本文将介绍一些简单的使用Python3实现关键词提取的算法。目前仅整理了一些比较简单的方法,如后期将了解更多、更前沿的算法,会继续更新本文。
文章目录
1. 基于TF-IDF算法的中文关键词提取:使用jieba包实现
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"
import jieba.analyse
print(jieba.analyse.extract_tags(extracted_sentences, topK=20, withWeight=False, allowPOS=()))
输出:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.457 seconds.
Prefix dict has been built successfully.
['预测', '模型', '销量', '降低库存', '企业', 'AI', '规划', '提高', '准确性', '助力', '交货', '算法', '计量', '序列', '较差', '繁多', '过多', '假设', '缩短', '营销']
函数入参:
-
topK
:返回TF-IDF权重最大的关键词的数目(默认值为20) -
withWeight
是否一并返回关键词权重值,默认值为 False -
allowPOS
仅包括指定词性的词,默认值为空,即不筛选
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径:
用法:
jieba.analyse.set_idf_path(file_name)
# file_name为自定义语料库的路径
自定义语料库示例:
https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
用法示例:
https://github.com/fxsjy/jieba/blob/master/test/extract_tags_idfpath.py
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径:
用法:
jieba.analyse.set_stop_words(file_name)
# file_name为自定义语料库的路径
自定义语料库示例:
https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
用法示例:
https://github.com/fxsjy/jieba/blob/master/test/extract_tags_stop_words.py
2. 基于TextRank算法的中文关键词提取:使用jieba包实现
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"
import jieba.analyse
print(jieba.analyse.textrank(extracted_sentences, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
输出:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.451 seconds.
Prefix dict has been built successfully.
['企业', '预测', '模型', '规划', '提高', '销量', '比如', '时间', '市场', '分析', '降低库存', '成本', '缩短', '交货', '影响', '因素', '情况', '计量', '现实', '数据']
入参和第一节中的入参相同,但
allowPOS
的默认值不同。
TextRank用固定窗口大小(默认为5,通过span属性调整),以词作为节点,以词之间的共现关系作为边,构建无向带权图。
然后计算图中节点的得分,计算方式类似PageRank。
对PageRank的计算方式和原理的更深入了解可以参考我之前撰写的博文:
cs224w(图机器学习)2021冬季课程学习笔记4 Link Analysis: PageRank (Graph as Matrix)_诸神缄默不语的博客-CSDN博客
3. 基于TextRank算法的中文关键词提取(使用textrank_zh包实现)
待补。
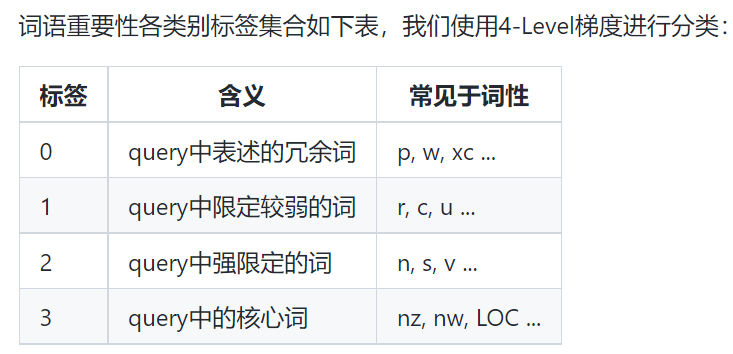
3. 没说基于什么算法的中文词语重要性:LAC实现
最后输出的数值就是对应词语的重要性得分。
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"
from LAC import LAC
lac=LAC(mode='rank')
seg_result=lac.run(extracted_sentences) #以Unicode字符串为入参
print(seg_result)
输出:
W0625 20:13:22.369424 33363 init.cc:157] AVX is available, Please re-compile on local machine
W0625 20:13:22.455566 33363 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:13:22.455617 33363 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
W0625 20:13:22.561131 33363 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:13:22.561169 33363 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
