十五、线程池(ThreadPool)
1. 自定义线程池
public class TestPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(1, 1000, TimeUnit.MILLISECONDS, 1, (queue, task) -> {
// 队列满时可选操作:
// 1.死等
// queue.put(task);
// 2.带超时的等待
// queue.offer(task, 1500, TimeUnit.MILLISECONDS);
// 3.调用者放弃任务执行 什么都不写,就放弃执行
// 4.抛出异常
// throw new RuntimeException("任务执行失败" + task);
// 5.调用者自己执行任务
task.run();
});
for (int i = 0; i < 4; i++) {
int j = i;
threadPool.execute(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(j);
});
}
}
}
// 拒绝策略
@FunctionalInterface
interface RejectPolicy<T> {
void reject(BlockingQueue<T> queue, T task);
}
// 线程池
class ThreadPool {
// 任务队列
private BlockingQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet<>();
// 核心线程数
private int coreSize;
// 获取任务的超时时间
private long timeout;
private TimeUnit timeUnit;
// 拒绝策略
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapcity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapcity);
this.rejectPolicy = rejectPolicy;
}
// 执行任务
public void execute(Runnable task) {
synchronized (workers) {
// 当任务数没有超过线程数时,交给 worker 对象执行
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
System.out.println("新增线程worker: " + worker + "任务对象: " + task);
workers.add(worker);
worker.start();
} else {
// 如果任务数超过线程数时,就加入任务队列暂存
// taskQueue.put(task);
// 队列满时可选操作:
// 1.死等
// 2.带超时的等待
// 3.调用者放弃任务执行
// 4.抛出异常
// 5.调用者自己执行任务
taskQueue.tryPut(rejectPolicy, task);
}
}
}
// 线程类
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// 当task不为空,执行任务
// task执行结束后,从任务队列再获取任务并执行
// 设置超时等待,超过时间没有任务,就将线程结束
while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {
try {
System.out.println("正在执行: " + task);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
task = null;
}
}
synchronized (workers) {
System.out.println("worker被移除: " + this);
workers.remove(this);
}
}
}
}
// 阻塞队列
class BlockingQueue<T> {
// 任务队列
private Deque<T> queue = new ArrayDeque<>();
// 锁
private ReentrantLock lock = new ReentrantLock();
// 生产者条件变量
private Condition fullWaitSet = lock.newCondition();
// 消费者条件变量
private Condition emptyWaitSet = lock.newCondition();
// 容量上限
private int capcity;
public BlockingQueue(int capcity) {
this.capcity = capcity;
}
// 带超时的阻塞获取
public T poll(long timeout, TimeUnit unit) {
lock.lock();
try {
// 将timeout同一转换为 纳秒
long nanos = unit.toNanos(timeout);
// 如果队列为空,则需要等待添加
while (queue.isEmpty()) {
try {
if (nanos <= 0) return null;
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 队列不为空,跳出循环,从头取出元素
T element = queue.removeFirst();
fullWaitSet.signal();
return element;
} finally {
lock.unlock();
}
}
// 带超时的阻塞添加
public boolean offer(T task, long timeout, TimeUnit unit) {
lock.lock();
try {
long nanos = unit.toNanos(timeout);
// 如果队列已经满了,就需要等待被消费
while (queue.size() == capcity) {
try {
System.out.println("等待加入任务队列:...... " + task);
if (nanos <= 0) return false;
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 队列不满,跳出循环,在队尾添加元素
System.out.println("加入任务队列: " + task);
queue.addLast(task);
emptyWaitSet.signal();
return true;
} finally {
lock.unlock();
}
}
// 阻塞获取
public T take() {
lock.lock();
try {
// 如果队列为空,则需要等待添加
while (queue.isEmpty()) {
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 队列不为空,跳出循环,从头取出元素
T element = queue.removeFirst();
fullWaitSet.signal();
return element;
} finally {
lock.unlock();
}
}
// 阻塞添加
public void put(T task) {
lock.lock();
try {
// 如果队列已经满了,就需要等待被消费
while (queue.size() == capcity) {
try {
System.out.println("等待加入任务队列:...... " + task);
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 队列不满,跳出循环,在队尾添加元素
System.out.println("加入任务队列: " + task);
queue.addLast(task);
emptyWaitSet.signal();
} finally {
lock.unlock();
}
}
// 获取队列大小
public int size() {
lock.lock();
try {
return queue.size();
} finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
// 判断队列是否已满
if (queue.size() == capcity) {
rejectPolicy.reject(this, task);
} else { // 队列还有空闲
System.out.println("加入任务队列: " + task);
queue.addLast(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
}
2. ThreadPoolExecutor
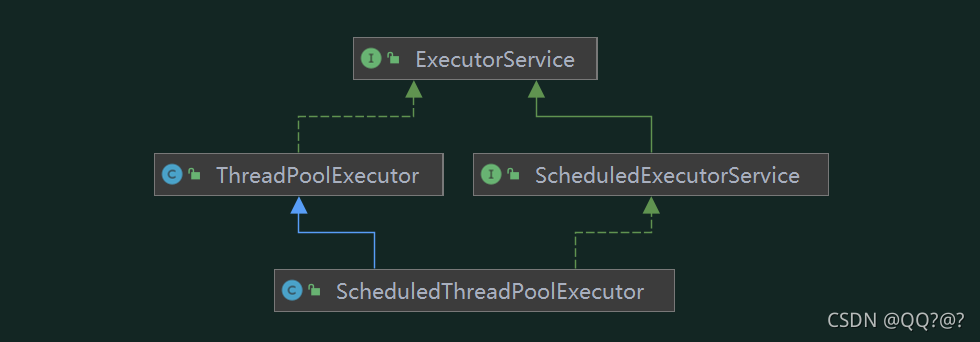
1. 线程池状态
ThreadPoolExecutor 使用 int 的
高 3 位
来表示
线程池状态
,
低 29 位
表示
线程数量
| 状态名 | 高3位 | 接受新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| RUNNING | 111 | Y | Y | 正常运行 |
| SHUTDOWN | 000 | N | Y | 不会接收新任务,但会处理阻塞队列剩余任务 |
| STOP | 001 | N | N | 会中断正在执行的任务,并抛弃阻塞队列任务 |
| TIDYING | 010 | – | – | 任务全执行完毕,活动线程为 0 即将进入终结 |
| TERMINATED | 011 | – | – | 终结状态 |
这些状态均由int型表示,大小关系为 RUNNING<SHUTDOWN<STOP<TIDYING<TERMINATED,这个顺序基本上也是遵循线程池从 运行 到 终止这个过程。
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值
2. 构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
解释:
