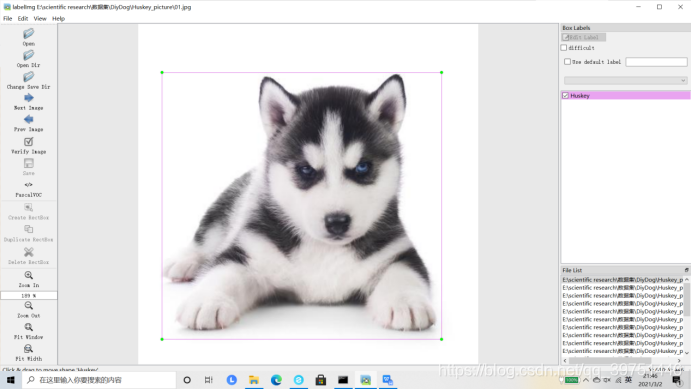
darknet入门:从训练到测试
一.获取训练集的txt.xml文件(yolo存储txt格式,voc存储xml格式)
注意尽量第一次就按顺序命名文件
二、新建文件夹与数据整理
(1)在如图所示对应路径下新建VOCdevkit文件夹
\darknet(Mask)\darknet\scripts

(2)在VOCdevkit文件夹下创建两个文件夹:JEPGImages和VOC2019

1)将训练图片全部放到JPEGImages文件夹中
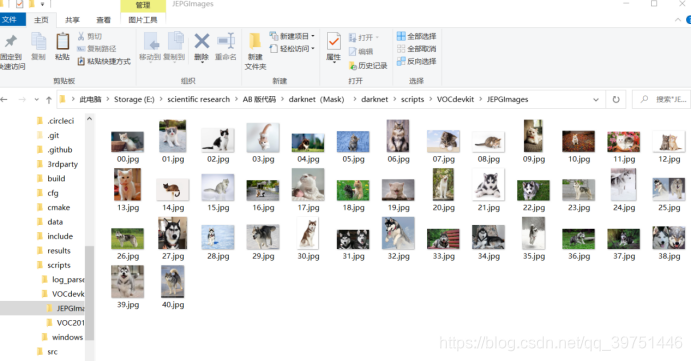
2)在VOC2019文件夹下再新建三个文件夹:Annotations;labels;ImageSets

2.1)将之前生成的.xml文件放入Annotations文件夹
2.2)将之前生成的.txt文件放入labels文件夹
2.3)在ImageSets文件夹下再新建一个文件夹Main
并在main文件夹下新建两个文本文档
(3)在darknet(Mask)\darknet\scripts文件夹下新建get_train_test.py,运行如下代码,得到train.txt和val.txt。这里明显file_num<776,所以val.txt不会有数据。
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder = 'E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\JEPGImages'
dest = 'E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC2019\\ImageSets\\Main\\train.txt'
dest2 = 'E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC2019\\ImageSets\\Main\\val.txt'
file_list = os.listdir(source_folder)
train_file = open(dest, 'a')
val_file = open(dest2, 'a')
for file_obj in file_list:
file_path = os.path.join(source_folder, file_obj)
file_name, file_extend = os.path.splitext(file_obj)
file_num = int(file_name)
if (file_num < 776):
train_file.write(file_name + '\n')
else:
val_file.write(file_name + '\n')
train_file.close()
val_file.close()
得到的train.txt文件:
(4)修改E:\scientific research\AB 版代码\darknet(Mask)\darknet\scripts路径下 voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2019', 'train'), ('2019', 'val')]#sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["Huskey", "cat"]#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC%s\\Annotations\\%s.xml'%(year, image_id))
out_file = open('E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\'%(year)):
os.makedirs('E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\'%(year))
image_ids = open('E:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC%s\\ImageSets\\Main\\%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%sE:\\scientific research\\AB 版代码\\darknet(Mask)\\darknet\\scripts\\VOCdevkit\\VOC%s\\JPEGImages\\%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2019_train.txt 2019_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
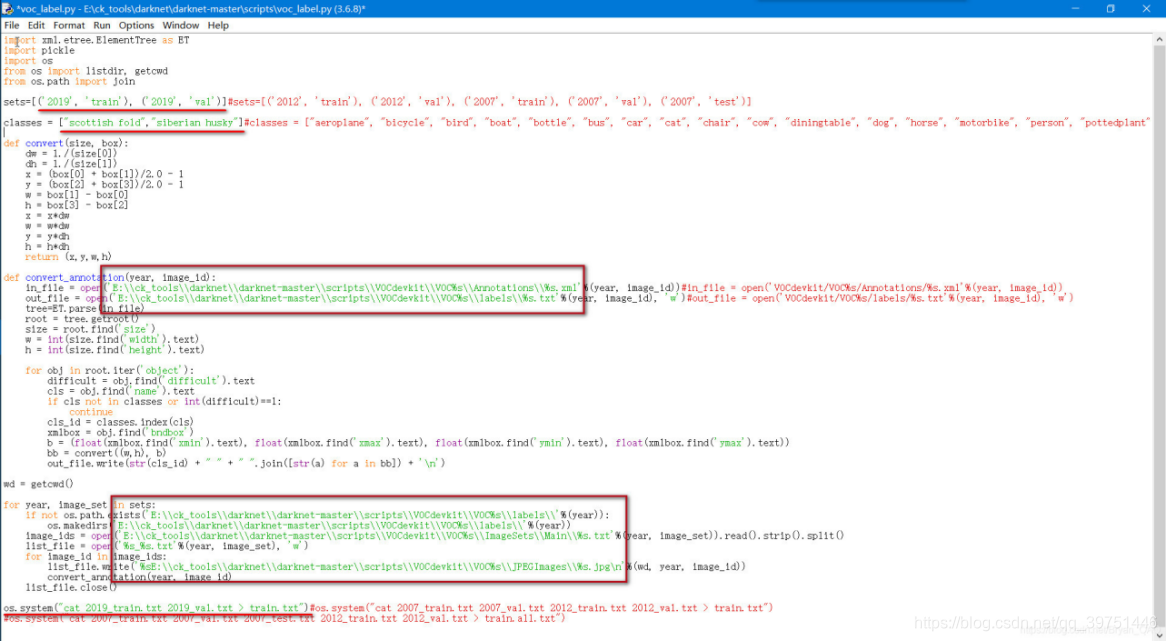
(5)运行 voc_label.py,得\darknet(Mask)\darknet\scripts下到如下三个文件