[['随着', '企业', '持续', '产生', '的', '商品', '销量', ',', '其', '数据', '对于', '自身', '营销', '规划', '、', '市场分析', '、', '物流', '规划', '都', '有', '重要', '意义', '。', '但是', '销量', '预测', '的', '影响', '因素', '繁多', ',', '传统', '的', '基于', '统计', '的', '计量', '模型', ',', '比如', '时间', '序列', '模型', '等', '由于', '对', '现实', '的', '假设', '情况', '过多', ',', '导致', '预测', '结果', '较差', '。', '因此', '需要', '更加', '优秀', '的', '智能', 'AI算法', ',', '以', '提高', '预测', '的', '准确性', ',', '从而', '助力', '企业', '降低', '库存', '成本', '、', '缩短', '交货', '周期', '、', '提高', '企业', '抗', '风险', '能力', '。'], ['p', 'n', 'vd', 'v', 'u', 'n', 'n', 'w', 'r', 'n', 'p', 'r', 'vn', 'n', 'w', 'n', 'w', 'n', 'n', 'd', 'v', 'a', 'n', 'w', 'c', 'n', 'vn', 'u', 'vn', 'n', 'a', 'w', 'a', 'u', 'p', 'v', 'u', 'vn', 'n', 'w', 'v', 'n', 'n', 'n', 'u', 'p', 'p', 'n', 'u', 'vn', 'n', 'a', 'w', 'v', 'vn', 'n', 'a', 'w', 'c', 'v', 'd', 'a', 'u', 'n', 'nz', 'w', 'p', 'v', 'vn', 'u', 'n', 'w', 'c', 'v', 'n', 'v', 'n', 'n', 'w', 'v', 'vn', 'n', 'w', 'v', 'n', 'v', 'n', 'n', 'w'], [0, 1, 1, 1, 0, 2, 2, 0, 1, 2, 0, 1, 2, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 0, 0, 2, 2, 0, 2, 1, 2, 0, 2, 0, 0, 2, 0, 2, 1, 0, 1, 2, 2, 1, 0, 0, 0, 2, 0, 2, 1, 2, 0, 1, 2, 2, 2, 0, 0, 1, 1, 2, 0, 2, 2, 0, 0, 2, 2, 0, 2, 0, 0, 2, 1, 1, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 2, 2, 0]]
4. KeyBert
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import TfidfVectorizer
# 导入Bert模型
from sentence_transformers import SentenceTransformer
# 导入计算相似度前置库,为了计算候选者和文档之间的相似度,我们将使用向量之间的余弦相似度,因为它在高维度下表现得相当好。
from sklearn.metrics.pairwise import cosine_similarity
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
# 读取数据集
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
test['text'] = test['title'].fillna('') + ' ' +test['abstract'].fillna('')
#停用词文件链接:https://pan.baidu.com/s/1mQ50_gsKZHWERHzfiDnheg?pwd=qzuc
# 定义停用词,去掉出现较多,但对文章不关键的词语
stops =[i.strip() for i in open(r'stop.txt',encoding='utf-8').readlines()]
model = SentenceTransformer(r'xlm-r-distilroberta-base-paraphrase-v1')
#这里我们使用distiluse-base-multilingual-cased,因为它在相似性任务中表现出了很好的性能,这也是我们对关键词/关键短语提取的目标!
#由于transformer模型有token长度限制,所以在输入大型文档时,你可能会遇到一些错误。在这种情况下,您可以考虑将您的文档分割成几个小的段落,并对其产生的向量进行平均池化(mean pooling ,要取平均值)。
#提取关键词
#这里我的思路是获取文本内容的embedding,同时与文本标题的embedding进行比较,文章的关键词往往与标题内容有很强的相似性,为了计算候选者和文档之间的相似度,我们将使用向量之间的余弦相似度,因为它在高维度下表现得相当好。
test_words = []
for row in test.iterrows():
# 读取第每一行数据的标题与摘要并提取关键词
# 修改n_gram_range来改变结果候选词的词长大小。例如,如果我们将它设置为(3,3),那么产生的候选词将是包含3个关键词的短语。
n_gram_range = (2,2)
# 这里我们使用TF-IDF算法来获取候选关键词
count = TfidfVectorizer(ngram_range=n_gram_range, stop_words=stops).fit([row[1].text])
candidates = count.get_feature_names_out()
# 将文本标题以及候选关键词/关键短语转换为数值型数据(numerical data)。我们使用BERT来实现这一目的
title_embedding = model.encode([row[1].title])
candidate_embeddings = model.encode(candidates)
# 通过修改这个参数来更改关键词数量
top_n = 15
# 利用文章标题进一步提取关键词
distances = cosine_similarity(title_embedding, candidate_embeddings)
keywords = [candidates[index] for index in distances.argsort()[0][-top_n:]]
if len( keywords) == 0:
keywords = ['A', 'B']
test_words.append('; '.join( keywords))
test['Keywords'] = test_words
test[['uuid', 'Keywords']].to_csv('submit_task2.csv', index=None)
5. 基于词频的
包括unigram和bigram
