1. PCIe错误定义
规范使用了四个关于错误的通用术语,定义如下:
1.
错误检测
:确定存在错误的过程。
2.
错误记录
:指的是将相关寄存器(配置空间中的)的对应位置位,以等待软件中的相关错误处理程序来处理该错误。
3.
错误报告
:通知系统某个(或多个)错误发生了。在PCIe总线中,发生错误的设备会通过错误消息(Error Message)逐级将错误信息发送至Root,Root接收到错误消息后,会产生对应的中断通知系统。
4.
错误信号
:指的是通过发送错误消息(或者带有UR,CA的Completion和Poisoned TLP)来传递错误信息的过程。
2. PCIe错误报告
PCIe总线Spec定义了两个错误报告等级。
第一个为基本的(Baseline Capability),是所有PCIe设备都需要支持的功能。
第二个是可选的,称之为高级错误报告(Advanced Error Reporting Capability)。
2.1 Baseline Error Reporting
这包括对传统错误报告的支持以及对报告PCIe错误的基本支持。
所有设备都需要两套配置寄存器,以支持Baseline Error Reporting
在基本的错误报告机制中,有两组相关的配置寄存器(配置空间中),
分别为:
· 兼容PCI总线的寄存器(PCI-compatible Registers)
· PCIe总线中新增的寄存器(PCI Express Capability Registers)
PCI‐compatible Registers
这些寄存器与PCI使用的寄存器相同,为现有PCI兼容软件提供向后兼容性。为了实现这一点,PCIe错误被映射到PCI兼容错误,使其对传统软件可见。
PCI Express Capability Registers
这些寄存器仅对了解PCIe的较新软件有用,但它们提供了更多专门针对PCIe软件的错误信息。
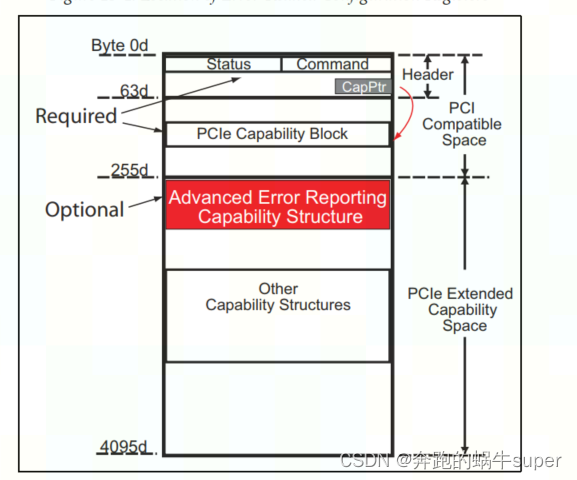
2.2 Advanced Error Reporting (AER),
它添加了一组新的配置寄存器,并跟踪发生了哪些错误、错误的严重程度等更多细节,在某些情况下,甚至可以记录导致错误的数据包的信息。
这种可选的错误报告机制包括一组新的专用配置寄存器,这些寄存器为错误处理软件在诊断和恢复问题时提供了更多信息。
AER寄存器被映射到扩展的配置空间中,并提供更多关于任何错误性质的信息。
3. 错误分类
参考文章
https://blog.csdn.net/weixin_43405280/article/details/131701958?spm=1001.2014.3001.5502
4. PCIe错误检查机制
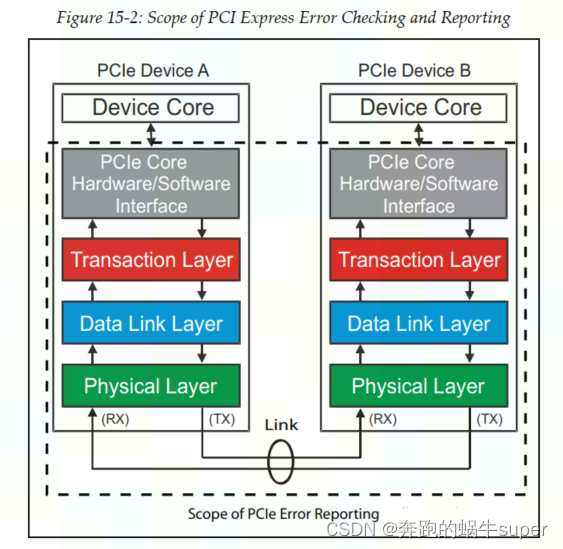
PCIe错误检查的范围集中在与链路和数据包传递相关的错误上,如下图所示。与链路传输无关的错误不会通过PCIe错误处理机制报告,并且需要专有的方法来报告,例如设备特定的中断。接口的每一层都包括错误检查功能。
包传递过程的错误主要通过CRC编码来检测。PCIe定义了两种CRC——LCRC和ECRC。其中LCRC(Link CRC)由数据链路层产生和校检,用于检测从一端的数据链路层发送到另一端的数据链路层的TLP是否发生的错误。而ECRC(End-to-end CRC)由事务层产生和校检,且ECRC是可选的。
4.1 CRC
循环冗余校验码(cyclic redundancy check)简称CRC(循环码),是一种能力相当强的检错、纠错码,并且实现编码和检码的电路比较简单,常用于串行传送(二进制位串沿一条信号线逐位传送)的辅助存储器与主机的数据通信和计算机网络中。
循环码是指通过某种数学运算实现有效信息与校验位之间的循环校验。
这种编码基本思想是将要传送的信息M(X)表示为一个多项式L,用L除以一个预先确定的多项式G(X),得到的余式就是所需的循环冗余校验码。
这种校验又称多项式校验。
理论上可以证明循环冗余校验码的检错能力有以下特点:①可检测出所有奇数位错;②可检测出所有双比特的错;③可检测出所有小于、等于校验位长度的突发错
4.2 Error Checks by Laye (按层进行错误检查)
在不同分层架构中接收到的数据包,某些错误检查列为可选。对于这些情况,如果发生错误,但设计者选择不实现这种形式的检查,则不会检测到错误。
4.2.1Physical Layer Errors (物理层错误)
到达接收器的分组首先到达物理层。有一些事情必须在这个级别进行检查,还有一些事情可以选择进行检查。链路训练也发生在这一层,在这个过程中可能会出现各种问题总之,物理层错误,也称为接收器错误或链路错误,包括以下情况:
· 8b/10b编解码异常
· Framing异常(8b/10b编码中是可选的,128b/130b中是必选的)
· Elastic Buffer错误(可选的)
· 起始字符失锁(Loss of Symbol Lock)或者通道对齐失锁(Lane Deskew)(可选的)
4.2.2 Data Link Layer Errors(数据链路层错误)
在物理层之后进入的分组接着进入数据链路层,在那里检查它们是否存在几个可能的问题。
总之,错误如下:
•TLP 的LCRC校检失败
•TLP的序列号(Sequence Number)异常
•DLLP中的16-bit CRC校检失败
4.2.3 Transaction Layer Errors(事务层错误)
