随着目标检测算法的快速发展,以及终端应用的日渐广泛,工业界对深度学习网络在终端应用的关注度越来越高,尤其是对于如何保持速度和精度上的平衡,也形成了不小的研究热度。本篇整理了一些较新的轻量级目标检测网络,结合我们自己的目标,所选的网络参数量多在
4M
以下。
1. YOLO Nano
YOLO Nano是一个
高度紧凑的网络,它是一个基于
YOLO
网络的
8
位量化模型,并在
PASCAL VOC 2007
数据集上进行了优化。
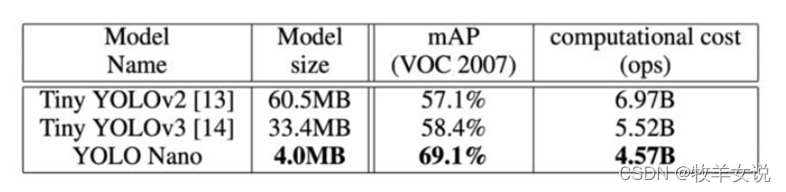
模型大小在4M左右,在计算上需要4.57B推算,性能表现上,在VOC 2007数据集上得到了69.1%的mAP。该网络非常适合边缘设备与移动端的实时检测。
论文地址:
https://arxiv.org/abs/1910.01271
代码地址:
GitHub – liux0614/yolo_nano: Unofficial implementation of yolo nano
YOLO Nano与Tiny YOLOv2、Tiny YOLOv3的对比:
2. Micro-YOLO
Micro-YOLO
基于
YOLOv3-Tiny
,它在保持检测性能的同时显着减少了参数数量和计算成本。研究者建议将
YOLOv3-tiny
网络中的卷积层替换为深度分布偏移卷积
(
