA_NUM; i++)
{
fprintf(fp, "%d ", temp[i]);
}
fclose(fp);
cout << "随机数文件生成成功!" << endl;
}
//
//void set(int *bigMap,int i)
//{
// bigMap[i >> SHIFT] |= (1 << (i&MASK));
//}
//
//void clr(int *bigMap, int i)
//{
// bigMap[i >> SHIFT] &= ~(1 << (i&MASK));
//}
//
//int test(int *bigMap, int i)
//{
// return bigMap[i >> SHIFT] & (1 << (i&MASK));
//}
void bigMapSort()
{
//int bigmap[DATA_NUM];
//for (int i = 0; i < DATA_NUM; i++)
//{
// clr(bigmap, i);
//}
bitset<DATA_NUM+1> bigmap;
bigmap.reset();
FILE *fpsrc;
fpsrc = fopen("data.txt", "r");
if (fpsrc == NULL)
{
cout << "fopen() error in bigMapSort!" << endl;
return;
}
int data;
while (fscanf(fpsrc, "%d ", &data)!=EOF)
{
if (data <= DATA_NUM)
{
//set(bigmap, data);
bigmap.set(data,1);
}
}
FILE *fpdst;
fpdst = fopen("result.txt", "w");
if (fpdst == NULL)
{
cout << "fopen() error in bigMapSort!" << endl;
return;
}
for (int i = 0; i < DATA_NUM; i++)
{
if(bigmap[i]==1) //(test(bigmap,i) == 1)
{
fprintf(fpdst, "%d ", i);
}
}
cout << "排序成功!" << endl;
fclose(fpdst);
fclose(fpsrc);
}
int main()
{ //初始化随机数种子
srand((unsigned)time(NULL));
make_data(DATA_NUM);
clock_t start = clock();
bigMapSort();
clock_t end = clock();
cout << "程序执行所需要的时间为:" << end - start << endl;
system("pause");
return 0;
}
多路归并排序
1、第一次遍历文件,读取文件内的第1到第250 000个数字,进行排序,将排序后的正整数存储在临时的磁盘文件filename1.txt中;
2、第二次遍历文件,读取文件内的第250 001到底500 000个数字,进行排序,将排序后的正整数存储在临时的磁盘文件filename2.txt中;
……
将文件中的整数分别进行排序后,然后使用多路归并排序进行整合,首先读取40个文件中的第一个数字,查找这40个数字中最小的数字,将其输出到结果文件中result.txt中,然后读取该最小的元素对应的文件中的下一个数字,替代其位置,依次进行,最后得到排序号的文件。
代码实例1如下所示。
#include <iostream>
#include <algorithm>
#include <string>
#include <fstream>
#include <time.h>
using namespace std;
#define MAX 10000 //总数据量,可修改
#define MAX_ONCE 2500 //内存排序MAX_ONCE个数据
#define FILENAME_LEN 20
//range:范围
//num :个数
void Random(int range, int num)
{
int *a = new int[range];
int i, j;
fstream dist_file;
//初始化随机数种子
srand((unsigned)time(NULL));
for (i = 0; i < range; i++)
{
a[i] = i + 1;
}
//打表预处理
for (j = 0; j < range; j++)
{
int ii = (rand() * RAND_MAX + rand()) % range;
int jj = (rand() * RAND_MAX + rand()) % range;
swap(a[ii], a[jj]);
}//for
dist_file.open("data.txt", ios::out);
//写入文件
for (i = 0; i < num; i++)
{
dist_file << a[i] << " ";
}
//回收
delete[]a;
dist_file.close();
}
bool comp(int &a, int &b)
{
return a < b;
}
//index: 文件的下标
char *create_filename(int index)
{
char *a = new char[FILENAME_LEN];
sprintf(a, "data %d.txt", index);
return a;
}
//num:每次读入内存的数据量
void mem_sort(int num)
{
fstream fs("data.txt", ios::in);
int temp[MAX_ONCE]; //内存数据暂存
int file_index = 0; //文件下标
int count; //实际读入内存数据量
bool eof_flag = false; //文件末尾标识
while (!fs.eof())
{
count = 0;
for (int i = 0; i < MAX_ONCE; i++)
{
fs >> temp[count];
//读入一个数据后判断是否到了末尾
if (fs.peek() == EOF)
{
eof_flag = true;
break;
}//if
count++;
}//for
