对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节。在将数据集加载、融合、准备好之后,通常就是计算分组统计或生成透视表。pandas提供了一个灵活高效的gruopby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
Hadley Wickham(许多热门R语言包的作者)创造了一个用于表示分组运算的术语”split-apply-combine”(拆分-应用-合并)。第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。例如,DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。下图大致说明了一个简单的分组聚合过程。
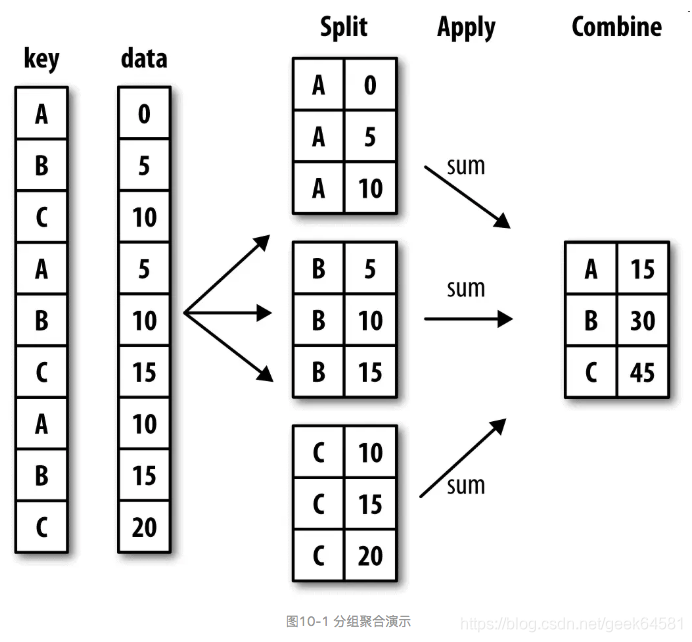
一、分组API
-
DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个