DSConv:https://arxiv.org/abs/1901.01928v1
)
和带有
squeeze
和
excitation
块的移动反向瓶颈卷积
(MBConv
:主要源自于
EfficientNet)
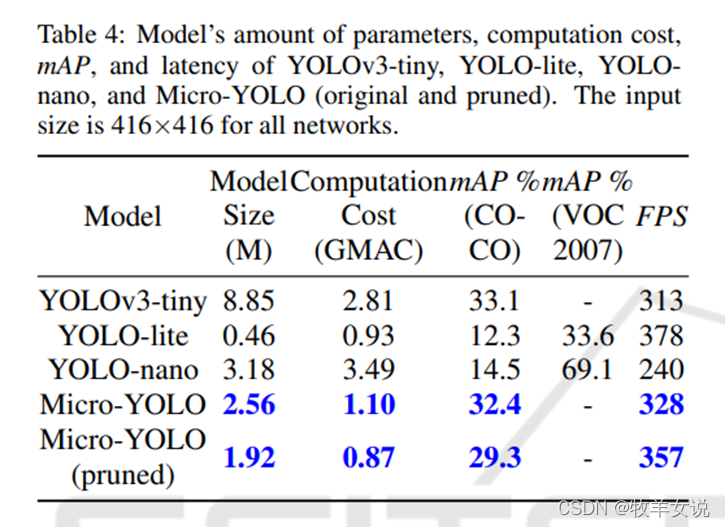
,并设计渐进式通道级剪枝算法以最小化数量参数并最大化检测性能。
该网络尚未找到开源实现。
论文地址:
https://www.scitepress.org/Papers/2021/102344/102344.pdf
Micro-YOLO模型的参数量、乘加数可参见下表:
3. NanoDet
NanoDet是一款超快速、高精度、anchor-free的轻量级检测网络,可实现在移动设备上的实时运行。主要面向工程应用,暂未有论文发表。
工程链接:
GitHub – RangiLyu/nanodet: NanoDet-Plus
该网络具有如下特性:
- 超轻量级:模型文件只有0.98MB(INT8)或1.8MB(FP16);
- 推理速度快:在移动ARM CPU上可达到97fps,即每帧10.23ms的推理速度;
- 高精度:CPU实时推理下最高可达34.3 mAPval@0.5:0.95;
- 训练友好:比其他模型具有明显小的GPU memory消耗,在GTX1060 6G0上可做到batch-size=80;