if (eof_flag) //如果到达文件末尾
{
break;
}
//内存排序
sort(temp, temp + count, comp);
//写入文件
char *filename = create_filename(++file_index);
fstream fs_temp(filename, ios::out);
for (int i = 0; i < count; i++)
{
fs_temp << temp[i] << " ";
}
fs_temp.close();
delete[]filename;
}//while
fs.close();
}
void merge_sort(int filecount)
{
fstream *fs = new fstream[filecount];
fstream ret("ret.txt", ios::out);
int index = 1;
int temp[MAX_ONCE];
int eofcount = 0;
bool *eof_flag = new bool[filecount];
memset(eof_flag, false, filecount * sizeof(bool));
for (int i = 0; i < filecount; i++)
{
fs[i].open(create_filename(index++), ios::in);
}
for (int i = 0; i < filecount; i++)
{
fs[i] >> temp[i];
}
while (eofcount < filecount)
{
int j = 0;
//找到第一个未结束处理的文件
while (eof_flag[j])
{
j++;
}
int min = temp[j];
int fileindex = 0;
for (int i = j + 1; i < filecount; i++)
{
if (temp[i] < min && !eof_flag[i])
{
min = temp[i];
fileindex = i;
}
}//for
ret << min << " ";
fs[fileindex] >> temp[fileindex];
//末尾判断
if (fs[fileindex].peek() == EOF)
{
eof_flag[fileindex] = true;
eofcount++;
}
}//while
delete[]fs;
delete[]eof_flag;
ret.close();
}
int main()
{
Random(MAX, MAX);
clock_t start = clock();
mem_sort(MAX);
merge_sort(4);
clock_t end = clock();
double cost = (end - start) * 1.0 / CLK_TCK;
cout << "耗时" << cost << "s" << endl;
system("pause");
return 0;
}多路归并的方法需要多次进行磁盘I/O读写,会增加额外的时间开销,总体来说,该方法的时间复杂度比较高。
代码示例2:
下面以一个包含很多个整数的大文件为例,来说明多路归并的外排序算法基本思想。假设文件中整数个数为N(N是亿级的),整数之间用空格分开。首先分多次从该文件中读取M(十万级)个整数,每次将M个文件在内存中使用快排序之后存入临时文件,然后使用多路归并将临时文件中的数据牌号序存入输出文件。显然,该排序算法需要对每个整数做2次磁盘读和2次磁盘写。 下面代码是基于以上思想对包含大量整数文件的从小到大排序的一个简单实现,这里没有使用内存缓冲区,在归并时简单使用一个数组来存储每个临时文件的第一个元素。
/*********使用多路归并进行外排序的类*************/
//ExternSort.h
/*
* 大数据量的排序
* 多路归并排序
* 以千万级整数从小到大排序为例
* 一个比较简单的例子,没有建立内存缓冲区
*/
#ifndef EXTERN_SORT_H
#define EXTERN_SORT_H
#include <cassert>
class ExternSort
{
public:
void sort()
{
time_t start = time(NULL);
//将文件内容分块在内存中排序,并分别写入临时文件
int file_count = memory_sort();
//归并临时文件内容到输出文件
merge_sort(file_count);
time_t end = time(NULL);
printf("total time:%f\n", (end - start) * 1000.0/ CLOCKS_PER_SEC);
}
//input_file:输入文件名
//out_file:输出文件名
//count: 每次在内存中排序的整数个数
ExternSort(const char *input_file, const char * out_file, int count)
{
m_count = count;
m_in_file = new char[strlen(input_file) + 1];
strcpy(m_in_file, input_file);
m_out_file = new char[strlen(out_file) + 1];
strcpy(m_out_file, out_file);
}
virtual ~ExternSort()
{
delete [] m_in_file;
delete [] m_out_file;
}
private:
int m_count; //数组长度
char *m_in_file; //输入文件的路径
char *m_out_file; //输出文件的路径
protected:
int read_data(FILE* f, int a[], int n)
{
int i = 0;
while(i < n && (fscanf(f, "%d", &a[i]) != EOF)) i++;
printf("read:%d integer\n", i);
return i;
}
void write_data(FILE* f, int a[], int n)
{
for(int i = 0; i < n; ++i)
fprintf(f, "%d ", a[i]);