最后,如果传入的TLP通过了物理层和数据链路层的所有检查,它们将最终到达事务层,在那里进行检查:
•ERCR校检失败(可选的)
•异常的TLP(Malformed TLP)(即TLP的格式异常)
•流量控制协议异常(Flow Control Protocol Violation)
•不支持的请求
•数据损坏(Data Corruption,又称为Poisoned Packet)
•Completer Abort(可选的)
•接收端溢出(Receiver Overflow)(可选的)
与数据链路层一样,事务层也存在一些错误检查,
例如:
•返回包超时(Completion Timeout)
•意不对应的返回包(Unexpected Completion,即Completion与发出的Request不一致)
4.3 Error Pollution(错误污染)
如果设备在同一事务中发现多个问题,则可能会出现问题。这可能导致报告多个错误(称为“错误污染”)。
为了避免这种情况,报告的错误仅限于最重要的错误。例如,如果TLP在物理层有接收器错误,那么肯定会发现它在数据链路层和事务层也有错误,但报告所有错误只会增加混乱。最相关的是报告出现的第一个错误。因此,如果在物理层中看到错误,则没有理由将数据包转发到更高层。同样,如果在数据链路层中看到了错误,则数据包将不会转发到事务层。在一个级别上的偏移数据包不会被转发到下一个级别,而是被丢弃。
5. PCI Express错误的来源
PCIe错误来源主要有一下几种:
-
ECRC校验错误
-
Data Poisoning (错误传递)
-
Transaction Errors (事务错误)
-
Link Flow Control Related Errors(流控制相关错误)
-
Malformed TLP (格式不正确的TLP)
-
Internal Errors (内部错误)
5.1 ECRC校验错误
如前所述,ECRC生成和检查需要提供可选的高级错误报告配置寄存器结构,如下图所示。配置软件检查此功能寄存器,以确定功能中是否支持ECRC。如果是,则可以使用对错误能力和控制寄存器的写入来启用它。
5.1.1 TLP Digest (TLP摘要)
如果使能了ECRC功能,可以通过TLP包头中的TD(TLP Digest,ECRC也被称为Digest)为来标记当前的TLP是否使用ECRC,如下图所示。需要特别注意的是,如果TD为1(表示使用ECRC),但是TLP中却没有ECRC;或者TD为0,TLP中却包含了ECRC,则会被判定为TLP格式错误,即Malformed TLP错误。
ECRC是基于TLP的包头和数据(Header and Data Payload)计算的,接收端的事务层会重新基于这些内容计算并与收到的TLP中的ECRC(发送端的事务层计算的ECRC)作对比,如果不一致,则认为数据传输过程中发生了问题,数据被破坏了,进而产生ECRC校检错误。需要注意的是,在TLP包头中,有两位实际上是不参与ERCR计算的——Type域的bit0和EP位。这两位通常被称为Variant bits,且在ECRC计算的时候,这两位的对应位置始终被认为是1,而非使用实际的数值。

TLP Digest Bit in a Completion Header
当接收端(Completer)接收到的请求(Request) TLP中存在ECRC校检错误时,接收端通常会选择不对该请求发送返回TLP(Completion),并将ECRC错误状态位置位。发送端由于长时间未接收到Completion,进而会产生Completion超时错误(Timeout Error)。而大部分发送端,会选择重新发送先前的请求Request。
当发送端(Requester)在发送完请求后收到了来自接收端返回的TLP(Completion)时,却发现该Completion TLP中存在ECRC校检错误,会将ECRC错误状态位置位。发送端可以选择重新发送先前的请求Request,还可以选择通过特殊功能中断(Function Specific Interrupt)向系统报告错误。
以上两种情况中,如果使能了错误消息报告功能的话,不可校正的非致命错误消息(Uncorrectable Non-fatal Error Message)会被发送至系统。
5.1.2 Variant Bits Not Included in ECRC Mechanism(可变位不包括在ECRC机制中)
由于bit0和EP bit 可以在数据包传输时发生变化,因此它们被称为“可变比特”,不能用于生成或检查ECRC。相反,对于ECRC生成和检查,它们的值总是假设为1b,而不是使用实际值。这样一来,ECRC就不依赖于它们,并且会得到正确的评估。
5.2 Data Poisoning(Error Forwarding)
Data Poisoning也被称为错误传递(Error Forwarding),指的是在已知TLP Data Payload被破坏(Corrupted)的情况下,该TLP仍然被发送至其他的PCIe设备。此时,该TLP包头的EP位(Error Poisoned)被置位为1

5.3 Transaction Errors (事务错误)
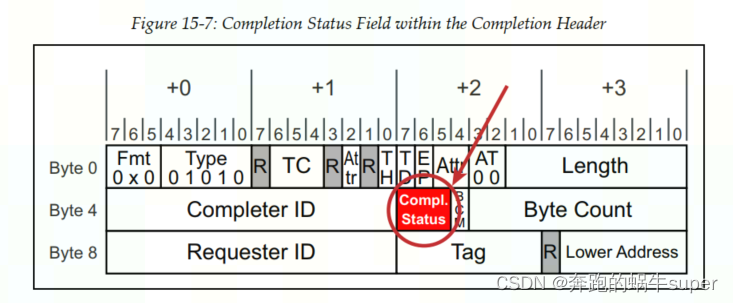