- 方便部署:支持各种后端,包括ncnn、MNN和OpenVINO。并且提供了基于ncnn推理框架的Android演示。
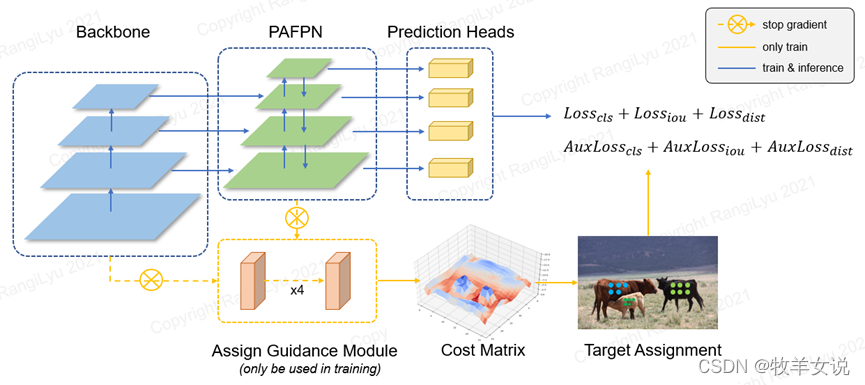
NanoDet-Plus在NanoDet基础上进行了更进一步的优化,增加了AGM(Assign Guidance Module) 和DSLA(Dynamic Soft Label Assigner)模块,使精度在COCO dataset上有了7个点的 mAP提升(与NanoDet相比提升了30%左右),且使得训练和部署更容易。
NanoDet-Plus整体架构图:
模型表现对比:
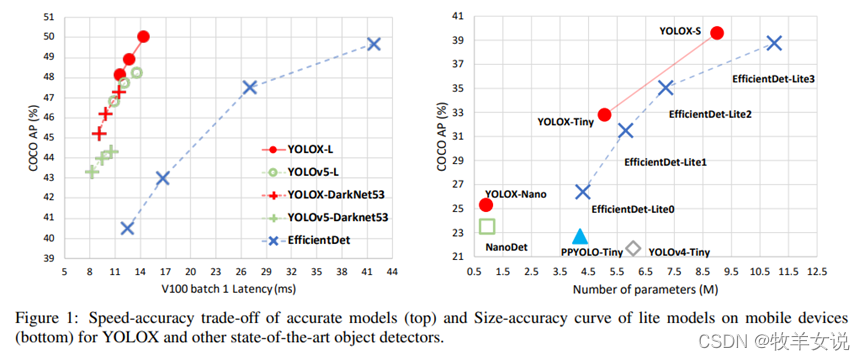
4. YOLOX-Nano
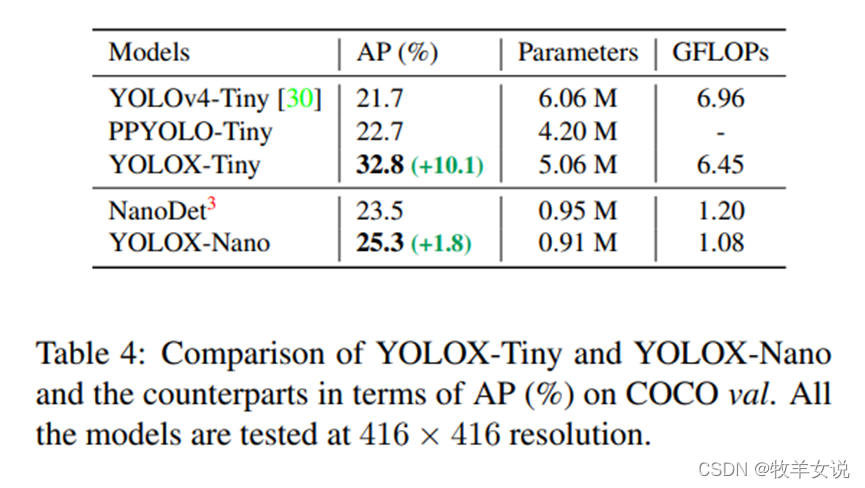
YOLOX是在YOLO系列的基础上进行了若干改进生成的新的高性能检测器。要点包括:(1) Anchor-free的检测方式;(2) 检测头解耦;(3) 先进的标签分配策略SimOTA;(4)强数据增广;(5) Multi positives。其中,YOLOX-Nano只有0.91M的参数量和1.08G FLOPs,在COCO数据集上获得了25.3%的mAP,比NanoDet高1.8% mAP。
论文地址:
https://arxiv.org/abs/2107.08430
代码地址:
