一、导读
BERT 在2018年底横空出世之后,已经横扫了很多 NLP 的榜单,文本匹配这项基本的任务也不例外。
但是如果要将BERT模型部署到线上,考虑其延时,对于工业界大多数应用还是有些困难
,目前主流的方案是
采用知识蒸馏的方法
,通过 Student 模型去蒸馏 Teacher 模型BERT,以达到
接近甚至超过 BERT 模型的效果
。
这篇文章我们来介绍一种新型的、高效的比较文本相似性的方法 Enhanced-RCNN,该模型在
Quora Question Pair
和
Ant Financial
两个公开的文本匹配数据集上均取得了非常有竞争力的结果,并且和时下火热的预训练语言模型 BERT 相比,Enhanced-RCNN 也取得了相当的效果,同时参数量相比 BERT-Base 也大幅减少,
可以看作一种理想的蒸馏 BERT 模型的 Student 模型候选。
相关的论文已经被
WWW 2020
接收,欢迎大家一起交流和讨论。
二、背景介绍
如何衡量句子相似性是自然语言处理中一项基础而又重要的任务。当前比较句子相似性的方法主要分为3种:
表示型(Siamese Network Framework)、交互型(Matching-Aggregation Framework)和预训练语言模型(Pre-trained Language Model)
。
表示型的方法,
代表作如(Siamese-CNN,Siamese-RNN 等)
,它们将待比较的两个句子通过同一个编码器映射到相同的向量空间中,这种简单的参数共享的方法有着很好的线上性能,但是由于模型本身没有去考虑两个句子编码向量之间的交互关系,往往准确率不佳,于是,就有人提出了
交互型的句子相似度比较模型(ESIM,BIMPM,DINN 等)
,通过一些复杂的注意力机制来去捕捉两个句子编码向量之间交互的信息,从而更好的进行句子相似度建模。通常,基于交互型的句子相似度比较方法的预测准确率通常会比基于表示型的方法高出不少。
最近,
预训练语言模型(BERT,RoBERTa 等)
在很多公开数据集上达到了最优的效果,这种方法将在大规模语料上(比如维基百科)上训练好的语言模型放到特定领域的目标数据集上进行微调(Fine-tune)。这种类型的方法效果显著,但是缺点在于模型参数量庞大,在实际工业界难以部署到线上使用。
我们在
经典的文本匹配模型 ESIM
的基础上,提出了一种新型的计算文本相似度的方法 Enhanced-RCNN,在效果保证的前提下也拥有良好的性能。
下面将对 Enhanced-RCNN 模型进行详细的介绍。
三、Enhanced-RCNN Model
Enhanced-RCNN 模型的结构如下图所示,我们自底向上依次来介绍:
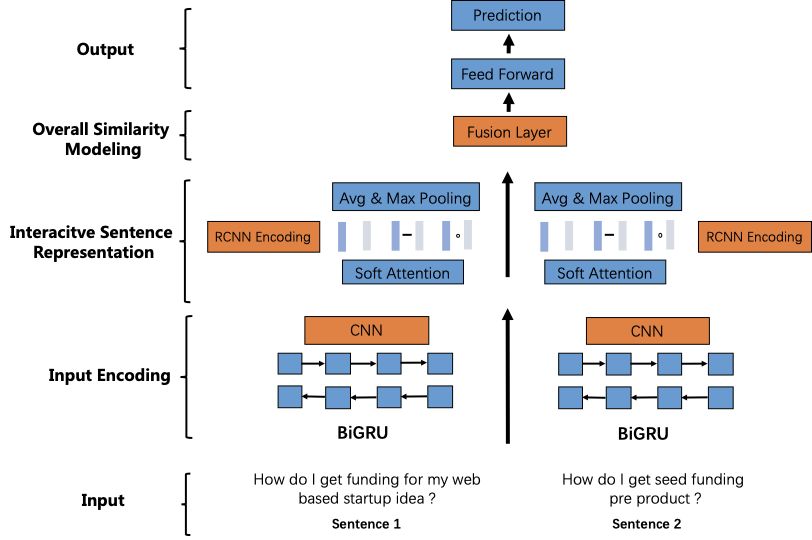
Enhanced-RCNN 模型整体结构图
3.1 Input Encoding
Input Encoding 分为 RNN Encoder 和 CNN Encoder 两部分。RNN 主要用来捕捉文本的序列信息 (sequence and context features of sentences);CNN 主要用来捕捉文本的关键词信息 (keywords and phrases information in sentences),