(6)在如下darknet(Mask)\darknet\build\darknet\x64\data路径新建两个文件夹:obj;weights并将之前的训练图片样本和对应的txt文件放入obj文件夹;weights文件夹用来存放之后训练生成的权重文件
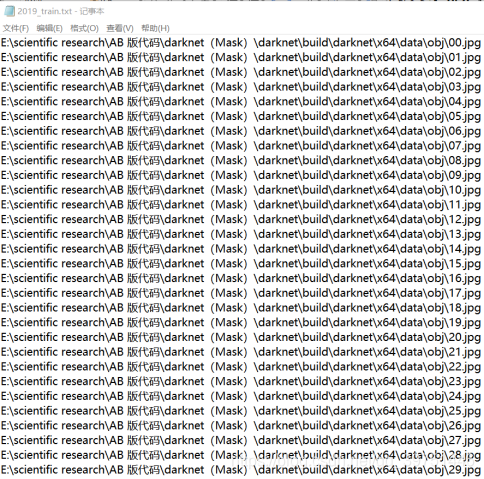
(7)修改2019_train.txt和2019_val.txt(2019_val.txt为空不用修改),改为obj中图片的绝对路径。
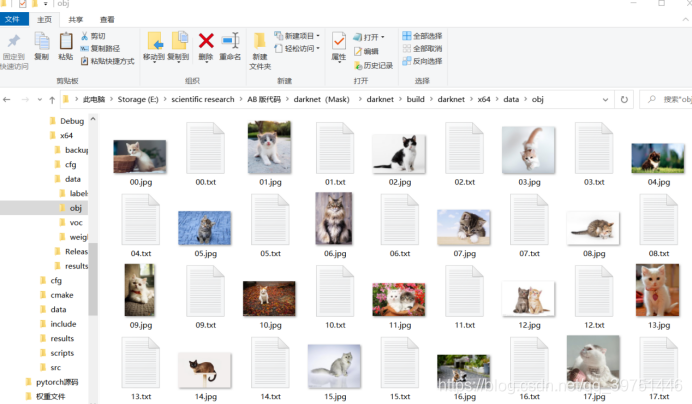
(8)修改2019_train.txt和2019_val.txt(2019_val.txt为空不用修改),改为obj中图片的绝对路径。
并把2019_train.txt复制到如下路径:
E:\scientific research\AB 版代码\darknet(Mask)\darknet\build\darknet\x64\data
三、修改文件
(1)darknet(Mask)\darknet\build\darknet\x64\data修改
voc.data
classes= 2
train = data/2019_train.txt
valid = data/2019_val.txt
names = data/voc.names
backup = data/weights
(2)darknet(Mask)\darknet\build\darknet\x64\data修改voc.names
cat
Huskey
(3)darknet(Mask)\darknet\build\darknet\x64修改yolov3-voc.cfg
Max_batches大约为每个类2000步
一共要改三处这样的地方
,每处改如下两个参数,我这里类别数classes=2,filters=(classes+5)*3=21;