- 案例:不同颜色的不同笔的价格数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
- 进行分组,对颜色分组,price进行聚合
# 分组,求平均值
col.groupby(['color'])['price1'].mean()
col['price1'].groupby(col['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
# 分组,数据的结构不变
col.groupby(['color'], as_index=False)['price1'].mean()
color price1
0 green 2.025
1 red 2.380
2 white 5.560
二、星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
数据来源:https://www.kaggle.com/starbucks/store-locations/data
2.1 数据获取
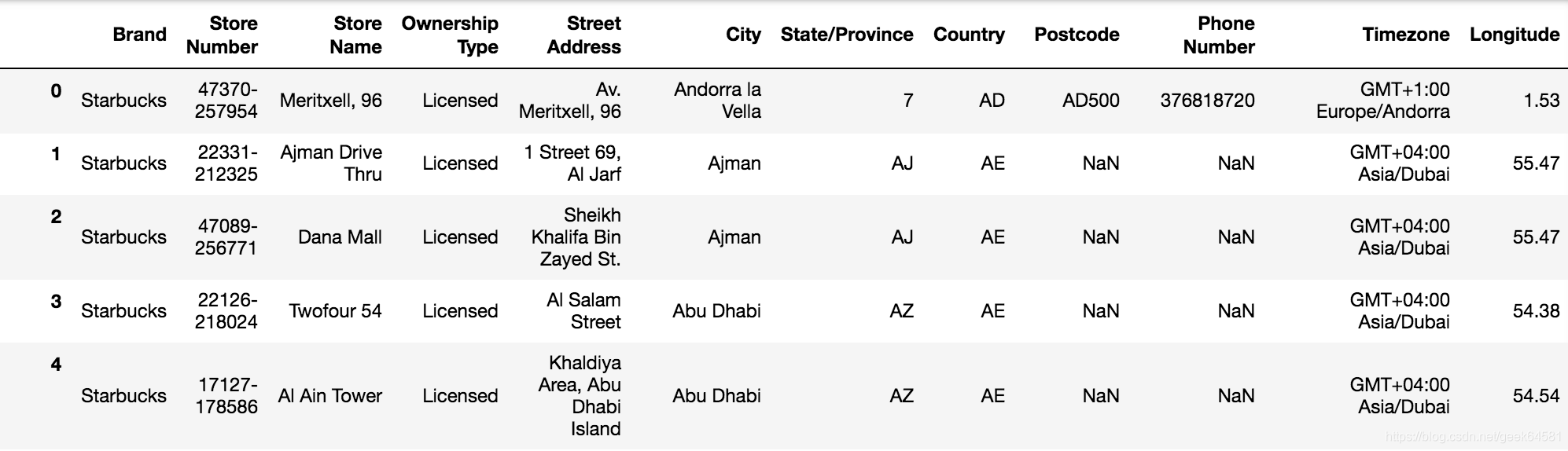