https://github.com/Megvii-BaseDetection/YOLOX
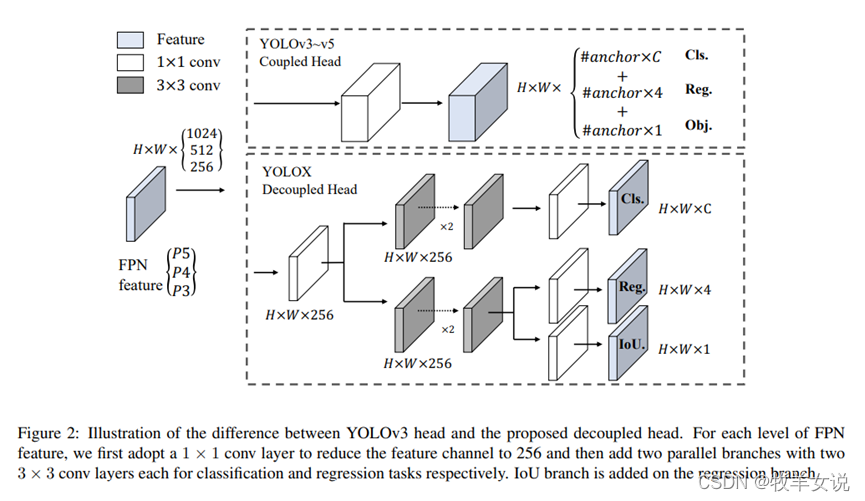
下图给出了YOLO和YOLOX在检测头结构上的区别:
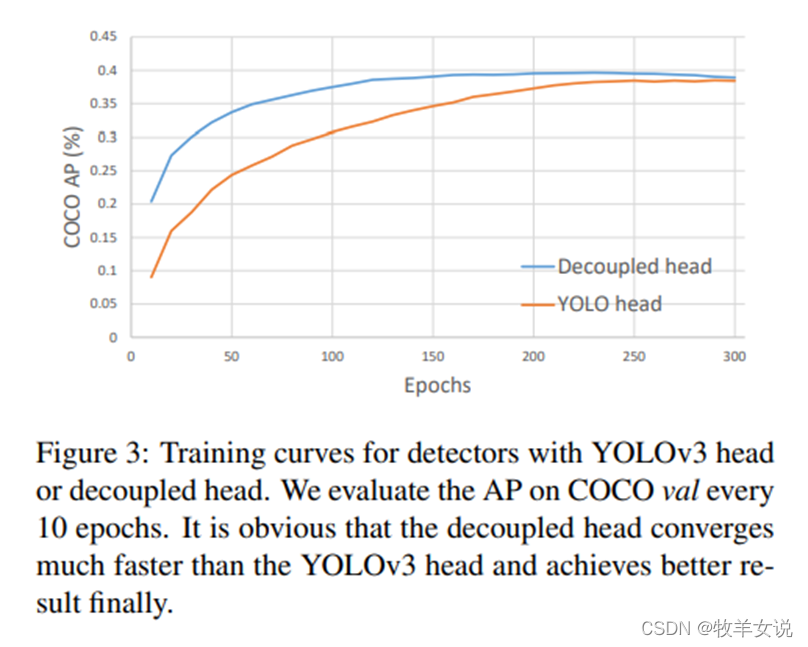
两种检测头在训练时的收敛情况如下图所示:
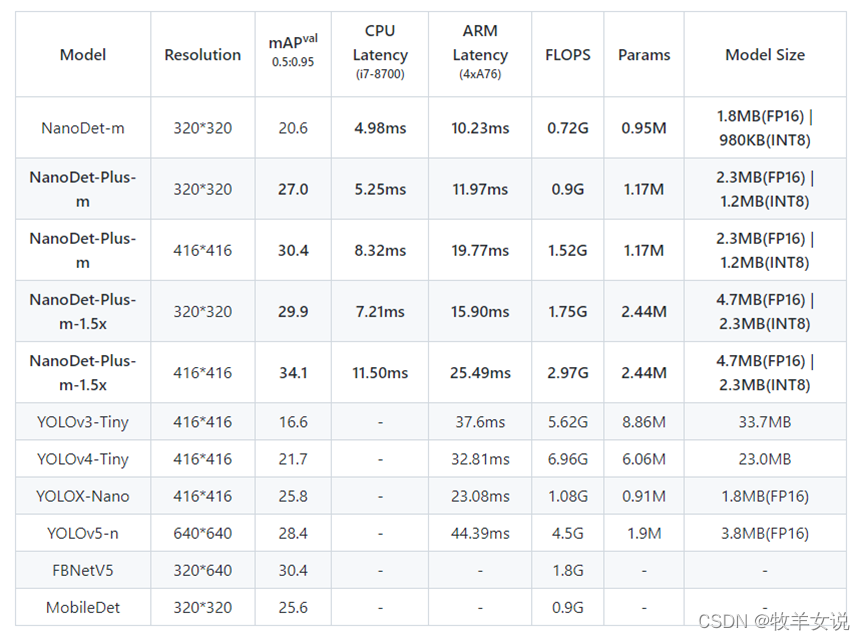
论文中给出了YOLOX-Nano与其他轻量级网络的对比。
更多图形化对比:
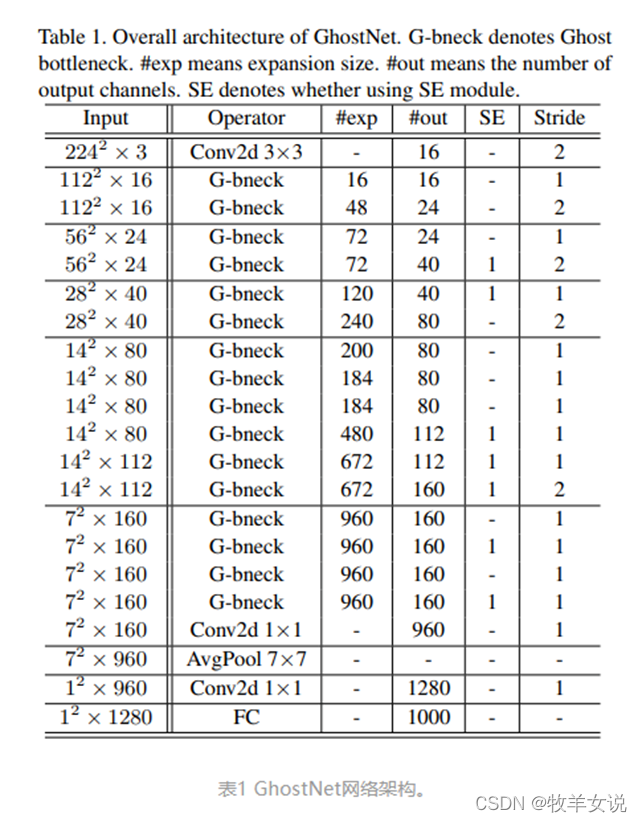
5. 华为GhostNet
GhostNet
通过
Ghost
模块构建高效的神经网络结构,从而减少神经网络的计算成本。
Ghost
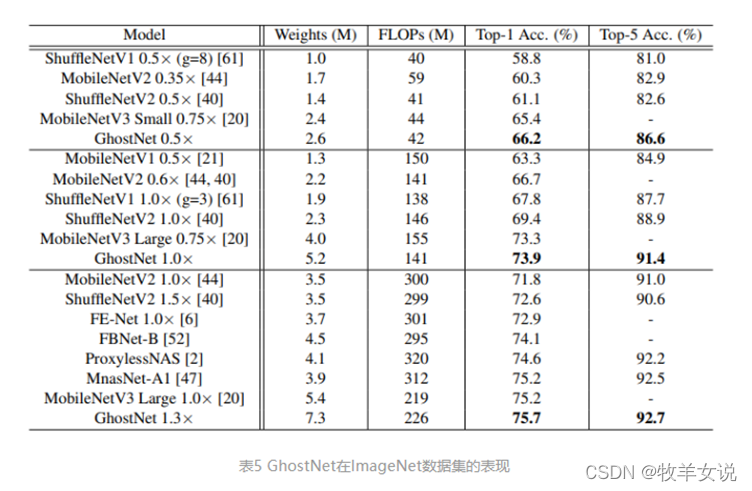
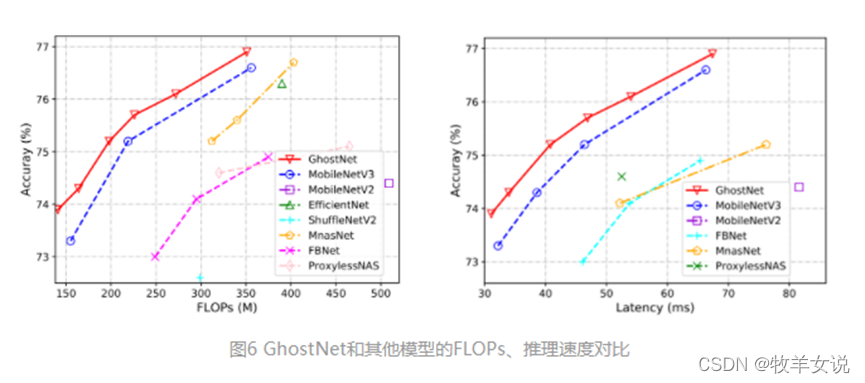
模块将原始卷积层分为两部分,首先使用较少的卷积核来生成原始特征图,然后,进一步使用廉价变换操作以高效生产更多幻影特征图。在基准模型和数据集上进行的实验表明,该方法是一个即插即用的模块,能够将原始模型转换为更紧凑的模型,同时保持可比的性能。此外,在效率和准确性方面,使用提出的新模块构建的
GhostNet
均优于最新的轻量神经网络,如
MobileNetV3