CNN 的这个特性在自动摘要中已经得到广泛应用。
下面分别来介绍 RNN Encoder 和 CNN Encoder。
3.1.1 RNN Encoder
首先,对待比较的 2 个问题文本使用 BiGRU 进行编码,主要为了捕捉句子序列的特征信息。这里没有使用 BiLSTM,因为在实际应用中发现使用 BiGRU 的效果更好,同时效率更高。
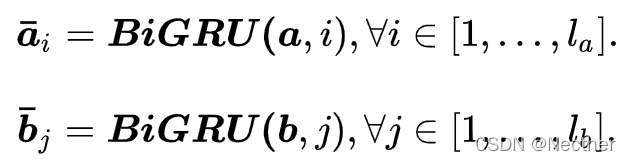
3.1.2 CNN Encoder
在 BiGRU 编码的基础上,使用 CNN 来进行二次编码,利用 CNN 卷积核的特质来捕捉词粒度 (类似 n-gram) 的特征信息 (关键词、词组等), 得到 RCNN Encoding。

在设计 CNN 层结构的时候,我们借鉴了 “Network in Network” 的思想,设计了相应的结构方便更好的提取文本的特征信息,如下图所示。

CNN Encoder 结构
我们通过在 Input Encoding 中结合 BiGRU 和 CNN,可以更加充分的去捕捉两个待比较的问题文本的细粒度 (fine-grained) 特征信息。然后,在后续的 Interaction Modeling 中,Enhanced-RCNN 会同时使用 RNN Encoding 和 RCNN Encoding 来捕捉两个文本的交互信息。
3.2 Interactive Sentence Representation
我们的 Enhanced-RCNN 和 ESIM 模型一样,都属于基于“交互式”的文本模型,所以在 Input Encoding 之后,通过 Attention 机制去捕捉两个带比较文本直接的交互信息,这里用到的是 Soft attention Alignment 来得到 Interactive Sentence Representation。
3.2.1 Soft-attention Alignment
首先,我们利用 BiGRU 输出的 RNN Encoding 去计算得到两个待比较的文本之间的软注意力权重 (Soft-attention)。这里针对待比较的两个文本,可以得到的 2 个不同的注意力权重,分别是文本 A 相对文本 B,和文本 B 相对文本 A 的。这部分可以理解为去捕捉两个问题之间交互的信息 (相似和不相似的地方)。
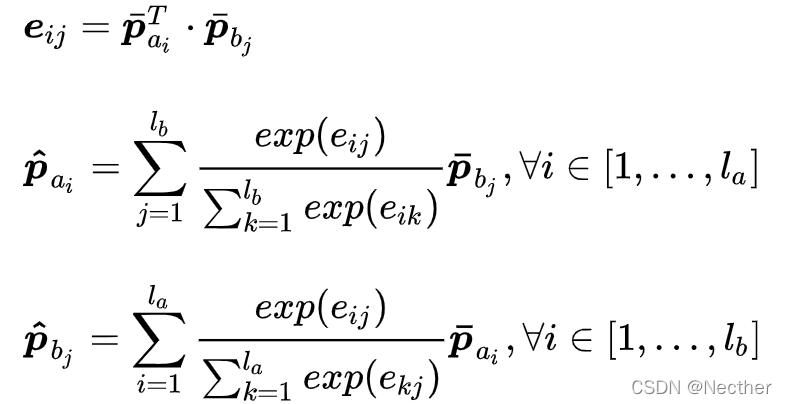
3.2.2 Interaction Modeling
通过 Soft Attention alignment 得到 Interactive Sentence Representation 之后,我们使用“最大”池化和“均值”池化进一步捕捉文本的特征信息,并且在之后和 RCNN Encoding 相结合,具体的计算过程如下所示。
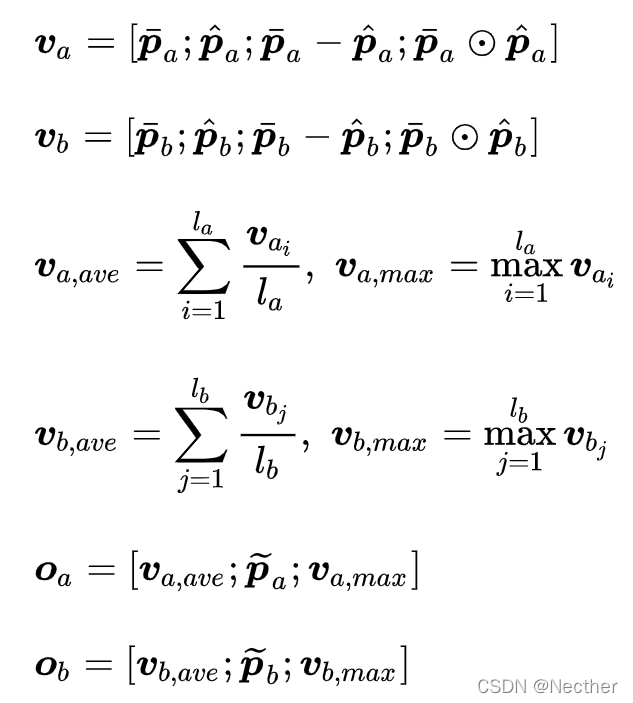