}
char* temp_filename(int index)
{
char *tempfile = new char[100];
sprintf(tempfile, "temp%d.txt", index);
return tempfile;
}
static int cmp_int(const void *a, const void *b)
{
return *(int*)a - *(int*)b;
}
int memory_sort()
{
FILE* fin = fopen(m_in_file, "rt");
int n = 0, file_count = 0;
int *array = new int[m_count];
//每读入m_count个整数就在内存中做一次排序,并写入临时文件
while(( n = read_data(fin, array, m_count)) > 0)
{
qsort(array, n, sizeof(int), cmp_int);
char *fileName = temp_filename(file_count++);
FILE *tempFile = fopen(fileName, "w");
free(fileName);
write_data(tempFile, array, n);
fclose(tempFile);
}
delete [] array;
fclose(fin);
return file_count;
}
void merge_sort(int file_count)
{
if(file_count <= 0) return;
//归并临时文件
FILE *fout = fopen(m_out_file, "wt");
FILE* *farray = new FILE*[file_count];
int i;
for(i = 0; i < file_count; ++i)
{
char* fileName = temp_filename(i);
farray[i] = fopen(fileName, "rt");
free(fileName);
}
int *data = new int[file_count];//存储每个文件当前的一个数字
bool *hasNext = new bool[file_count];//标记文件是否读完
memset(data, 0, sizeof(int) * file_count);
memset(hasNext, 1, sizeof(bool) * file_count);
for(i = 0; i < file_count; ++i)
{
if(fscanf(farray[i], "%d", &data[i]) == EOF)//读每个文件的第一个数到data数组
hasNext[i] = false;
}
while(true)
{
//求data中可用的最小的数字,并记录对应文件的索引
int max = data[0];
int j = 0;
for(i = 0; i < file_count; ++i)
{
if(hasNext[i] && max > data[i])
{
max = data[i];
j = i;
}
}
if(j == 0 && !hasNext[0]) break; //没有可取的数字,终止归并
if(fscanf(farray[j], "%d", &data[j]) == EOF) //读取文件的下一个元素
hasNext[j] = false;
fprintf(fout, "%d ", max);
}
delete [] hasNext;
delete [] data;
for(i = 0; i < file_count; ++i)
{
fclose(farray[i]);
}
delete [] farray;
fclose(fout);
}
};
#endif
/**************测试主函数文件*****************************************/
/*
* 大文件排序
* 数据不能一次性全部装入内存
* 排序文件里有多个整数,整数之间用空格隔开
*/
#include <iostream>
#include <ctime>
#include <fstream>
#include "ExternSort.h"
using namespace std;
const unsigned int count = 100000000; // 文件里数据的行数
const unsigned int number_to_sort = 1000000; //在内存中一次排序的数量
const char *unsort_file = "unsort_data.txt"; //原始未排序的文件名
const char *sort_file = "sort_data.txt"; //已排序的文件名
void init_data(unsigned int num); //随机生成数据文件
int main(int argc, char* *argv)
{
srand(time(NULL));
init_data(count);
ExternSort extSort(unsort_file, sort_file, number_to_sort);
extSort.sort();
system("pause");
return 0;
}
void init_data(unsigned int num)
{
FILE* f = fopen(unsort_file, "wt");
for(int i = 0; i < num; ++i)
fprintf(f, "%d ", rand());
fclose(f);
}
扩展:
给40亿个不重复的unsigned int的整数,没有排过序,然后再给一个数,如果快速判断这个数是否在那40亿个数当中。(腾讯面试题)
用位图法:
40亿unsigned int,则用位图表示的话需要大小为40亿个bit=4*10^9 bit=0.5*10^9 bytes ;因此申请的内存只需要大小约为512MB左右,这样在内存每个bit代表一个unsigned int整数,并将每个bit初始化为0,然后将40亿个unsigned int的整数读入,每个unsigned int的整数对应bit设置为1,读入后,最后看所给定的数对应的bit是否为1,是1存在,否则不存在。