。
论文地址:
https://arxiv.org/pdf/1911.11907.pdf
代码地址:
GhostNet
6. YOLOv5
代码地址:
YOLOv5
YOLOv5是一系列目标检测架构的合集,其
高精度、低耗时、易训练、易部署、好上手等特点,让
YOLOv5
的热度一举超过
YOLOv4
,成为当前目标检测界的主流。并且作者也一直在维护,新版本精度越来越高、速度越来越快、模型越来越小,截至目前为止,
YOLOv5
已经迭代到了第六个版本。为了应对移动端的部署应用,作者推出了
YOLOv5
的
n
版本,其参数量只有
1.9M
,在
COCO val2007 dataset
上的
mAP
精度也达到了
28.4
,而
YOLOv5n6
在
YOLOv5n
的基础上,
mAP
又有所提升,达到了
34
,同时模型参数量提升到
3.2M
。
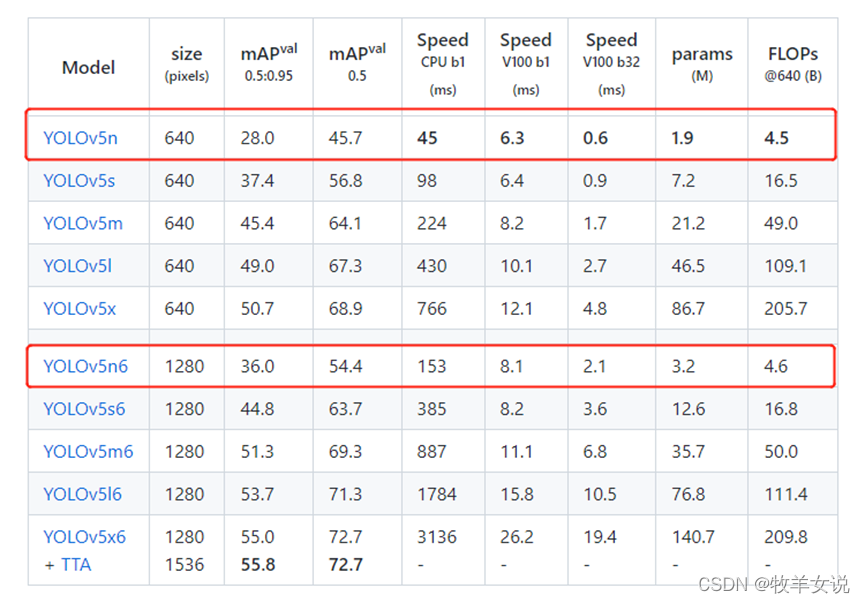
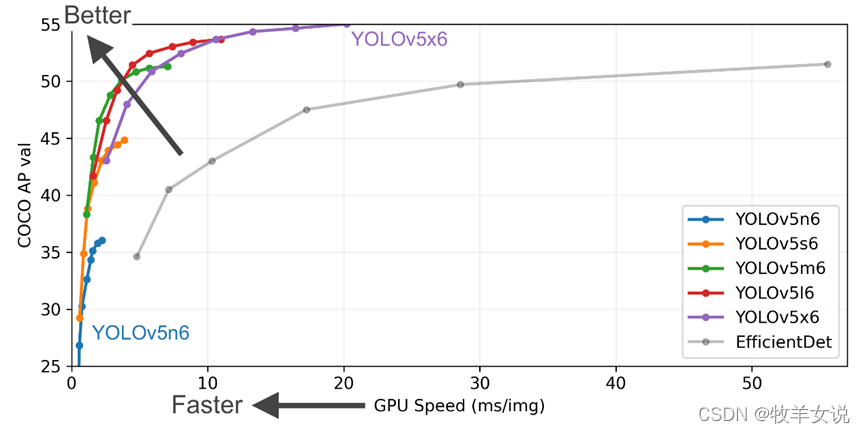
推理和精度:
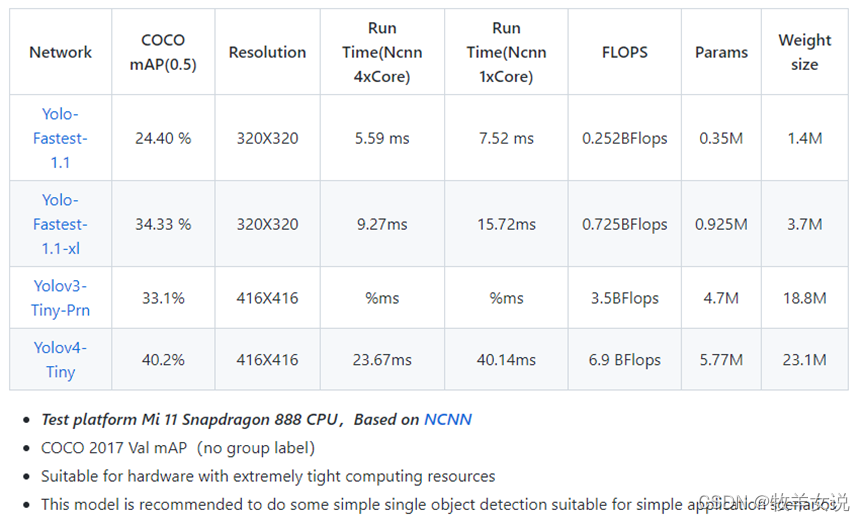
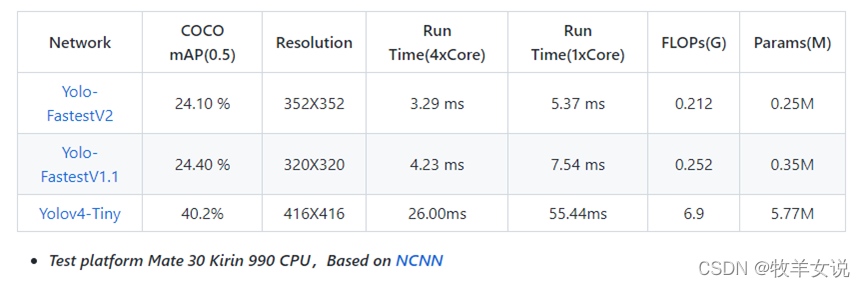
7. YOLO-Fastest
Yolo-Fastest注重的是单核的实时推理性能,在满足实时的条件下的低CPU占用。目前Yolo-Fastest更新到了V2版本。