事务错误主要包括不支持的请求(Unsupported Request)、Completer Abort、非预期的Completion和Completion超时。该错误类型主要通过返回的Completion TLP包头中的Compl. Status告知Requester,
下图说明了该字段在完成标题中的位置。如表所示,只定义了四个编码,其中两个表示错误条件。

5.3.1 Unsupported Request (UR) Status
如果接收方不支持请求,则返回具有UR状态的完成。
规范定义了许多可能导致UR状态的条件。一些
例如:
• 请求类型不被当前PCIe设备支持
• 消息中使用了不支持或者未定义的消息编码
•请求未引用映射到设备的地址空间
•请求地址未映射到交换机端口的地址范围内
•针对Completer的IO或者存储映射控制空间(Memory-mapped Control Space)进行的Poisoned写操作(EP=1)
•Root或者Switch的Downstream端口接收到针对其二级总线(Secondary Bus)上的不存在的设备的配置请求(Configuration Request)
•Endpoint接收到Type1型的配置请求
•Completion中使用了保留的Completion状态编码(参考上面的表格)
•设备(的某个功能,Function)处于D1、D2或者D3hot电源管理状态时,却接收到了除了配置请求和消息之外的内容
5.3.2 Completer Abort (CA) Status
可能会出现几种情况,导致Completer将此CA状态返回给Requester。
•Completer接收的特殊请求,只有在违背其规则的情况下才能对该请求进行响应(返回Completion)
•因为某些恒定的错误状态(Permanent Error Condition),导致Completer无法响应接收到的请求
•Completer接收到存在访问控制服务错误(Access Control Services Error,ACS Error)的请求
•PCIe-to-PCI桥接收到针对其连接的PCI设备的请求,但是该PCI设备无法处理该请求
中止请求的完成者可能会向根报告错误,并显示非致命错误消息,如果请求需要完成,则状态为CA。
5.3.3 Unexpected Completion
Requester接收到的Completion和其发出的Request不一致
Completion超时:
所有的PCIe设备都必须支持Completion超时定时器,除非该设备只是用于初始化配置事务的。需要注意的是,PCIe设备必须能够针对多个事务(Transaction)分别计时。PCIe 1.x和2.0的Spec建议超时时间最好设置为10ms至50ms之间,对于一些特殊情况,超时时间最低可设置为30us。PCIe 2.1 Spec开始,增加了第二设备控制寄存器(Device Control Register 2)用于查看和控制超时时间的值。如下图所示:
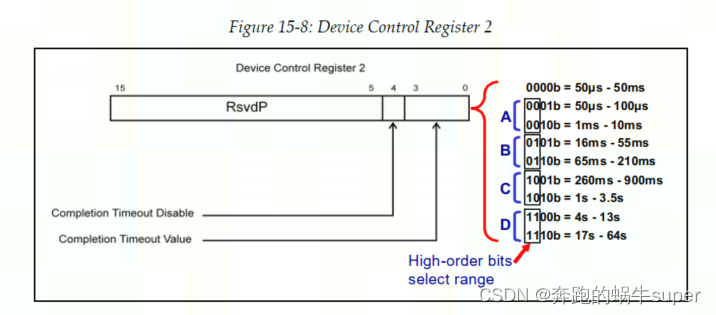
如果,某个请求对应多个Completion,那么除了最后一个Completion,其他的Completion不会造成该请求的定时器停止计时。
5.3.4 Completion Timeout
PCIE 规范规定发出需要 Completions 的 Requests 的 PCIE 设备必须实现 Completion Timeout 机制。配置 Requests 除外。PCIE 设备每发出一个需要 Completions 的Requests,Completion timeout 机制被激活。PCIE Root Complexes, PCI Express-PCI Bridges, 和 Endpoints 需要实现 Completion timeout 机制。Switches 不需要主动发起操作,因而不需要 Completion timeout。
5.4 Link Flow Control Related Errors(流控制相关错误)
链路流量控制相关的错误主要有:
•在FC初始化时,链路相邻设备无法完成针对任何一个VC的,最小的FC Credits的交换更新(Advertises)
•链路相邻设备交换更新(Advertises)的FC Credits超过了最大值(Data Payload最大为2047,Header最大为127)
•链路相邻设备交换更新时,FC Credits为非零值,且该链路的FC Credits之前已经被初始化为无限值了
•接收端Buffer溢出,导致数据丢失(可选的,但是如果使能,则认为是Fatal Error)
5.5 Malformed TLP (格式不正确的TLP)
检查到达事务层的TLP是否违反了数据包格式化规则。数据包格式的违规被视为致命错误,因为这意味着发送器在协议中犯了严重错误,例如未能正确维护计数器,结果是它不再按预期运行。
被认为格式错误的数据包的一些示例包括以下内容:
-
Data Payload超过了最大值(Max Payload Size)
-
数据长度(Data Length)与包头中的长度值不一致
-
存储地址起始位置跨越了4KB边界(Naturally-aligned 4KB Boundary)
-
TD(TLP Digest)的值与ECRC是否使用不一致
-
字节使能冲突(Byte Enable Violation)
-
未定义的类型值(Type Field Values)
-
Completion违反了RCB(Read Completion Boundary)值