>corePoolSize 核心线程数目 (最多保留的线程数)
maximumPoolSize 最大线程数目
keepAliveTime 生存时间 – 针对救急线程(救急线程数 = 最大线程数目 – 核心线程数目)
unit 时间单位 – 针对救急线程
workQueue 阻塞队列
threadFactory 线程工厂 – 可以为线程创建时起个好名字
handler 拒绝策略
工作流程(重点)
- 线程池中最开始没有线程(懒创建),当一个任务提交给线程池之后,线程池就会创建一个新线程来执行任务
- 添加任务,当线程数达到 corePoolSize(核心线程数) 时,代表没有线程空闲了,那么这时在加入任务,新加入的任务就会被加入到 workQueue 队列排队,直到有空闲的线程
- 如果队列选择了有界队列,那么当任务超过了队列的大小时,就会创建 maximumPoolSize – corePoolSize(最大线程数 – 核心线程数) 数目的救急线程来执行此时在加入的任务
-
如果线程数达到了 maximumPoolSize(救急线程 + 核心线程 即 最大线程数) 时,仍然有新任务加入,此时就会执行拒绝策略。JDK提供了4中拒绝策略的实现:
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
- 当高峰过去之后,超过 corePoolSize 的救急线程如果一段时间没有任务去做,就需要结束以节省资源,这个时间由 keepAliveTime 和 unit 来控制
3. JDK 实现的线程池
根据这个构造方法,JDK Executors 类中提供了许多工厂方法来创建各种用途的线程池
1. newFixedThreadPool(固定大小线程池)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点:
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
评价: 适用于任务量已知,相对耗时的任务
2. newCacheThreadPool(带缓存效果的线程池)
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着:全部都是救急线程(60s 后可以回收),且救急线程可以无限创建
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货);当任务被加入后,队列会被阻塞,只有当这个任务被取出时,才能有新的任务加入队列。
评价: 整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况
3. newSingleThreadPool(单线程的线程池)
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
newSingleThreadExecutor() 与 自己创建单线程 的区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池会在执行失败(异常,错误)后,立即创建一个新的线程,保证池的正常工作
newSingleThreadExecutor() 与 newFixedThreadPool(int 1) 的区别:
-
Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改:
FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用ThreadPoolExecutor 中特有的方法,如修改线程大小的 setCorePoolSize 等方法
-
Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改:
对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
使用场景:希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
4. 线程池的提交任务
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果(相比execute,增加了返回值)
// 返回值Future, 底层使用了保护性暂停模式,保证可以获取到结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
5. 任务提交源码解析
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// 方法:c & 高3位为1,低29位为0的~CAPACITY,用于获取高3位保存的线程池状态
runStateOf(int c)
// 方法:c & 高3位为0,低29位为1的CAPACITY,用于获取低29位的线程数量
workerCountOf(int c)
// 方法:参数rs表示runState,参数wc表示workerCount,即根据runState和workerCount打包合并成ctl
ctlOf(int rs, int wc) { return rs | wc; }
execute(Runnable command)方法
参数:
command 提交执行的任务,不能为空
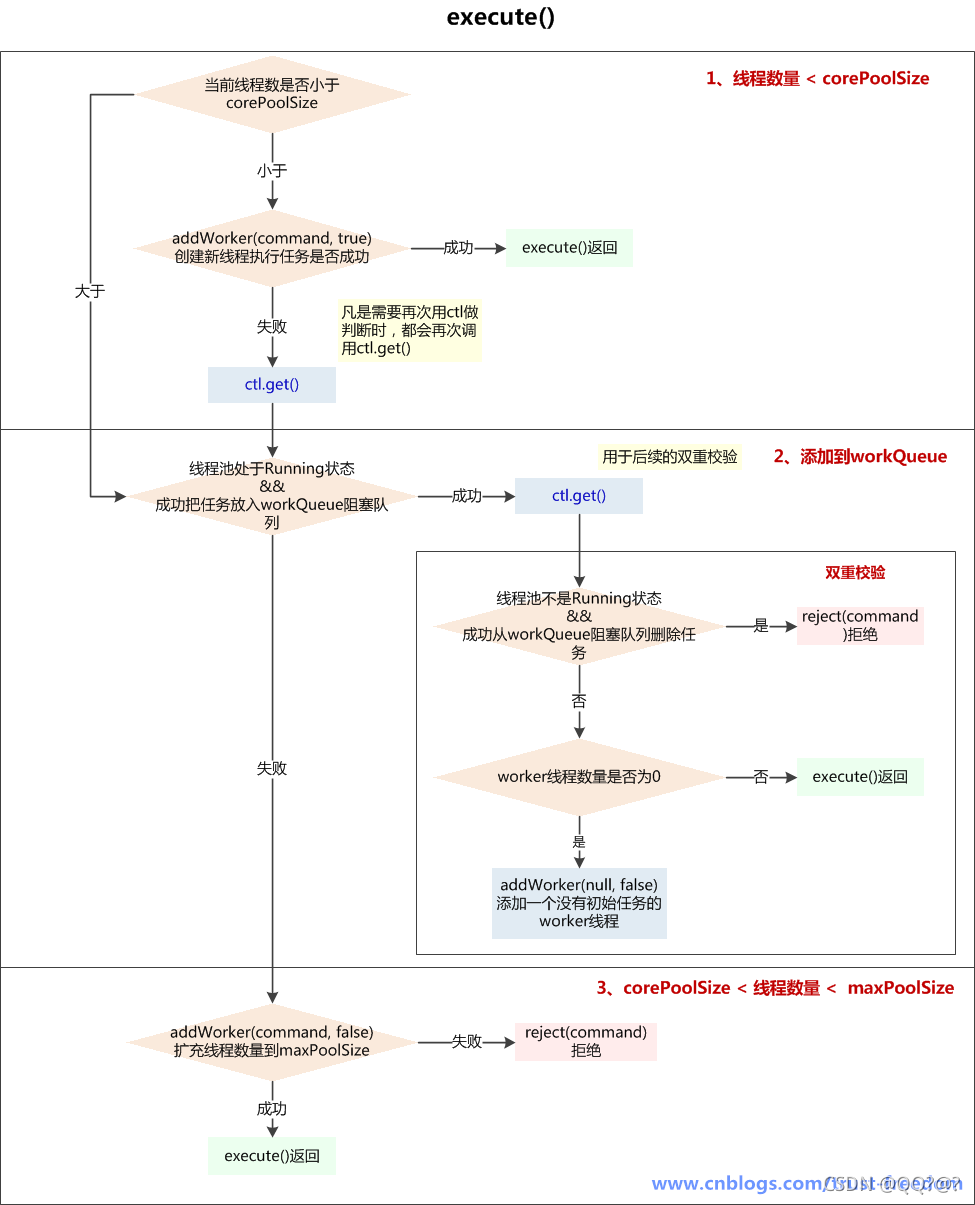
执行流程
:
-
如果线程池当前线程数量少于corePoolSize,则addWorker(command, true)创建新worker线程,如创建成功返回,如没创建成功,则执行后续步骤;
addWorker(command, true)失败的原因可能是:- A、线程池已经shutdown,shutdown的线程池不再接收新任务
- B、workerCountOf© < corePoolSize 判断后,由于并发,别的线程先创建了worker线程,导致workerCount>=corePoolSize
-
如果线程池还在running状态,将task加入workQueue阻塞队列中,如果加入成功,进行double-check,如果加入失败(可能是队列已满),则执行后续步骤;
double-check主要目的是判断刚加入workQueue阻塞队列的task是否能被执行- A、如果线程池已经不是running状态了,应该拒绝添加新任务,从workQueue中删除任务
- B、如果线程池是运行状态,或者从workQueue中删除任务失败(刚好有一个线程执行完毕,并消耗了这个任务),确保还有线程执行任务(只要有一个就够了)
- 如果线程池不是running状态 或者 无法入队列,尝试开启新线程,扩容至maxPoolSize,如果addWork(command, false)失败了,拒绝当前command
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
* 在未来的某个时刻执行给定的任务。这个任务用一个新线程执行,或者用一个线程池中已经存在的线程执行
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
* 如果任务无法被提交执行,要么是因为这个Executor已经被shutdown关闭,要么是已经达到其容量上限,任务会被当前的RejectedExecutionHandler处理
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
* 如果运行的线程少于corePoolSize,尝试开启一个新线程去运行command,command作为这个线程的第一个任务
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
* 如果任务成功放入队列,我们仍需要一个双重校验去确认是否应该新建一个线程(因为可能存在有些线程在我们上次检查后死了) 或者 从我们进入这个方法后,pool被关闭了
* 所以我们需要再次检查state,如果线程池停止了需要回滚入队列,如果池中没有线程了,新开启 一个线程
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
* 如果无法将任务入队列(可能队列满了),需要新开区一个线程(自己:往maxPoolSize发展)
* 如果失败了,说明线程池shutdown 或者 饱和了,所以我们拒绝任务
*/
int c = ctl.get();
// 1、如果当前线程数少于corePoolSize(可能是由于addWorker()操作已经包含对线程池状态的判断,如此处没加,而入workQueue前加了)
if (workerCountOf(c) < corePoolSize) {
// //addWorker()成功,返回
if (addWorker(command, true))
return;
/**
* 没有成功addWorker(),再次获取c(凡是需要再次用ctl做判断时,都会再次调用ctl.get())
* 失败的原因可能是:
* 1、线程池已经shutdown,shutdown的线程池不再接收新任务
* 2、workerCountOf(c) < corePoolSize 判断后,由于并发,别的线程先创建了worker线程,导致workerCount>=corePoolSize
*/
c = ctl.get();
}
// 2、使用线程失败,尝试加入队列,如果线程池RUNNING状态,且入队列成功
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get(); // 再次校验位
/**
* 再次校验放入workerQueue中的任务是否能被执行
* 1、如果线程池不是运行状态了,应该拒绝添加新任务,从workQueue中删除任务
* 2、如果线程池是运行状态,或者从workQueue中删除任务失败(刚好有一个线程执行完毕,并消耗了这个任务),确保还有线程执行任务(只要有一个就够了)
*/
//如果再次校验过程中,线程池不是RUNNING状态,并且remove(command)--workQueue.remove()成功,拒绝当前command
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果当前worker数量为0,通过addWorker(null, false)创建一个线程,其任务为null
// 为什么只检查运行的worker数量是不是0呢?? 为什么不和corePoolSize比较呢??