工程地址:
模型特点:
- 简单、快速、紧凑、易于移植;
- 占用资源少,单核性能优异,功耗低;
- 基于yolo的已知最快最小通用目标检测算法;
- 适用于所有平台的实时目标检测算法;
- ARM移动终端优化设计,优化支持NCNN推理框架。
- 训练速度快,计算能力要求低,训练只需要3GB视频内存,gtx1660ti训练COCO 1 epoch只需4分钟。
V2版本相对于V1版本更快更小:以0.3%的精度损失换取30%的推理速度提高,参数数量减少25%。
数据对比:
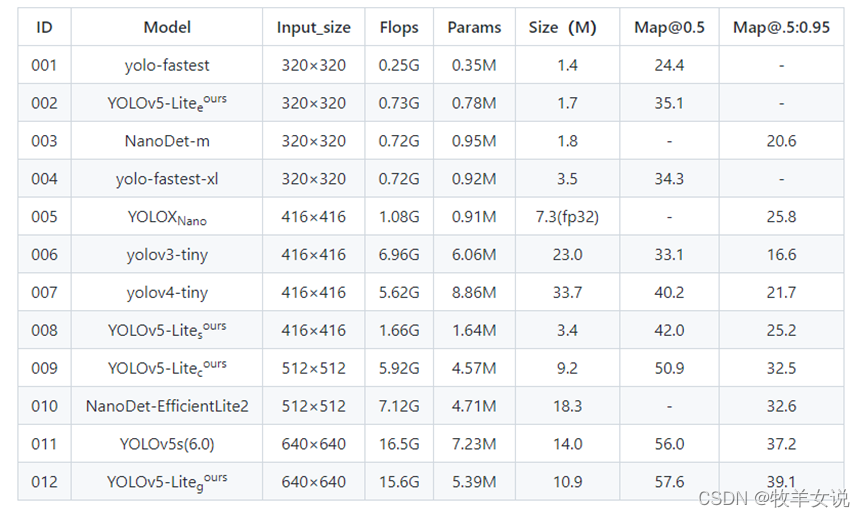
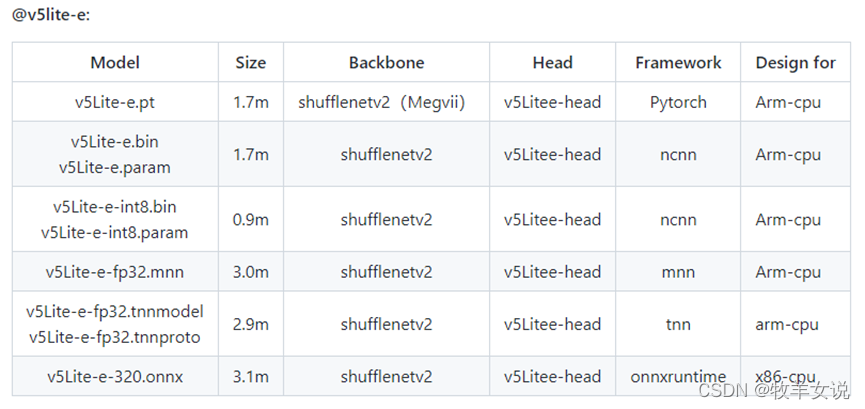
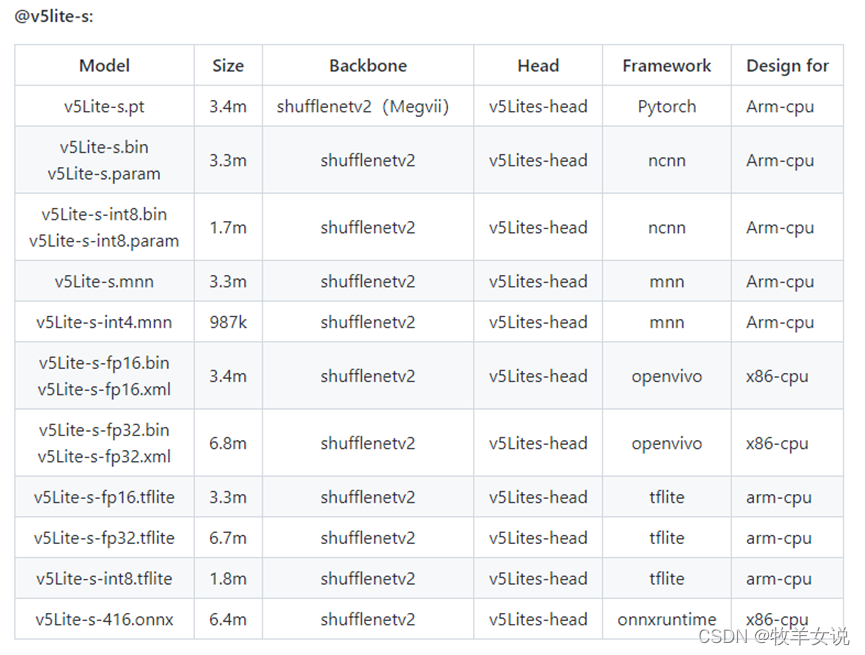
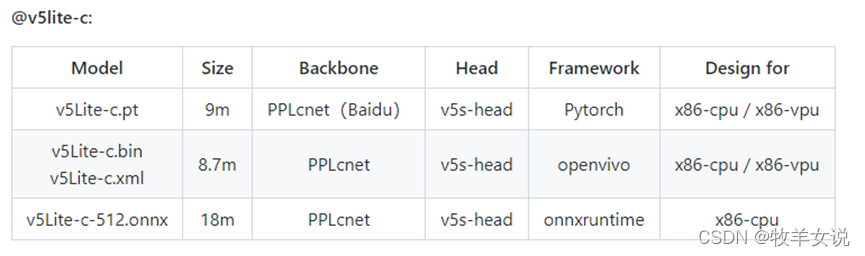
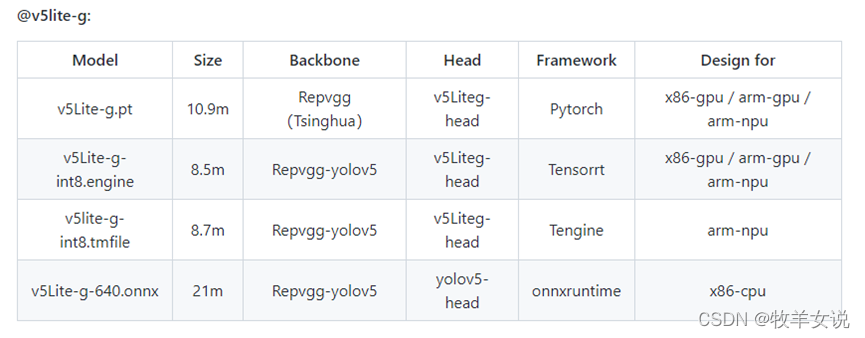
8. YOLOv5-Lite
YOLOv5-Lite为轻量型的YOLOv5改进版本,整体算法与YOLOv5基本一致,通过修改了YOLOv5的backbone达到模型压缩的目的。根据不同的backbone分别提供了e、s、c、g版本,e版本的backbone为shufflenetv2,s版本的backbone也是shufflenetv2 (与e版本的head不同),c版本的backbone为PPLcnet,g版本的backbone为Repvgg。