-
针对非配置请求返回的Completion中的状态为配置请求重试状态(Configuration Request Retry Status)
-
TC域包含了一个未被分配到当前使能的VC的值(也被称为TC Filtering)
-
IO或者配置请求冲突(可选的)
-
中断Emulation消息向下发送(可选的)
-
TLP前缀错误
5.6 Internal Errors (内部错误)
一般指的是Switch等桥设备内部产生的错误
6 如何报告错误
PCI Express包括三种报告错误的方法,主要介绍第三种报告方式
• Completions — 通过Completion中的状态位向Requestor返回错误信息
• Poisoned Packet — 告知接收端当前TLP的Data Payload已经被破坏
• Error Message —向主机报告错误信息
6.1 Error Messages
为了兼容PCI总线的错误报告机制(使用PERR#和SERR#),PCIe设备会自动将CA、UR和Poisoned TLP转换为对应的错误信息。
PCIe取消了PCI中的边带信号,并将其替换为错误消息。
这些消息提供了PERR#和SERR#信号无法传达的信息,例如识别检测功能和指示错误的严重性。
下图显示了错误消息格式。它们被路由到RC进行处理。
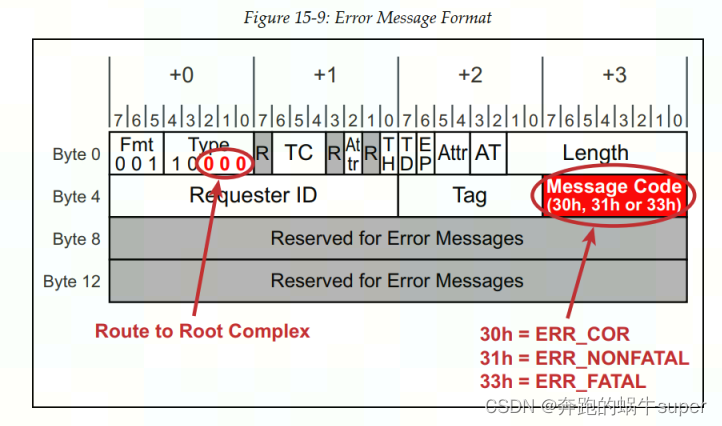
消息代码定义了用信号发送的消息的类型
规范定义了三种类型的错误消息
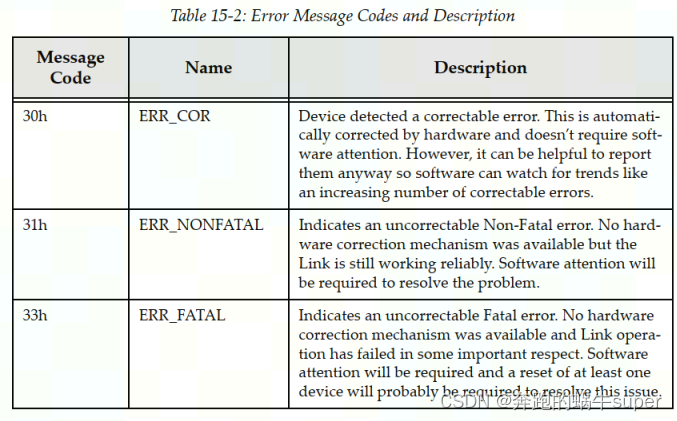
6.1.1 Advisory Non-Fatal Error(警告性的非致命错误)
在一些情况下如果检测到ERR_NONFATAL错误的设备并不是最终决定错误处理的设备,设备如果配有AER则发送ERR_COR提醒软件,若果没有配置AER则不发送消息通知软件。PCIe规定以下几种情况为警告性的非致命错误:
-
Completer Sending a Completion with UR/CA Status
-
Intermediate Receive
-
Ultimate PCIExpress Receiver of a Poisoned TLP
-
Requester with completion timeout
-
Receiver of an unexpected completion
7. Baseline Error Detection and Handling
Baseline Error Reporting:该机制是PCIe设备必需支持的一种错误报告机制,同时设备会定义最小的错误报告请求。是通过配置Device Control和Command寄存器做到通知其他设备产生了错误的一种机制。
Legacy Command and Status Registers
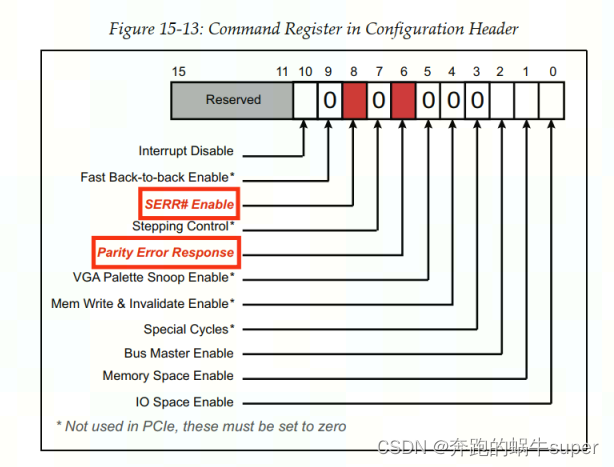
SERR# Enable
:当该Bit被置1时,设备检测到FATAL或者NON_FATAL ERROR允许设备通过Message的形式向RC发送ERR_FATAL或者ERR_NONFATAL Message。
Parity Error Response
:当该Bit被置1时,允许设备通过Device Status Register中的Master Data Parity Error Bit logging Poisoned Data。
由以上定义可以看出:PCI-Compatible Command Register中的SERR# Enable Bit不再表示当设备发生System Error时(硬件将Device States寄存器的Signaled System Error State Bit置1) 会通过Assert SERR# sideband signal触发NMI interrupt,而是通过Error Message的形式向RC报告dev发生了Fatal Error或者Non-Fatal Error。


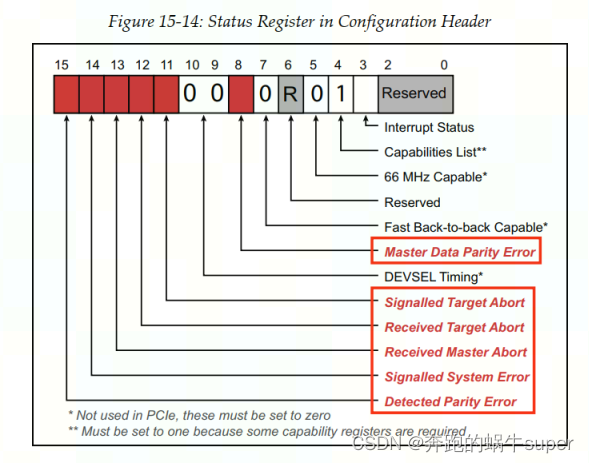
Master Data Parity Error
:当Port Device或者Device接收到Poisoned Completion或者发出Poisoned Request时该Bit被置1(如果Device Command Register中Parity Error Response bit被置1).
Signaled Target Abort
:当Device发出的Posted Request或者Non-Posted Request收到以一笔Target Abort状态结束Translation时,该Bit被置1.
Received Target Abort
: 当Bus Master Device发出一笔Request,收到了这个Request对应的Response是Target Abort状态时,该Bit被置1。即该Device发出的请求,目标设备暂时无法相应。
Received Master Abort
: 当设备发出一笔Request,收到了这笔Request的Response是Master Abort状态时该Bit会被置1。即该dev发出的Request被认为是Unsupported Request.
Signaled System Error