// 只保证有一个worker线程可以从queue中获取任务执行就行了??
// 因为只要还有活动的worker线程,就可以消费workerQueue中的任务
else if (workerCountOf(recheck) == 0)
// 第一个参数为null,说明只为新建一个worker线程,没有指定firstTask
// 第二个参数为true代表占用corePoolSize,false占用maxPoolSize
addWorker(null, false);
}
/**
* 3、如果线程池不是running状态 或者 无法入队列
* 尝试开启新(救急线程)线程,扩容至maxPoolSize,如果addWork(command, false)失败了,拒绝当前command
*/
else if (!addWorker(command, false))
reject(command);
}
addWorker(firstTask, core)方法
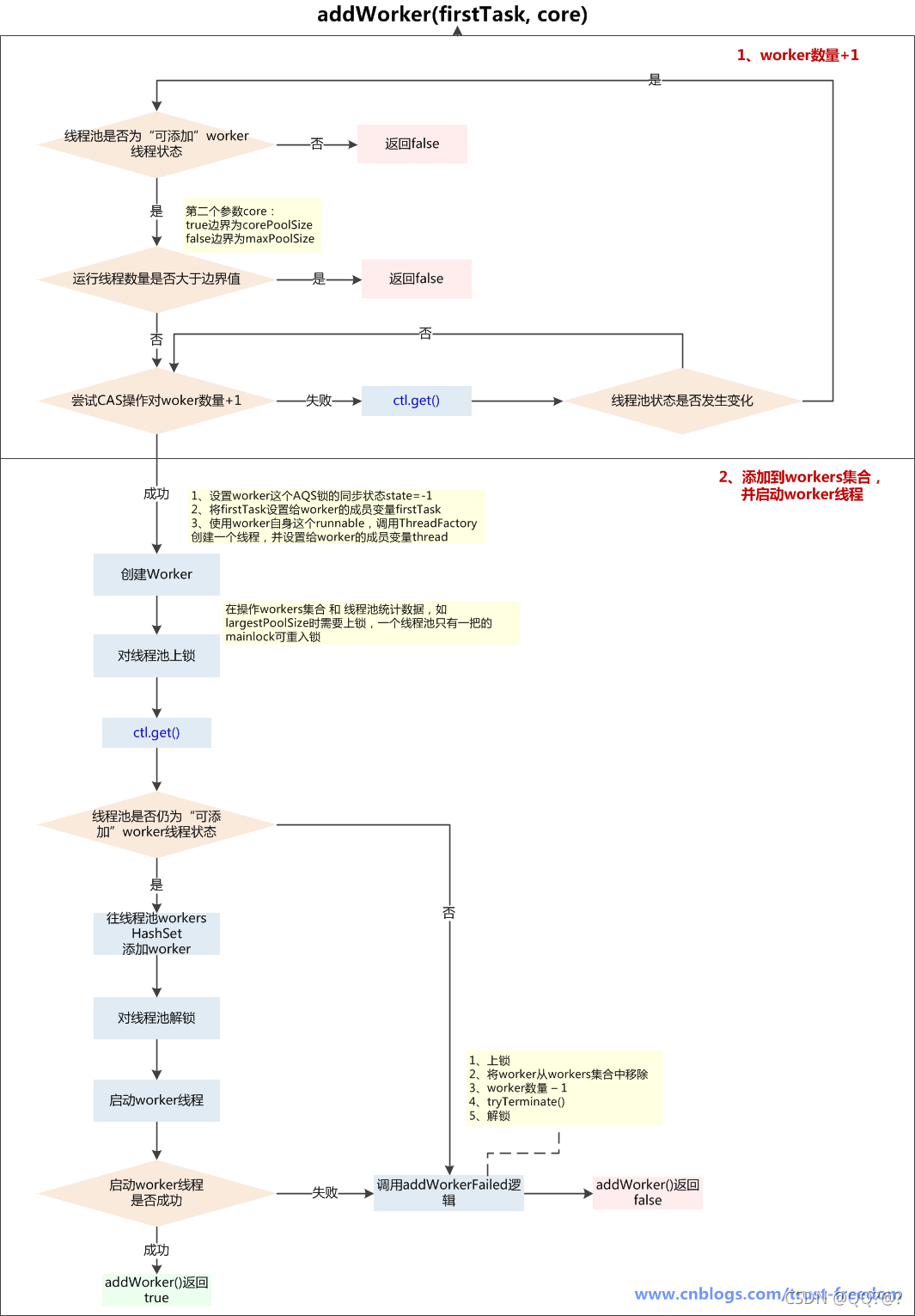
参数:
firstTask: worker线程的初始任务,可以为空
core: true:将corePoolSize作为上限,false:将maximumPoolSize作为上限
addWorker方法有4种传参的方式:
1.addWorker(command, true)
2.addWorker(command, false)
3.addWorker(null, false)
4.addWorker(null, true)
在execute方法中就使用了前3种,结合这个核心方法进行以下分析
第一个:线程数小于corePoolSize时,放一个需要处理的task进Workers Set。如果Workers Set长度超过corePoolSize,就返回false
第二个:当队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize。如果线程池也满了的话就返回false
第三个:放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务
第四个:这个方法就是放一个null的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行
执行流程:
-
判断线程池当前是否为可以添加worker线程的状态,可以则继续下一步,不可以return false:
- A、线程池状态>shutdown,可能为stop、tidying、terminated,不能添加worker线程
- B、线程池状态==shutdown,firstTask不为空,不能添加worker线程,因为shutdown状态的线程池不接收新任务
- C、线程池状态== shutdown,firstTask ==null,workQueue为空,不能添加worker线程,因为firstTask为空是为了添加一个没有任务的线程再从workQueue获取task,而workQueue为空,说明添加无任务线程已经没有意义
- 线程池当前线程数量是否超过上限(corePoolSize 或 maximumPoolSize),超过了return false,没超过则对workerCount+1,继续下一步
- 在线程池的ReentrantLock保证下,向Workers Set中添加新创建的worker实例,添加完成后解锁,并启动worker线程,如果这一切都成功了,return true,如果添加worker入Set失败或启动失败,调用addWorkerFailed()逻辑
/**
* Checks if a new worker can be added with respect to current
* pool state and the given bound (either core or maximum). If so,
* the worker count is adjusted accordingly, and, if possible, a
* new worker is created and started, running firstTask as its
* first task. This method returns false if the pool is stopped or
* eligible to shut down. It also returns false if the thread
* factory fails to create a thread when asked. If the thread
* creation fails, either due to the thread factory returning
* null, or due to an exception (typically OutOfMemoryError in
* Thread.start()), we roll back cleanly.
* 检查根据当前线程池的状态和给定的边界(core or maximum)是否可以创建一个新的worker
* core代表核心线程数是否用完,true(没用完), false(已用完)
* 如果是这样的话,worker的数量做相应的调整,如果可能的话,创建一个新的worker并启动,参数中的firstTask作为worker的第一个任务
* 如果方法返回false,可能因为pool已经关闭或者调用过了shutdown
* 如果线程工厂创建线程失败,也会失败,返回false
* 如果线程创建失败,要么是因为线程工厂返回null,要么是发生了OutOfMemoryError
*
* @param firstTask the task the new thread should run first (or
* null if none). Workers are created with an initial first task
* (in method execute()) to bypass queuing when there are fewer
* than corePoolSize threads (in which case we always start one),
* or when the queue is full (in which case we must bypass queue).
* Initially idle threads are usually created via
* prestartCoreThread or to replace other dying workers.
*
* @param core if true use corePoolSize as bound, else
* maximumPoolSize. (A boolean indicator is used here rather than a
* value to ensure reads of fresh values after checking other pool
* state).
* @return true if successful
*/
private boolean addWorker(Runnable firstTask, boolean core) {
// 外层循环,负责判断线程池状态
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c); // 获取线程池状态
// Check if queue empty only if necessary.