四、开始训练
(1)下载预训练的权重文件
(2)在如下路径打开cmd窗口,输入:
`darknet.exe detector train data\voc.data yolov3-voc.cfg darknet53.conv.74 data\weights`
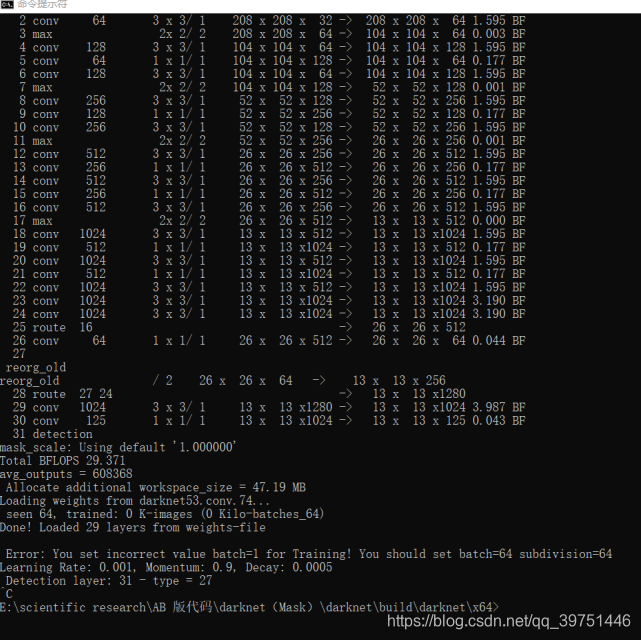
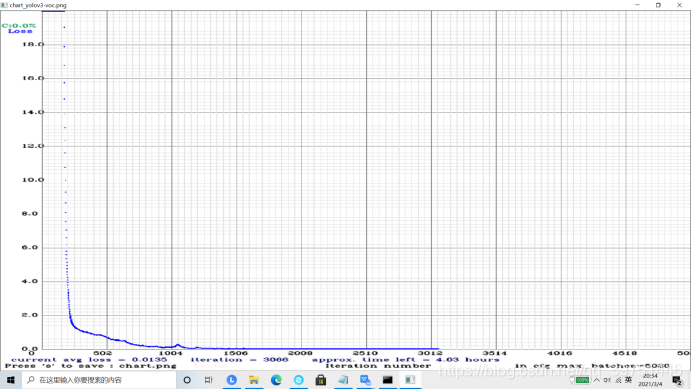
修改后继续运行如下,接下来就是等待。。。。。。
部分参数指标 :
Avg IOU:当前迭代中,预测的box与标注的box的平均交并比。越接近于1越优。
Class:标注物体的分类准确率。越接近于1越优。
Obj:越接近于1越优。
No Obj:越接近于0越优。
五、结果测试
(1)训练结果如下图所示,我就训练到这里了。
(2)在weights文件夹下生成了相应的权重,(\darknet\build\darknet\x64\data\weights)并将迭代2000次的权重拷贝到如下目录:\darknet\build\darknet\x64
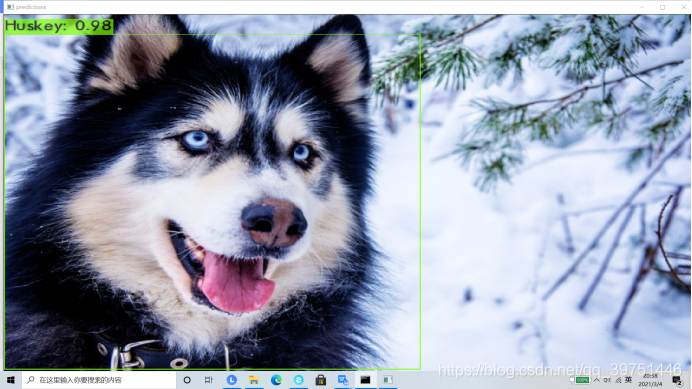
(3)准备测试图片进行测试
1)测试图片
保存在\darknet\build\darknet\x64\data\testimgs
测试 打开cmd窗口,输入 >darknet.exe detector test data\voc.data yolov3-voc.cfg yolov3-voc_2000.weights -thresh 0.8
测试:输入文件路径:data/testimgs/0001.jpg
按回车进行下一次检测
3)测试结果
参考:
https://pjreddie.com/darknet/yolo/
https://blog.csdn.net/Bryan_QAQ/article/details/90789549?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161467874216780271513221%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=161467874216780271513221&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2
all
sobaiduend~default-4-90789549.first_rank_v2_pc_rank_v29&utm_term=darknet%E8%AE%AD%E7%BB%83%E8%87%AA%E5%B7%B1%E7%9A%84%E6%95%B0%E6%8D%AE%E9%9B%86