:当该Bit被置1时,表示该设备检测到一个Uncorrectable Error(Fatal Error或者Non-Fatal Error)并将这个Error通过Error Message的形式上报(如果Device Command Register中的SERR# Enable为1)。Command register的SERR# Enable bit在PCIE中改变意义了,不再是控制是否通过SERR# sideband signal向system报告system error,而是控制这个device是否通过error message来报告Non-Fatal error和fatal error。
Detected Parity Error
:当Device接收到一笔Poisoned TLP该Bit被置1。该Bit被置1不受Device Command Register中的Parity Error Response是否被置为1的影响。
由PCI错误检测和错误报告与PCI-Compatible错误检测和错误报告可知:所有的Fatal Error和Non-Fatal Error都通过Signaled System Error Status来记录,而对于Correctable Error就通过PCI-Compatible Device Status寄存器其他Status来记录。
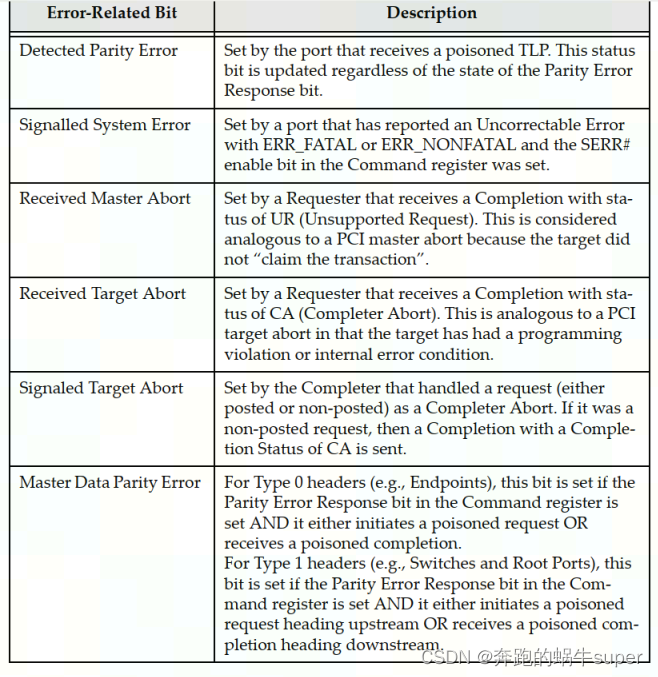
PCIe设备的配置空间中的状态与控制寄存器如下图所示,通过这些寄存器可以使能(或禁止)通过错误消息(Error Message)发送错误报告、查询错误状态信息,以及链路训练和初始化状态等。
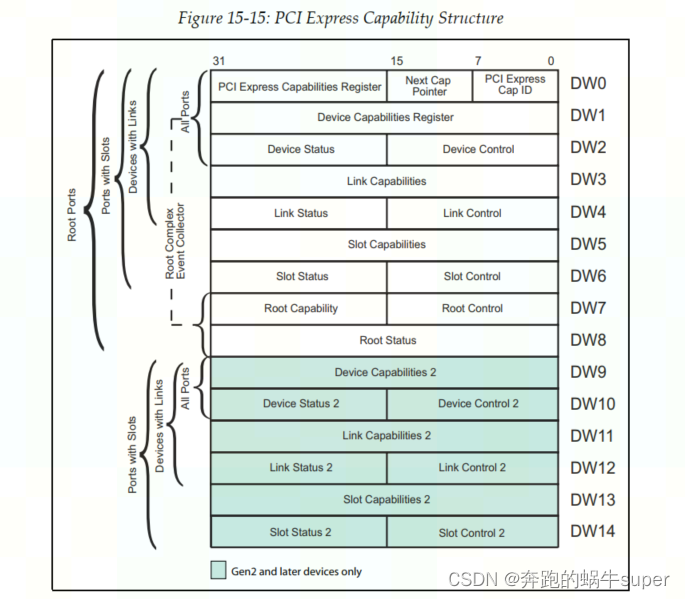
默认的错误分类如下表所示:
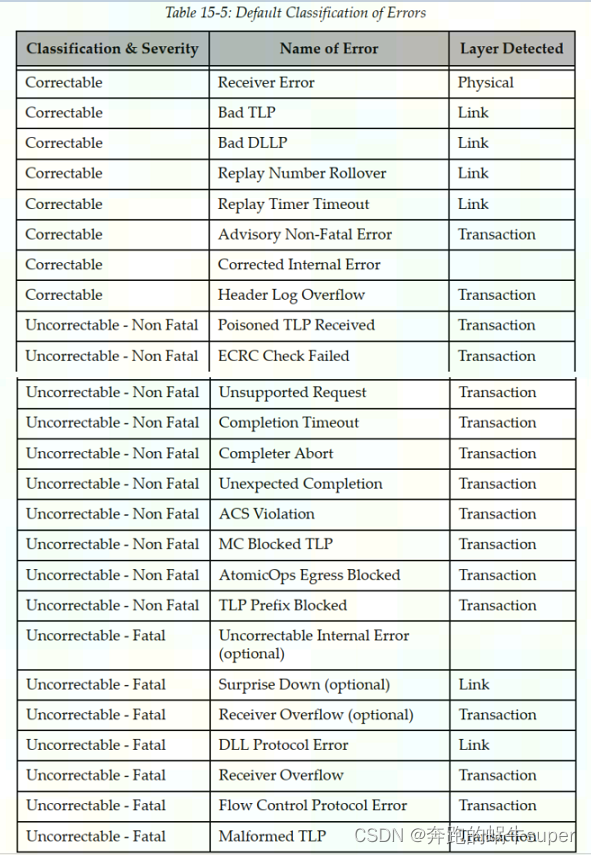
这些错误类型可以通过设备控制寄存器(Device Control Register)中的相关位,进行使能或者禁止:
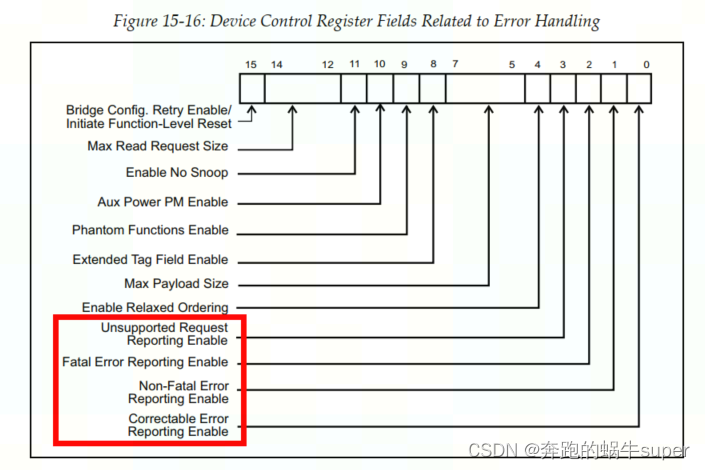
Device Control Register
Correctable Error Reporting Enable
:当该Bit被置1,设备产生Correctable Error时允许设备通过发送Correctable Error Message向RC报告该dev发生了Correctable Error。
Non-Fatal Error Reporting Enable
: 当该Bit被置1,设备产生Non-Fatal Error时允许设备通过发送Non-Fatal Error Message向RC报告该dev发生了Non-Fatal Error。
Fatal Error Reporting Enable
: 当该Bit被置1,设备产生Fatal Error时允许设备通过发送Fatal Error Message向RC报告该dev发生了Fatal Error。
Unsupported Request Reporting Enable
: 当该Bit被置1,设备接收到一笔Unsupported Request时允许设备通过发送Unsupported Request Error Message向RC报告该dev发生了Unsupported Request Error。
也可以通过设备状态寄存器(Device Status Registers)相关位查询错误状态:

Device Status Register
Correctable Error Detected
:当Device检测到Correctable Error时,该Bit被置1(该Bit被置1与Device Control Register中的Correctable Error Enable Bit是否被置1无关)。
Non-Fatal Error Detected
:当Device检测到Non-Fatal Error时,该Bit被置1(该Bit被置1与Device Control Register中的Non-Fatal Error Enable Bit是否被置1无关)
Fatal Error Detected
:当Device检测到Fatal Error时,该Bit被置1(该Bit被置1与Device Control Register中的Fatal Error Reporting Enable Bit是否被置1无关)
Unsupported Request Detected
:当Device检测到Unsupported Request Error时,该Bit被置1(该Bit被置1与Device Control Register中的Unsupported Request Reporting Enable Bit是否被置1无关)。