/**
* 线程池的state越小越是运行状态,runnbale=-1,shutdown=0,stop=1,tidying=2,terminated=3
* 1、如果线程池state已经至少是shutdown状态了
* 2、并且以下3个条件任意一个是false
* rs == SHUTDOWN (隐含:rs>=SHUTDOWN)false情况: 线程池状态已经超过shutdown,可能是stop、tidying、terminated其中一个,即线程池已经终止
* firstTask == null (隐含:rs==SHUTDOWN)false情况: firstTask不为空,rs==SHUTDOWN 且 firstTask不为空,return false,场景是在线程池已经shutdown后,还要添加新的任务,拒绝
* ! workQueue.isEmpty() (隐含:rs==SHUTDOWN,firstTask==null)false情况: workQueue为空,当firstTask为空时是为了创建一个没有任务的线程,再从workQueue中获取任务,如果workQueue已经为空,那么就没有添加新worker线程的必要了
* return false,即无法addWorker()
*/
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 线程池在RUNNING 且 任务不为空 或 等待队列不为空,内层循环,负责worker数量+1
for (;;) {
int wc = workerCountOf(c); // 获取worker数量
//如果worker数量>线程池最大上限CAPACITY(即使用int低29位可以容纳的最大值)
//或者( worker数量>corePoolSize 或 worker数量>maximumPoolSize ),即已经超过了给定的边界
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 调用unsafe CAS操作,使得worker数量+1,成功则跳出retry循环
if (compareAndIncrementWorkerCount(c))
break retry;
// CAS worker数量+1失败,再次读取ctl
c = ctl.get(); // Re-read ctl
// 如果状态不等于之前获取的state,跳出内层循环,继续去外层循环判断
if (runStateOf(c) != rs)
continue retry;
// else CAS失败时因为workerCount改变了,继续内层循环尝试CAS对worker数量+1
}
}
/**
* worker数量+1成功的后续操作
* 添加到workers Set集合,并启动worker线程
*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//1、设置worker这个AQS锁的同步状态state=-1
//2、将firstTask设置给worker的成员变量firstTask
//3、使用worker自身这个runnable,调用ThreadFactory创建一个线程,并设置给worker的成员变量thread
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
//--------------------------------------------这部分代码是上锁的
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// 当获取到锁后,再次检查
int rs = runStateOf(ctl.get());
// 如果线程池在运行running<shutdown 或者 线程池已经shutdown,且firstTask==null(可能是workQueue中仍有未执行完成的任务,创建没有初始任务的worker线程执行)
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable 线程还未加入workers就已经启动,抛非法线程状态异常
throw new IllegalThreadStateException();
// workers是一个HashSet<Worker>
workers.add(w);
// 设置最大的池大小largestPoolSize,workerAdded设置为true
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//--------------------------------------------这部分代码是上锁的
// 如果往HashSet中添加worker成功,启动线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果启动线程失败
// worker数量-1的操作在addWorkerFailed()
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
内部类Worker
Worker类本身既实现了Runnable,又继承了AbstractQueuedSynchronizer(以下简称AQS),所以其既是一个可执行的任务,又可以达到锁的效果
/**
* Class Worker mainly maintains interrupt control state for
* threads running tasks, along with other minor bookkeeping.
* This class opportunistically extends AbstractQueuedSynchronizer
* to simplify acquiring and releasing a lock surrounding each
* task execution. This protects against interrupts that are
* intended to wake up a worker thread waiting for a task from
* instead interrupting a task being run. We implement a simple
* non-reentrant mutual exclusion lock rather than use
* ReentrantLock because we do not want worker tasks to be able to
* reacquire the lock when they invoke pool control methods like
* setCorePoolSize. Additionally, to suppress interrupts until
* the thread actually starts running tasks, we initialize lock
* state to a negative value, and clear it upon start (in
* runWorker).
*
* Worker类大体上管理着运行线程的中断状态 和 一些指标
* Worker类投机取巧的继承了AbstractQueuedSynchronizer来简化在执行任务时的获取、释放锁
* 这样防止了中断在运行中的任务,只会唤醒(中断)在等待从workQueue中获取任务的线程
* 解释:
* 为什么不直接执行execute(command)提交的command,而要在外面包一层Worker呢??
* 主要是为了控制中断
* 用什么控制??
* 用AQS锁,当运行时上锁,就不能中断,TreadPoolExecutor的shutdown()方法中断前都要获取worker锁
* 只有在等待从workQueue中获取任务getTask()时才能中断
* worker实现了一个简单的不可重入的互斥锁,而不是用ReentrantLock可重入锁
* 因为我们不想让在调用比如setCorePoolSize()这种线程池控制方法时可以再次获取锁(重入)
* 解释:
* setCorePoolSize()时可能会interruptIdleWorkers(),在对一个线程interrupt时会要w.tryLock()
* 如果可重入,就可能会在对线程池操作的方法中中断线程,类似方法还有:
* setMaximumPoolSize()
* setKeppAliveTime()
* allowCoreThreadTimeOut()
* shutdown()
* 此外,为了让线程真正开始后才可以中断,初始化lock状态为负值(-1),在开始runWorker()时将state置为0,而state>=0才可以中断
*
*
* Worker继承了AQS,实现了Runnable,说明其既是一个可运行的任务,也是一把锁(不可重入)
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread; // 利用ThreadFactory和 Worker这个Runnable创建的线程对象
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
// 设置AQS的同步状态private volatile int state,是一个计数器,大于0代表锁已经被获取
// 在调用runWorker()前,禁止interrupt中断,在interruptIfStarted()方法中会判断 getState()>=0
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 根据当前worker创建一个线程对象
// 当前worker本身就是一个runnable任务,也就是不会用参数的firstTask创建线程,而是调用当前worker.run()时调用firstTask.run()
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this); // runWorker()是ThreadPoolExecutor的方法
}
// Lock methods
//
// The value 0 represents the unlocked state. 0代表“没被锁定”状态
// The value 1 represents the locked state. 1代表“被锁定”状态