和当前的基于交互式的文本匹配方法不同的是,我们同时使用 RNN 和 CNN 来进行 Interaction Modeling 以获得两个文本的 Interactive Sentence Representation。通过结合 RNN 和 CNN 的优点,我们可以捕捉更细粒度(fine-grained)的特征 (sequence and keywords information)。同时,由于 CNN 卷积核特有的参数共享机制,我们模型的参数量也能得到进一步缩小。
3.3 Similarity Modeling
在得到了 Interactive Sentence Representation 和 之后,我们参考了达摩院在机器阅读任务里提出的
SLQA 模型
,设计了一个特殊的融合层(Fusion Layer),在全局性的相似度建模中融合两个文本的向量表示。
3.3.1 Fusion Layer
将 RCNN 的 Input Encoding 和经过均值/最大池化后的软注意力权重输出到融合层,同时引入了门限(Gate)机制,进行全局性的相似度建模。
融合层的主要目的是为了更好的融合两个待比较文本的 Interacitve Sentence Representation,为了方便后面计算两个问题的相似度:

在设计这个融合层的时候, 两个输入文本的 Fused Representations 可以被形式化的表示如下:
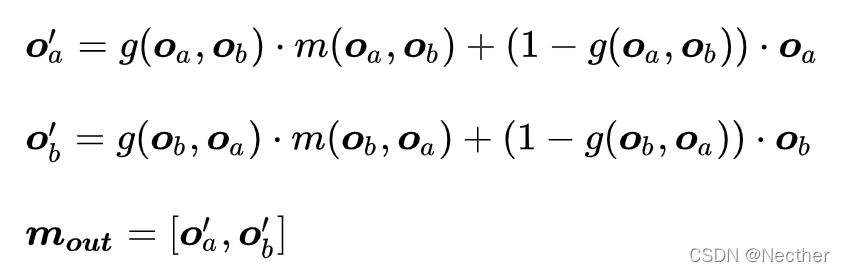
3.3.2 Label Prediction
在最后的 prediction layer,我们将前一步输出
![]()
输入到一个两层的 MLP 中去计算两个文本相似的概率。整个模型是端到端来训练的,并且使用 cross-entropy 作为损失函数。
四、实验结果
我们选择 Quora Question Pair 和 Ant Financial 这两个比较文本相似性的公开数据集.
4.1 消融分析
首先,我们做了消融分析的实验,来比较
有无 BiGRU、CNN、Attenion 的影响
,结果如 Table 2 所示。

消融分析实验对比
从消融分析的结果可以看出,去掉 BiGRU 对应结果的影响是最大的,说明了使用 BiGRU 对文本进行建模是有效并且必要的;去掉 CNN 的影响其次,说明 CNN 的加入,可以在某些方面弥补 BiGRU 的不足。从前 2 个消融分析的实验可以看出,单独使用 BiGRU 和单独使用 CNN 的效果和同时使用 BiGRU 和 CNN 有较大差距,说明了我们在 Input Encoding 和 Interaction Modeling 阶段引入 BiGRU 和 CNN 的做法是 work 的。
最后一个消融分析实验,我们比较了去掉 Attention Layer 对结果的影响,实验结果显示,其实有无 Attention 对应结果影响不大,至少远没有去掉 CNN 或者 BiGRU 大。这个有趣的发现抛出了一个问题,就是现在很多 Text Matching 模型中使用的那么复杂的 Attenion 机制真的有用吗?
4.2 对比实验
下面我们和当下流行的 Text Matching 模型进行了比较,分为两部分,第一个是和非 BERT 的传统文本匹配模型进行比较,第二个是和 BERT 模型进行比较。
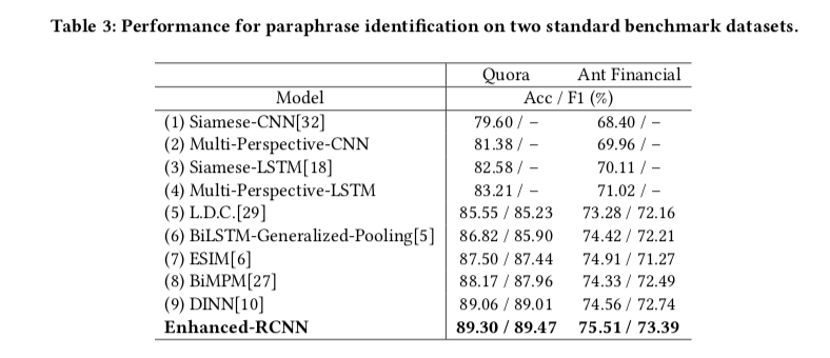
和传统的文本匹配方法的对比实验
第一个部分,Enhanced-RCNN 在 Quora 和 Ant Financial 这两个公开数据集上和传统的文本匹配模型的比较中,取得了最优的结果。传统的文本匹配模型主要分为两种 — “表示型”(Siamese-CNN, Siamese-LSTM)和 “交互型” (BiMPM, LDC, ESIM 和 DINN)。“交互型” 模型和“表示型”模型的主要区别在于“交互型”的模型利用 Attenion 机制去捕捉了 2 个文本之间的交互信息,对于文本特征信息的捕捉相比“表示型”模型更加的充分。我们提出的 Enhanced-RCNN 属于一种 “交互型” 的文本匹配模型,在交互机制的设计上更加轻量级,同时效果相比其他的 “交互型” 模型更好。

和BERT模型的对比实验
第二个部分,我们拿 Enhanced-RCNN 和当下 NLP 的明星模型 BERT 进行了比较。不出意外,在单模型的比较下,Enhanced-RCNN 不如 BERT-Base,不过效果也很有竞争力;当对 BERT-Base 进行 ensemble 之后 (5-fold),Enhanced-RCNN 的效果要好于 BERT-Base。
除了对比 Enhanced-RCNN 和 BERT-Base 的效果之外,我们还对比了他们的 params size 和 inference time cost,Enhanced-RCNN 的 params size 只有 BERT-Base 的十二分之一,inference speed 比 BERT-Base 要快十倍。可以看出,Enhanced-RCNN 要更高效,更适合工业场景的应用。
4.3 案例分析

案例分析
这里我们展示了一个典型的例子,“花呗” 和 “花被” 是经常被混淆的错别字,我们对 Enhanced-RCNN 做了有无 CNN module 的对比实验,可视化了 Interaction Modeling 中两个句子的 Attention 矩阵。可以看到,“花呗” 和 “花被” 这 2 个词在 Enhanced-RCNN 下的 Attention 权重要明显高于没有加 CNN module 下的,从侧面反映了 CNN module 在错别字(或者关键词)的处理上有更好的效果。
五、总结
至此,我们介绍完了整个 Enhanced-RCNN 模型。虽然效果相比 BERT 仍有差距,但是性能却能有很大的提升,较为适合作为知识蒸馏时的 Student 模型。同时,除了文本匹配任务,NLP领域其他任务也有使用轻量级文本匹配模型的需求,比如 Paraphrase Generation 任务,当我们要去衡量生成的 Paraphrase Pair 质量而对模型精度要求没那么高的时候,Enhanced-RCNN 会比 BERT 等重量级模型更适合一些。
后续我们专栏也会介绍一些如何高效的用小模型蒸馏大模型的方法。
再次欢迎大家一起参与讨论。