参考
https://www.tensorflow.org/versions/master/how_tos/distributed/index.html
和
https://blog.csdn.net/CodeMaster_/article/details/76223835
。
一、单机单卡
单机单卡是最普通的情况,当然也是最简单的,示例代码如下:
#coding=utf-8
#单机单卡
#对于单机单卡,可以把参数和计算都定义再gpu上,不过如果参数模型比较大,显存不足等情况,就得放在cpu上
import tensorflow as tf
with tf.device('/cpu:0'):#也可以放在gpu上
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
np1,np2=sess.run([addwb,mutwb])
print (np1)
print (np2)
二、单机多卡
单机多卡,只要用device直接指定设备,就可以进行训练,SGD采用各个卡的平均值,示例代码如下:
#coding=utf-8
#单机多卡:
#一般采用共享操作定义在cpu上,然后并行操作定义在各自的gpu上,比如对于深度学习来说,我们一把把参数定义、参数梯度更新统一放在cpu上
#各个gpu通过各自计算各自batch 数据的梯度值,然后统一传到cpu上,由cpu计算求取平均值,cpu更新参数。
#具体的深度学习多卡训练代码,请参考:https://github.com/tensorflow/models/blob/master/inception/inception/inception_train.py
import tensorflow as tf
with tf.device('/cpu:0'):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
with tf.device('/gpu:1'):
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
while 1:
print (sess.run([addwb,mutwb]))
单机多卡过程可用下图来进行描述
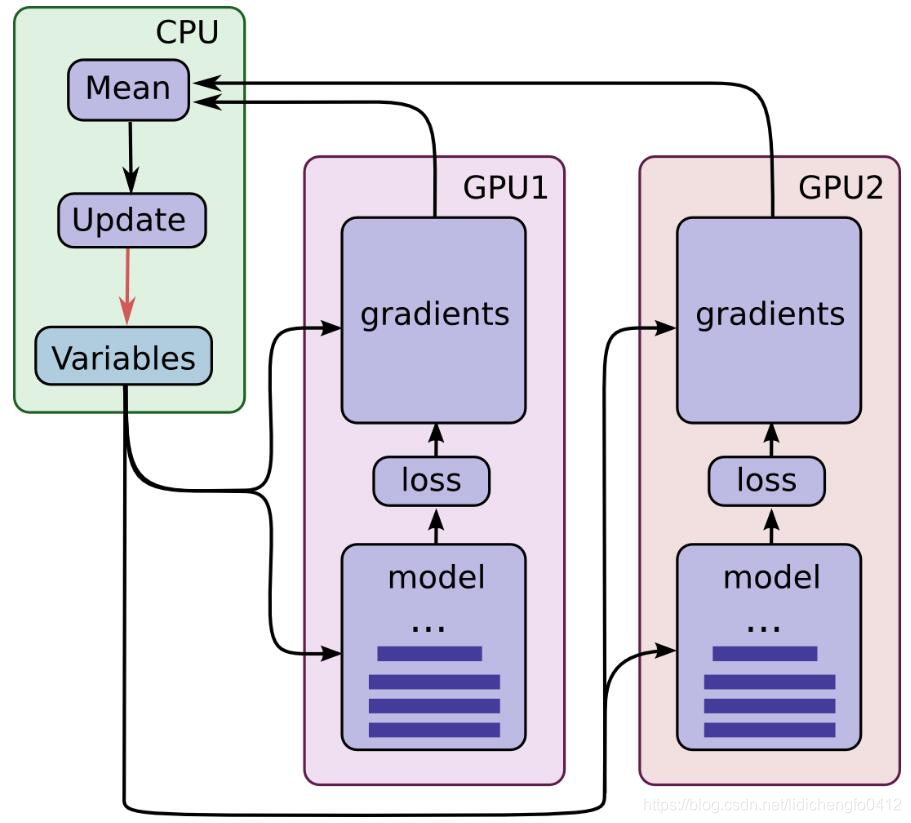
三、多机多卡
1、基本概念
cluster(集群)、job(作业)、task(任务)概念:三者可以简单的看成是层次关系,task可以看成每台机器上的一个进程,多个task组成job;job又有:ps、worker两种,分别用于参数服务、计算服务,组成cluster。
2、同步SGD与异步SGD
2.1、同步SGD
所谓的同步更新指的是:各个用于并行计算的电脑,计算完各自的batch 后,求取梯度值,把梯度值统一送到ps服务机器中,由ps服务机器求取梯度平均值,更新ps服务器上的参数。
如下图所示,可以看成有四台电脑,第一台电脑用于存储参数、共享参数、共享计算,可以简单的理解成内存、计算共享专用的区域,也就是ps job;另外三台电脑用于并行计算的,也就是worker task。
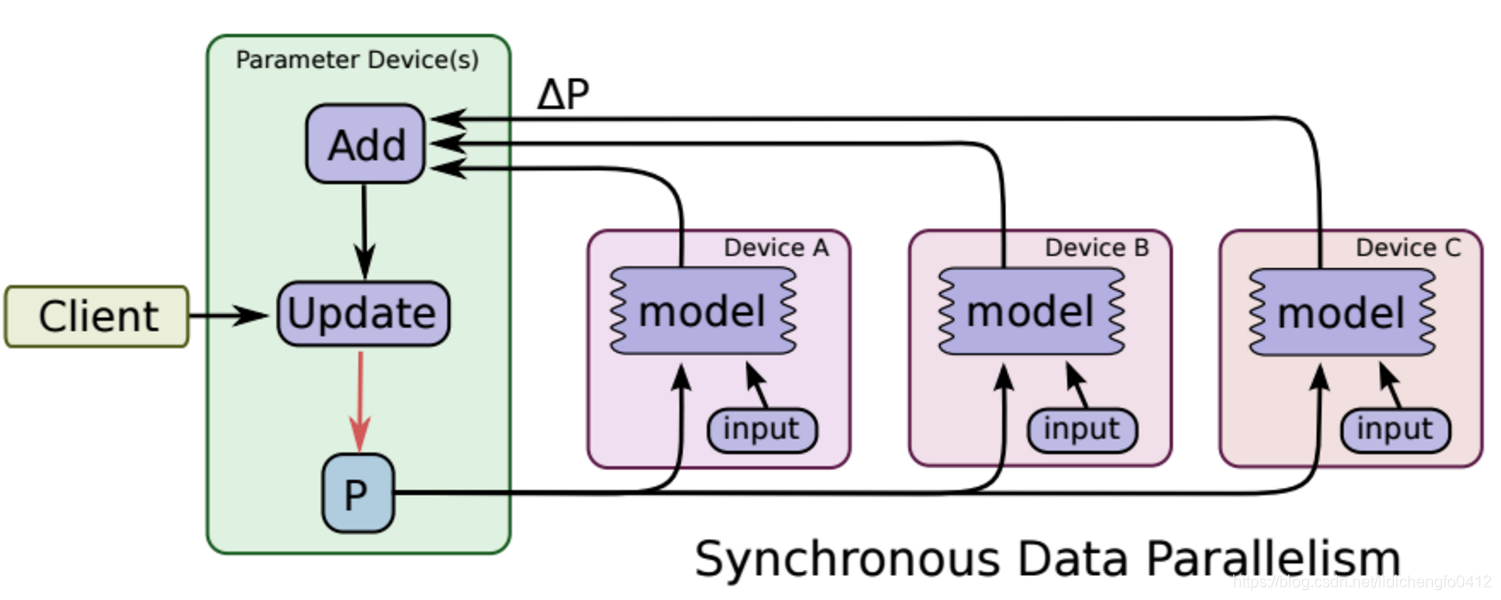
这种计算方法存在的缺陷是:每一轮的梯度更新,都要等到A、B、C三台电脑都计算完毕后,才能更新参数,也就是迭代更新速度取决与A、B、C三台中,最慢的那一台电脑,所以采用同步更新的方法,建议A、B、C三台的计算能力差不多。
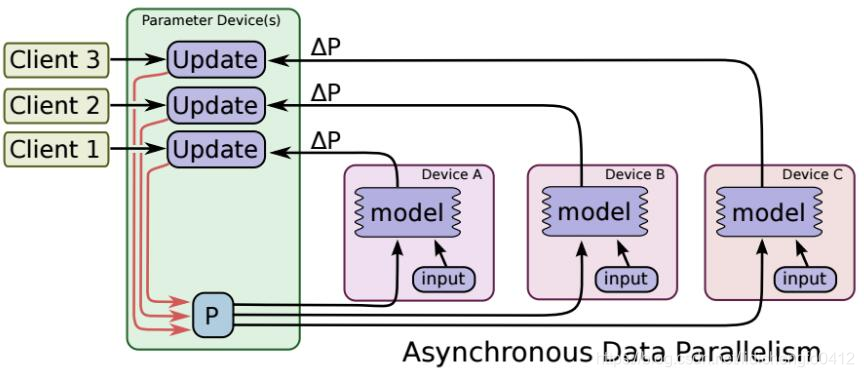
2.2、异步SGD
所谓的异步更新指的是:ps服务器收到只要收到一台机器的梯度值,就直接进行参数更新,无需等待其它机器。这种迭代方法比较不稳定,收敛曲线震动比较厉害,因为当A机器计算完更新了ps中的参数,可能B机器还是在用上一次迭代的旧版参数值。
其过程可描述成下图:
三、tensorflow的分布式训练在MNIST数据集的应用
# encoding:utf-8
import math
import tempfile
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
flags = tf.app.flags
IMAGE_PIXELS = 28
# 定义默认训练参数和数据路径
flags.DEFINE_string('data_dir', './MNIST_data', 'Directory for storing mnist data')
flags.DEFINE_integer('hidden_units', 100, 'Number of units in the hidden layer of the NN')
flags.DEFINE_integer('train_steps', 10000, 'Number of training steps to perform')
flags.DEFINE_integer('batch_size', 100, 'Training batch size ')
flags.DEFINE_float('learning_rate', 0.01, 'Learning rate')
# 定义分布式参数
# 参数服务器parameter server节点
flags.DEFINE_string('ps_hosts', '192.168.2.158:22221', 'Comma-separated list of hostname:port pairs')
# 两个worker节点
flags.DEFINE_string('worker_hosts', '192.168.2.154:22221,192.168.2.202:22221',
'Comma-separated list of hostname:port pairs')
# 设置job name参数
flags.DEFINE_string('job_name', None, 'job name: worker or ps')
# 设置任务的索引
flags.DEFINE_integer('task_index', None, 'Index of task within the job')
# 选择异步并行,同步并行
flags.DEFINE_integer("issync", None, "是否采用分布式的同步模式,1表示同步模式,0表示异步模式")
FLAGS = flags.FLAGS
def main(unused_argv):
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
if FLAGS.job_name is None or FLAGS.job_name == '':
raise ValueError('Must specify an explicit job_name !')
else:
print ('job_name : %s' % FLAGS.job_name)
if FLAGS.task_index is None or FLAGS.task_index == '':
raise ValueError('Must specify an explicit task_index!')
else:
print ('task_index : %d' % FLAGS.task_index)
ps_spec = FLAGS.ps_hosts.split(',')
worker_spec = FLAGS.worker_hosts.split(',')
# 创建集群
num_worker = len(worker_spec)
cluster = tf.train.ClusterSpec({'ps': ps_spec, 'worker': worker_spec})
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == 'ps':
server.join()
is_chief = (FLAGS.task_index == 0)
# worker_device = '/job:worker/task%d/cpu:0' % FLAGS.task_index
with tf.device(tf.train.replica_device_setter(
cluster=cluster
)):
global_step = tf.Variable(0, name='global_step', trainable=False) # 创建纪录全局训练步数变量
hid_w = tf.Variable(tf.truncated_normal([IMAGE_PIXELS * IMAGE_PIXELS, FLAGS.hidden_units],
stddev=1.0 / IMAGE_PIXELS), name='hid_w')
hid_b = tf.Variable(tf.zeros([FLAGS.hidden_units]), name='hid_b')
sm_w = tf.Variable(tf.truncated_normal([FLAGS.hidden_units, 10],
stddev=1.0 / math.sqrt(FLAGS.hidden_units)), name='sm_w')
sm_b = tf.Variable(tf.zeros([10]), name='sm_b')
x = tf.placeholder(tf.float32, [None, IMAGE_PIXELS * IMAGE_PIXELS])
y_ = tf.placeholder(tf.float32, [None, 10])
hid_lin = tf.nn.xw_plus_b(x, hid_w, hid_b)
hid = tf.nn.relu(hid_lin)
y = tf.nn.softmax(tf.nn.xw_plus_b(hid, sm_w, sm_b))
cross_entropy = -tf.reduce_sum(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
opt = tf.train.AdamOptimizer(FLAGS.learning_rate)
train_step = opt.minimize(cross_entropy, global_step=global_step)
# 生成本地的参数初始化操作init_op
init_op = tf.global_variables_initializer()
train_dir = tempfile.mkdtemp()
sv = tf.train.Supervisor(is_chief=is_chief, logdir=train_dir, init_op=init_op, recovery_wait_secs=1,
global_step=global_step)
if is_chief:
print ('Worker %d: Initailizing session...' % FLAGS.task_index)
else:
print ('Worker %d: Waiting for session to be initaialized...' % FLAGS.task_index)
sess = sv.prepare_or_wait_for_session(server.target)
print ('Worker %d: Session initialization complete.' % FLAGS.task_index)
time_begin = time.time()
print ('Traing begins @ %f' % time_begin)
local_step = 0
while True:
batch_xs, batch_ys = mnist.train.next_batch(FLAGS.batch_size)
train_feed = {x: batch_xs, y_: batch_ys}
_, step, loss = sess.run([train_step, global_step, cross_entropy], feed_dict=train_feed)
local_step += 1
now = time.time()
if local_step%1000==0:
print ('%f: Worker %d: traing step %d dome, loss: %f (global step:%d)' % (now, FLAGS.task_index, local_step, step, loss))
if step >= FLAGS.train_steps:
break
time_end = time.time()
print ('Training ends @ %f' % time_end)
train_time = time_end - time_begin
print ('Training elapsed time:%f s' % train_time)
val_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
val_xent = sess.run(cross_entropy, feed_dict=val_feed)
print ('After %d training step(s), validation cross entropy = %g' % (FLAGS.train_steps, val_xent))
sess.close()
if __name__ == '__main__':
tf.app.run()