protected boolean isHeldExclusively() {
return getState() != 0;
}
/**
* 尝试获取锁
* 重写AQS的tryAcquire(),AQS本来就是让子类来实现的
*/
protected boolean tryAcquire(int unused) {
// 尝试一次将state从0设置为1,即“锁定”状态,但由于每次都是state 0->1,而不是+1,那么说明不可重入
// 且state==-1时也不会获取到锁
if (compareAndSetState(0, 1)) {
// 如果获取锁成功,设置exclusiveOwnerThread=当前线程
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
/**
* 尝试释放锁
* 不是state-1,而是置为0
*/
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
/**
* 中断(如果运行)
* shutdownNow时会循环对worker线程执行
* 且不需要获取worker锁,即使在worker运行时也可以中断
*/
void interruptIfStarted() {
Thread t;
// 如果state>=0、t!=null、且t没有被中断
// new Worker()时state==-1,说明不能中断
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
new Worker()
1、将AQS的state置为-1,在runWoker()前不允许中断
2、待执行的任务会以参数传入,并赋予firstTask
3、用Worker这个Runnable创建Thread
之所以Worker自己实现Runnable,并创建Thread,在firstTask外包一层,是因为要通过Worker控制中断(之前自定义线程池时有设计),而firstTask这个工作任务只是负责执行业务
Worker控制中断主要有以下几方面:
-
初始AQS状态为-1,此时不允许中断interrupt(),只有在worker线程启动了,执行了runWoker(),将state置为0,才能中断
不允许中断体现在:- A、shutdown()线程池时,会对每个worker tryLock()上锁,而Worker类这个AQS的tryAcquire()方法是固定将state从0->1,故初始状态state==-1时tryLock()失败,没发interrupt()
- B、shutdownNow()线程池时,不用tryLock()上锁,但调用worker.interruptIfStarted()终止worker,interruptIfStarted()也有state>0才能interrupt的逻辑
- 为了防止某种情况下,在运行中的worker被中断,runWorker()每次运行任务时都会lock()上锁,而shutdown()这类可能会终止worker的操作需要先获取worker的锁,这样就防止了中断正在运行的线程
Worker实现的AQS为不可重入锁,为了是在获得worker锁的情况下再进入其它一些需要加锁的方法
Worker和Task的区别:
Worker是线程池中的线程,而Task虽然是runnable,但是并没有真正执行,只是被Worker调用了run方法,后面会看到这部分的实现。
runWorker()方法 – 执行任务
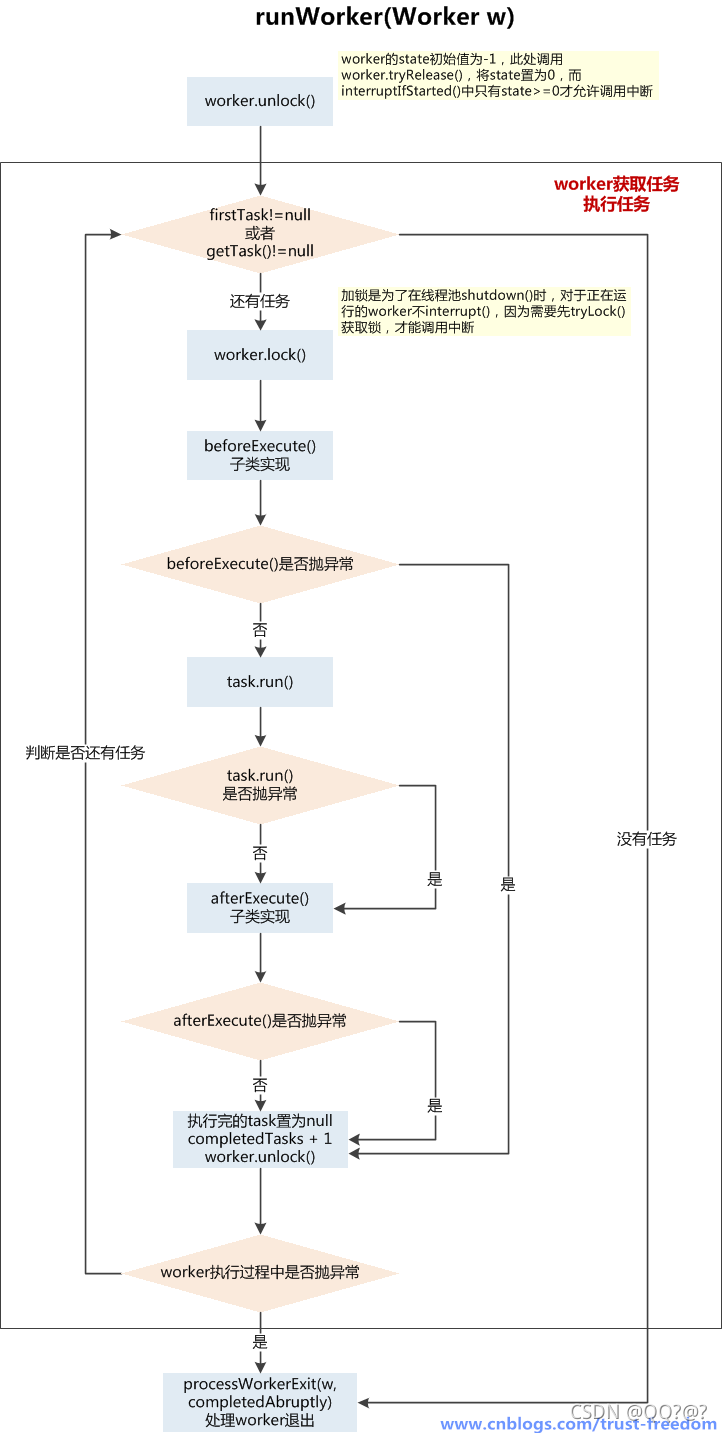
执行流程:
- Worker线程启动后,通过Worker类的run()方法调用runWorker(this)
- 执行任务之前,首先worker.unlock(),将AQS的state置为0,允许中断当前worker线程
- 开始执行firstTask,调用task.run(),在执行任务前会上锁wroker.lock(),在执行完任务后会解锁,为了防止在任务运行时被线程池一些中断操作中断
- 在任务执行前后,可以根据业务场景自定义beforeExecute() 和 afterExecute()方法
- 无论在beforeExecute()、task.run()、afterExecute()发生异常上抛,都会导致worker线程终止,进入processWorkerExit()处理worker退出的流程
- 如正常执行完当前task后,会通过getTask()从阻塞队列中获取新任务,当队列中没有任务,且获取任务超时,那么当前worker也会进入退出流程
/**
* Main worker run loop. Repeatedly gets tasks from queue and
* executes them, while coping with a number of issues:
* 重复的从队列中获取任务并执行,同时应对一些问题:
*
* 1. We may start out with an initial task, in which case we
* don't need to get the first one. Otherwise, as long as pool is
* running, we get tasks from getTask. If it returns null then the
* worker exits due to changed pool state or configuration
* parameters. Other exits result from exception throws in
* external code, in which case completedAbruptly holds, which
* usually leads processWorkerExit to replace this thread.
* 我们可能使用一个初始化任务开始,即firstTask为null
* 然后只要线程池在运行,我们就从getTask()获取任务
* 如果getTask()返回null,则worker由于改变了线程池状态或参数配置而退出
* 其它退出因为外部代码抛异常了,这会使得completedAbruptly为true,这会导致在processWorkerExit()方法中替换当前线程
*
* 2. Before running any task, the lock is acquired to prevent
* other pool interrupts while the task is executing, and then we
* ensure that unless pool is stopping, this thread does not have
* its interrupt set.
* 在任何任务执行之前,都需要对worker加锁去防止在任务运行时,其它的线程池中断操作
* clearInterruptsForTaskRun保证除非线程池正在stoping,线程不会被设置中断标示
*
* 3. Each task run is preceded by a call to beforeExecute, which
* might throw an exception, in which case we cause thread to die
* (breaking loop with completedAbruptly true) without processing
* the task.
* 每个任务执行前会调用beforeExecute(),其中可能抛出一个异常,这种情况下会导致线程die(跳出循环,且completedAbruptly==true),没有执行任务
* 因为beforeExecute()的异常没有catch住,会上抛,跳出循环
*
* 4. Assuming beforeExecute completes normally, we run the task,
* gathering any of its thrown exceptions to send to afterExecute.
* We separately handle RuntimeException, Error (both of which the
* specs guarantee that we trap) and arbitrary Throwables.
* Because we cannot rethrow Throwables within Runnable.run, we
* wrap them within Errors on the way out (to the thread's
* UncaughtExceptionHandler). Any thrown exception also
* conservatively causes thread to die.
* 假定beforeExecute()正常完成,我们执行任务
* 汇总任何抛出的异常并发送给afterExecute(task, thrown)
* 因为我们不能在Runnable.run()方法中重新上抛Throwables,我们将Throwables包装到Errors上抛(会到线程的UncaughtExceptionHandler去处理)
* 任何上抛的异常都会导致线程die
*
* 5. After task.run completes, we call afterExecute, which may
* also throw an exception, which will also cause thread to
* die. According to JLS Sec 14.20, this exception is the one that
* will be in effect even if task.run throws.
* 任务执行结束后,调用afterExecute(),也可能抛异常,也会导致线程die
* 根据JLS Sec 14.20,这个异常(finally中的异常)会生效
*
* The net effect of the exception mechanics is that afterExecute
* and the thread's UncaughtExceptionHandler have as accurate
* information as we can provide about any problems encountered by
* user code.