从文件中读取星巴克店铺数据
# 导入星巴克店的数据
starbucks = pd.read_csv("./data/starbucks/directory.csv")
2.2 进行分组聚合
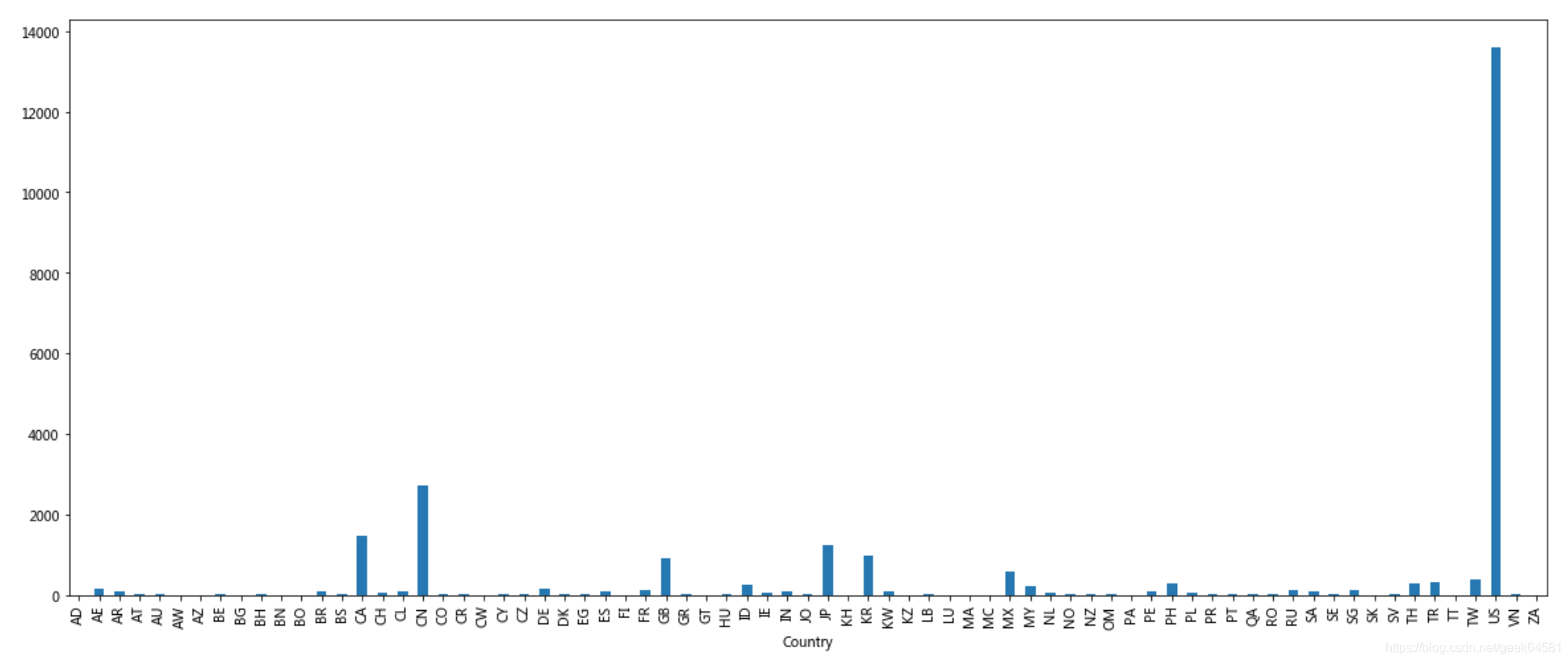
# 按照国家分组,求出每个国家的星巴克零售店数量
count = starbucks.groupby(['Country']).count()
画图显示结果
count['Brand'].plot(kind='bar', figsize=(20, 8))
plt.show()
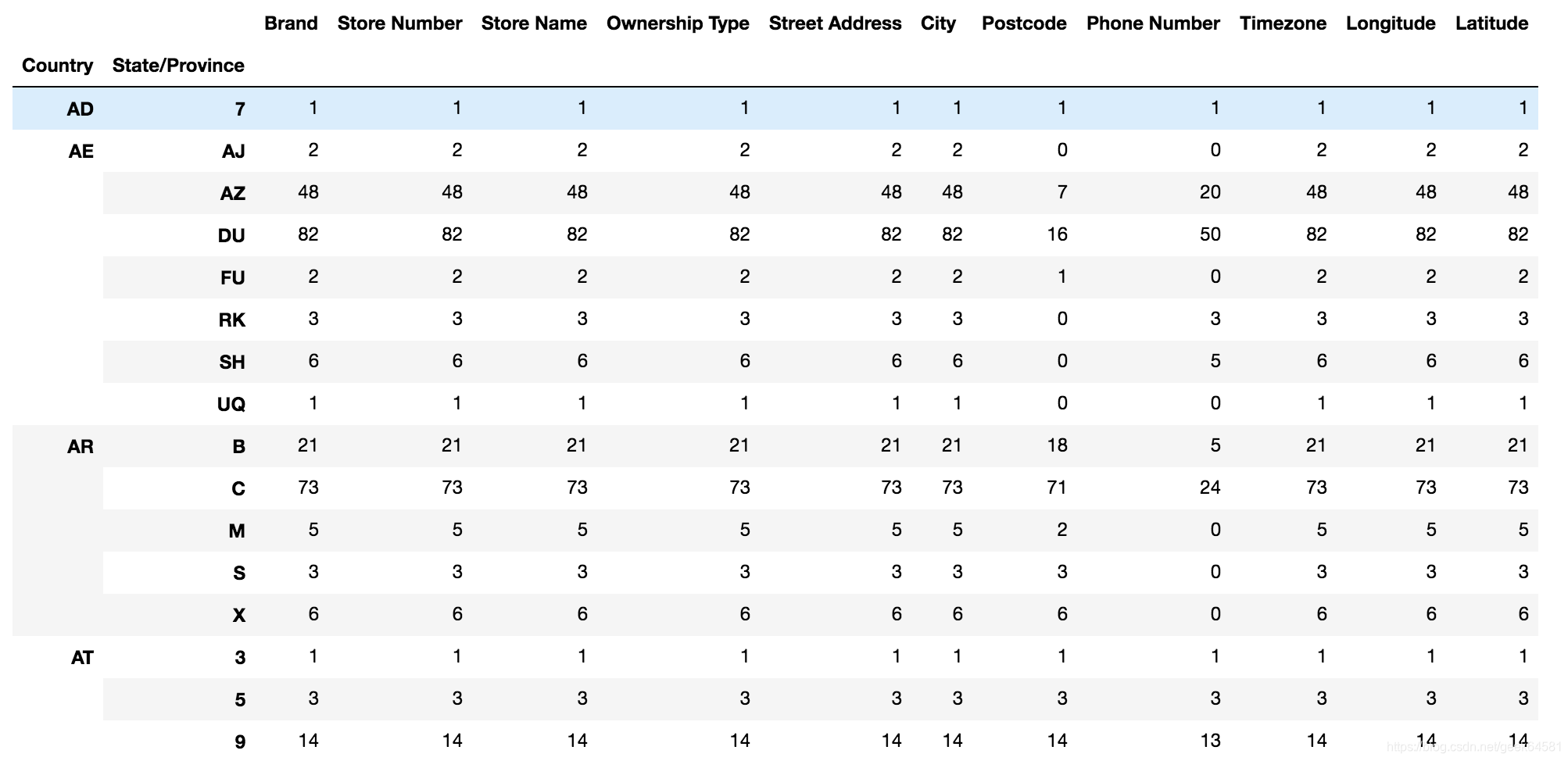
假设我们加入省市一起进行分组
# 设置多个索引,set_index()
starbucks.groupby(['Country', 'State/Province']).count()
版权声明:本文为geek64581原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。