# 引入分词器
from nltk import word_tokenize, ngrams
# 定义停用词,去掉出现较多,但对文章不关键的词语
stops = [
'will', 'can', "couldn't", 'same', 'own', "needn't", 'between', "shan't", 'very',
'so', 'over', 'in', 'have', 'the', 's', 'didn', 'few', 'should', 'of', 'that',
'don', 'weren', 'into', "mustn't", 'other', 'from', "she's", 'hasn', "you're",
'ain', 'ours', 'them', 'he', 'hers', 'up', 'below', 'won', 'out', 'through',
'than', 'this', 'who', "you've", 'on', 'how', 'more', 'being', 'any', 'no',
'mightn', 'for', 'again', 'nor', 'there', 'him', 'was', 'y', 'too', 'now',
'whom', 'an', 've', 'or', 'itself', 'is', 'all', "hasn't", 'been', 'themselves',
'wouldn', 'its', 'had', "should've", 'it', "you'll", 'are', 'be', 'when', "hadn't",
"that'll", 'what', 'while', 'above', 'such', 'we', 't', 'my', 'd', 'i', 'me',
'at', 'after', 'am', 'against', 'further', 'just', 'isn', 'haven', 'down',
"isn't", "wouldn't", 'some', "didn't", 'ourselves', 'their', 'theirs', 'both',
're', 'her', 'ma', 'before', "don't", 'having', 'where', 'shouldn', 'under',
'if', 'as', 'myself', 'needn', 'these', 'you', 'with', 'yourself', 'those',
'each', 'herself', 'off', 'to', 'not', 'm', "it's", 'does', "weren't", "aren't",
'were', 'aren', 'by', 'doesn', 'himself', 'wasn', "you'd", 'once', 'because', 'yours',
'has', "mightn't", 'they', 'll', "haven't", 'but', 'couldn', 'a', 'do', 'hadn',
"doesn't", 'your', 'she', 'yourselves', 'o', 'our', 'here', 'and', 'his', 'most',
'about', 'shan', "wasn't", 'then', 'only', 'mustn', 'doing', 'during', 'why',
"won't", 'until', 'did', "shouldn't", 'which'
]
# 定义方法按照词频筛选关键词
def extract_keywords_by_freq(title, abstract):
ngrams_count = list(ngrams(word_tokenize(title.lower()), 2)) + list(ngrams(word_tokenize(abstract.lower()), 2))
ngrams_count = pd.DataFrame(ngrams_count)
ngrams_count = ngrams_count[~ngrams_count[0].isin(stops)]
ngrams_count = ngrams_count[~ngrams_count[1].isin(stops)]
ngrams_count = ngrams_count[ngrams_count[0].apply(len) > 3]
ngrams_count = ngrams_count[ngrams_count[1].apply(len) > 3]
ngrams_count['phrase'] = ngrams_count[0] + ' ' + ngrams_count[1]
ngrams_count = ngrams_count['phrase'].value_counts()
ngrams_count = ngrams_count[ngrams_count > 1]
return list(ngrams_count.index)[:5]
## 对测试集提取关键词
test_words = []
for row in test.iterrows():
# 读取第每一行数据的标题与摘要并提取关键词
prediction_keywords = extract_keywords_by_freq(row[1].title, row[1].abstract)
# 利用文章标题进一步提取关键词
prediction_keywords = [x.title() for x in prediction_keywords]
# 如果未能提取到关键词
if len(prediction_keywords) == 0:
prediction_keywords = ['A', 'B']
test_words.append('; '.join(prediction_keywords))
test['Keywords'] = test_words
test[['uuid', 'Keywords', 'label']].to_csv('submit_task2.csv', index=None)
其他资料
-
我还没看,但是反正是关于关键词抽取主题的
-
(2023 APSIT)
A Comparative Study on Keyword Extraction and Generation of Synonyms in Natural Language Processing
:对比基于规则的模型、统计模型和extreme learning machine (ELM)模型
-
(2023 APSIT)