*
* @param w the worker
*/
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// new Worker()是state==-1,此处是调用Worker类的tryRelease()方法,将state置为0, 而interruptIfStarted()中只有state>=0才允许调用中断
w.unlock(); // allow interrupts
// 是否“突然完成”,如果是由于异常导致的进入finally,那么completedAbruptly==true就是突然完成的
boolean completedAbruptly = true;
try {
// 如果task不为null,或者从阻塞队列中getTask()不为null, 有任务需要执行
while (task != null || (task = getTask()) != null) {
// 上锁,不是为了防止并发执行任务,为了在shutdown()时不终止正在运行的worker
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
/**
* clearInterruptsForTaskRun操作
* 确保只有在线程stoping时,才会被设置中断标示,否则清除中断标示
* 1、如果线程池状态>=stop,且当前线程没有设置中断状态,wt.interrupt()
* 2、如果一开始判断线程池状态<stop,但Thread.interrupted()为true,即线程已经被中断,又清除了中断标示,再次判断线程池状态是否>=stop
* 是,再次设置中断标示,wt.interrupt()
* 否,不做操作,清除中断标示后进行后续步骤
*/
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt(); // 当前线程调用interrupt()中断
try {
beforeExecute(wt, task); // 执行前(子类实现)
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 这里就考验catch和finally的执行顺序了,因为要以thrown为参数
afterExecute(task, thrown); //执行后(子类实现)
}
} finally {
// 任务执行完毕
// task置为null
task = null;
// 完成任务数+1
w.completedTasks++;
// 解锁
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly); //处理worker的退出
}
}
getTask() – 获取任务
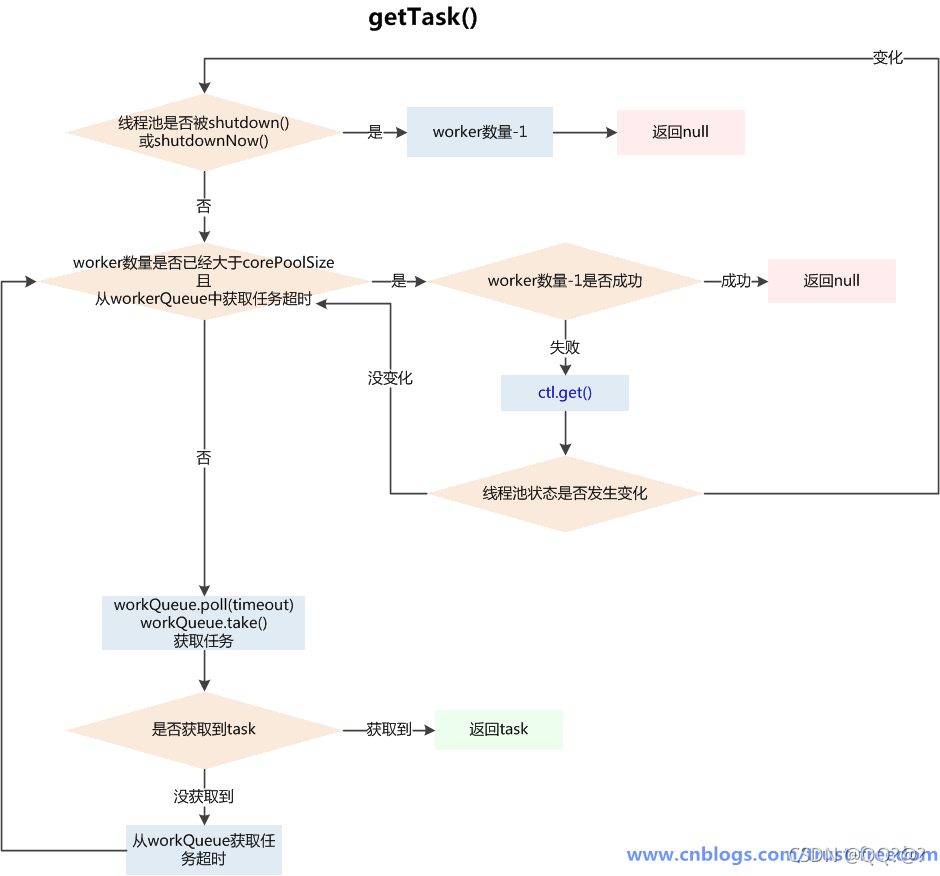
执行流程:
-
首先判断是否可以满足从workQueue中获取任务的条件,不满足return null
-
A、线程池状态是否满足:
(a)shutdown状态 + workQueue为空 或 stop状态,都不满足,因为被shutdown后还是要执行workQueue剩余的任务,但workQueue也为空,就可以退出了
(b)stop状态,shutdownNow()操作会使线程池进入stop,此时不接受新任务,中断正在执行的任务,workQueue中的任务也不执行了,故return null返回 -
B、线程数量是否超过maximumPoolSize 或 获取任务是否超时
(a)线程数量超过maximumPoolSize可能是线程池在运行时被调用了setMaximumPoolSize()被改变了大小,否则已经addWorker()成功不会超过maximumPoolSize
(b)如果 当前线程数量>corePoolSize,才会检查是否获取任务超时,这也体现了当线程数量达到maximumPoolSize后,如果一直没有新任务,会逐渐终止worker线程直到corePoolSize
-
A、线程池状态是否满足:
-
如果满足获取任务条件,根据是否需要定时获取调用不同方法:
- A、workQueue.poll():如果在keepAliveTime时间内,阻塞队列还是没有任务,返回null
- B、workQueue.take():如果阻塞队列为空,当前线程会被挂起等待;当队列中有任务加入时,线程被唤醒,take方法返回任务
- 在阻塞从workQueue中获取任务时,可以被interrupt()中断,代码中捕获了InterruptedException,重置timedOut为初始值false,再次执行第1步中的判断,满足就继续获取任务,不满足return null,会进入worker退出的流程
/**
* Performs blocking or timed wait for a task, depending on
* current configuration settings, or returns null if this worker
* must exit because of any of: 以下情况会返回null
* 1. There are more than maximumPoolSize workers (due to
* a call to setMaximumPoolSize).
* 超过了maximumPoolSize设置的线程数量(因为调用了setMaximumPoolSize())
*
* 2. The pool is stopped.
* 线程池被stop
*
* 3. The pool is shutdown and the queue is empty.
* 线程池被shutdown,并且workQueue空了
*
* 4. This worker timed out waiting for a task, and timed-out
* workers are subject to termination (that is,
* {@code allowCoreThreadTimeOut || workerCount > corePoolSize})
* both before and after the timed wait, and if the queue is
* non-empty, this worker is not the last thread in the pool.
* 线程等待任务超时
*
* @return task, or null if the worker must exit, in which case
* workerCount is decremented
* 返回null表示这个worker要结束了,这种情况下workerCount-1
*/
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
/**
* 对线程池状态的判断,两种情况会workerCount-1,并且返回null
* 线程池状态为shutdown,且workQueue为空(反映了shutdown状态的线程池还是要执行workQueue中剩余的任务的)
* 线程池状态为stop(shutdownNow()会导致变成STOP)(此时不用考虑workQueue的情况)
*/
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount(); // 循环的CAS减少worker数量,直到成功
return null;
}
int wc = workerCountOf(c); // 获取当前线程数
// Are workers subject to culling?
// 是否需要定时从workQueue中获取
// 如果allowCoreThreadTimeOut为true,说明corePoolSize和maximum都需要定时
// wc > corePoolSize 证明现在的线程时救急线程,需要定时
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 线程数大于了最大线程数 或者 超时了 并且 有线程 或者 队列为空(没有任务)
// 就需要尝试减少线程数,然后再次循环尝试执行任务
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
/**
* 如果到了这一步,说明要么线程数量超过了maximumPoolSize(可能maximumPoolSize被修改了)
* 要么既需要计时timed==true,也超时了timedOut==true
* worker数量-1,减一执行一次就行了,然后返回null,在runWorker()中会有逻辑减少worker线程
* 如果本次减一失败,继续内层循环再次尝试减一
*/
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// poll() - 使用 LockSupport.parkNanos(this, nanosTimeout) 挂起一段时间,interrupt()时不会抛异常,但会有中断响应
// take() - 使用 LockSupport.park(this) 挂起,interrupt()时不会抛异常,但会有中断响应
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
// 如获取到了任务就返回
if (r != null)
return r;
// 没有返回,说明超时,那么在下一次循环时会进入worker count减一的步骤
timedOut = true;
/**
* blockingQueue的take()阻塞使用LockSupport.park(this)进入wait状态的,对LockSupport.park(this)进行interrupt不会抛异常,但还是会有中断响应
* 但AQS的ConditionObject的await()对中断状态做了判断,会报告中断状态 reportInterruptAfterWait(interruptMode)
* 就会上抛InterruptedException,在此处捕获,重新开始循环
* 如果是由于shutdown()等操作导致的空闲worker中断响应,在外层循环判断状态时,可能return null
*/
} catch (InterruptedException retry) {
timedOut = false; // 响应中断,重新开始,中断状态会被清除
}
}
}
processWorkerExit() – worker线程退出
参数
:
worker: 要结束的worker
completedAbruptly: 是否突然完成(是否因为异常退出)
执行流程:
-
worker数量-1
A、如果是突然终止,说明是task执行时异常情况导致,即run()方法执行时发生了异常,那么正在工作的worker线程数量需要-1
B、如果不是突然终止,说明是worker线程没有task可执行了,不用-1,因为已经在getTask()方法中-1了 - 从Workers Set中移除worker,删除时需要上锁mainlock
-
tryTerminate():在对线程池有负效益的操作时,都需要“尝试终止”线程池,大概逻辑:
判断线程池是否满足终止的状态
A、如果状态满足,但还有线程池还有线程,尝试对其发出中断响应,使其能进入退出流程
B、没有线程了,更新状态为tidying->terminated -
是否需要增加worker线程,如果线程池还没有完全终止,仍需要保持一定数量的线程
线程池状态是running 或 shutdown
A、如果当前线程是突然终止的,addWorker()
B、如果当前线程不是突然终止的,但当前线程数量 < 要维护的线程数量,addWorker()
故如果调用线程池shutdown(),直到workQueue为空前,线程池都会维持corePoolSize个线程,然后再逐渐销毁这corePoolSize个线程
/**
* Performs cleanup and bookkeeping for a dying worker. Called
* only from worker threads. Unless completedAbruptly is set,
* assumes that workerCount has already been adjusted to account
* for exit. This method removes thread from worker set, and
* possibly terminates the pool or replaces the worker if either
* it exited due to user task exception or if fewer than
* corePoolSize workers are running or queue is non-empty but
* there are no workers.