当PCIE设备检测到Error时,硬件就会根据以上的表将错误所在的类型记录Device Status Register中的Non-Fatal Error Detected,Fatal Error Detected或者Correctable Error Detected Status Bit中,同时也会根据检测到的错误类型将PCI Device Status Register中的相应Bit置1(如果是Fatal Error或者Non-Fatal Error将Signaled System Error Bit置1,如果是Correctable Error将会Correctable Error类型将PCI Device Status Register中的相应Bit位置1)。如果发生Unsupported Request Error,除了将Non-Fatal Error Detected Status Bit置1还会将Unsupported Request Detected Status Bit置1。也就是说如果发生Error,PCIE Device Status Register和PCI Compatible Status Register都会Log这笔错误,清除PCI Compatible Status Register中的错误状态位将不会影响PCIE Device Status Register中的错误状态位的值
Root接收到错误消息后,怎么处理还要取决于Root Control Register的设置:

PCIE Root Control Register
的描述
System Error on Fatal Error Enable
:当该Bit被置1,如果Root Port收到Fatal Error类型的Error Message时,应该产生System Error告知系统。
System Error on Non-Fatal Error Enable
:当该Bit被置1,如果Root Port收到Non-Fatal Error类型的Error Message时,应该产生System Error告知系统。
System Error on Correctable Error Enable
:当该Bit被置1,如果Root Port收到Correctable Error类型的Error Message时,应该产生System Error告知系统。
链路错误(Link Errors)一般发生在物理层与数据链路层通信的过程中。对于Downstream的设备,如果链路上发生了Fatal错误,此时,该设备并不能够向Root报告错误。这种情况下,需要Upstream设备向Root来报告错误。为了消除链路错误,一般需要对链路进行重新训练(Retrain)。如下图所示,在链路控制寄存器中,可以通过往Retrain Link这一位写1,来强制进行链路重训练。
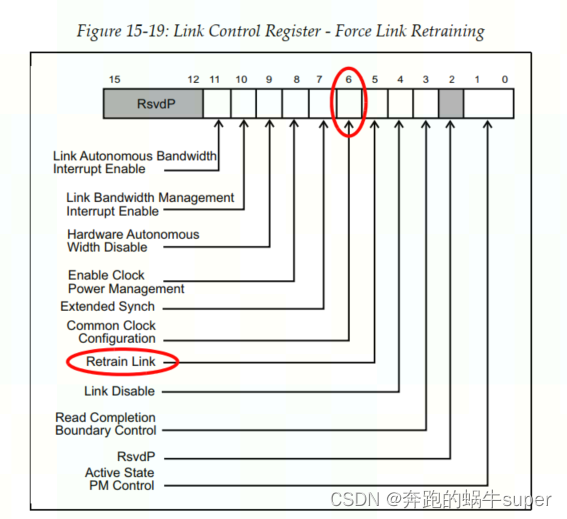
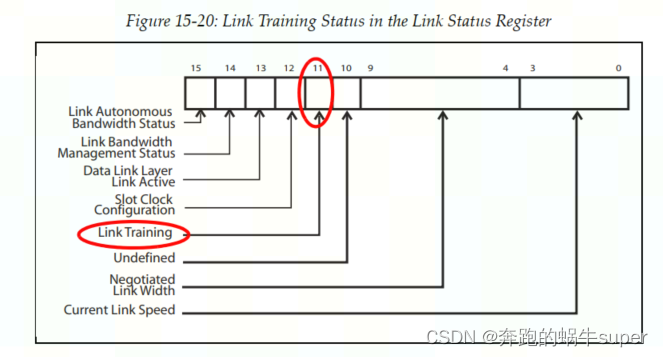
当发起重训练请求后,软件可以检查链路状态寄存器(Link Status Register)中的Link Training位,来确认链路训练是否已经完成,如下图所示。当该位为1时,表明链路训练尚未完成(或者还没有开始),如果链路训练已经完成,硬件会自动将该位清零。
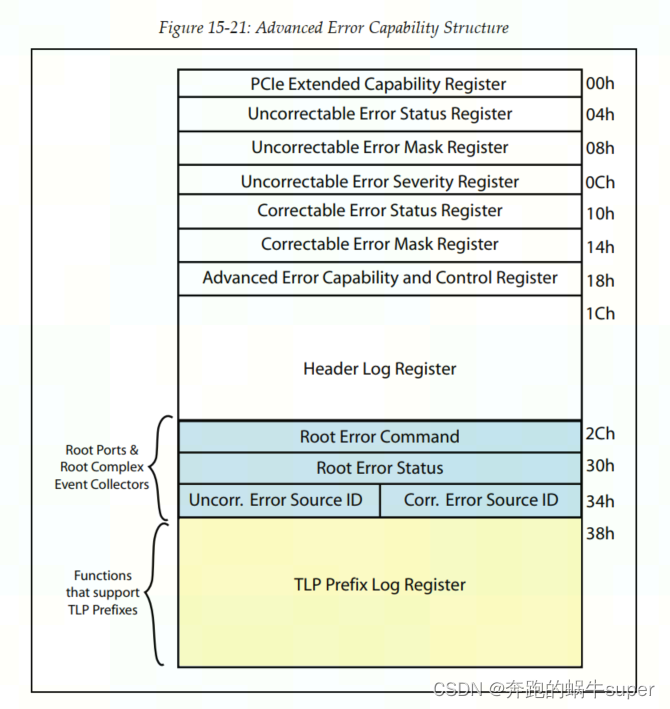
8. Advanced Error Reporting (AER)
PCIE baseline capability只是能记录设备发生了Correctable Error,Non-Fatal Error,Fatal Error这三种错误类型的中哪一种,并没法记录到底发生了哪种错误,这就需要AER来log设备具体发生了哪些错误。
高级错误报告结构如下图所示
允许更复杂的错误处理。这些寄存器提供
几个附加功能:
•记录实际发生的错误类型时具有更好的粒度
•控制以指定每种不可纠正错误类型的严重性
•支持记录有错误的数据包的标头
•标准化根报告接收到的带有中断的错误消息的控制
•识别PCIe拓扑中的错误源
•屏蔽报告个别类型错误的能力
ECRC的产生于校检需要AER的支持,相关控制bit位于高级错误功能控制寄存器中,如下图所示
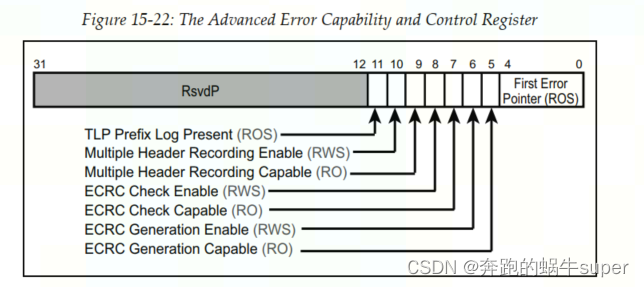
Advanced Error Capabilities and Control Register
First Error Pointer
:硬件将Uncorrectable Error Status寄存器中第一个错误所在的位置记录在First Error Pointer中以便软件在进行AER错误处理的时候知道哪一个Uncorrectable Error是最先产生的。当SW清掉第一个error对应的status bit,那这个First Error Pointer就会被HW update,指向第二个error所对应的status bit,直到所有的error所对应的status bit都被clear掉之后,这个First Error Pointer就会指向无效的位置(uncorrectable error status register的bit0在当前的Spec中就是无效的)或者指向一个值为0的bit。需要注意的是,如果一个error resource被mask,虽然它的uncorrectable error status register bit会被置上,但它不会记录在这个multiple error handling机制的内部寄存器中。
ECRC Generation Capable
:当该Bit被置1时,表示该设备支持生成ECRC校验的能力。
ECRC Generation Enable
:当该Bit被置1时,表示该设备使能生成ECRC校验。
ECRC Check Capable
:当该Bit被置1时,表示该设备支持对ECRC检查的能力。
ECRC Check Enable