工程地址:
YOLOv5-Lite
与各个轻量级算法的精度对比:
各模型的backbone、head以及适用的平台可参加下面几个表:
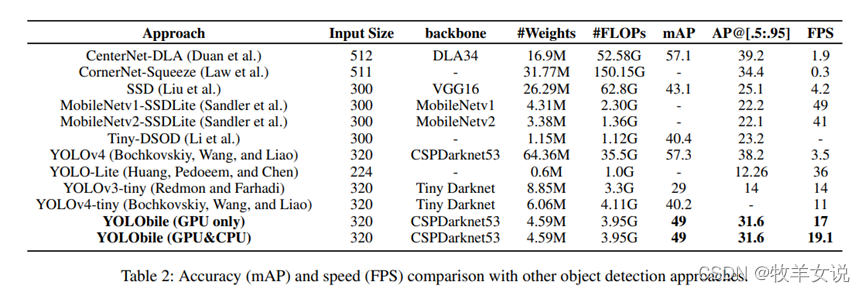
9. YOLObile
YOLObile,顾名思义,是一种适用于移动设备的轻量级网络,从压缩、编译两个角度,在保证模型准确率的基础上,减少模型的大小,并提升模型在移动设备端的运行速度。新的YOLObile framework将YOLOv4压缩了14倍,准确率保持在49.0mAP。
论文地址:
https://arxiv.org/pdf/2009.05697.pdf
代码地址:
YOLObile
YOLObile使用了一种新的block-punched剪枝技术,并且为了提高在移动设备上的计算效率,采用了GPU-CPU协作方案以及高级编译器辅助优化。YOLObile在三星Galaxy S20 GPU上达到17FPS的帧率,使用GPU-CPU协作方案可将帧率提升至19.1 FPS,比YOLOv4的速度提升了5倍。
YOLObile与其他模型在精度和速度上的对比:
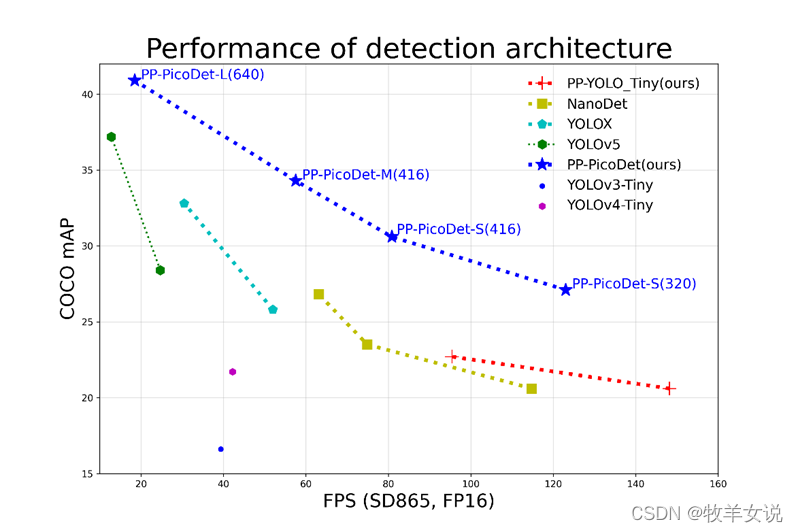