*
* @param w the worker
* @param completedAbruptly if the worker died due to user exception
*/
private void processWorkerExit(Worker w, boolean completedAbruptly) {
/**
* 1、worker数量-1
* 如果是突然终止,说明是task执行时异常情况导致,即run()方法执行时发生了异常,那么正在工作的worker线程数量需要-1
* 如果不是突然终止,说明是worker线程没有task可执行了,不用-1,因为已经在getTask()方法中-1了
*/
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
/**
* 2、从Workers Set中移除worker
*/
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 把worker的完成任务数加到线程池的完成任务数
completedTaskCount += w.completedTasks;
// 从HashSet<Worker>中移除
workers.remove(w);
} finally {
mainLock.unlock();
}
/**
* 3、在对线程池有负效益的操作时,都需要“尝试终止”线程池
* 主要是判断线程池是否满足终止的状态
* 如果状态满足,但还有线程池还有线程,尝试对其发出中断响应,使其能进入退出流程
* 没有线程了,更新状态为tidying->terminated
*/
tryTerminate();
int c = ctl.get();
// 如果状态是running、shutdown,即tryTerminate()没有成功终止线程池,尝试再添加一个worker
if (runStateLessThan(c, STOP)) {
// 不是突然完成的,即没有task任务可以获取而完成的,计算min,并根据当前worker数量判断是否需要addWorker()
if (!completedAbruptly) {
// allowCoreThreadTimeOut默认为false,即min默认为corePoolSize
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果min为0,即不需要维持核心线程数量,且workQueue不为空,至少保持一个线程
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// 如果线程数量大于最少数量,直接返回,否则下面至少要addWorker一个
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 添加一个没有firstTask的worker
// 只要worker是completedAbruptly突然终止的,或者线程数量小于要维护的数量,就新添一个worker线程,即使是shutdown状态
addWorker(null, false);
}
}
6. 关闭线程池
shutdown()方法
/*
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
*/
void shutdown();
shutdownNow()方法
/*
线程池状态变为 STOP
- 不会接收新任务
- 会将队列中的任务返回
- 并用 interrupt 的方式中断正在执行的任务
*/
List<Runnable> shutdownNow();
7. 关闭线程池源码解析
1. shutdown()方法 – 温柔的终止线程池
/*
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
*/
void shutdown();
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN); // 修改线程池状态为SHUTDOWN
interruptIdleWorkers(); // 仅会打断空闲线程
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试终结
tryTerminate();
}
shutdown()执行流程:
- 上锁,mainLock是线程池的主锁,是可重入锁,当要操作workers set这个保持线程的HashSet时,需要先获取mainLock,还有当要处理largestPoolSize、completedTaskCount这类统计数据时需要先获取mainLock
- 判断调用者是否有权限shutdown线程池
- 使用CAS操作将线程池状态设置为shutdown,shutdown之后将不再接收新任务
- 中断所有空闲线程 interruptIdleWorkers()
- onShutdown(),ScheduledThreadPoolExecutor中实现了这个方法,可以在shutdown()时做一些处理
- 解锁
- 尝试终止线程池 tryTerminate()
可以看到shutdown()方法最重要的几个步骤是:更新线程池状态为shutdown、中断所有空闲线程、tryTerminated()尝试终止线程池
那么,什么是空闲线程?interruptIdleWorkers() 是怎么中断空闲线程的?
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
interruptIdleWorkers()方法
/**
* Interrupts threads that might be waiting for tasks (as
* indicated by not being locked) so they can check for
* termination or configuration changes. Ignores
* SecurityExceptions (in which case some threads may remain
* uninterrupted).
* 中断在等待任务的线程(没有上锁的),中断唤醒后,可以判断线程池状态是否变化来决定是否继续
*
* @param onlyOne If true, interrupt at most one worker. This is
* called only from tryTerminate when termination is otherwise
* enabled but there are still other workers. In this case, at
* most one waiting worker is interrupted to propagate shutdown
* signals in case all threads are currently waiting.
* Interrupting any arbitrary thread ensures that newly arriving
* workers since shutdown began will also eventually exit.
* To guarantee eventual termination, it suffices to always
* interrupt only one idle worker, but shutdown() interrupts all
* idle workers so that redundant workers exit promptly, not
* waiting for a straggler task to finish.
*
* onlyOne如果为true,最多interrupt一个worker
* 只有当终止流程已经开始,但线程池还有worker线程时,tryTerminate()方法会做调用onlyOne为true的调用
* (终止流程已经开始指的是:shutdown状态 且 workQueue为空,或者 stop状态)
* 在这种情况下,最多有一个worker被中断,为了传播shutdown信号,以免所有的线程都在等待
* 为保证线程池最终能终止,这个操作总是中断一个空闲worker
* 而shutdown()中断所有空闲worker,来保证空闲线程及时退出
*/
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
interruptIdleWorkers() 首先会获取mainLock锁,因为要迭代workers set,在中断每个worker前,需要做两个判断:
- 线程是否已经被中断,是就什么都不做
-
worker.tryLock() 是否成功
第二个判断比较重要,因为Worker类除了实现了可执行的Runnable,也继承了AQS,本身也是一把锁
,具体可见 ThreadPoolExecutor内部类Worker解析
tryLock()调用了Worker自身实现的tryAcquire()方法,这也是AQS规定子类需要实现的尝试获取锁的方法
public boolean tryLock() { return tryAcquire(1); }
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
tryAcquire()先尝试将AQS的state从0–>1,返回true代表上锁成功,并设置当前线程为锁的拥有者
可以看到compareAndSetState(0, 1)只尝试了一次获取锁,且不是每次state+1,而是0–>1,说明锁不是可重入的
但是为什么要worker.tryLock()获取worker的锁呢?
这就是Woker类存在的价值之一,
控制线程中断
在runWorker()方法中每次获取到task,task.run()之前都需要worker.lock()上锁,运行结束后解锁,即正在运行任务的工作线程都是上了worker锁的
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock(); // 上锁
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock(); // 解锁
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
(
重要
)在interruptIdleWorkers()中断之前需要先tryLock()获取worker锁,意味着正在运行的worker不能中断,因为worker.tryLock()失败,且锁是不可重入的
故shutdown()只有对能获取到worker锁的空闲线程(正在从workQueue中getTask(),此时worker没有加锁)发送中断信号
由此可以将worker划分为:
1、空闲worker:正在从workQueue阻塞队列中获取任务的worker
2、运行中worker:正在task.run()执行任务的worker
正阻塞在getTask()获取任务的worker(空闲状态)在被中断后,会抛出InterruptedException,不再阻塞获取任务
捕获中断异常后,将继续循环到getTask()最开始的判断线程池状态的逻辑,当线程池是shutdown状态,且workQueue.isEmpty时,CAS尝试减少worker数量,return null(getTask()中的逻辑),进行worker线程退出逻辑;
如果此时队列中还有任务,则不会尝试去减少worker数量,而是继续将队列中的任务执行完毕之后,才尝试减少worker数量(这也就是shutdown()方法,会将队列中任务执行完毕的原因,只有在线程池状态为SHUTDOWN并且队列为空这两个条件全部满足时,才会进行终止线程池操作)
某些情况下,interruptIdleWorkers()时多个worker正在运行,不会对其发出中断信号,假设此时workQueue也不为空
那么当多个worker运行结束后,会到workQueue阻塞获取任务,获取到的执行任务,没获取到的,如果还是核心线程,会一直在getTask()中的workQueue.take()阻塞住,线程无法终止,因为workQueue已经空了,且shutdown后不会接收新任务了
这就需要在shutdown()后,还可以发出中断信号
,Doug Lea大神巧妙的在所有可能导致线程池产终止的地方安插了
tryTerminated()尝试线程池终止的逻辑,并在其中判断如果线程池已经进入终止流程,没有任务等待执行了,但线程池还有线程,中断唤醒一个空闲线程
tryTerminate()方法
tryTerminate() 执行流程:
- 判断线程池是否需要进入终止流程(只有当shutdown状态+workQueue.isEmpty 或 stop状态,才需要)
- 判断线程池中是否还有线程,有则 interruptIdleWorkers(ONLY_ONE) 尝试中断一个空闲线程(正是这个逻辑可以再次发出中断信号,中断阻塞在获取任务的线程)
- 如果状态是SHUTDOWN,workQueue也为空了,正在运行的worker也没有了,开始terminated
会先上锁,将线程池置为tidying状态,之后调用需子类实现的 terminated(),最后线程池置为terminated状态,并唤醒所有等待线程池终止这个Condition的线程
/**
* Transitions to TERMINATED state if either (SHUTDOWN and pool
* and queue empty) or (STOP and pool empty). If otherwise
* eligible to terminate but workerCount is nonzero, interrupts an
* idle worker to ensure that shutdown signals propagate. This
* method must be called following any action that might make
* termination possible -- reducing worker count or removing tasks
* from the queue during shutdown. The method is non-private to
* allow access from ScheduledThreadPoolExecutor.