:当该Bit被置1时,表示该设备使能对ECRC检查的能力。
Multiple Header Recording Capable
:当该Bit为1时,表示该device具有log多个error packet的header(都是16个byte)到AER capabilities的Header Log Register中去的能力。device需要至少具有记录一个error packet header的能力。如果device具有这种记录多个error packet header的能力,它也是按照error log的顺序来记录的,并且跟上面的First Error Pointer来同步工作。也就是每当clear掉一个status bit(代表着对一个error的处理就结束了),First Error Pointer就指向了下一个error,同时Header Log Register中就报告下一个error所对应的packet的header啦。
Multiple Header Recording Enable
:当该Bit被置1时,表示该设备使能记录多个Error TLP Header的能力。
TLP Prefix Log Present
:表示该device是否具有Log error TLP Prefix到AER TLP Prefix Log Register中去的能力,如果这个TLP Prefix Log Present bit为1,就表明TLP Prefix Log Register中包含有效值,否则就是包含无效值。
其中,最低5bits为当前错误指针(First Error Pointer),当相关错误状态更新时,该指针由硬件自动更新。一般情况下,当前错误指针指向的错误是优先级最高的错误,需要最先被处理的,往往也是其他错误的根源。PCIe Spec V2.1还支持多个错误的追踪(Tracking Multiple Errors)。
图中的ROS、RWS、RO等字符的意义如下:
· RO——只读(Read Only),由硬件控制
· ROS——只读且不被复位(Read Only and Sticky)
· RsvdP——保留且不可以用于其他用途
· RsvdZ——保留且只能被写0
· RWS——可读可写且不被复位(Readable,Writeable and Sticky)
· RW1CS——可读,写1清零,且不被复位
8.1 Advanced Correctable Error Handling
8.1.1 Advanced Correctable Error Status
高级可校正错误状态寄存器如下图所示,当相关错误发生后,硬件会自动地将对应bit置1。软件可以通过向对应bit写1,来清零。

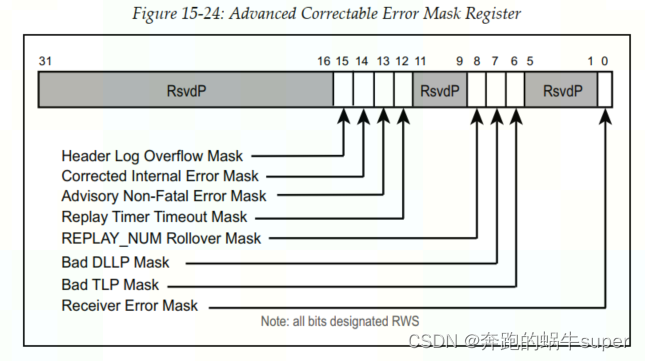
8.1.2 Advanced Correctable Error Masking
高级可校正错误屏蔽寄存器如下图所示,默认情况下,这些bit的值都是0。也就是说,只要发生相关错误,且该错误报告功能被使能,则相关错误便会被报告(不被屏蔽)。当然,软件可以通过将相关bit置1,来屏蔽相关的错误报告信息。
8.2 Advanced Uncorrectable Error Handling
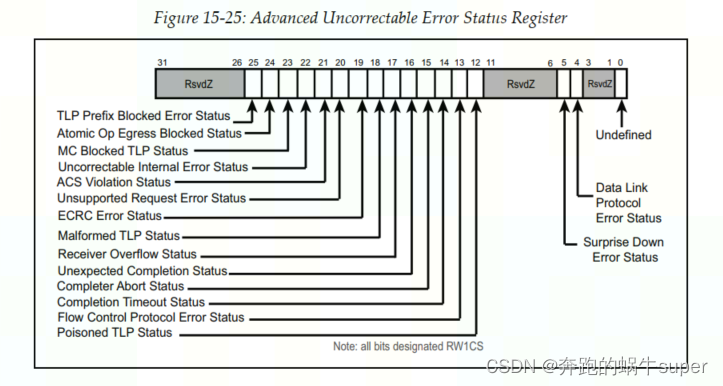
8.2.1 Advanced Uncorrectable Error Status
高级不可校正错误状态寄存器如下图所示,当相关错误发生时,不管这些错误会不会被报告到Root,相关的bit都会被置1。
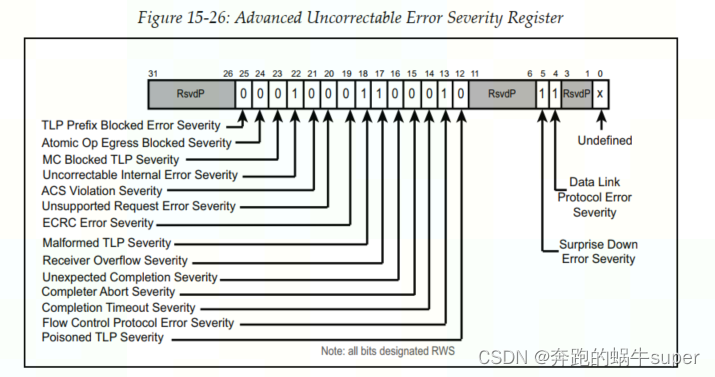
8.2.2 Selecting Uncorrectable Error Severity
软件可以选择不可纠正的错误是否应在此寄存器中被视为致命错误,从而允许不同应用程序对错误进行不同的处理。例如,如前所述,Poisoned TLP 默认为非致命情况,在某些情况下被视为咨询非致命错误。但软件可以通过将其严重性设置为1将其升级为致命,然后它将不再是一个咨询案例。默认严重性值如下图中的各个位字段所示(1=致命,0=非致命)。如果它们被启用且未被屏蔽,则那些被选为非致命的错误将导致向根复合体发送ERR_NONFATAL消息,而那些被选作致命的错误则会导致ERR_Fatal消息。
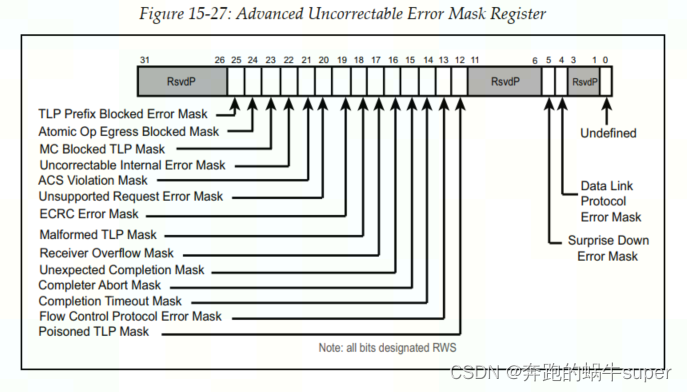
8.2.3 Uncorrectable Error Masking
高级不可校正错误屏蔽寄存器如下图所示,当相关bit被置1时,对应的错误类型将不会被报告。
8.3 AER错误处理
当Error Message发送到Root Port, Root Port就会通过Root Error Status Register记录收到的错误消息类型。如果是Root Port自身检测到错误,也会将Root Error Status Register中相应错误状态位置1。在Root Port收到错误消息后,可以通过Root Error Command Register控制Root Port收到Error Message后是否产生AER中断。Root Port Error Status Register定义如下:

Root Error Status Register
ERR_COR Received
:当Root Port收到Correctable Error Message后该Bit被置1.
