项目场景:
使用QT下的UDPsocket与FPGA进行通信,通过udp每62.5us发送512字节(66M的速度)的数据到PC端中。bind绑定后,connect关联槽函数,在槽函数中死循环接收读取发送过来的数据,为了使用户界面不卡死,开启一条单独的线程运行接收的槽函数。
问题描述:
每62.5us发送512字节大概是66M的速度,PC端使用的是百兆网卡,要求在这个速度下持续运行8小时以上。demo运行时卡顿,数据传输过程中数据时不时出现丢失的情况。查阅资料后发现window提供了接口可以将指定的线程绑定到特定的cpu核心中,可以减少卡顿,加快读取速度减少丢包。
原因分析:
一个程序指定到单独一个CPU上运行会比不指定CPU运行时快。这中间主要有两个原因:
- CPU切换时损耗的性能。
- Intel的自动降频技术和windows的机制冲突:windows有一个功能是平衡负载,可以将一个线程在不同时间分配到不同CPU,从而使得每一个CPU不“过累”。然而,Inter又有一个技术叫做SpeedStep,当一个CPU没有满负荷运行时自动降频从而达到节能减排的目的。这两个功能实际是冲突的:一个程序被分配到多个CPU协同工作->每个CPU都不是满载->每个CPU都会降频->windows发现每个CPU性能都降低了,因此程序执行速度也降低了。
因此,将线程(进程)绑定到指定CPU核心,从而不让windows自作主张帮我们分散任务,从而提高单线程效率是很有必要的。
解决方案:
#include <window.h>
DWORD_PTR SetThreadAffinityMask(HANDLE hThread, DWORD_PTR dwThreadAffinityMask);
参数:
第一个参数hThread:当前进程的句柄,可以通过函数GetCurrentThread()配套使用得到;
第二个参数mask:指定的CPU核心
以我8核电脑为例:
第0个cpu核:mask=0x00
第1个cpu核:mask=0x01
第2个cpu核:mask=0x04
…
第7个cpu核:mask=0x80
示例:将我的udp读取数据线程放在最后一个核中运行
#include <window.h>
SetThreadAffinityMask(GetCurrentThread(), 0x80);
结论:
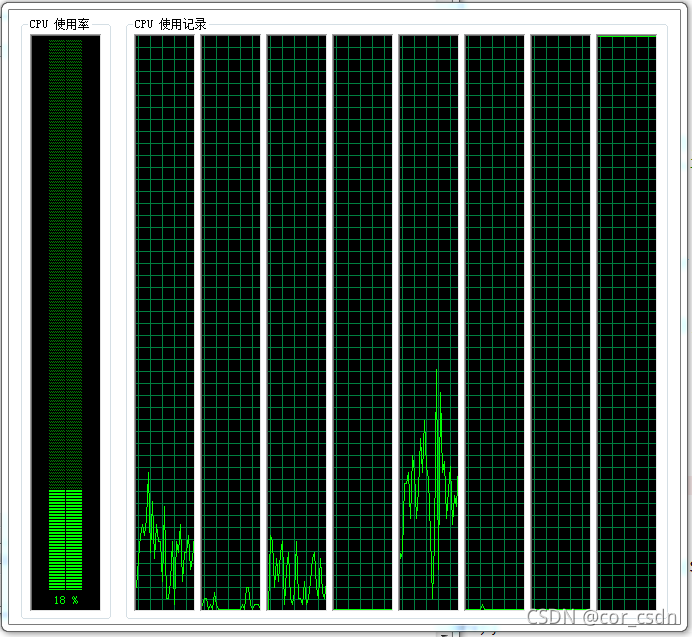

可以看到最后一个cpu已经100%使用率了,已经成功将指定线程移动到该核心上运行。
丢包情况已经改善一些,可是还是有万分之一多的丢包率,如何解决?
更新
丢包就是server端发的太快,客户端cpu处理不过来就丢了,解决思路主要有:
1、udp每个数据包数据长度不要超过mtu限制,杜绝分片,一般为1500Byte以下;
2、增大以太网接口(NIC)传输队列和套接字接收缓冲区,这个方法最直接有效;
3、cpu核心锁定。
优先第二种方法,一般就能解决丢包问题,不行再配合其它办法使用。我用这些办法已经实现90M的速度,长时间运行无丢包了,亲测可行。