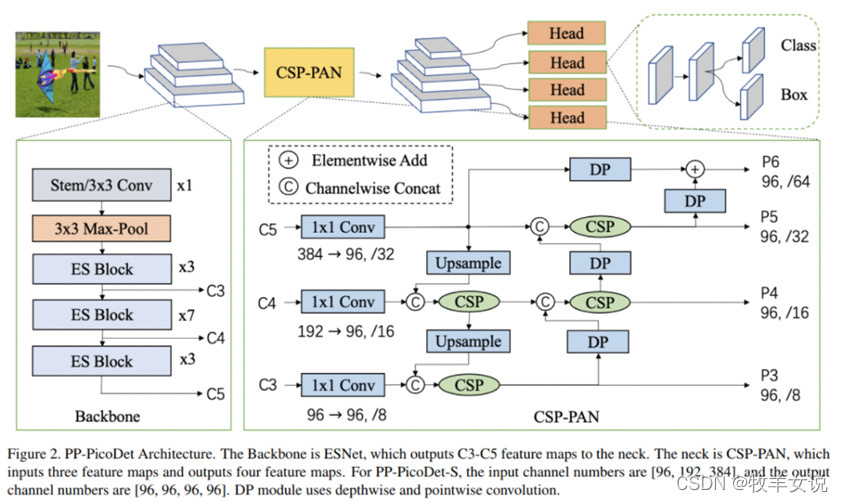
10. PP-PicoDet
PP-PicoDet是基于百度PaddleDetection提出的面向移动端和CPU的轻量级检测模型,在移动设备上具有卓越的性能,成为全新的SOTA轻量级模型,并且一直在更新维护,最新的版本发布于2022年3月20日。
论文地址:
https://arxiv.org/abs/2111.00869
工程链接:
PaddlePaddle/PaddleDetection
PP-PicoDet模型具有如下特点:
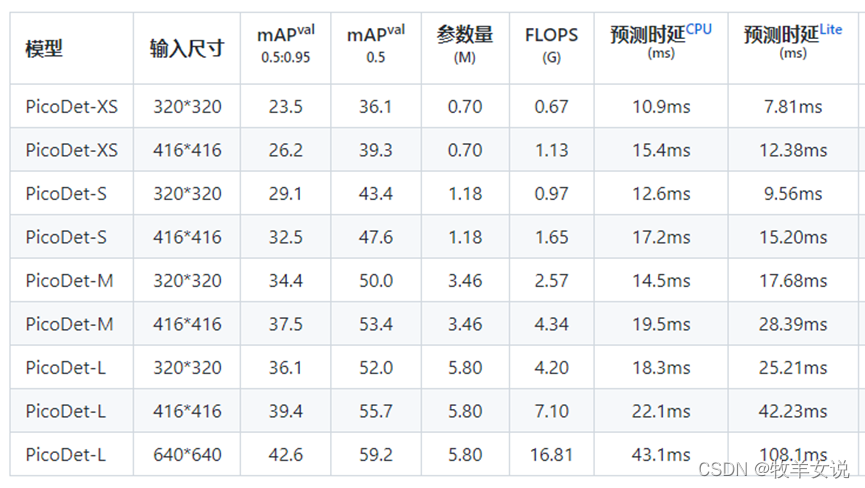
- 更高的mAP,参数量在1M以内,在输入像素416×416时,mAP超过30;
- 更快的预测速度,在ARM CPU上可达到150FPS;
- 部署友好,支持PaddleLite、MNN、MCNN、OpenVINO等平台,支持转换ONNX,并且提供了C++/Python/Android的Demo;
- 算法创新,在现有SOTA算法上进行了优化,包括ESNet、CSP-PAN、SimOTA等。
模型架构:
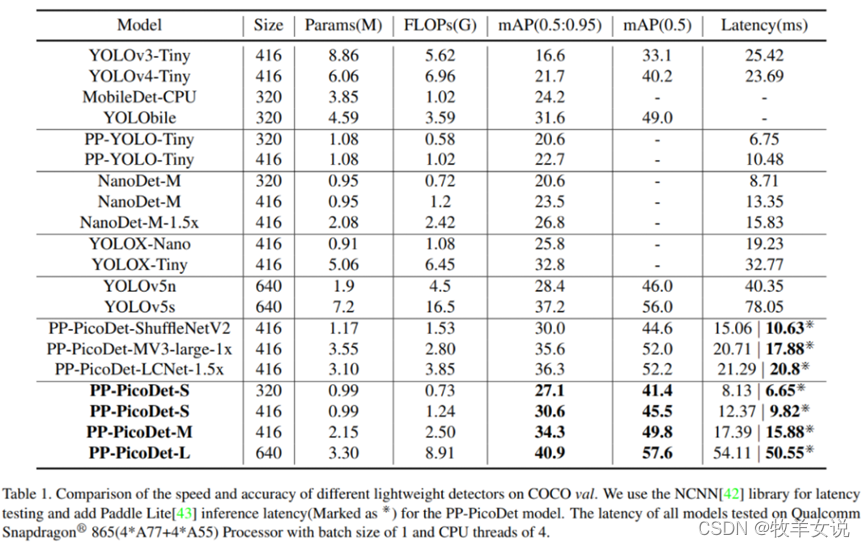
模型参数量、FLOPs等数据如下表所示:
更多模型对比:
各移动端模型在COCO数据集上精度mAP和高通骁龙865处理器上预测速度(FPS)对比图: