提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
并查集的C++实现及优化
前言
提并查集(Disjoint-set) 的代码非常简洁,但是功能却很强大。
关于并查集,这里有一篇文章超有爱的并查集~,讲得非常好,但是只使用了并查集两个主要优化中的”路径压缩”优化,并且我觉得很多情况下采用递归的写法要比采用循环的写法要易懂很多。本文将使用C++实现并查集并使用“按秩合并”和”路径压缩“优化并查集。我们先大概了解什么是并查集。
一、什么是并查集(Disjoint-set)
对于一个集合S={a1, a2, …, an-1, an},我们还可以对集合S进一步划分: S1,S2,…,Sm-1,Sm,我们希望能够快速确定S中的两两元素是否属于S的同一子集。
举个栗子,S={0,1, 2, 3, 4, 5, 6},如果我们按照一定的规则对集合S进行划分,假设划分后为S1={1, 2, 4}, S2={3, 6},S3={0, 5},任意给定两个元素,我们如何确定它们是否属于同一子集?某些合并子集后,又如何确定两两关系?基于此类问题便出现了并查集这种数据结构。
并查集有两个基本操作:
Find: 查找元素所属子集
Union:合并两个子集为一个新的集合
# 二、并查集的基本结构 我们可以使用树这种数据结构来表示集合,不同的树就是不同的集合,并查集中包含了多棵树,表示并查集中不同的子集,树的集合是森林,所以并查集属于森林。 若集合S={0, 1, 2, 3, 4, 5, 6},最初每一个元素都是一棵树。

对于Union操作,我们只需要将两棵树合并,例如合并0、1、2得到S1={0, 1, 2},合并3和4得到S2={3, 4}
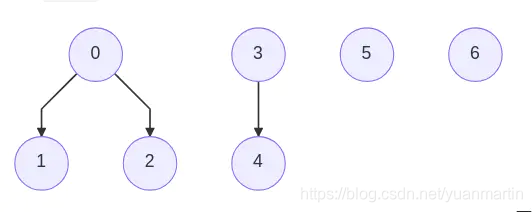
对于Find操作,我们只需要返回该元素所在树的根节点。所以,如果我们想要比较判断1和2是否在一个集合,只需要通过Find(1)和Find(2)返回各自的根节点比较是否相等便可。已知树中的一个节点,找到其根节点的时间复杂度为O(D),D为节点的深度。
我们可以使用数组来表示树,数组下标表示树的一个节点,该下表所对应的值表示树的父节点。例如P[i]表示元素i的父节点。对于图2中的集合,我们可以存储在下面的数组中(第二行为数组下标)
0 0 0 3 3 5 6
0 1 2 3 4 5 6
对于树的根节点,我们规定其元素值为其本身(即父节点为自己)。
三、C++实现一
我们使用一个parent数组存储树,先实现未经优化的版本。
对于Find操作,代码非常简单
int find(int x)
{
return parent[x] == x ? x : find(parent[x]);
}
该代码比较元素x的父节点parent[x]是否等于x自身,如果是便说明找到了根节点(根节点的父节点是自身),直接返回;否则,把x的父节点parent[x]传入find,直到找到根节点。
下面是union操作
void to_union(int x1,int x2)
{
int p1 = find(x1);
int p2 = find(x2);
parent[p1] = p2;
}
传入两个元素,分别找到根节点,使根节点p1的父节点为p2,即将p1为根节点的这棵树合并到p2为根节点的树上。
下面是完整代码:
#include <vector>
class DisjSet
{
private:
std::vector<int> parent;
public:
DisjSet(int max_size) : parent(std::vector<int>(max_size))
{
// 初始化每一个元素的根节点都为自身
for(int i = 0;i < max_size;i++)
{
parent[i] = i;
}
}
int find(int x)
{
return (parent[i] == x ? x : find(parent[i]);
}
void to_union(int x1, int x2)
{
parent[find(x1)] = find(x2);
}
// 判断两个元素是否属于同一个集合
bool is_same(int e1, int e2)
{
return find(e1) == find(e2);
}
};
刚学并查集的时候看到这里都快哭了,这代码也简洁了吧?。
上面的实现,可以看出每一次Find操作的时间复杂度为O(H),H为树的高度,由于我们没有对树做特殊处理,所以树的不断合并可能会使树严重不平衡,最坏情况每个节点都只有一个子节点,如下图3(第一个点为根节点)

此时Find操作的时间复杂度为O(n),这显然不是我们想要的。下面引入两个优化的方法。
# 四、并查集的优化
方法一:
“按秩合并”。实际上就是在合并两棵树时,将高度较小的树合并到高度较大的树上。这里我们使用“秩”(rank)代替高度,秩表示高度的上界,通常情况我们令只有一个节点的树的秩为0,严格来说,rank + 1才是高度的上界;两棵秩分别为r1、r2的树合并,如果秩不相等,我们将秩小的树合并到秩大的树上,这样就能保证新树秩不大于原来的任意一棵树。如果r1与r2相等,两棵树任意合并,并令新树的秩为r1 + 1。
方法二:
路径压缩”。在执行Find的过程中,将路径上的所有节点都直接连接到根节点上

同时使用这两种方法的平均时间复杂度为O(\alpha(n)),\alpha(n)是n=f(x)=A(x, x)的反函数,A(x, x)是阿克曼函数,A(x,x)增长率非常之高,所以在n非常大的时候,\alpha(n)依然小于5。下面是采用”按秩合并”与“路径压缩”两中优化算法的实现
五、C++实现二(优化版)
#include <vector>
class DisjSet
{
private:
std::vector<int> parent;
std::vector<int> rank; // 秩
public:
DisjSet(int max_size) : parent(std::vector<int>(max_size)),
rank(std::vector<int>(max_size, 0))
{
for (int i = 0; i < max_size; ++i)
parent[i] = i;
}
int find(int x)
{
return x == parent[x] ? x : (parent[x] = find(parent[x]));
}
void to_union(int x1, int x2)
{
int f1 = find(x1);
int f2 = find(x2);
if (rank[f1] > rank[f2])
parent[f2] = f1;
else
{
parent[f1] = f2;
if (rank[f1] == rank[f2])
++rank[f2];
}
}
bool is_same(int e1, int e2)
{
return find(e1) == find(e2);
}
};
六、总结
时间复杂度
采用“路径压缩”与“按秩合并”优化的并查集每个操作的平均时间复杂度为,是的反函数,在n非常大的时候,依然小于5。
空间复杂度
,n为元素的数量
参考资料
并查集—维基百科
数据结构与算法分析-C语言描述 第二版
算法导论(原书第3版)