Multiple ERR_COR Received
:当Root Error Status Register中的ERR_COR Received Bit被置1且Root Port再次收到了Correctable Error Message,该Bit被置1。
ERR_FATAL/NONFATAL Received
:当Root Port接收到Uncorrectable Fatal或者Non-Fatal Message后且该Bit为0时,该Bit被置1。
First Uncorrectable Fatal
:当Root Port收到的第一个uncorrectable error message是ERR_FATAL error message。
Non-Fatal Error Messages Received
:当Root Port收到一个或者多个Non-Fatal Error Messages后该Bit被置1。
Fatal Error Messages Received
:当Root Port收到一个或者多个Fatal Error Messages后该Bit被置1。
Advanced Error Interrupt Message Number
:定义了root port针对收到的error message将使用MSI/MSIX的哪个entry来产生中断。这个field由HW给出的,并且可能会随着enable MSI/MSIX entry数目的不同而变化。
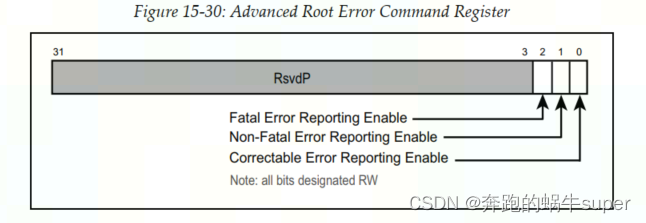
Root Error Command Register
Correctable Error Reporting Enable
:当该Bit被置1,Root Port收到Correctable Error Message后将通过Root Port产生中断。
Non-Fatal Error Reporting Enable
:当该Bit被置1,Root Port收到Non-Fatal Error Message后将通过Root Port产生中断。
Fatal Error Reporting Enable
:当该Bit被置1,Root Port收到Fatal Error Message后将通过Root Port产生中断。
8.4 PCIE AER错误处理的硬件流程
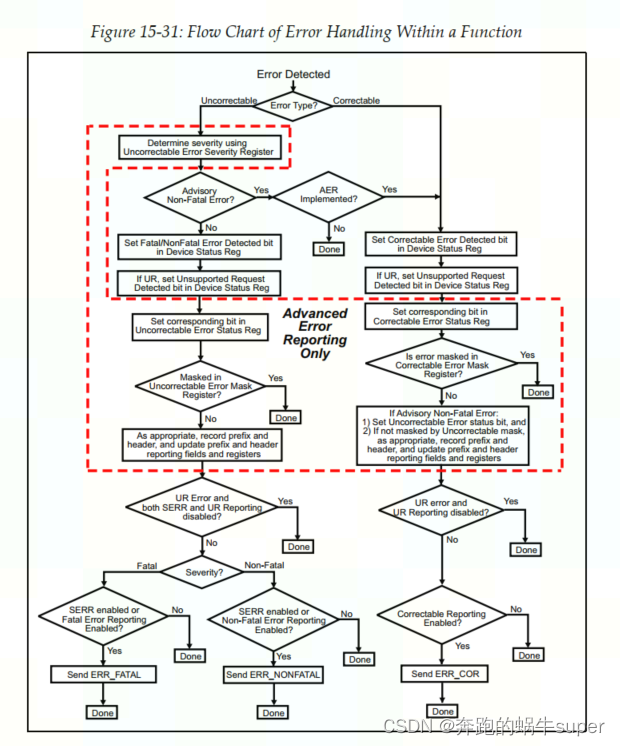
8.4.1 Uncorrectable Error的硬件处理流程
当PCIE dev检测到Uncorrectable Error发生时,硬件首先检查PCIE Device的Uncorrectable Error Severity Register对应Uncorrectable Error的Severity来决定是将该Uncorrectable Error是以Fatal Error Message还是Non-Fatal Error Message上报。
如果系统需要把Uncorrectable Error 作为Advisory Non-Fatal Error处理(需要满足一定的case),则该Uncorrectable Error就交给Correctable Error的情况来处理吧。
在确定了Uncorrectable Error的Severity等级后(通过AER Uncorrectable Error Severity Register),硬件就知道把该错误当成Fatal Error来处理还是Non-Fatal Error来处理。之后通过Device States Register记录该设备产生的错误类型(Uncorrectable Non-Fatal Error还是Uncorrectable Fatal Error),如果该错误是一个Unsupported Request Error则将 Device States Register中的Unsupported Request Detected Bit位置1。
如果Device支持AER,则也需要将AER Uncorrectable Error States Register中相关错误状态位置1,之后需要硬件检查AER Uncorrectable Error Mask Register中相关Error的Mask Bit,以此决定是否需要发送Error Non-Fatal Message或者Error Fatal Message到Root Port(发送Error Non-Fatal/Fatal Message取决于AER Uncorrectable Error Severity Register相关Error的Severity的值)。如果AER Uncorrectable Error Mask Register相关错误的Mask Bit为1则AER的处理从此结束,否则通过AER的Header Log Register和其他Log寄存器记录Uncorrectable Error的TLP Header。此后就是准备发送Uncorrectable Fatal Error或者Uncorrectable Non-Fatal Error Message的过程。需要注意的是对于Unsupported Request Error,如果Device Control Register中的Unsupported Request Reporting Enable Bit和PCI 配种空间的PCI Command Register中SERR# Enable Bit都为0,则表示不需要将Unsupported Request Error报告到RC,则硬件对Unsupported Request Error的处理结束。
之后硬件判断DPC是否被Uncorrectable Error触发,如果Uncorrectable Error被触发则硬件设置DPC Trigger Status以及DPC被触发的原因的相关寄存器Bit的配置。之后交给DPC硬件来处理Uncorrectable Error。否则需要根据相关错误的Severity的值确定向Root Complex发送Non-Fatal Error Message还是Fatal Error Message(当然也需要Device Control Register Non-Fatal Error Reporting Enable Bit/Fatal Error Reporting Enable Bit为1或者PCI Command Register中的SERR# Enable Bit为1)。
8.4.2 Correctable Error的硬件处理流程
当PCIE dev检测到Correctable Error发生时,硬件首先将Device Status Register中的Correctable Error Detected Bit置1表示dev检测到Correctable Error发生。如果Unsupported Request Error被当作advisory non-fatal error处理且发生了Unsupported Request则硬件将Device States Register中的Unsupported Request Detected Bit置1。
如果设备支持AER,则也需要将AER Correctable Error Status寄存器中的相关错误Bit置1,之后硬件通过获取AER Correctable Error Mask寄存器中的相关错误的Mask Bit决定是否要将错误通过Error Message向RC发送。如果AER Correctable Error Mask寄存器中的相关错误的Mask Bit为1,则硬件对Correctable Error的处理结束。
而对于Advisory Non-Fatal Error,则依然需要通过Uncorrectable Error Status寄存器记录Uncorrectable Error。如果相关Advisory Non-Fatal Error Mask为0,则硬件需要将Advisory Non-Fatal Error的TLP Header记录在Header Log Register中。
对于Unsupported Request Error,则需要硬件判断Device Control Register中的Unsupported Request Reporting Enable Bit是否为1,如果不为1则表示设备不希望将Unsupported Request Error告知RC,Unsupported Request Error的处理结束。
对于其他类型的Correctable Error,硬件通过获取Device Control Register中的Correctable Error Reporting Enable Bit的值确定是否需要发送Correctable Error Message到RC。如果Correctable Error Reporting Enable Bit为0,则硬件对Correctable Error的处理从此退出。否则硬件需要向RC发送Correctable Error Message告知RC,该dev发生了Correctable Error。