(本文数据为虚构,仅供实验)
产品地址:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.102.OwEfx2
一、背景
本文将针对阿里云平台上图算法模块来进行实验。图算法一般被用来解决关系网状的业务场景。与常规的结构化数据不同,图算法需要把数据整理成首尾相连的关系图谱。图算法更多的是考虑边和点的概念。阿里云机器学习平台上提供了丰富的图算法组件,包括K-Core、最大联通子图、标签传播聚类等。
本文的业务场景如下:
下图是已知的一份人物通联关系图,每两个人之间的连线表示两人有一定关系,可以是同事关系或者亲人关系等。已知“Enoch”是信用用户,”Evan”是欺诈用户,计算出其它人的信用指数。通过图算法,可以算出图中每个人是欺诈用户的概率,这个数据可以方便相关机构做风控。
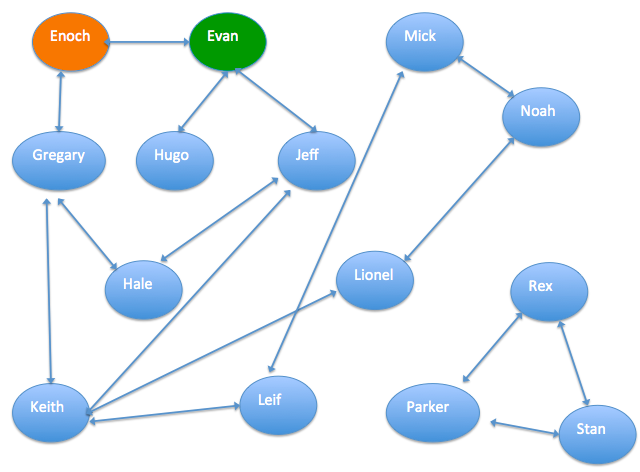
二、数据集介绍
数据源:本文数据为自己生成,用于实验。
具体字段如下:
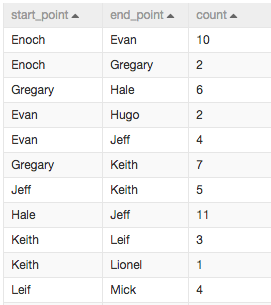
| 字段名 | 含义 | 类型 | 描述 |
|---|---|---|---|
| start_point | 边的起始节点 | string | 人 |
| end_point | 边结束节点 | string | 人 |
| count | 关系紧密度 | double | 数值越大,两人的关系越紧密 |
数据截图:
三、数据探索流程
首先,实验流程图:
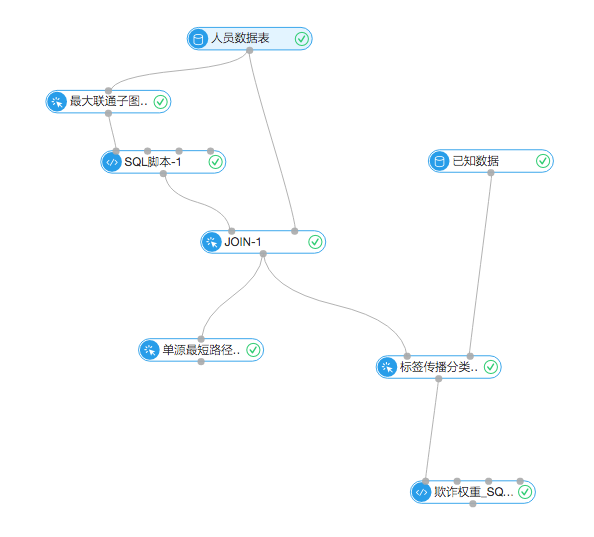
1.最大联通子图
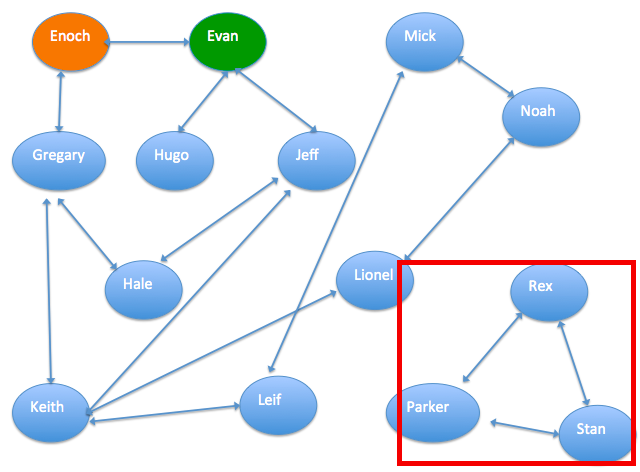
最大联通子图的功能很好理解,前面已经介绍了,图算法的输入数据是关系图谱结构的。最大联通子图可以找到有通联关系的最大集合,在团伙发现的场景中可以排除掉一些与风控场景无关的人。本次实验通过“最大联通子图”组件将数据中的群体分为两部分,并赋予group_id。通过“SQL脚本”组件和“JOIN”组件去除下图中的无关联人员。
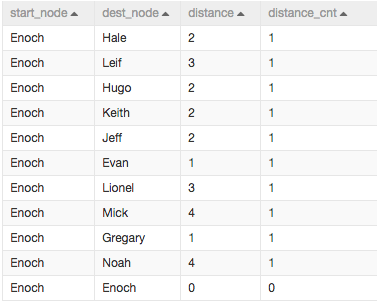
2.单源最短路径
通过“单源最短路径”组件探查出每个人的一度人脉、二度人脉关系等。distance讲的是“Enoch”通过几个人可以联络到目标人。
如下图:
3.标签传播分类
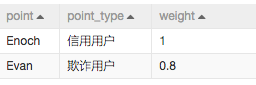
“标签传播分类”算法为半监督的分类算法,原理是用已标记节点的标签信息去预测未标记节点的标签信息。在算法执行过程中,每个节点的标签按相似度传播给相邻节点。
调用“标签传播分类”组件除了要有所有人员的通联图数据以外,还要有人员打标数据。这里通过“已知数据-读odps”组件导入打标数据(weight表示目标是欺诈用户的概率):
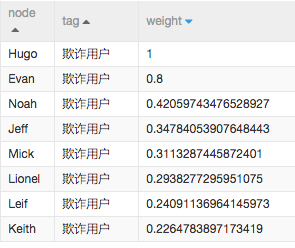
通过SQL对结果进行筛选,最终结果展现的是每个人涉嫌欺诈的概率,数值越大表示是欺诈用户的概率越大。
四、其它
作者微信公众号(与作者讨论):

参与讨论:
云栖社区公众号
免费体验:
阿里云数加机器学习平台