目录
前言
一次部署,无限安装?
1 安装nvidia显卡驱动
参考2.2更新驱动:
https://blog.csdn.net/weixin_50008473/article/details/115250986
2 安装docker
详细参考docker官方文档:
https://docs.docker.com/engine/install/ubuntu/
sudo apt install docker.io
重启Docker服务
sudo systemctl daemon-reload
sudo systemctl restart docker
3 Docker 修改容器默认存储位置
(1)
docker info
Docker Root Dir:/var/lib/docker
是镜像和容器默认存储位置
(2)
vim /etc/docker/daemon.json
(若没有则创建)
(3)添加以下内容:
{
"graph":"/data/docker" # 想要修改的存储路径
}
(4)重启docker:
systemctl restart docker
(5)再次查看,确定修改位置正确:
docker info
4 安装docker compose
可以启动多个容器并建立连接。
(1) 下载对应安装包:
sudo curl -L \
"https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" \
-o /usr/local/bin/docker-compose
(2)赋予可执行权限:
sudo chmod +x /usr/local/bin/docker-compose
测试:
sudo docker-compose --version
结果如下图所示:

5 安装nvidia-docker
Docker只能使用CPU 的资源,需要连接Docker 和宿主机的显卡驱动 —— nvidia-docker
(1)设置稳定版的存储库和GPG密钥:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
(2)更新:
sudo apt-get update
(3)安装:
sudo apt-get install -y nvidia-docker2
(4)重启docker:
sudo systemctl restart docker
测试:
sudo docker run --rm --gpus all nvidia/cuda:11.1-base nvidia-smi
6 下载 nvidia CUDA 镜像
1.
sudo vim /etc/docker/daemon.json
2.加入镜像源地址:
添加
"registry-mirrors": [https://docker.mirrors.ustc.edu.cn]
如下图所示:

注:Docker中国区官方镜像:https://registry.docker-cn.com
3.重启docker:
systemctl restart docker.service
4.Nvidia docker cuda 官方镜像:
https://hub.docker.com/r/nvidia/cuda

5.选择需要的 CUDA版本和cuDNN版本,这里选择了 11.1-cudnn8-devel-ubuntu18.04::
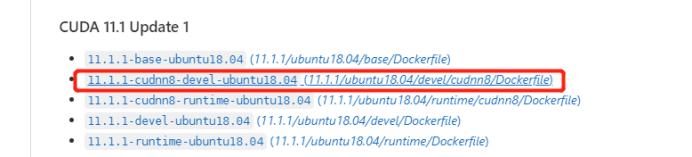
6.再点击 Tags 并根据刚刚选好的名字进行搜索:
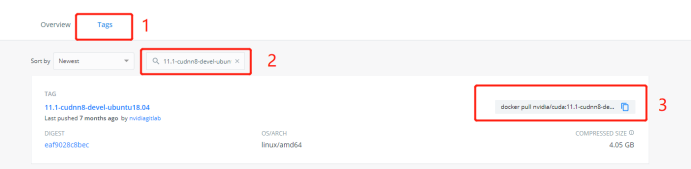
7.下载镜像:
sudo docker pull nvidia/cuda:11.1-cudnn8-devel-ubuntu18.04
8.查看到下载好的镜像:
sudo docker images
9.运行docker镜像
sudo docker run -it --name algorithm -v /data/algorithm:/data/algorithm --runtime=nvidia -e NVIDIA_VISIBLE_DEVICE=all nvidia/cuda:11.1-cudnn8-devel-ubuntu18.04
其中:algorithm为自定义容器名;/data/algorithm:/data/algorithm为项目绝对路径:容器内项目路径;nvidia/cuda:11.1-cudnn8-devel-ubuntu18.04为镜像名称。
(1)测试显卡驱动:
nvidia-smi

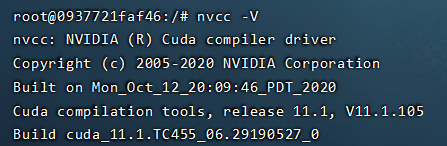
(2)测试 CUDA:
nvcc -V
(3)测试 CUDNN:
ll /usr/lib/x86_64-linux-gnu/ | grep cudnn

7 安装python3.8环境
1.准备:
(1)
sudo apt-get install libffi-dev
(2)
make clean && make && make install
2.下载:
(1)下载地址:
https://www.python.org/ftp/python/3.8.9/Python-3.8.9.tgz
(2)cd 下载路径
(3)解压:
tar -xzvf Python-3.8.9.tgz
(4)
cd Python-3.8.9
3.安装:
./configure prefix=/usr/local/python3
# 指定安装的目录
make && make install
# 编译,安装
4.添加python3和pip3的软链接:
ln -s /usr/local/python3/bin/python3 /usr/bin/python
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip
8 安装pytorch1.8
(1)如果下载慢或者超时,设置源(此处为清华源)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
(2)若出现:
subprocess.CalledProcessError: Command ‘(‘lsb_release’, ‘-a’)’ returned non-zero exit status 1.
解决方法:
find / -name lsb_release
rm -rf /usr/bin/lsb_release
(3)安装torch1.8.0与torchvision0.9.0
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
(4)安装 torchaudio
pip install torchaudio==0.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
9 安装tensorrt7.2.2.3和opencv4.4.0
参考:
https://blog.csdn.net/weixin_50008473/article/details/115250986
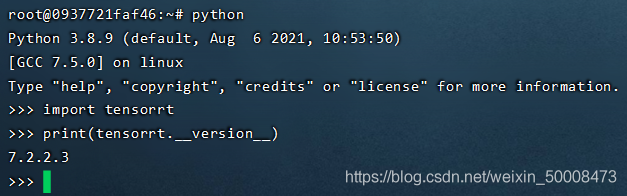
验证安装环境:
10 提交容器成为新镜像并保存本地加载
docker commit -m "提交的描述信息" -a "作者" 容器ID 要创建的目标镜像名称:[标签名]
sudo docker commit -m “v5” -a “double_ww” 0937721faf46 yolov5:1.0
如下图所示:

将镜像保存为本地文件
docker save
IMAGE ID
> 本地路径地址/yolov5.tar
使用load方法加载刚才上传的tar文件
docker load < 本机路径地址/yolov5.tar
load后镜像的REPOSITORY和TAG均为NONE,修改原来的镜像名称和标签名称
docker tag
IMAGE ID
yolov5:latest
加载:docker run -itd –name yolov5 -v 本地路径目录:/容器内路径目录
IMAGE ID
/bin/bash
常用命令附录
启动/停止容器:
docker start/stop container
进入容器:
docker exec -it container bash
退出并停止容器:
exit
只退出容器,不停止容器:
Ctrl+p+q
拷贝文件至容器:
sudo docker cp 文件路径 container:容器路径
删除容器:
docker rm container
查找镜像:
docker search images
下载镜像:
docker pull images
删除镜像:
docker rmi images
列出本地所有的镜像:
docker images -a
列出当前所有正在运行的容器:
docker ps
列出所有的容器:
docker ps -a
强制停止容器:
docker kill container