最经典的题目

以及洛谷一大堆相似题
斐波那契升级版
,
广义斐波那契
等等,都是相关的题目。一般而言我们求解斐波那契无非是不断地向前迭代,但是这样的效率实在是太低了。对于
n
n
n
的规模如此之大的题目应该如何求解呢?可能有人会认为通过递推式求出通项,就可以求解了。可是斐波那契数列的通项公式是
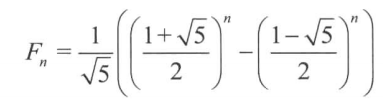
这谁能找出个规律来,由于式中包含无理数,无法简单求得模之后的结果。况且,在其他问题中有一些很难直接求得通项公式。不过这些情况都可以不求出通项,而用矩阵高效地求出第
n
n
n
项的值。
首先,我们先介绍一下对于斐波那契数列应该如何求解。把斐波那契数列的递推式表示成矩阵就得到了下面的式子

因此只要能求出
A
n
A^n
A
n
,就可以求出
F
n
F_n
F
n
了。类似的,对于
广义斐波那契数列
而言,
a
1
,
a
2
a_1,a_2
a
1
,
a
2
以及递推关系式
F
n
=
p
F
n
−
1
+
q
F
n
−
2
F_n=pF_{n-1}+qF_{n-2}
F
n
=
p
F
n
−
1
+
q
F
n
−
2
,系数
p
,
q
p,q
p
,
q
都是题目中给的,此时如何进行计算呢?只需要简单的修改矩阵
A
A
A
的样子就好了
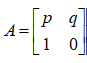
就是新的矩阵
A
A
A
,原因如下图所示,
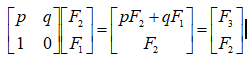
这样的话我们进行和正常斐波那契数列一样的递推,就能得出
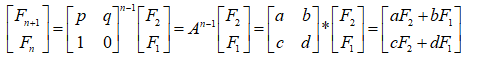
计
B
=
A
n
−
1
B=A^{n-1}
B
=
A
n
−
1
也就是说
F
n
=
B
[
1
]
[
0
]
∗
F
2
+
B
[
1
]
[
1
]
∗
F
1
F_n=B[1][0]*F_2+B[1][1]*F_1
F
n
=
B
[
1
]
[
0
]
∗
F
2
+
B
[
1
]
[
1
]
∗
F
1
,然后求个模就好了
#include<iostream>
#include<cmath>
#include<string.h>
#include<algorithm>
#include<vector>
#include<map>
#include<queue>
#include<iomanip>
using namespace std;
#define ll long long
#define Max 1000
#define vec vector< ll >
#define arr vector< vec >
ll p, q, a1, a2, n, m;
arr mut(arr a, arr b) {
arr c(2, vec(2));
for (ll i = 0; i < 2; i++) {
for (ll j = 0; j < 2; j++) {
for (ll k = 0; k < 2; k++) c[i][j] = (c[i][j] + a[i][k] * b[k][j]) % m;
}
}
return c;
}
arr quick(arr a, ll n) {
arr ans(2, vec(2)); ans[0][0] = 1; ans[1][1] = 1;//主对角线元素全1
while (n > 0) {
if (n & 1) ans = mut(ans, a);
a = mut(a, a);
n >>= 1;
}
return ans;
}
int main() {
cin >> p >> q >> a1 >> a2 >> n >> m;
arr a(2, vec(2));//两行两列
a[0][0] = p; a[0][1] = q; a[1][0] = 1; a[1][1] = 0;
a = quick(a, n - 1);
cout << (a[1][0] * a2%m + a[1][1] * a1%m) % m << endl;
}
更一般的

通过计算这个矩阵的
n
n
n
次幂,就可以在
〇
(
m
3
log
n
)
〇(m^3 \log n)
〇
(
m
3
lo
g
n
)
的时间内计算出第
n
n
n
项的值。不过,如果递推式里含有常数项则稍微复杂一些,需变成如下形式

需要稍作分析的矩阵快速幂


矩阵幂求和

n
∗
n
n*n
n
∗
n
的矩阵的
k
k
k
次幂可以通过快速幂在
O
(
n
3
log
k
)
O(n^3\log k)
O
(
n
3
lo
g
k
)
时间内求出。但是这又不是快速幂的模板题,怎么可能真的让你快速幂计算完一个一盒加起来,注意
k
k
k
的量级,
O
(
n
3
k
)
O(n^3k)
O
(
n
3
k
)
显然会超时。因此需要在挨个加的基础上进行一些改进,与上述问题不同的是,在这里我们还没有找到一个递推关系式,不妨把目光聚焦到
S
k
S_k
S
k
与
S
k
−
1
S_{k-1}
S
k
−
1
的关系上来,通过
查看题解
仔细分析,我们得到了这个重要的关系
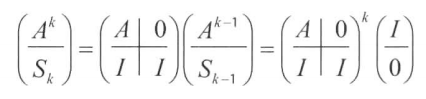
然后通过计算该矩阵的快速幂,我们就快速的进行了原式的求和。