* 在以下情况将线程池变为TERMINATED终止状态
* shutdown 且 正在运行的worker 和 workQueue队列为empty
* stop 且 没有正在运行的worker
*
* 这个方法必须在任何可能导致线程池终止的情况下被调用,如:
* 减少worker数量
* shutdown时从queue中移除任务
*
* 这个方法不是私有的,所以允许子类ScheduledThreadPoolExecutor调用
*/
final void tryTerminate() {
// 这个for循环主要是和进入关闭线程池操作的CAS判断结合使用的
for (;;) {
int c = ctl.get();
/**
* 线程池是否需要终止
* 如果以下3中情况任一为true,return,不进行终止
* 1、还在运行状态
* 2、状态是TIDYING、或 TERMINATED,已经终止过了
* 3、SHUTDOWN 且 workQueue不为空
*/
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
/**
* 只有shutdown状态 且 workQueue为空,或者 stop状态能执行到这一步
* 如果此时线程池还有线程(正在运行任务,正在等待任务)
* 中断唤醒一个正在等任务的空闲worker
* 唤醒后再次判断线程池状态,getTask()会return null,跳回runWorker()while循环接收到这个null
* 会直接finally进入processWorkerExit()流程
* 这个过程会循环执行tryTerminate()方法,直到线程为0,终止成功
*/
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE); // 中断workers集合中的空闲任务,参数为true,只中断一个
return;
}
/**
* 如果状态是SHUTDOWN,workQueue也为空了,正在运行的worker也没有了,开始terminated
*/
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// CAS:将线程池的ctl变成TIDYING(所有的任务被终止,workCount为0,为此状态时将会调用terminated()方法),期间ctl有变化就会失败,会再次for循环
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated(); // 需子类实现
} finally {
ctl.set(ctlOf(TERMINATED, 0)); // 将线程池的ctl变成TERMINATED
termination.signalAll(); // 唤醒调用了 等待线程池终止的线程 awaitTermination()
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
// 如果上面的CAS判断false,再次循环
}
}
2. shutdownNow() – 强硬的终止线程池
shutdownNow() 和 shutdown()的大体流程相似,差别是:
- 将线程池更新为stop状态
- 调用 interruptWorkers() 中断所有线程,包括正在运行的线程
- 将workQueue中待处理的任务移到一个List中,并在方法最后返回,说明shutdownNow()后不会再处理workQueue中的任务
/**
* Attempts to stop all actively executing tasks, halts the
* processing of waiting tasks, and returns a list of the tasks
* that were awaiting execution. These tasks are drained (removed)
* from the task queue upon return from this method.
* 尝试停止所有活动的正在执行的任务,停止等待任务的处理,并返回正在等待被执行的任务列表
* 这个任务列表是从任务队列中排出(删除)的
*
* <p>This method does not wait for actively executing tasks to
* terminate. Use {@link #awaitTermination awaitTermination} to
* do that.
* 这个方法不用等到正在执行的任务结束,要等待线程池终止可使用awaitTermination()
*
* <p>There are no guarantees beyond best-effort attempts to stop
* processing actively executing tasks. This implementation
* cancels tasks via {@link Thread#interrupt}, so any task that
* fails to respond to interrupts may never terminate.
* 除了尽力尝试停止运行中的任务,没有任何保证
* 取消任务是通过Thread.interrupt()实现的,所以任何响应中断失败的任务可能永远不会结束
*
* @throws SecurityException {@inheritDoc}
*/
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock(); // 上锁
try {
checkShutdownAccess(); // 判断调用者是否有权限shutdown线程池
advanceRunState(STOP); // CAS+循环设置线程池状态为STOP
interruptWorkers(); // 中断所有线程,包括正在运行任务的线程
tasks = drainQueue(); // 将workQueue中的元素放入一个List并返回
} finally {
mainLock.unlock(); // 解锁
}
tryTerminate(); // 尝试终止线程池
return tasks; // 返回workQueue中未被执行的任务
}
interruptWorkers()
interruptWorkers() 很简单,循环对所有worker调用 interruptIfStarted(),其中会判断worker的AQS state是否大于0,即worker是否已经开始运作,再调用Thread.interrupt()
需要注意的是,对于运行中的线程调用Thread.interrupt()并不能保证线程被终止,task.run()内部可能捕获了InterruptException,没有上抛,导致线程一直无法结束
/**
* Interrupts all threads, even if active. Ignores SecurityExceptions
* (in which case some threads may remain uninterrupted).
*/
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
/**
* Drains the task queue into a new list, normally using
* drainTo. But if the queue is a DelayQueue or any other kind of
* queue for which poll or drainTo may fail to remove some
* elements, it deletes them one by one.
*/
private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<Runnable>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
3. awaitTermination() – 等待线程池终止
参数:
timeout:超时时间
unit: timeout超时时间的单位
返回:
true:线程池终止
false:超过timeout指定时间
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (;;) {
if (runStateAtLeast(ctl.get(), TERMINATED))
return true;
if (nanos <= 0)
return false;
nanos = termination.awaitNanos(nanos);
}
} finally {
mainLock.unlock();
}
}
在发出一个shutdown请求后,在以下3种情况发生之前,awaitTermination()都会被阻塞
1、所有任务完成执行
2、到达超时时间
3、当前线程被中断
/**
* Wait condition to support awaitTermination
*/
private final Condition termination = mainLock.newCondition();
awaitTermination() 循环的判断线程池是否terminated终止 或 是否已经超过超时时间,然后通过termination这个Condition阻塞等待一段时间
termination.awaitNanos() 是通过 LockSupport.parkNanos(this, nanosTimeout)实现的阻塞等待
阻塞等待过程中发生以下具体情况会解除阻塞(对上面3种情况的解释):
1、如果发生了 termination.signalAll()(内部实现是 LockSupport.unpark())会唤醒阻塞等待,且由于ThreadPoolExecutor只有在 tryTerminated()尝试终止线程池成功,将线程池更新为terminated状态后才会signalAll(),故awaitTermination()再次判断状态会return true退出
2、如果达到了超时时间 termination.awaitNanos() 也会返回,此时nano==0,再次循环判断return false,等待线程池终止失败
3、如果当前线程被 Thread.interrupt(),termination.awaitNanos()会上抛InterruptException,awaitTermination()继续上抛给调用线程,会以异常的形式解除阻塞
故终止线程池并需要知道其是否终止可以用如下方式:
executorService.shutdown();
try{
while(!executorService.awaitTermination(500, TimeUnit.MILLISECONDS)) {
LOGGER.debug("Waiting for terminate");
}
} catch (InterruptedException e) {
//中断处理
}
8.任务调度线程池(定时)
旧版本JDK 使用 java.util.Timer 实现定时效果
public class Test21 {
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
System.out.println(new Date().toString() + "task1 ......");
// 使用 timer 添加两个任务,希望它们都在 1s 后执行
// 会产生如下问题:
// 1. 但由于 timer 内只有一个线程来顺序执行队列中的任务,因此『任务1』的延时,影响了『任务2』的执行
// try {
// Thread.sleep(2000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// 2. 使用Timer如果任务中出现了异常,则会导致接下来的任务不能正常执行
int i = 1 / 0;
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
System.out.println(new Date().toString() + "task2 ......");
}
};
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
}
使用 ScheduledExecutorService 改写
public class Test21 {
public static void main(String[] args) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
executor.schedule(() -> {
System.out.println("task1 ..." + new Date().toString());
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(() -> {
System.out.println("task2 ..." + new Date().toString());
}, 1000, TimeUnit.MILLISECONDS);
}
}
9. Fork \ Join 线程池
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
举例,创建 1~n 数字累加器
class AddTask extends RecursiveTask<Integer>{
int n;
public AddTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n == 1) return 1;
AddTask task = new AddTask(n - 1);
task.fork();
int count = n + task.join();
return count;
}
}
public class Test21 {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask(5)));
}
}