我们都知道在mysql中使用联合索引时要遵循最左前缀原则,那么究竟为什么要遵循这个原则呢,我们可以从mysql的索引结构B+tree看起,B+tree是B-tree的变种,B+tree相比B-tree有几个不同点:
非叶子节点只存储键值信息。所有叶子节点之间都有一个链指针。数据记录都存放在叶子节点中。接下来我们就新建一个表来演示B+tree的结构图,首先我们创建一个表,设置a字段为主键并插入一些数据:

这时候生成的主键索引如下图所示(这边只是个大概,并非实际):
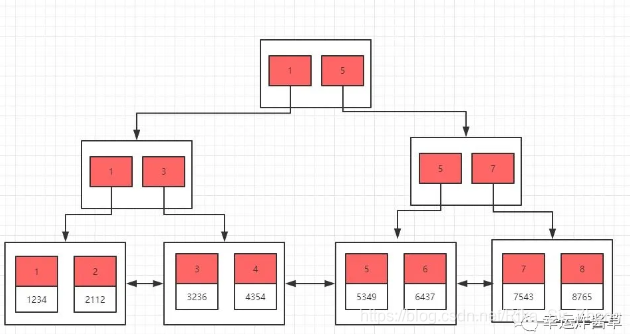
接下来我们创建一个联合索引:
create INDEX idx_bcd on test(b,c,d);
基于上面的主键索引结构图,我们可以画出该联合索引的结构图(与主键索引不同的是,联合索引中叶子节点并不会存储行数据而是存储该行数据的主键):
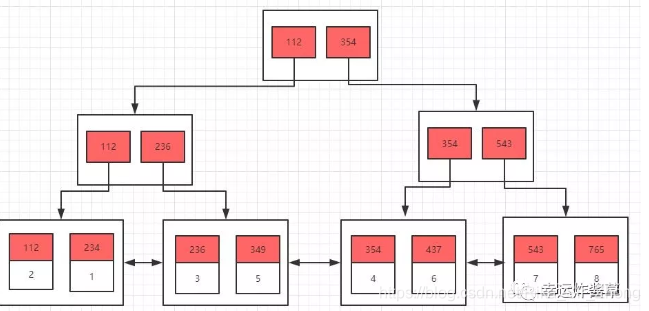
从图中我们其实就能明白为什么要遵循最左前缀原则了,我们可以看到当我们创建联合索引时,索引结构中非叶子节点存储的是bcd三个字段组合起来的值,除开第一字段b外,光看c和d字段我们可以明显看出其并非连续性的,也就无法进行查询了,比如:
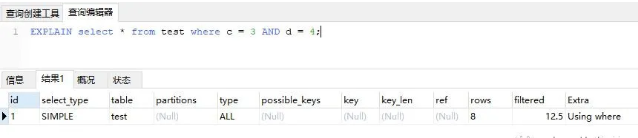
我们可以看到在查询的方式是全表扫描,这不难理解,因为按该条查询语句,假设我们使用索引去查询,就相当于拿
34到索引中进行对比,而
号可能是任意值,无法确定该往左节点还是右节点,因此便采用了全表扫描的方式。